Wissen
Was ist ein Datenprodukt?
Ein Datenprodukt bietet Zugriff auf gemanagte Daten und hat eine klare Ownership.
Datenprodukt vs. Data as a Product
Der Begriff Product stammt aus dem Ansatz des Product Thinking, der in den letzten Jahren Einzug in die Softwareentwicklung gehalten hat. Zhamak Dehghani hat den Begriff im zweiten Kernprinzip von Data Mesh aufgegriffen: Data as a Product. Das bedeutet, dass Software, oder jetzt Daten, immer aus Sicht der Consumers gestaltet wird, damit sie die beste User Experience erhalten. Wie bei einem physischen Produkt sollten Daten konsequent für die Bedürfnisse der Consumers entwickelt werden. Sie werden den Usern verständlich erklärt (intuitiv oder über eine Bedienungsanleitung), so optimiert, dass sie leicht zugänglich sind, und vielleicht auch innerhalb der Organisation beworben, um ihr Potenzial zu zeigen. Und konsequenterweise können sie auch einen Preis haben, den Consumers zu zahlen bereit sind. Daten gelten heute als wertvoll für das Unternehmen und sind nicht länger nur ein Nebenprodukt der Softwareentwicklung.
Der Begriff Datenprodukt ist vom Data-as-a-Product-Prinzip abgeleitet und folgt dessen Ideen, ist aber nicht synonym zu verstehen. Versuchen wir eine Definition:
Ein Datenprodukt ist eine logische Einheit, die alle Komponenten zum Verarbeiten und Speichern von Domänendaten für analytische oder datenintensive Use Cases enthält und sie anderen Teams über Output Ports zur Verfügung stellt.
Ein Datenprodukt ist also etwas Technisches, das von Data Product Developern implementiert wird. Es nutzt Datentechnologien, um große Datenmengen zu speichern und zu verarbeiten, oft Millionen von Einträgen oder mehr. Die Größe eines Datenprodukts wird so gewählt, dass es zusammenhängende fachliche Konzepte oder Use Cases abdeckt, die für sich genommen einen Mehrwert bieten. Die maximale Größe ergibt sich aus dem, was ein Team handhaben kann. Datenprodukte lassen sich grob mit Microservices oder Self-Contained Systems vergleichen, nur eben mit Datentechnologien und für analytische Anforderungen. Trotz des Begriffs Product sind Data Product Consumers in der Regel andere interne Teams, nicht externe Kunden.
Beispiele für Datenprodukte
- Das Team Product Search bietet ein Datenprodukt Search Queries mit allen Suchanfragen, die Users in die Suchleiste eingegeben haben, der Anzahl der Treffer und Informationen über den Eintrag, den der User angeklickt hat.
- Das Team Article Management bietet ein Datenprodukt Articles mit den Stammdaten der Artikel, sowohl im aktuellen Zustand als auch in der Historie.
- Das Team Checkout bietet ein Datenprodukt Orders mit allen Bestellungen seit 2020. Es hat zwei Output Ports: einen mit personenbezogenen Daten (PII) und einen mit PII-Redaction.
- Das Team Fulfillment hat ein Datenprodukt Shelf Warmers mit allen Artikeln, die in den letzten 3 Monaten nicht verkauft wurden.
- Das Team Management Support nutzt andere Datenprodukte, um ein Realtime Business Dashboard-Data-Product für den CEO zu erstellen. Es teilt keine Daten und hat keine Output Ports.
- Das Team Recommendations nutzt andere Datenprodukte, um ein ML-Modell für Empfehlungen zu trainieren. Das ML-Modell wird als Tensorflow-SavedModel-Verzeichnis auf einem Object Store geteilt. Das Marketing-Team nutzt dieses Modell, um kundenspezifische Empfehlungen im Newsletter zu erstellen.
Interne Komponenten eines Datenprodukts
Aus Engineering- und Plattformsicht hat ein Datenprodukt mehrere Komponenten, die zusammen eine kohärente Einheit bilden. Das folgende Diagramm zeigt typische Komponenten eines Datenprodukts: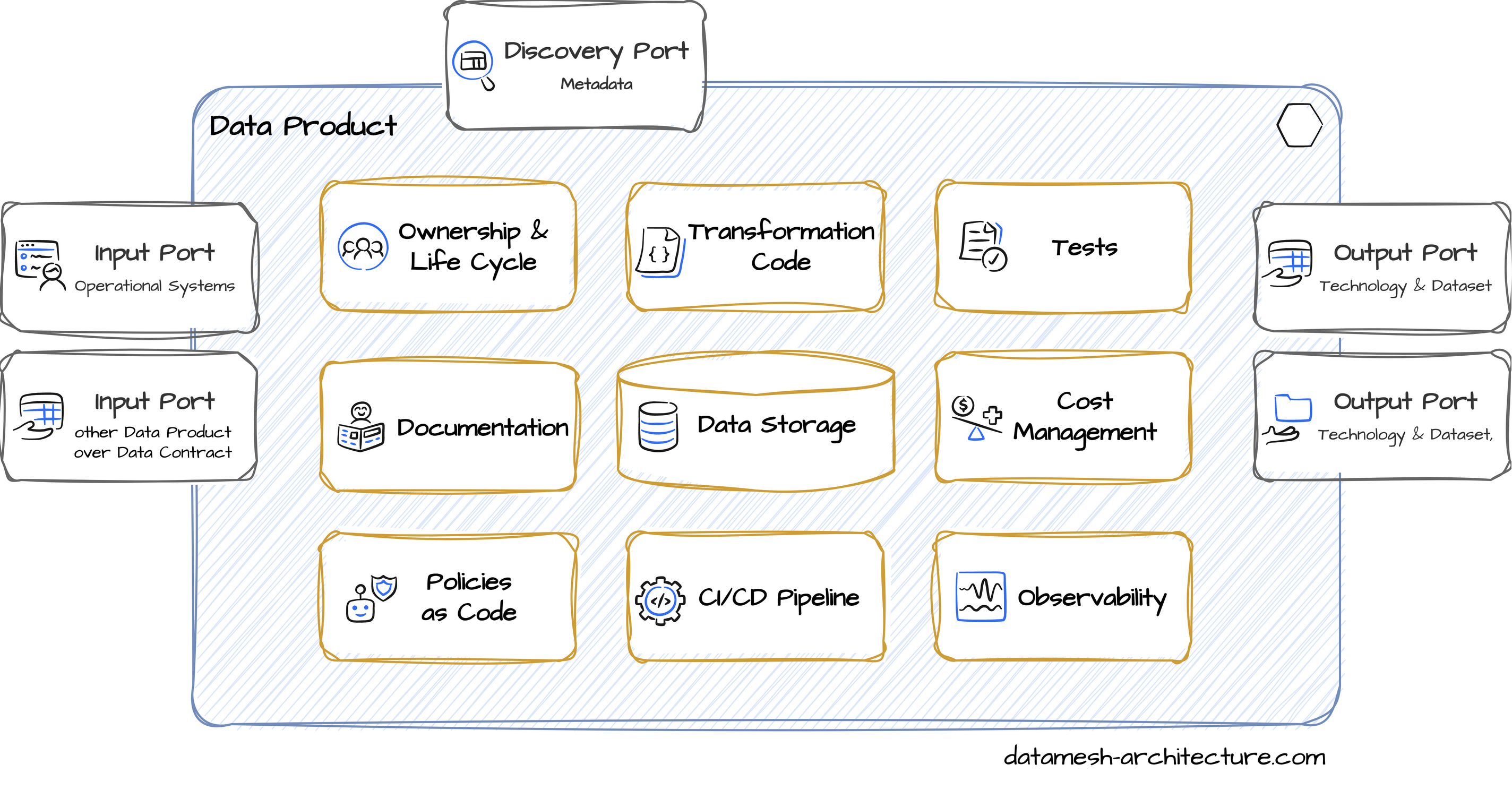 Ein Datenprodukt folgt dem Designprinzip des Information Hiding. Es gibt Schnittstellen nach außen und interne Komponenten.
Die konkrete Implementierung der Komponenten kann je nach Use Case und Datenplattform variieren.
Ein Datenprodukt folgt dem Designprinzip des Information Hiding. Es gibt Schnittstellen nach außen und interne Komponenten.
Die konkrete Implementierung der Komponenten kann je nach Use Case und Datenplattform variieren.
Output Ports
Output Ports stellen die Haupt-API eines Datenprodukts dar: Sie bieten lesenden Zugriff auf strukturierte Datensätze in Form von Tabellen, Dateien oder Topics. Ein Datenprodukt kann mehrere Output Ports haben: Sie können denselben Datensatz in unterschiedlichen Technologien oder unterschiedliche Datensätze in derselben Technologie bereitstellen, zum Beispiel einen Output Port mit PII-Daten und einen zweiten mit PII-Redaction. Ein neuer Output Port kann auch hinzugefügt werden, wenn eine strukturelle Änderung notwendig ist, um ein Datenprodukt über die Zeit weiterzuentwickeln.
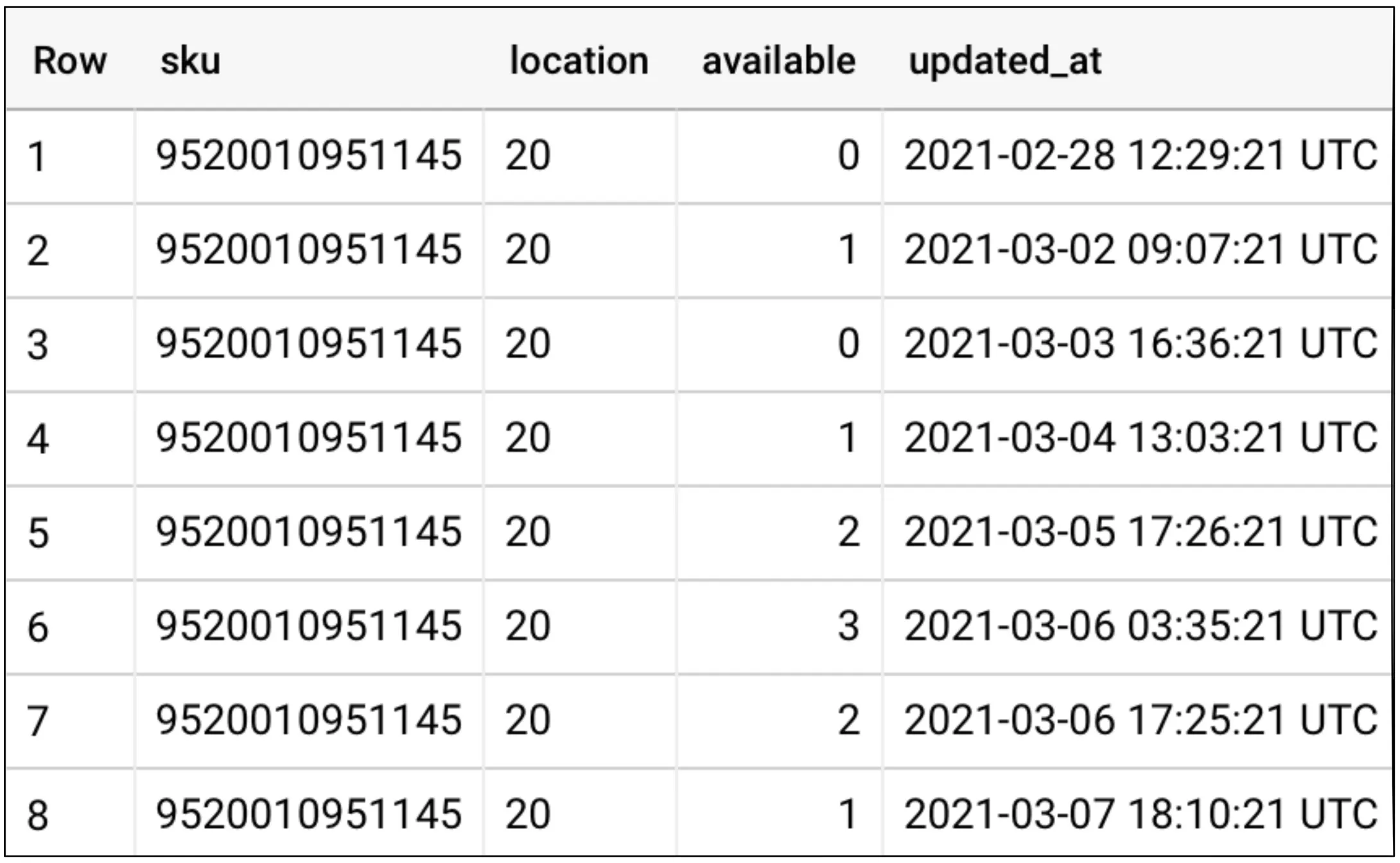
Die primäre Schnittstellentechnologie für einen Output Port ist SQL. Sie ermöglicht einfachen Zugriff auf große Datenmengen und wird von praktisch allen Analysewerkzeugen unterstützt. Ein Output Port wird oft als SQL View als Abstraktionsschicht implementiert, damit sich die zugrunde liegende Datenstruktur ändern lässt, ohne die Data Consumers zu beeinträchtigen. Weitere Schnittstellentechnologien für Output Ports sind Dateien oder Topics für Stream Processing oder als asynchrone API zu operativen Systemen.
Output Ports definieren das Modell des bereitgestellten Datensatzes. Dieses Modell wird in einem Schema mit allen Tabellen, Attributen und Typen definiert. Typische Technologien sind SQL DDL, dbt models, Protobuf, Avro oder JSON Schema. Das Modell kann auch in einem Datenkatalog-Eintrag beschrieben werden.
models:
- name: stock_last_updated_v1
description: >
Current state of the stock.
One record per SKU and location with the last updated timestamp.
columns:
- name: sku
type: string
description: Stock Keeping Unit (SKU), the business key of an article.
tests:
- not_null
- name: location
type: string
description: The ID of the warehouse location.
tests:
- not_null
- name: available
type: number
description: The number of articles with this SKU that are available at this location.
tests:
- not_null
- dbt_utils.expression_is_true:
expression: "col_a >= 0"
- name: updated_at
type: timestamptz
description: The business timestamp in UTC when the available was changed.
tests:
- not_nullOutput Ports sind optional oder können privat sein, wenn ein Datenprodukt nur teaminterne analytische Use Cases bedient.
Der Zugriff auf Output Ports wird über Data Contracts geregelt.
Input Ports
Ein Datenprodukt kann zwei Arten von Datenquellen haben: operative Systeme oder andere Datenprodukte.
Teams, die die operativen Systeme entwickeln, stellen auch ihre relevanten Domänendaten in Datenprodukte zur Verfügung. Oft geschieht das über asynchrone Topics, idealerweise unter Verwendung definierter Domain Events. Letztlich entscheidet das Domain-Team aber selbst, wie die Domänendaten in seine Datenprodukte eingespeist werden.
Datenprodukte können auch andere Datenprodukte über deren Output Port nutzen, sobald ein Data Contract vereinbart ist. Diese können demselben Team oder anderen Teams gehören. Typisch ist das für consumer-aligned Datenprodukte oder aggregierte Datenprodukte, aber auch source-aligned Datenprodukte können andere Domänendaten verlinken, wenn das sinnvoll ist, zum Beispiel, um Stammdaten nachzuschlagen.
Discovery Port
Data Consumers müssen die Datenprodukte finden können, die für sie relevant sind. Da Daten in der Regel eine domänenspezifische Bedeutung haben, ist es wichtig, eine ausführliche Beschreibung der Semantik des Datenmodells bereitzustellen.
Weitere Metadaten wie Kontaktinformationen, Reifegrad, Nutzung des Datenprodukts durch andere, Datenqualitätstests und Service-Level-Objectives sind für Data Consumers wichtig, damit sie entscheiden können, ob ein Datenprodukt vertrauenswürdig und für ihren Use Case geeignet ist.
Es ist gute Praxis, Metadaten automatisch über CI/CD-Pipeline-Schritte in einen Datenkatalog und das Datenprodukt-Inventar zu publizieren, zum Beispiel in Entropy Data.
Ownership
Ein Datenprodukt wird von einem einzigen Team entwickelt und gepflegt, das die fachliche Domäne, die Geschäftsprozesse und die Daten versteht. Das Team ist dafür verantwortlich, die zugesagte Datenqualität und die Service-Level-Objectives bereitzustellen. Ein Datenprodukt hat eine eigene Kontaktperson, den Product Owner des Teams, der letztverantwortlich für das Datenprodukt und dessen Qualität ist.
Der Product Owner ist verantwortlich für den Lebenszyklus und die Weiterentwicklung eines Datenprodukts und berücksichtigt dabei die Anforderungen der (potenziellen) Consumers sowie die domäneninternen analytischen Bedürfnisse. Er oder sie legt auch den Preis fest, der für die Nutzung des Datenprodukts in Rechnung gestellt wird.
Transformation Code
Daten müssen bereinigt, aggregiert, zusammengeführt und transformiert werden, um das Schema des Output Ports zu erfüllen oder analytische Fragestellungen zu beantworten.
Welche Technologie genutzt wird und wie der Code intern organisiert ist, sind Implementierungsdetails eines Datenprodukts. Sie hängen von der Datenplattform ab und werden vom Entwicklungsteam entschieden.
In vielen Fällen kommen SQL-Queries für einfache Transformationen zum Einsatz und Apache Spark für komplexe Pipelines.
Ein Scheduling- und Orchestrierungstool wie Airflow wird genutzt, um den Transformation Code auszuführen.
Data Storage
Ein Datenprodukt muss in der Regel eine erhebliche Datenmenge in einer Form von Speicher ablegen, etwa als Tabellen oder Dateien in einem Object Store. Data Storage wird als Self-Service über die Datenplattform bereitgestellt. Ein Datenprodukt hat seinen eigenen privaten Bereich, der von anderen Datenprodukten isoliert ist.
Welche Technologie genutzt wird und wie Daten intern organisiert sind, sind Implementierungsdetails eines Datenprodukts. Sie hängen von der Datenplattform ab und werden vom Entwicklungsteam entschieden. In vielen Fällen kommen spaltenorientierte Speichertechnologien zum Einsatz.
Tests
Datenprodukte stellen gemanagte und qualitativ hochwertige Datensätze bereit, daher sind Tests, wie in jeder anderen Software-Engineering-Disziplin, essenziell. Es gibt verschiedene Testarten:
Unit-Tests testen den Transformation Code selbst. Sie verwenden feste Eingabedaten und definieren die erwarteten Ausgabedaten.
Expectation-Tests laufen während des Deployments auf den realen Datenmodellen und verifizieren, dass die Quelldaten der Input Ports, die Zwischenmodelle und der Output Port die definierten Erwartungen erfüllen.
Qualitätstests laufen regelmäßig auf den realen Daten, um die Service-Level-Objectives zu überwachen.
Dokumentation
Wenn Domänendaten mit anderen Teams geteilt werden, ist es wichtig, die Semantik der Daten und den fachlichen Kontext ihrer Entstehung zu beschreiben.
Neben einer Beschreibung der Attribute des Datenmodells gibt eine gute Dokumentation auch eine Einführung dazu, was vom Datensatz zu erwarten ist, und erste Hinweise, welche Daten interessant sein können und wie man auf sie zugreift.
Ein guter Weg, Dokumentation zu implementieren, ist die Bereitstellung eines interaktiven Notebooks (Jupyter, Google Colab, Databricks Notebook) mit Beispiel-Queries.
Cost Management
Datentechnologien werden schnell teuer, wenn sie in großem Maßstab eingesetzt werden. Deshalb ist es wichtig, die Kosten von Datenprodukten zu überwachen. Sie können die Grundlage für den Preis bilden, der Data Consumern in Rechnung gestellt wird, wie in den Data Contracts vereinbart.
Policies as Code
Globale Policies sind die Spielregeln im Data Mesh, definiert von der föderierten Governance-Gruppe, etwa Namenskonventionen, Klassifizierungsschemata für Daten oder Zugriffskontrolle.
Die meisten Policies sollten auf Ebene der Datenplattform umgesetzt werden, einige müssen jedoch auf Ebene des Datenprodukts konfiguriert werden, vor allem, wenn Domänenwissen erforderlich ist oder Product Owner über Berechtigungen entscheiden müssen. Beispiele sind die spaltenbezogene Klassifizierung von Domänendaten, PII-Tagging und Zugriffskontrolle.
CI/CD-Pipeline und Scheduling
Ein Datenprodukt hat seine eigene CI/CD-Pipeline und Infrastruktur-Ressourcendefinitionen. Die CI/CD-Pipeline wird ausgelöst, wenn sich der Transformation Code oder das Datenmodell ändert; Tests werden ausgeführt, und das Datenprodukt wird im Einklang mit den globalen Policies auf der Datenplattform deployed. Das Datenplattform-Team kann Module oder Templates für die Datenprodukt-Teams bereitstellen.
Ein Scheduling- und Orchestrierungstool wie Airflow wird verwendet, um Transformation Code und Tests auszuführen.
Observability
Ein Datenprodukt kann weitere Ports und Fähigkeiten haben, die nicht direkt von Data Consumern genutzt werden, aber für den Betrieb des Datenprodukts wichtig sind. Dazu gehören Ports für Monitoring, Logging und Admin-Funktionen.
Open Data Product Standard
Inzwischen gibt es einen Industriestandard zur Definition von Datenprodukten: den Bitol Open Data Product Standard (ODPS). Es handelt sich um eine YAML-basierte Spezifikation, die in Kombination mit ihrem Pendant, dem Open Data Contract Standard (ODCS), genutzt werden kann.
apiVersion: "v1.0.0"
kind: "DataProduct"
id: "shelf-warmers"
name: "Shelf Warmers"
status: "active"
description:
purpose: "A list of articles with no sales in last 6 months"
team:
name: "fulfillment"
tags:
- "demo"
outputPorts:
- name: "snowflake_fulfillment_shelf_warmers"
version: "1"
description: "A list of articles with no sales in last 6 months"
type: "snowflake"
contractId: "snowflake_fulfillment_shelf_warmers"
authoritativeDefinitions:
- type: "Snowflake WebUI"
url: "https://example.com"
customProperties:
- property: "platformRole"
value: "op_shelf_warmers_snowflake_fulfillment_shelf_warmers_role"
- property: "status"
value: "active"
- property: "autoApprove"
value: true
- property: "containsPii"
value: false
- property: "server"
value:
schema: "SHELF_WARMERS"
account: "lmtabcd-xn12345"
database: "FULFILLMENT_DB"
- property: "environment"
value: "prod"
- name: "s3_fulfillment_shelf_warmers"
version: "1"
description: "A list of articles with no sales in last 6 months"
type: "s3"
contractId: "snowflake_fulfillment_shelf_warmers"
authoritativeDefinitions:
- type: "AWS Console"
url: "https://example.com"
customProperties:
- property: "platformRole"
value: "op_shelf_warmers_s3_fulfillment_shelf_warmers_role"
- property: "status"
value: "active"
- property: "autoApprove"
value: true
- property: "containsPii"
value: false
- property: "server"
value:
location: "s3://my-bucket"
- property: "environment"
value: "prod"
customProperties:
- property: "platformRole"
value: "dp_shelf_warmers_role"
- property: "type"
value: "consumer-aligned"
Eine formale Datenprodukt-Spezifikation kann als Grundlage für Automatisierung dienen und Metadaten für andere Systeme bereitstellen, etwa einen Datenkatalog oder einen Datenprodukt-Marktplatz.
Implementierung eines Datenprodukts
Schauen wir uns nun ein Beispiel an, wie ein konkretes Datenprodukt implementiert werden kann. Je nach Datenplattform gibt es unterschiedliche Wege, ein Datenprodukt umzusetzen:
- Databricks: ein Datenprodukt sollte als Databricks Asset Bundle implementiert werden
- Snowflake: ein Datenprodukt ist typischerweise ein dbt-Projekt
- BigQuery: ein Datenprodukt ist typischerweise ein dbt-Projekt
- AWS S3 und Athena: ein Datenprodukt wird häufig als Terraform-Projekt verwaltet
- Kafka: ein Java-Projekt
In diesem Beispiel verwenden wir einen AWS S3 und Athena Tech Stack. Das Datenplattform-Team stellt ein Terraform-Modul bereit, das alle notwendigen Services auf der Datenplattform provisioniert, um ein Datenprodukt im Einklang mit den von der Governance-Gruppe definierten Policies und Konventionen zu betreiben.
Die Data Product Developers haben pro Datenprodukt ein Git-Repository. Sie nutzen das bereitgestellte Terraform-Modul und konfigurieren es für ihr Datenprodukt. Im selben Repository definieren sie den Transformation Code als SQL-Query sowie eine JSON-Schema-Datei mit dem Modell des Output Ports und einer detaillierten Beschreibung des Datenmodells.
# dataproduct.tf
module shelf_warmers {
source = "git@github.com:datamesh-architecture/terraform-dataproduct-aws-athena.git"
version = "0.2.1"
domain = "fulfillment"
name = "shelf_warmers"
description = "Shelf warmers are products that are not selling for 3 months and are taking up space on the shelf."
schedule = "0 0 * * ? *" # Run at 00:00 am (UTC) every day
transform = {
query = "sql/transform.sql"
}
output = {
format = "PARQUET"
schema = "schema/shelf_warmers.schema.json"
roles_allowed = ["coo"] # Policy as code
}
}
Mit terraform apply, das in der Regel über die CI/CD-Pipeline ausgelöst wird, werden alle benötigten Ressourcen provisioniert, etwa S3-Buckets, AWS-Athena-Ressourcen und Lambda-Funktionen.
Außerdem werden Berechtigungen in AWS IAM erstellt.
Die Pipeline pusht außerdem Metadaten in den Datenkatalog und das Datenprodukt-Inventar.
Ein Beispiel für die Implementierung eines Terraform-Moduls findest du auf GitHub.
Entropy Data
Entropy Data ist eine Software, um Datenprodukte und Data Contracts zu verwalten und daraus einen leicht zu nutzenden Datenmarktplatz zu machen. Es nutzt den ODPS-Standard, um ein umfassendes Datenprodukt-Inventar aufzubauen. Datenprodukte lassen sich aus Datenplattformen und Datenkatalogen importieren, Metadaten können einfach über Web-UI, YAML-Editor, APIs und sogar Excel-Editoren angereichert werden. Data Consumers können das Datenprodukt-Inventar durchsuchen, die für sie relevanten Datenprodukte finden und Zugriff beantragen.
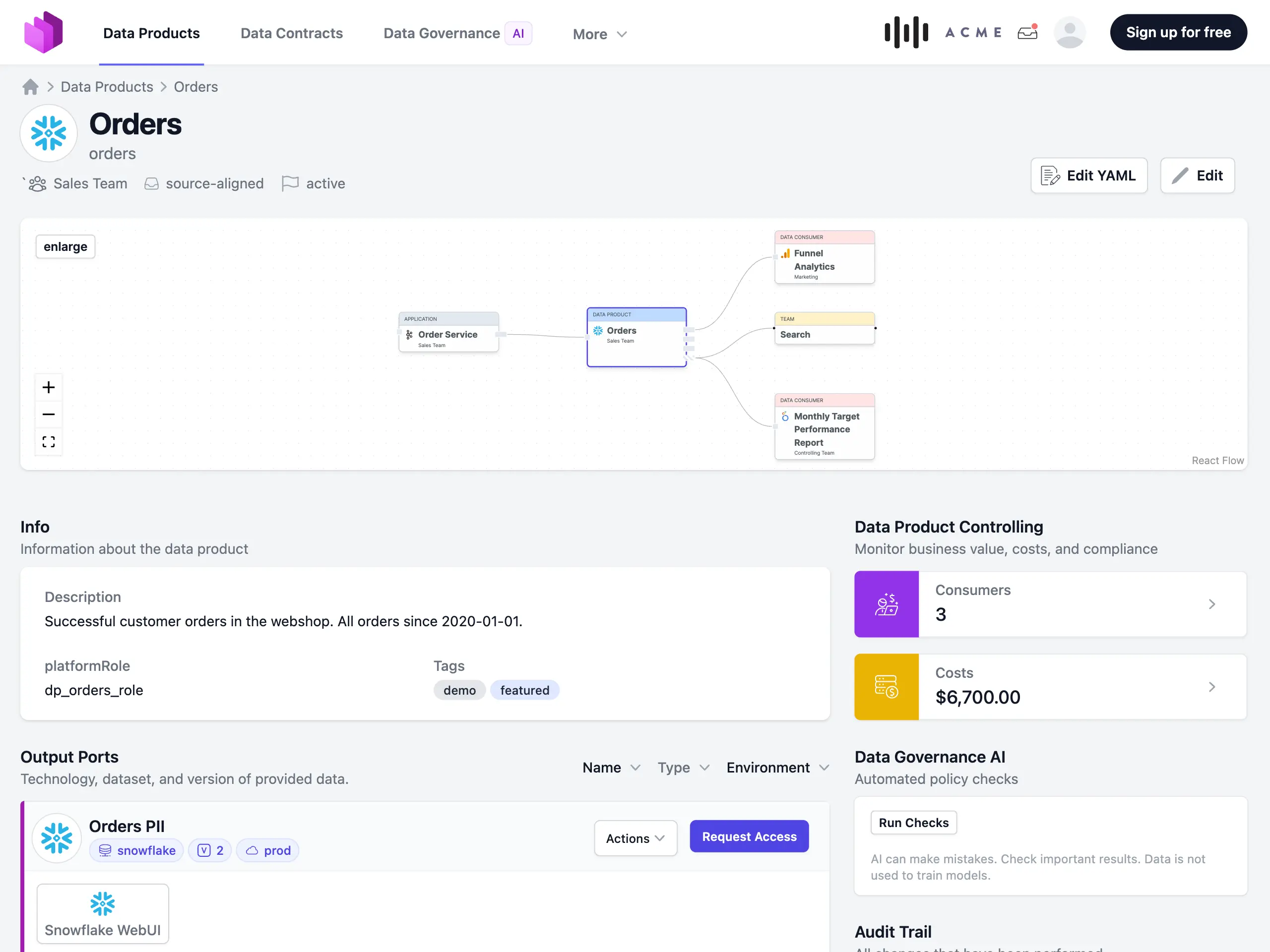
Über die REST-API integriert sich Entropy Data mit allen Datenplattformen und löst die automatische Erstellung von IAM-Berechtigungen in der Datenplattform aus, sobald ein Data Contract erstellt oder aktualisiert wird.
Jetzt kostenlos registrieren oder die klickbare Demo von Entropy Data erkunden.