A Data Marketplace Is
What Your Agents Need
Ein unabhängiger BARC-Report darüber, warum agentische KI die Anforderungen an vertrauenswürdige, governte und auffindbare Business-Daten erhöht — und wie ein Datenmarktplatz, der auf Datenprodukten und Data Contracts aufbaut, die Antwort darauf liefert.
Dieser BARC-Spotlight-Report wurde von Florian Bigelmaier geschrieben, Analyst for Data & Analytics bei BARC, dem führenden unabhängigen Analystenhaus für Data & Analytics, KI und Corporate Performance Management. Entropy Data hat diesen Report gesponsert und Input sowie Feedback beigesteuert, doch die Analyse und die Meinungen sind BARCs eigene. Der vollständige Text ist unten unverändert wiedergegeben.
Veröffentlicht im Juni 2026.

- 73%
- sagen, dass relevante Daten nicht leicht zu finden sind
- 75%
- bestätigen, dass ihren Daten und Analysen Verlässlichkeit und Interpretierbarkeit fehlen
- 49%
- nennen den Aufbau einer Datenprodukt-Organisation eine aktuelle Herausforderung
Quelle: BARC-Umfrage “Data Mesh and Data Fabric” 2024 (n=197 / n=121).
Vertrauen, Zugriff und Verantwortlichkeit: Wie Datenmarktplätze KI-Agenten ermöglichen
Daten vertrauenswürdig und auffindbar zu machen, ist seit Jahren eine hartnäckige, ungelöste Herausforderung in der Business-Datenanalyse. Laut der BARC-Studie Data Mesh and Data Fabric – From Theory to Application1 berichten 73 % der Befragten, dass relevante Daten nicht leicht zu finden sind, und 75 % bestätigen, dass ihren Daten und Analysen Verlässlichkeit und Interpretierbarkeit fehlen.
Diese Zahlen stammen aus der Zeit vor der Welle agentischer KI. Während KI-Agenten beginnen, kritische Geschäftsprozesse zu automatisieren, steigen die Einsätze deutlich: Die Lücken in der Infrastruktur, die Data Consumers2 ausbremsen, können dazu führen, dass Agenten auf Basis unvollständiger oder nicht vertrauenswürdiger Daten handeln. Ein Datenmarktplatz ist Teil der Antwort: Er macht Daten auffindbar, vertrauenswürdig und zugänglich, und zwar so, dass es für Menschen wie für KI-Agenten funktioniert.
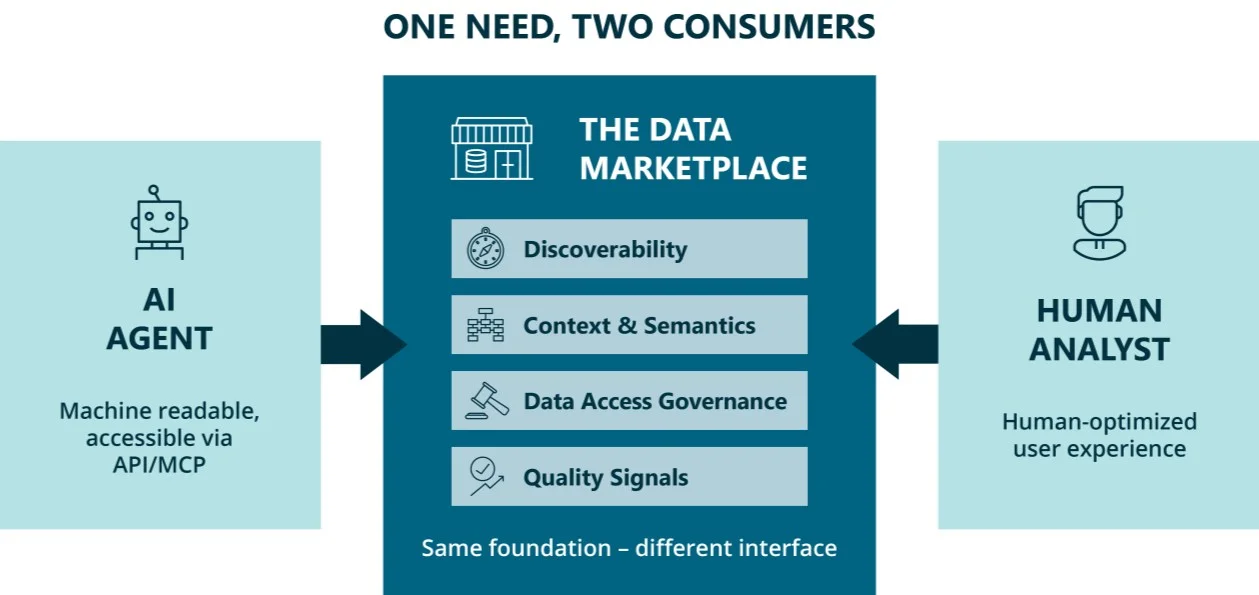
Menschen und Agenten brauchen dieselben vier Bedingungen von Business-Daten
Bevor wir zur vorgeschlagenen Lösung kommen, tauchen wir eine Ebene tiefer in die Diagnose ein. BARCs Forschung verweist immer wieder auf vier grundlegende Datenherausforderungen, vor denen Organisationen heute stehen:
- Data Consumers finden die richtigen Daten nicht (Auffindbarkeit)
- Sie verstehen nicht, was Daten bedeuten, weil sie schlecht erklärt sind (Kontext und Semantik)
- Sie können nicht schnell genug auf Daten zugreifen, weil die Datenzugriffs-Workflows komplex und manuell sind (Data Access Governance)
- Sie können nicht beurteilen, ob die Daten, die sie sich ansehen, vertrauenswürdig sind (Qualitätssignale)
Wir argumentieren, dass KI-Agenten vor denselben vier Hürden stehen, nur mit weniger Toleranz für Fehler. Lass mich dir zwei Beispiele geben:
| Situation | Verhalten von Menschen | Verhalten von Agenten |
|---|---|---|
| Datenqualität passt nicht zum Zweck | Kann innehalten, recherchieren oder einen Kollegen fragen | Erkennt die Qualitätslücke unter Umständen gar nicht. Die Ergebnisse reichen von der proaktiven Suche nach besseren Daten über den Abbruch der Aufgabe bis hin zum stillen Weitermachen mit ungeeigneten Daten und halluzinierten Ergebnissen. |
| Fehlende Zugriffsrechte für den beabsichtigten Zweck | Kann anfragen, warten, den Owner per Telefon fragen | Bleibt entweder stehen oder greift, falls Metadaten fehlen oder unklar sind, auf ein Data Asset zurück, zu dem es physischen Zugriff hat – ohne aber das Recht zu haben, es für den neuen, abweichenden Zweck zu nutzen. |
Leider sind das keine Randfälle, sondern vielmehr die vorhersehbaren Folgen davon, Agenten auf einer Dateninfrastruktur einzusetzen, die nicht mit agentischer KI im Blick entworfen wurde.
Die Schlussfolgerung ist eindeutig: Daten müssen auffindbar, kontextualisiert und so zugänglich sein, dass es für KI-Agenten funktioniert. Dann funktioniert es auch für Menschen, denn sie sind anpassungsfähiger.
Beliebige Data Assets reichen nicht aus
Diese vier Hürden zu adressieren, ist nicht nur eine Frage der Datenplattform oder des Designs der Benutzeroberfläche. Es beginnt damit, wie Daten für den Konsum verpackt werden. Nehmen wir eine Analogie: Ein pharmazeutischer Wirkstoff in Reinform, etwa ASS, ist kein Produkt. Aspirin3 schon, weil es die dosierte, etikettierte Variante davon ist, verpackt mit Gegenanzeigen, von einem verantwortlichen Hersteller und mit Beipackzettel. Die Analogie ist simpel: Wenn du etwas auf einem Marktplatz anbieten willst, mach ein Produkt daraus, das leicht zu bewerten, zu konsumieren und zu vertrauen ist.
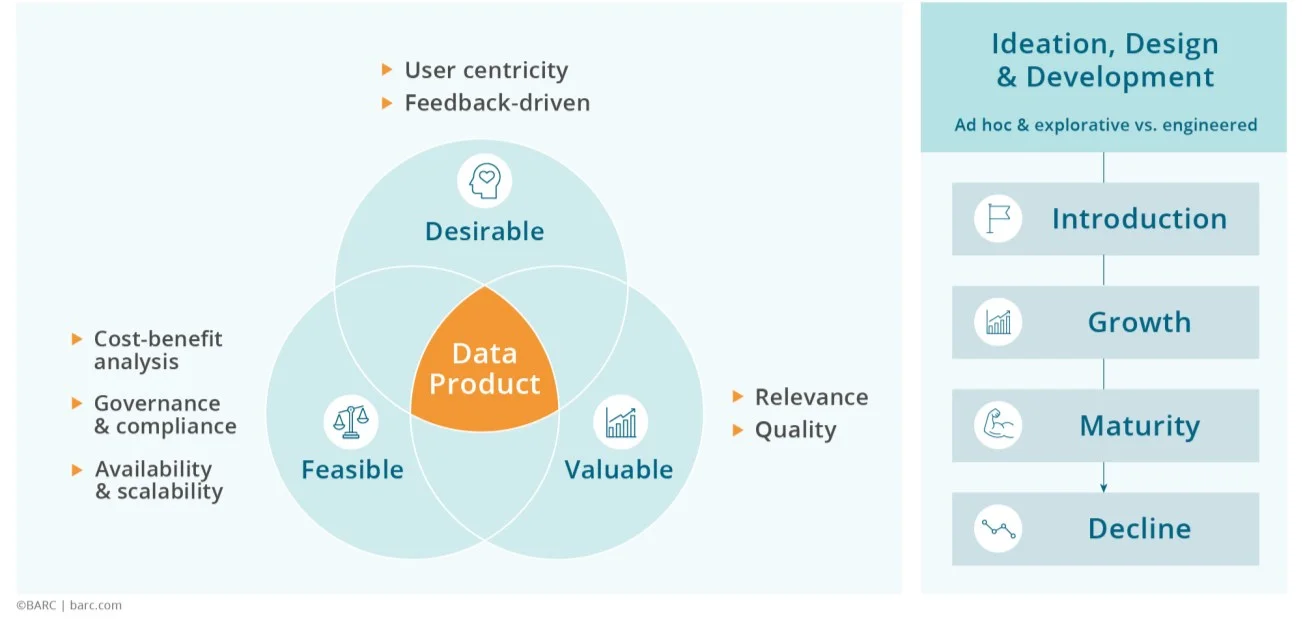
Definition eines Datenprodukts – Deep Dive für Neugierige
Ein Datenprodukt ist ein einkaufbares, wiederverwendbares, aktives und standardisiertes Data Asset, das darauf ausgelegt ist, messbaren Wert zu liefern, indem es Prinzipien des Product Thinking anwendet. Es umfasst ein oder mehrere Artefakte, angereichert mit Metadaten wie Governance-Policies, Data Contracts und optional einer SBOM (Software Bill of Material). Ausgerichtet auf eine bestimmte Domäne oder einen bestimmten Use Case stellt es Verantwortlichkeit, kontinuierliche Weiterentwicklung, Skalierbarkeit und Konformität mit fachlichen und regulatorischen Standards sicher.
– Jacqueline Bloemen, Florian Bigelmaier (beide BARC), 2025, mit einer leichten Anpassung der Bitol-Definition von Datenprodukten.
Erfahre mehr über Datenprodukte unter barc.com/data-products
Datenprodukte bündeln alles, was ein Consumer braucht: zweckorientierte Daten, Metadaten, SLAs, klares Ownership, dauerhafte Pflege und Nutzungsbedingungen. Beliebige Datensätze ohne Ownership und semantische Dokumentation erzeugen keine verlässliche Nachfrage.
Das lässt sich jedoch nicht über Nacht aufbauen. BARCs Forschung zeigt, dass 49 % der Organisationen den Aufbau einer Datenprodukt-Organisation und eines entsprechenden Mindsets als aktuelle Herausforderung benennen4, weil es einen Wechsel von einem serviceorientierten zu einem produktorientierten Modell erfordert. Ein Marktplatz kann bei dieser Herausforderung ein Katalysator sein, doch die dafür nötige kulturelle Transformation ist nicht zu unterschätzen.
Ownership von Datenprodukten ist das stärkste organisatorische Werkzeug, das wir haben, um das Vertrauen in Daten zu erhöhen. Oder andersherum gesagt: Datenprodukte werden nur erfolgreich sein, wenn Owner auf der Business-Seite die Verantwortung für die Daten übernehmen, die ihre Prozesse erzeugen. Data Engineers und Application Developers können Infrastruktur bauen, um diese Prozesse zu digitalisieren und zu automatisieren; sie können für die technischen Pipelines verantwortlich sein, die die Daten von A nach B bringen und veredeln. Aber sie können nicht für den Prozess verantwortlich gemacht werden, der die Daten erzeugt.
Ein einfaches Beispiel: Ein Data Engineer hat selten die Macht, einem Vertriebsmitarbeiter vorzuschreiben, wie er Daten im CRM-System eingibt.
KI erhöht den Einsatz bei der Datenqualität. Business-Manager haben jetzt ungewöhnlichen organisatorischen Hebel: Die Datenqualitätsprobleme, die Teams lange als "ungenaue Dashboards" tolerierten, übersetzen sich in einer agentischen Welt direkt in kaputte Automatisierung und unzuverlässige Agenten. Diese Konsequenz lässt sich schwer ignorieren.
Wenn Datenprodukte nicht dieselbe Sprache sprechen
Es gibt eine weitere Dimension, an der beliebige Datensätze scheitern: Interoperabilität. Ein einzelnes gut verpacktes Datenprodukt ist nützlich, aber erst die Kombination von zwei oder mehr lässt Erkenntnisse zusammenwachsen. Doch Produkte aus verschiedenen Domänen zu kombinieren, erfordert geteilte Semantik. Bedeutet "Kunde" in der Vertriebsdomäne dasselbe wie "Kunde" in der Logistikdomäne? Folgt "Umsatz" im Finanzwesen denselben Erfassungsregeln wie im kommerziellen Reporting? Daten als Produkt zu verpacken, kann diese Fragmentierung paradoxerweise verstärken: Domain Ownership gibt Teams weniger statt mehr Anreiz, ihre Definitionen mit dem Rest der Organisation abzustimmen.
Ein Ansatz, das zu lösen, besteht darin, mit explizit dokumentierten Definitionen zu arbeiten. Datenprodukte müssen nicht nur erklären, was sie enthalten, sondern auch, wie sich ihre Schlüsselbegriffe auf gleichwertige Begriffe in anderen Produkten beziehen, sie erweitern oder ihnen widersprechen. Ein Datenmarktplatz, der diese Beziehungen sichtbar macht und explizit kennzeichnet, wo Definitionen übereinstimmen und wo sie auseinandergehen, verwandelt passives Entdecken in informierte Kombination. Consumers und Agenten können dann gleichermaßen explizite Entscheidungen darüber treffen, welche Definition sie aus welchem Grund verwenden, anstatt unwissentlich inkompatible Repräsentationen desselben realen Konzepts zu kombinieren.
Data Contracts: Das fehlende Element zur Automatisierung von Datenzugriff
Während die Etablierung echten Ownerships die häufigste organisatorische Methode ist, um das Vertrauen in Daten zu erhöhen, gibt es einen Weg, die Beziehung zwischen Data Producer und Consumer weiter zu stärken: Data Contracts.
Data Contracts legen fest, was geliefert wird und unter welchen Bedingungen. Das erfüllt mehrere Zwecke: Erstens formalisiert ein Contract die Beziehung zwischen Producer und Consumer. In der Praxis heißt das, ein Consumer weiß genau, was er von einem Datenprodukt erwarten kann, wer dafür verantwortlich ist und an wen er sich wenden muss, wenn etwas kaputtgeht. Statt einer informellen Abhängigkeit von demjenigen, der die Pipeline gebaut hat, wird die Beziehung explizit: ein benannter Owner mit definierten Pflichten und ein Consumer mit klar formulierten Nutzungsrechten, gebunden an einen festgelegten Zweck.
Zweitens ist er eine strukturierte Informationsquelle über ein Datenprodukt, vergleichbar mit dem Beipackzettel einer Medikation, um bei der obigen Analogie zu bleiben. Qualitätssignale, die im Contract eingebettet sind, erlauben es Consumers und insbesondere Agenten, die Eignung für den Zweck zu beurteilen, bevor sie konsumieren.
Drittens machen Contracts Datenqualität überprüfbar. Ein Contract definiert, was ein Datenprodukt liefern soll. Er kann Erwartungen an Format, Vollständigkeit und Aktualität enthalten. So lassen sich tatsächliche Daten automatisch gegen diese Spezifikationen validieren. Gerade für Agenten ist das wichtig: Anstatt Qualitätsprobleme stromabwärts weiterzureichen, kann ein Agent die Eignung für den Zweck vor der Verarbeitung verifizieren.
Viertens machen Contracts das Zugriffsmanagement automatisierbar. Wenn die Regeln darüber, wer ein Datenprodukt für welchen Zweck nutzen darf, bereits niedergeschrieben sind, kann das System Zugriffsanfragen automatisch ohne menschliche Beteiligung genehmigen. Für einen Menschen bedeutet das schnelleren Zugriff auf die Daten, die er braucht. Für Agenten ist das noch wichtiger, denn sie werden irgendwann weitaus häufiger Zugriff auf Daten anfragen, als es Menschen je getan haben.
Data Contracts allein reichen jedoch nicht aus. Ähnlich wie in der realen Welt, wo Verträge einzelne Beziehungen regeln, aber innerhalb eines breiteren rechtlichen Rahmens operieren, brauchen Data Contracts organisationsweite Policies, die ihnen Kontext geben. Policies definieren, was universell erlaubt oder verboten ist und welchen Standards zu folgen ist; Contracts spezifizieren zusätzliche Regeln innerhalb dieser Grenzen für ein bestimmtes Datenprodukt.
Der Datenmarktplatz: Wo alles zusammenkommt
Jede ausgereifte Datenplattform hat zumindest ein technisches Metadaten-Repository, so wie jede Bibliothek einen Index hat. Solche Werkzeuge helfen bei der Auffindbarkeit. Was sie nicht können, ist Vertrauen schaffen. Ein Metadaten-Index sagt dir, dass ein Datensatz existiert, aber er sagt dir nicht, ob er verlässlich ist, was er in deinem Business-Kontext bedeutet oder ob er zu deinem Use Case passt. Vertrauen, aufgebaut durch Kontext, Semantik und Qualitätssignale (wie oben erläutert), ist das, was passives Entdecken in tatsächliche Nachfrage verwandelt und einen internen Datenmarktplatz so wertvoll macht.
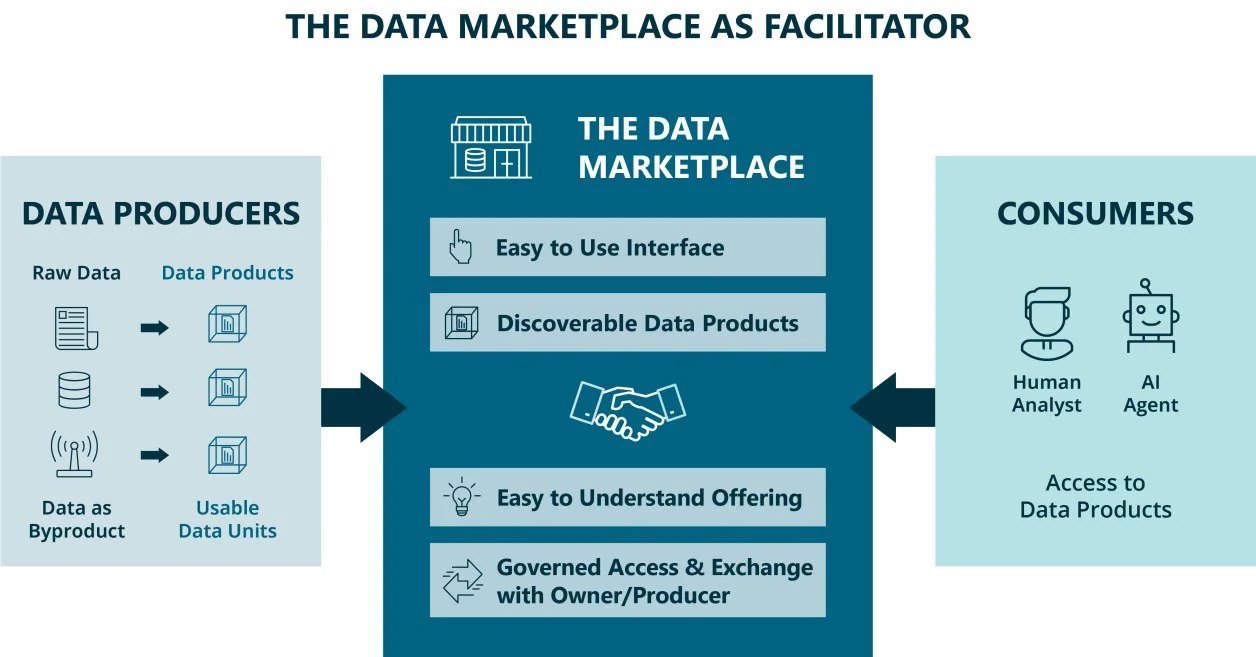
Viele Datenmarktplätze fühlen sich an wie ein Amazon-Einkaufserlebnis – aber sie beginnen zu bröckeln, sobald du das Produkt tatsächlich beziehen willst. Sobald ein Consumer ein vertrauenswürdiges Datenprodukt gefunden hat, ist die nächste Erwartung sofortiger Zugriff. Genau hier kommen viele Organisationen noch zu kurz, mit manuellen Freigabe-Workflows, die Tage oder Wochen dauern. Ein Datenmarktplatz adressiert den Entdeckungsteil dieser Schleife. Im Kern ist er eine kuratierte Metadaten-Suchmaschine, die Datenprodukte mit dem Kontext sichtbar macht, der nötig ist, um ihre Eignung und Vertrauenswürdigkeit zu beurteilen. Die meisten Marktplätze hören heute genau dort auf. Die ehrgeizigere Vision, und die Richtung, in die sich die ausgereiftesten Implementierungen bewegen, ist es, das auch auf die Bereitstellung von Zugriff auszuweiten. Statt einen Consumer einfach zum richtigen Datenprodukt zu lotsen und ihn dann ein Ticket öffnen zu lassen, würde der Marktplatz auch die Zugriffsanfrage selbst governen und automatisieren.
Vertrauen ist der Marktmechanismus, der in vielen Unternehmen mit gescheiterten Marktplatz-Implementierungen fehlt. Erfolgreiche Implementierungen haben eines gemeinsam: Consumers finden ein Angebot und können schnell beurteilen, in welchem Maße ein Datenprodukt für ihren Use Case geeignet ist, und sich auf dieses Urteil verlassen.
Je komplexer eine Organisation wird, desto wertvoller ist ein Datenmarktplatz. Mehr Fachlichkeiten, mehr Datenplattformen, mehr Teams, die mit Daten arbeiten: All das erhöht den Bedarf zu wissen, welche Daten existieren, wo man sie findet und wie man auf sie zugreift. Es braucht einen verlässlichen Einstiegspunkt, der genug Kontext liefert, um das richtige Datenprodukt auszuwählen und zu konsumieren.
Ein Wort der Vorsicht: Das gilt nur, wenn der Marktplatz aktuell gehalten wird. Mit der Zahl der registrierten Produkte wächst auch der Pflegeaufwand. Ein schlecht gepflegter Marktplatz wird schnell zu Rauschen statt zu Signal, und Consumers hören auf, ihm zu vertrauen. Jedes Marktplatzprojekt hat einen Punkt, an dem Komplexität gegen die Auffindbarkeit zu arbeiten beginnt. Das führt uns zurück zu dem, was zuvor gesagt wurde: Ownership für Datenprodukte ist ein mächtiges Konzept. Es macht Datenprodukte nicht nur vertrauenswürdig; es ist auch die Kraft, die den Marktplatz aktuell hält.
Der Marktplatz löst außerdem eine der zentralen Spannungen von Datenprodukten als Teil der Bemühungen, den Fachlichkeiten mehr Macht zu geben: Föderierte Organisationen und Architekturen sind nicht vollständig dezentralisiert. Sie sollten ein klar definiertes Rückgrat haben. Viele Organisationen schieben Ownership und Erstellung von Datenprodukten zu Recht in die Fachlichkeiten, doch zwei Dinge müssen zentral bleiben: ein einziger Zugriffs- und Entdeckungspunkt (weil ein Marktplatz Skalierungsgesetzen folgt) und ein bestimmtes Set organisationsweiter Governance-Policies, die für alle veröffentlichten Produkte gelten. Der Marktplatz kann die natürliche Heimat für beides sein. Solche Marktplätze können Contracts bei der Veröffentlichung gegen organisationsweite Policies validieren und Zugriffsanfragen beim Konsum gegen dieselben Policies bewerten.
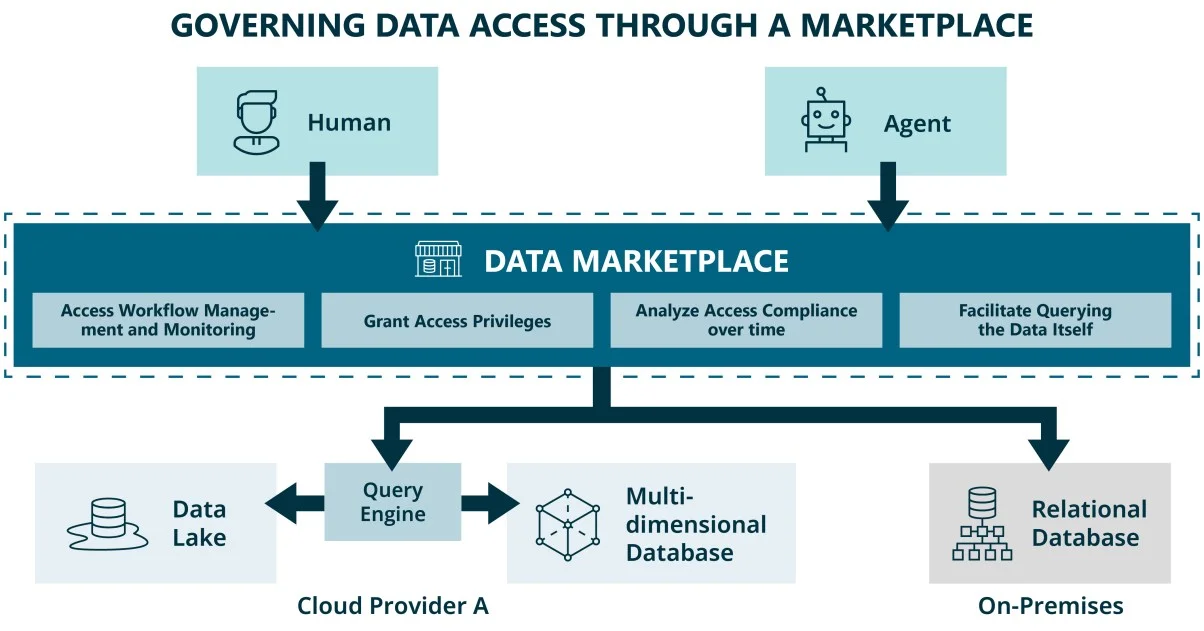
Zugriff gewährt ist nicht Zugriff governt
Marktplätze, die über die Entdeckung hinaus in die Bereitstellung von Zugriff reichen, gewinnen eine Fähigkeit, die klassischen Systemen fehlt: Sie können nicht nur erfassen, wer auf was zugegriffen hat, sondern auch warum. Diese letzte Dimension zu verfolgen (den Zweck des Datenkonsums) fehlt in klassischer Zugriffskontrolle typischerweise, ist aber die Voraussetzung, um Datenzugriff im großen Maßstab zu automatisieren.
In den meisten Organisationen funktioniert Datenzugriff wie ein RFID-Ausweis: Berechtigungen häufen sich an und verfallen oder werden selten widerrufen. Drei Jahre nach dem Wechsel vom Fertigungsteam ins Engineering-Büro kannst du die Shopfloor-Tür möglicherweise immer noch um 3 Uhr morgens an einem Samstag öffnen.
Stell dir zum Beispiel einen großen Konzern vor, der Daten über den Customer Lifetime Value hat. Ein Data Scientist erhält Zugriff, um ein Modell zur Priorisierung im Vertrieb zu bauen. Es funktioniert wirklich gut. Dann bittet ein Kollege aus dem Marketing darum, dieselben CLV-Daten für die Kampagnensegmentierung zu nutzen. Der Data Scientist teilt sie informell, ohne eine neue Zugriffsanfrage. Die Daten werden nun für einen Zweck verwendet, für den sie nie freigegeben wurden.
Bei menschlichen Analysten erzeugen informelle Signale, Review-Prozesse und professionelles Urteilsvermögen eine gewisse natürliche Reibung gegen Nutzung ohne Erlaubnis und gegen offensichtlichen Missbrauch. KI-Agenten handeln ohne moralisches Urteil und ohne diese Reibung. Der Versuch, ihnen solche Skrupel einzubauen, gelingt nie zu 100 %.
Die Konsequenz: Organisationen müssen die Daten selbst schützen. Sie können das Gewähren von Zugriff nicht länger als das Ende der Governance betrachten. Klassische Zugriffskontrolle ist eine punktuelle Entscheidung: Eine Anfrage trifft ein, der Anfragende nennt einen Zweck, und das System gewährt oder verweigert den Zugriff. Einmal gewährt, lautet die Annahme, dass die Nutzung im deklarierten Rahmen bleibt. Bestenfalls wird der Zugriff alle paar Jahre einmal überprüft.
Zurück zum Beispiel, aber jetzt tauschen wir den Data Scientist gegen einen KI-Agenten. Dasselbe CLV-Datenprodukt und derselbe deklarierte Zweck: Vertriebspriorisierung. Drei Monate später beginnt der Agent, die Daten zu nutzen, um ein Risikomodell zu speisen, das die Frage steuert, ob ein Kunde per Rechnung kaufen kann oder im Voraus zahlen soll. Auch wenn es betriebswirtschaftlich Sinn ergeben mag, ist das eindeutig ein anderer Zweck, der weder deklariert noch genehmigt wurde. In einem Compliance-Audit kann niemand erklären, warum der Agent Kundendaten außerhalb seines ursprünglichen Rahmens verarbeitet hat.
Wenn ein Agent auf Daten zugreifen kann, die er für einen bestimmten Zweck nicht nutzen sollte, wird er es irgendwann tun. Murphy hatte keine Ahnung, dass er gerade Data-Governance-Policy schrieb!
Die Lösung besteht nicht darin, Zugriffsdefinitionen häufiger zu überprüfen. Sie besteht darin, die Governance-Logik zu verlagern: von Zugriff als einmaliger Freigabe hin zu Zugriff als kontinuierlich durchgesetztem Zustand. Ein Datenmarktplatz hält sowohl den Contract als auch den Kontext, um zu bewerten, ob eine bestimmte Query im Rahmen ist. Er kann auch sichtbar machen, ob die in einem Data Contract zugesicherten Garantien tatsächlich eingehalten werden. Das macht ihn zum natürlichen Ort, um das "Warum" hinter jeder Zugriffsfreigabe festzuhalten und Compliance durchzusetzen, wenn Queries vom deklarierten Zweck abweichen.
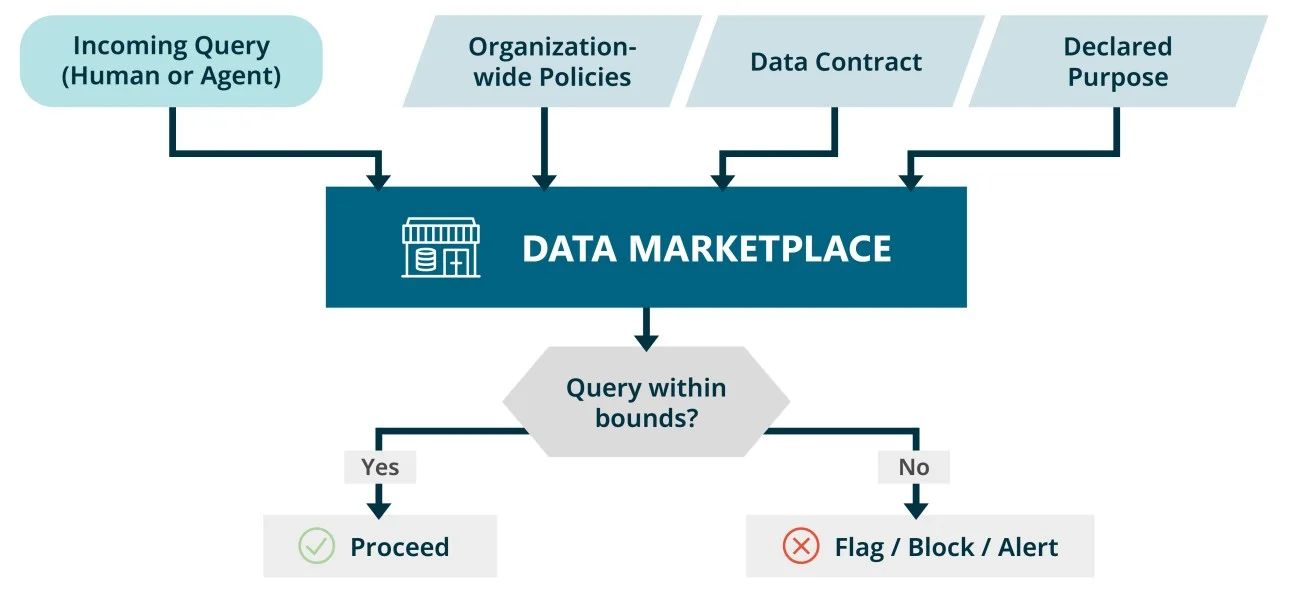
Datenzugriff zu governen ist ein Teil des viel größeren Puzzles namens AI Governance. Diese Disziplin umfasst außerdem Modellverhalten, Output-Qualität, Erklärbarkeit, Observability, menschliche Aufsicht, ethische Nutzung, Risikomanagement und regulatorische Compliance, um nur einige zu nennen. Und selbst innerhalb der Datendimension ist Zugriffskontrolle nicht die ganze Geschichte: Denk nur an Bias, Einwilligung, Aufbewahrungs-Policies usw. Dieser Artikel konzentriert sich auf die Governance eines sehr wichtigen Aspekts: den Datenzugriff von Agenten.
Vier Maßnahmen für den Start
Der Weg nach vorn ist kein Big-Bang-Marktplatz-Rollout, sondern vielmehr eine organisatorische Transformation, getragen davon, ein Datenprodukt nach dem anderen auf den Marktplatz zu bringen und ein Team nach dem anderen davon zu überzeugen, dass es die Mühe wert ist.
In Kultur investieren
Ownership von Datenprodukten gehört ins Business. Baue Datenkompetenz und Verantwortlichkeit parallel zur Infrastruktur auf.
Einen engen Piloten fahren
Viele Marktplatz- und Katalog-Initiativen scheitern, weil ihr Scope am Anfang zu breit ist. Wir haben beobachtet, dass es für die meisten Initiativen am vielversprechendsten ist, mit einer Domäne zu starten, die zur Zusammenarbeit bereit ist, und eine gemeinsame Erfolgsgeschichte zu schaffen (z. B. indem gezeigt wird, dass agentische KI mehr Erfolg hat, wenn Fachlichkeiten die Extrameile gehen und ihre Datenprodukte auf dem Marktplatz registrieren).
Für Agenten designen
Optimiere Metadaten so, dass Agenten das passendste Datenangebot schnell finden. Das kann bedeuten, Industriestandards wie ODCS für Data Contracts zu folgen, aber auch KI-Anweisungen pro Datenprodukt, Synonyme und Links zu tieferer Semantik hinzuzufügen.
Bring deine Daten unter Contract
Starte mit Data Contracts auf deinen kritischsten Datendomänen. Schon ein Contract pro Domäne verändert das Governance-Gespräch und schafft die Grundlage für "automatisierte Policy-Durchsetzung": die Möglichkeit, Governance zu automatisieren, weil deterministische Algorithmen und/oder LLMs entscheiden können, ob eine Handlung eines Menschen oder eines Agenten konform ist oder im Widerspruch zu dem Contract und den Policies steht, die gelten.
Organisationen, die in Dateninfrastruktur investieren, aber Datenmarktplätze, Contracts und Product Thinking vernachlässigen, werden feststellen, dass ihre KI-Agenten dasselbe Vertrauensdefizit erben, das menschliche Analysten seit Jahren plagt. Die Infrastruktur für Analytics auf Menschenniveau und für Automatisierung auf Agentenniveau ist in ihrem Fundament dieselbe. Die Konsequenzen, es falsch zu machen, sind es nicht.
Über Entropy Data
Entropy Data bietet einen Datenprodukt-Marktplatz, durchgesetzt mit Data Contracts, der sowohl für menschliche Analysten als auch für KI-Agenten funktioniert.
Er baut auf offenen Standards auf und unterstützt nativ den Open Data Contract Standard (ODCS), den Open Data Product Standard (ODPS) und den Open Semantic Interchange (OSI), und wir tragen aktiv zu diesen Standards bei, um sie noch besser zu machen. Zusammen machen diese Standards Datenprodukte auffindbar, kontextualisiert mit Business-Semantik und zugänglich über automatisierte Zugriffs-Workflows, und sie machen die Qualitätssignale sichtbar, die Consumers brauchen, um dem zu vertrauen, was sie finden. Die Contracts selbst werden von unserer populären Open-Source Data Contract CLI durchgesetzt.
Drei Bausteine treiben das an:
Marketplace
Übernimmt Self-Service-Entdeckung und -Zugriff, wobei Entropy Intelligence natürlichsprachige Fragen über Datenprodukte und ihre Daten hinweg beantwortet.
Studio
Lässt Teams Datenprodukte contract-first entwerfen (sogar aus einer simplen Excel-Vorlage), sie mit dem Data Product Builder unter Einsatz von KI-Coding-Agenten bauen und ihre Nutzung überwachen.
Governance
Setzt organisationsweite Policies und zweckbasierte Zugriffskontrolle durch, sodass jede Freigabe und jede Query innerhalb ihres deklarierten Zwecks bleibt.
Zusammen geben sie Agenten einen vertrauenswürdigen Einstiegspunkt über API und das Model Context Protocol (MCP) und geben Menschen einen Marktplatz, auf den sie sich verlassen können.
Entropy Data integriert sich mit allen großen Datenplattformen und ist als EU-basiertes SaaS, Bring Your Own Cloud oder On-Prem-Deployment verfügbar.
Entropy Data ist ISO 27001 zertifiziert und wird von großen Unternehmen in mehreren Branchen wie Logistik, Pharma, Medien und Telekommunikation sowie über mehrere Regionen hinweg, darunter die USA, Australien, die Schweiz und die EU, produktiv eingesetzt. Das zeigt, dass unser contract-durchgesetzter Datenprodukt-Marktplatz weit über die Pilotphase hinaus skaliert.
Über BARC
BARC ist das führende Analystenhaus für Data & Analytics, KI, Corporate Performance Management (CPM) und ESG mit einem Ruf für unvoreingenommene und vertrauenswürdige Beratung. Unsere Expert-Analysten liefern ein breites Spektrum an Research, Events und Beratungsleistungen für die Data-&-Analytics-Community. Unsere innovative Forschung bewertet Software, Anbieter und Dienstleister rigoros und beleuchtet Markttrends, um Erkenntnisse zu liefern, die es unseren Kunden ermöglichen, mit Daten, Analytics und KI zu innovieren. BARCs 25 Jahre Erfahrung mit Datenstrategie & -kultur, Datenarchitektur, Organisation und Softwareauswahl helfen Kunden, sich in wahrhaft datengetriebene Organisationen zu transformieren.
Gib deinen Agenten einen Marktplatz, dem sie vertrauen können
Sieh, wie Entropy Data Datenprodukte und Data Contracts in einen governten Marktplatz für Menschen und KI-Agenten gleichermaßen verwandelt.
Fußnoten
- BARC-Umfrage "Data Mesh and Data Fabric" 2024, Stichprobengrößen: Für die Umfrage insgesamt n=197, für die zitierten Fragen: n=197 ↩
- "Data Consumers" ist schlicht ein Begriff für Menschen, die Daten brauchen, um ihre Arbeit zu erledigen ↩
- Aspirin® ist eine eingetragene Marke der Bayer AG. Dieser Report ist unabhängig und steht in keiner Verbindung zu Bayer und wird nicht von Bayer unterstützt. ↩
- BARC-Umfrage "Data Mesh and Data Fabric" 2024, Stichprobengrößen: Für die Umfrage insgesamt n=197, für die zitierten Fragen: n=121 ↩
BARC Spotlight: A Data Marketplace Is What Your Agents Need © BARC 2026. Mit Genehmigung wiedergegeben. Bereitgestellt von Entropy Data.