Wissen
Vom Datenkatalog zum Datenmarktplatz
Klassische Datenkataloge sind seit langem die primäre Lösung für die Verwaltung von Data Assets. Ihre Wirksamkeit wird allerdings oft durch Überindexierung und fehlende Semantik- und Qualitätsgarantien begrenzt. Moderne Datenarchitekturen bauen auf Datenprodukte mit klarer Ownership, sauber definierten Data Contracts und einem Fokus auf die Bedürfnisse von Data Consumern. Diese werden in einem unternehmensweiten Datenmarktplatz gebündelt, um gemanagte Daten an andere Teams oder Organisationen weiterzugeben.
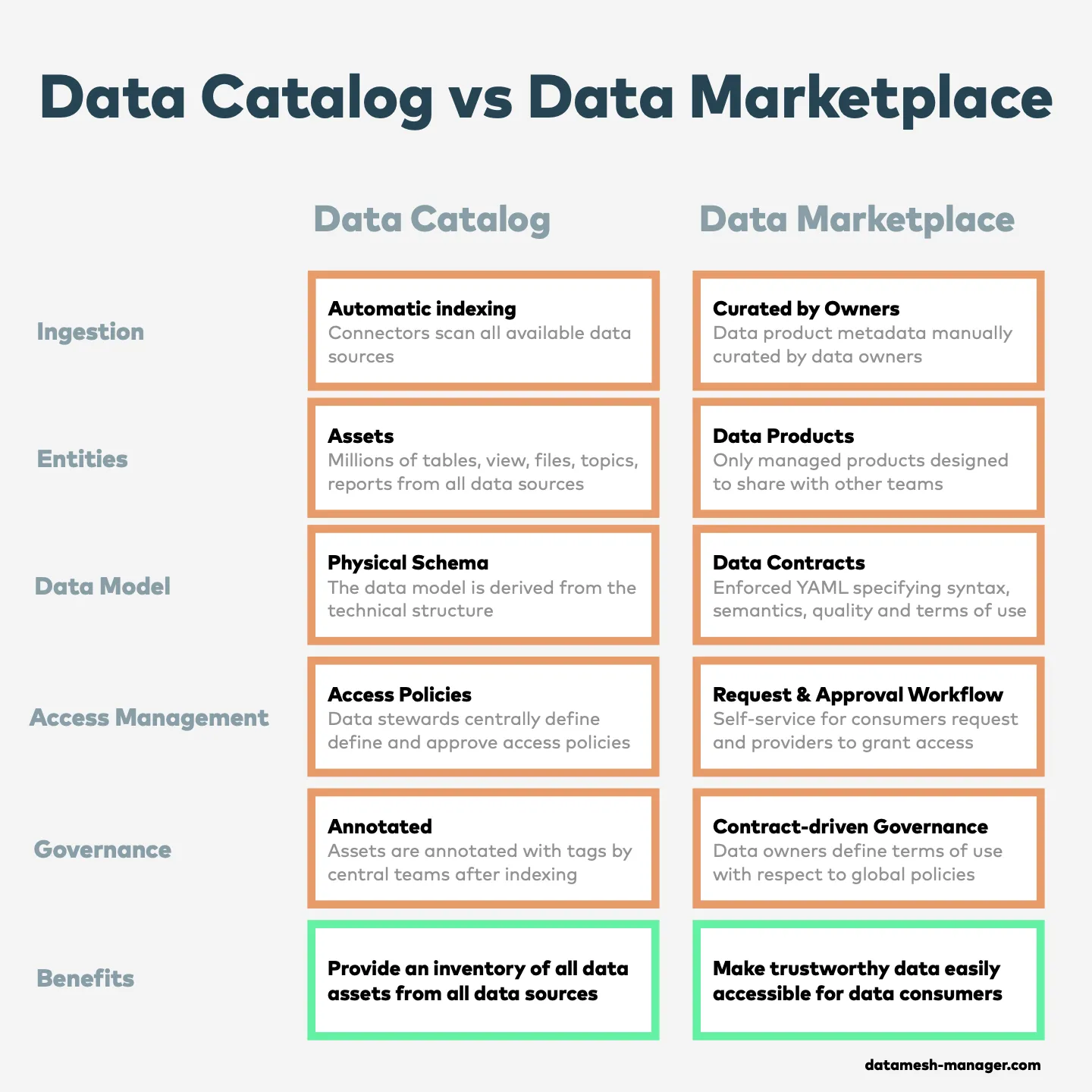
Datenkataloge: Data Assets indexieren
Datenkataloge sollen ein umfassendes Inventar der Data Assets einer Organisation bereitstellen und Fragen wie diese beantworten:
- Welche Daten gibt es?
- Wo liegen die Daten?
- Wie sieht das Schema der Daten aus?
- Welche statistischen Eigenschaften haben die Daten?
- Wie ist die Lineage der Daten?
- Wie werden die Daten genutzt?
Historisch waren Meta-Kataloge in Data-Lake-orientierten Architekturen notwendig, um die Datenstruktur in gespeicherten Dateien zu spezifizieren und sie für strukturierte Queries deserialisierbar und zugänglich zu machen (z. B. Hive Metastore, Project Nessie, Unity Catalog).
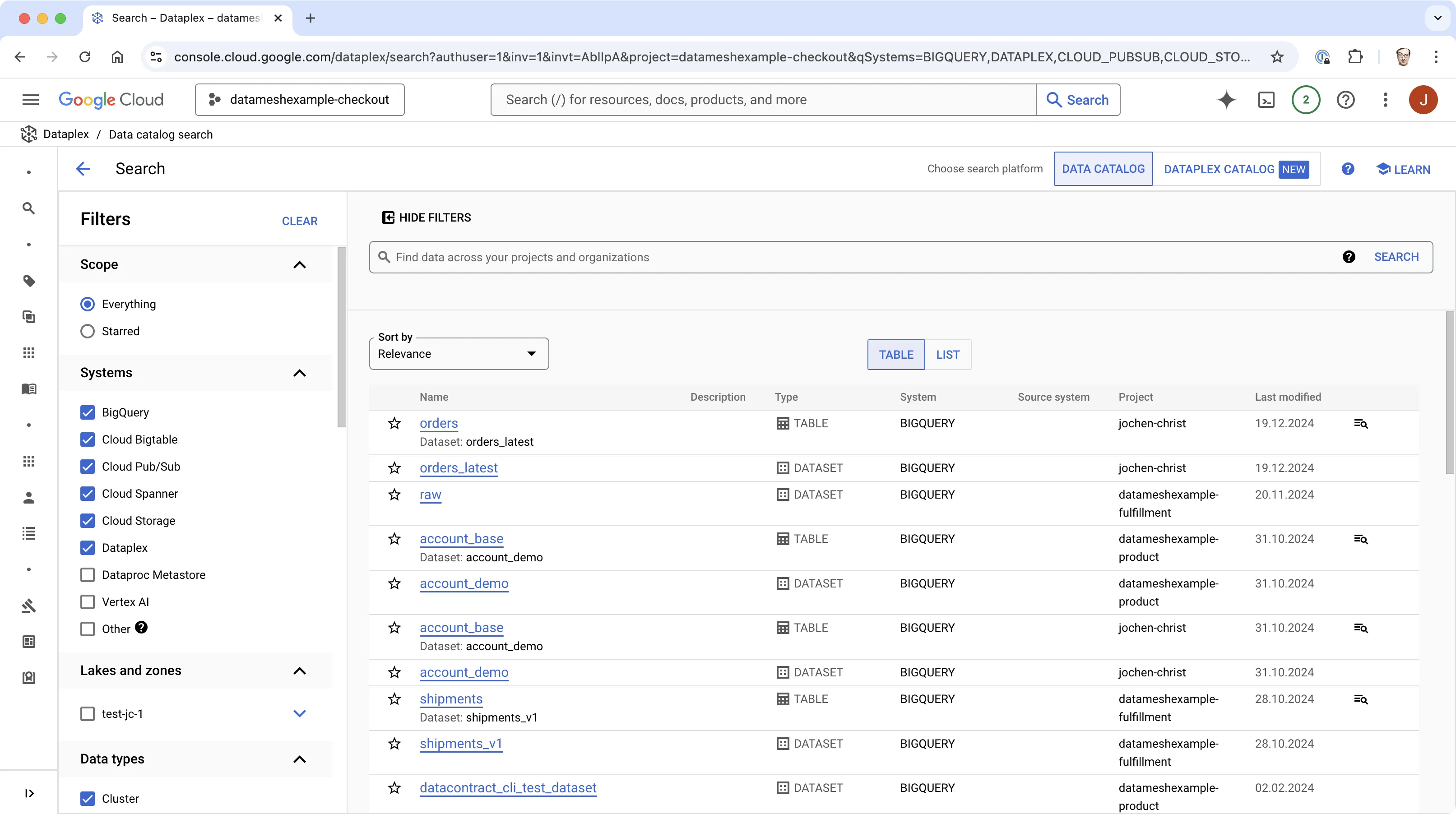
Über die Zeit wurden diese Lösungen um Discovery- und Governance-Funktionen zu vollwertigen Datenkatalogen ausgebaut. Heute werden Datenkataloge von allen großen Datenplattformen angeboten (AWS Glue Catalog, Google Dataplex Catalog, Microsoft Azure Purview, Databricks Unity Catalog) sowie von Drittanbietern (z. B. Alation, Atlan, Collibra, Informatica, ...).
Warum Datenkataloge in Organisationen oft keinen Wert liefern
In vielen Organisationen werden Datenkataloge trotz erheblicher Investitionen in Entwicklung und Pflege kaum genutzt. Auf den ersten Blick wirkt ein zentrales Repository, das alle Data Assets indiziert, in der heutigen datengetriebenen Welt unverzichtbar. In der Praxis sehen wir aber oft das Gegenteil. Der Hauptgrund liegt in dem, was wir Überindexierung von Assets nennen, und im Mangel an semantischen, handlungsleitenden Informationen in diesen Katalogen.
Überindexierung: eine Flut irrelevanter Daten
Datenkataloge haben Konnektoren für alle wichtigen Datenquellen wie Datenbanken, Data Lakes, Data Warehouses, BI-Tools und Datenpipelines. Wenn jede Datenquelle automatisch vollständig indiziert wird, enthält der Datenkatalog zwar fachlich wertvolle Domänendaten, aber genauso landen alle Zwischentabellen, Rohtabellen und veralteten Datensätze im Index, die für die meisten Data Consumers irrelevant sind. Teams müssen sich durch ein Meer von Datensätzen wühlen, von denen viele unvollständig, veraltet oder für ihre konkreten Anforderungen unpassend sind, vor allem, wenn Semantik und fachlicher Kontext unklar bleiben. Fast alle dieser automatisch indizierten Assets sind undokumentiert. Diese Überindexierung erzeugt einen Information Overload, der es schwer macht, die tatsächlich wertvollen und vertrauenswürdigen Data Assets zu erkennen.
Datenkataloge bauen schnell Indizes mit Millionen indizierter Tabellen, Views, Dateien, Topics, Dashboards, Reports und anderer Datenobjekte auf.
Der Bystander-Effekt
Der Bystander-Effekt ist ein sozialpsychologisches Phänomen: Menschen bieten in Situationen mit anderen Anwesenden weniger Hilfe an oder werden seltener aktiv, weil sich die Verantwortung verteilt und sie annehmen, jemand anderes werde schon einspringen. In einem Datenkatalog mit Millionen indizierter, aber undokumentierter Assets kann sich das so äußern, dass niemand Verantwortung für Dokumentation oder Verbesserung übernimmt. Bei Millionen von Assets denken alle, jemand anders, ob ein anderes Team, eine andere Abteilung oder jemand aus dem Nachbarteam, sei besser geeignet oder verpflichtet, ein bestimmtes Metadatum zu pflegen. Die schiere Größe des Problems lässt individuelle Beiträge unsichtbar wirken und reduziert die Motivation. Asset-Dokumentation wird als undankbare, unbedeutende Aufgabe empfunden.
Natürlich erlauben Datenkataloge das Hinzufügen von Dokumentation und Tags, und Data Stewards ermutigen Teams dazu. Aber niemand will der oder die Erste sein, der oder die das Chaos aufräumt. Es ist frustrierend, Zeit in Dokumentation und Aufräumarbeit zu investieren, während die große Mehrheit der Assets undokumentiert und qualitativ niedrig bleibt.
Zu viele technische Details, entkoppelt vom Business
Ein weiteres Hauptproblem ist der Fokus auf technische Metadaten. Informationen zu Schema-Strukturen, Feldtypen und Lineage helfen Engineers, sie helfen aber Business-Usern wenig, die auf semantische Klarheit und Qualitätszusagen angewiesen sind.
Die meisten Datenkataloge bilden folgende kritische Aspekte nicht ab:
- Semantik: Business-User müssen verstehen, was Daten in einem fachlichen Kontext bedeuten und unter welchen Geschäftsprozessen sie entstanden sind. Das verlangt klare Definitionen, Beziehungen und Beispiele, nicht nur technische Schemata.
- Datenqualität: Users müssen wissen, ob die Daten vollständig, konsistent und für den Zweck geeignet sind. Die meisten Kataloge liefern dazu keine klare Bewertung.
- Service-Level-Erwartungen: Verlässlichkeit, Verfügbarkeit und Aktualisierungsfrequenz sind entscheidend, um Datensätze in operativen und analytischen Prozessen einzusetzen. Ohne diese Informationen wird Datenvertrauen zur Glücksache.
Diese Aspekte lassen sich nicht automatisch aus den Datenquellen extrahieren, sie erfordern manuelle Kuration und Domänenwissen.
In Richtung eines neuen Paradigmas: der unternehmensweite Datenmarktplatz
Datenprodukte verändern, wie Organisationen mit verteilten Teams Daten managen und teilen. Sie stehen für einen konsumentenorientierten Ansatz im Datenmanagement.
Datenprodukte: für Consumers gebaut, mit klarer Ownership
Datenprodukte sind logische Einheiten rund um ein fachliches Konzept, die Assets, Code und Dokumentation zu einer kohärenten Datenlösung für Consumers kombinieren. Sie verbergen Implementierungsdetails (etwa Roh- und Zwischentabellen, Code-Pipelines, Testdaten) und zeigen anderen Teams nur die finalen, kuratierten Datensätze über definierte Output Ports. Ein Datenprodukt gehört in der Regel dem Team, das die fachliche Domäne versteht, und ist das Ergebnis einer bewussten Entscheidung, die Daten als Produkt zu teilen.
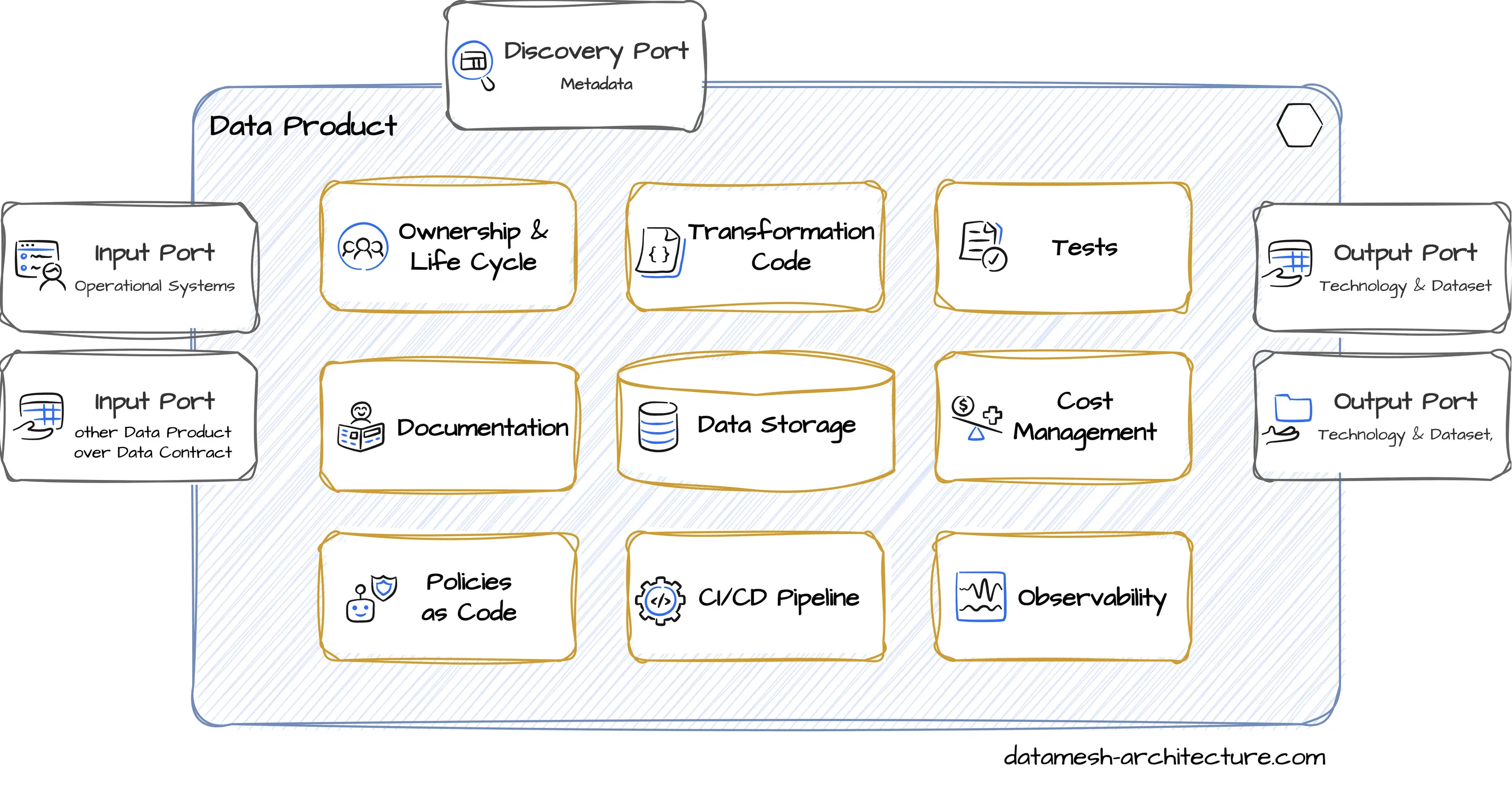
Die meisten Organisationen haben nur einige Hundert bis Tausend Datenprodukte. Das macht das Management deutlich einfacher als bei den Millionen indizierter Data Assets in klassischen Datenkatalogen.
Data Contracts: Syntax, Semantik und Qualität erklären und verifizieren
Wenn wir Datenprodukte bereitstellen, müssen wir potenziellen Data Consumern die Daten beschreiben und erklären. Hier kommen Data Contracts ins Spiel. Ein Data Contract definiert Struktur, Format, Semantik, Qualitätsmetriken, SLAs und Nutzungsbedingungen für Datenaustausche zwischen Data Producern und Data Consumern. Technisch ist ein Data Contract eine standardisierte YAML-Spezifikation, sowohl menschen- als auch maschinenlesbar (siehe Data Contract Specification und ODCS). Data Contracts werden von Product Ownern und Consumern in einem kollaborativen Requirements-Engineering-Prozess manuell kuratiert. Die Datenplattform testet, validiert und erzwingt die Einhaltung der Verträge durch die Datenprodukte.
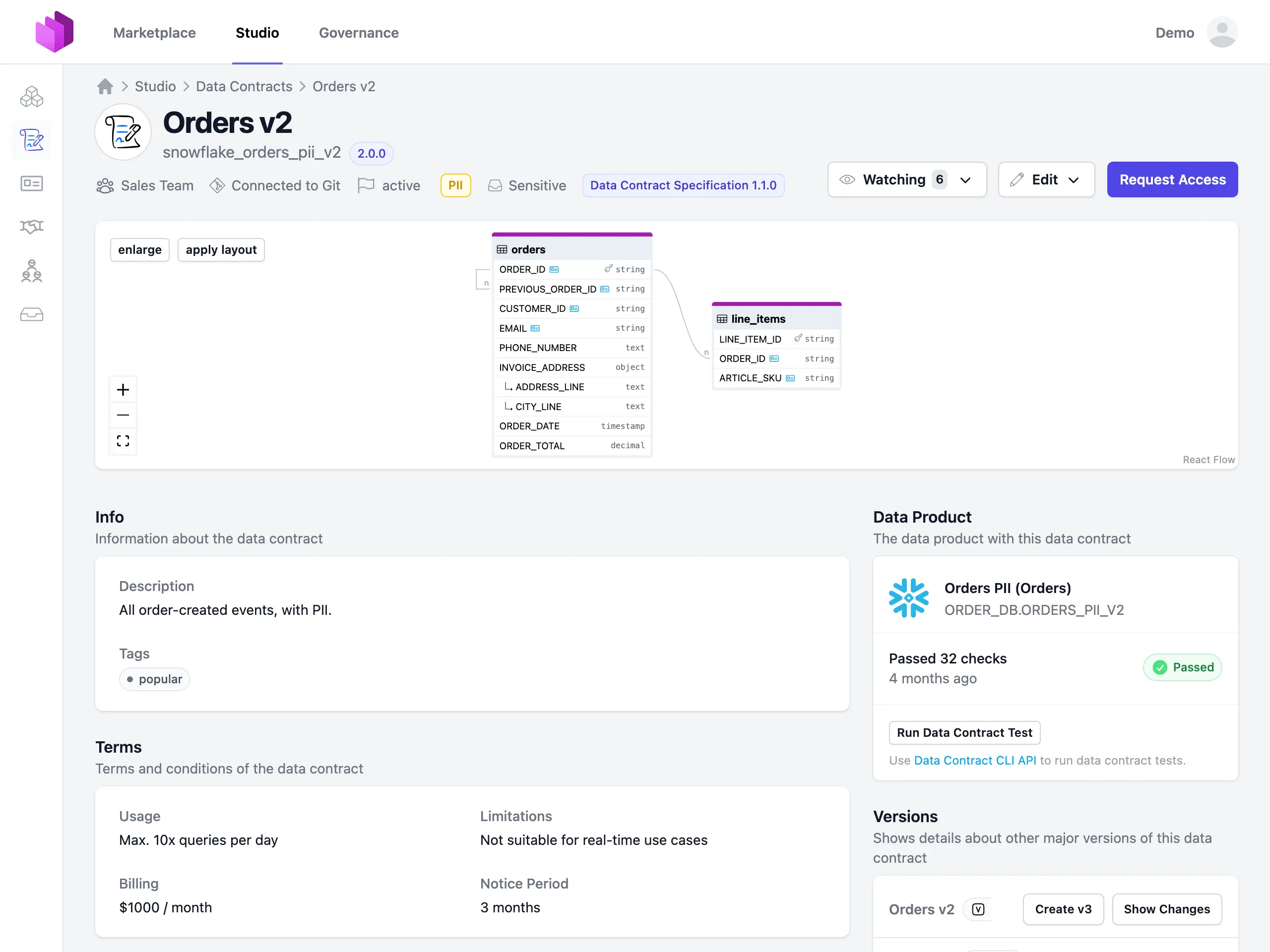
Data Contracts sind für Datenprodukte das, was APIs für Softwaresysteme sind. Sie bieten eine klare Schnittstellenspezifikation, auf der Data Consumers aufbauen können, ohne die Implementierungsdetails verstehen zu müssen.
Self-Service-Workflow für Anfrage und Freigabe
Wenn wir Datenprodukte mit ihren Data Contracts in einem unternehmensweiten Datenmarktplatz zusammenführen, lässt sich ein Self-Service für das Access Management aufbauen.
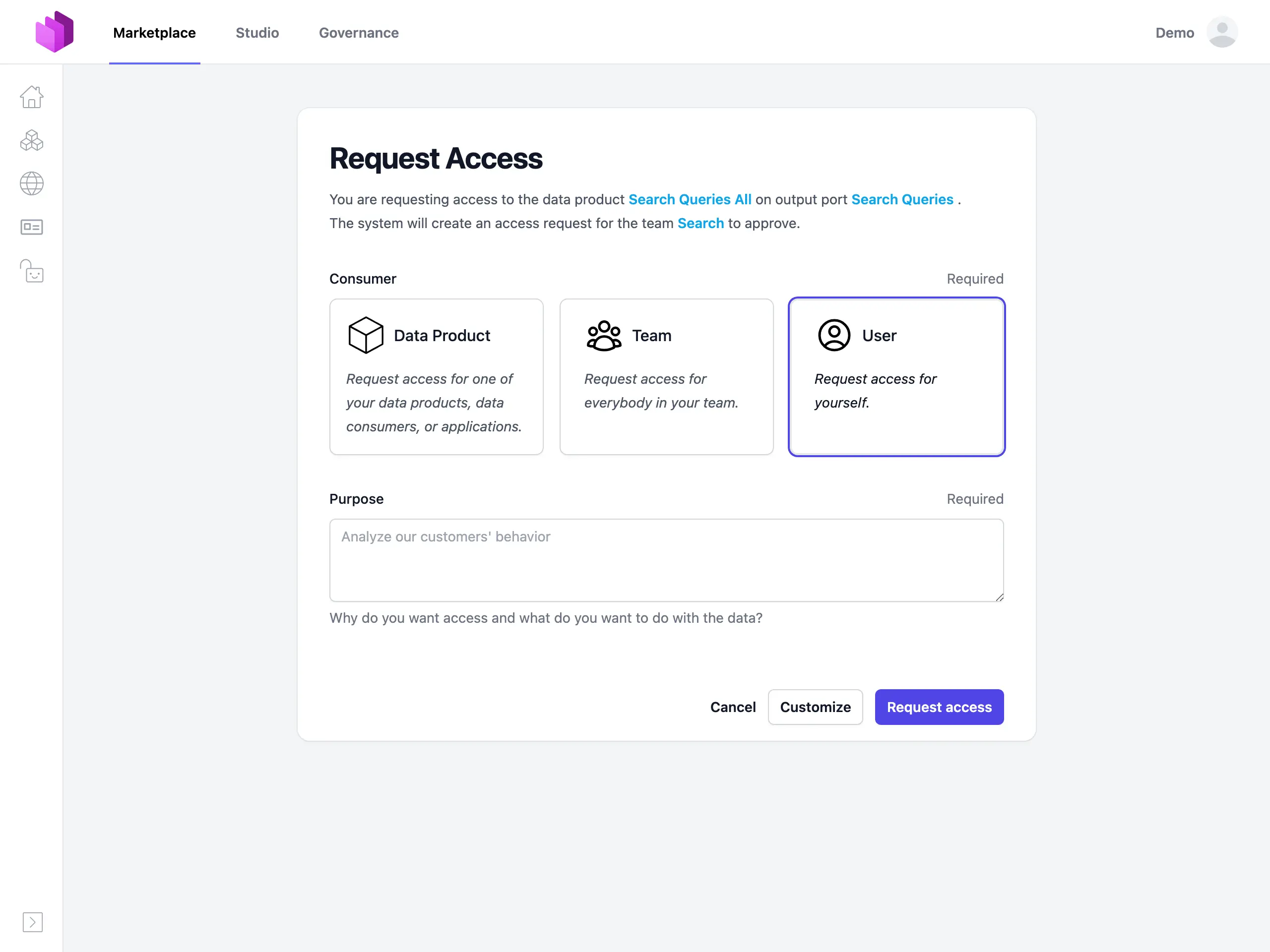
Data Consumers beantragen Zugriff auf Datenprodukte gemäß den Nutzungsbedingungen des Data Contracts. Data Product Owners verantworten die Freigabe oder Ablehnung auf Basis ihres Domänenwissens und der Governance-Regeln. Die Datenplattform automatisiert das Access-Rights-Management und sorgt für effiziente, sichere Verwaltung der Datenprodukt-Assets. Dieser Workflow eliminiert Bottlenecks zentralisierter Governance. Ein vollständiger Audit-Trail über Zugriffsanfragen, Freigaben und aktive Consumers sorgt für volle Transparenz für Data Producers und Governance-Teams.
Contract-Driven Data Governance
Effektive Governance in einem Datenmarktplatz lebt von klarer Ownership und stabilen Data Contracts. Globale Policies setzen die Basisregeln, die universell für alle Datenprodukte gelten und Konsistenz im Marketplace sicherstellen. Data Contracts bauen darauf auf und spezifizieren domänenspezifische Details wie Nutzungsbedingungen, Qualitätsstandards und Compliance-Anforderungen, entscheidend für vertrauensvolle Austausche zwischen Data Producern und Data Consumern.
Data Product Owners verantworten, dass ihre Angebote die vereinbarten Standards einhalten und sowohl globale Policies als auch contract-spezifische Zusagen erfüllen. Indem sie ihre Datenprodukte pflegen und mit Consumern zusammenarbeiten, sorgen sie für einen effizienten und verlässlichen Marketplace.
Wir können KI in der Data Governance einsetzen, um Metadaten zu überwachen, Compliance zu validieren und potenzielle Risiken zu erkennen. Mit guten Metadaten generieren LLMs Empfehlungen und Warnungen für Data Product Owners, um deren Verantwortung zu erleichtern. Die letzte Verantwortlichkeit liegt aber bei den Ownern. Ihr Domänenwissen sorgt dafür, dass Governance-Entscheidungen praxistauglich und auf Business-Ziele ausgerichtet bleiben.
Zusammenfassung
Datenkataloge waren lange die primäre Lösung für das Verwalten von Data Assets. Ihre Wirksamkeit ist aber oft durch Überindexierung und fehlende Semantik- und Qualitätsgarantien begrenzt. Effektive Datenprodukt-Metadaten sind contract-gestützt, manuell kuratiert und haben klare Ownership. In einem Datenmarktplatz können Organisationen gemanagte Datenprodukte im Self-Service mit klaren Governance-Regeln an andere Teams oder externe Organisationen weitergeben.
Entropy Data als Datenmarktplatz
Erfahre mehr darüber, wie Entropy Data dir hilft, einen unternehmensweiten Datenmarktplatz aufzubauen.
Starte kostenlos, erkunde die klickbare Demo oder vereinbare eine geführte Tour mit den Autoren.