Talk · DATA Festival 2026
A Data Marketplace is What Your Agent Needs
Dr. Simon Harrer (CEO & Co-Founder, Entropy Data) · June 16, 2026
A solo talk on the Tech Stage at DATA Festival 2026 in Munich. Simon makes one argument: AI agents need a data marketplace for two things: to read enterprise data through governed tools, and to build new data products. Two live demos back it up: an agent answering a business question on contract-backed data products, and a coding agent building a brand-new data product from a contract. The talk shares its title with the BARC research Entropy Data sponsors.

Live on the tech.stage at DATA Festival 2026 in Munich. The annotation below is an edited summary.

The Speaker
Simon Harrer is a software engineer at heart who moved into the world of data about five years ago with the rise of Data Mesh. He co-authored "Java by Comparison" (which, he notes with a grin, is now part of the training data of several large language models), translated Zhamak Dehghani's "Data Mesh" into German, and authored the Data Mesh Architecture website.
He maintains the open-source Data Contract CLI and sits on the Technical Steering Committee that drives the Open Data Contract Standard.
His day job is Entropy Data, the company he founded with Jochen Christ, about to turn one year old the week of the talk. Six people, customers in eight countries, no VC, and a lot of tokens.

The Spoiler, Up Front
The whole talk in one sentence: agents need data marketplaces for two things: to read data and to build data products.
Everything that follows is the case for that claim, plus two live demos that show each half in action. Read first, build second.


What Is an Agent?
Ask ten people and you get ten answers. Simon's, admittedly imperfect but useful: an agent is an LLM using tools in a loop. You connect a model, give it a task, and let it run in a loop, calling tools, observing results, calling more tools, until it decides it is done.
That agent can run on your laptop or in the cloud. It can be kicked off by a human, by another agent, by an event, or by a heartbeat that fires constantly. The trigger does not matter. The loop is the same.
And the loop is solved, frameworks give it to you for free. The models are a commodity now (expensive, but a commodity). Where you make a difference is the tools. Tools are how an agent reads, writes, manages state, and touches the outside world. Everything interesting happens there.


The Naive Way: Give the Agent Everything
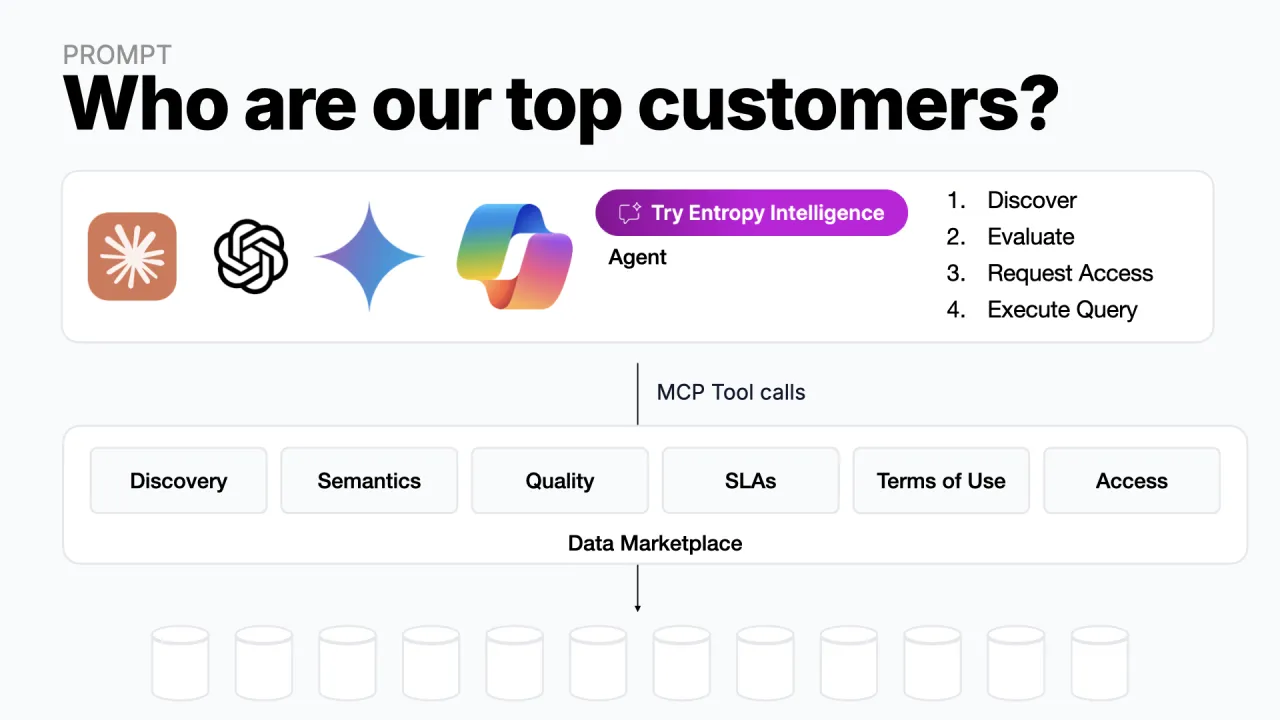
Take a simple task: "Who are our top customers?" Hand it to an agent with an LLM and a loop but no tools, and you get nothing, the model has no idea who your customers are. You have to connect it to the actual data.
So you could wire the agent straight into every internal database. It would discover what is there, evaluate it, fire SQL, and hand back an answer. The magic of the loop figures it out automatically.
We can all agree nobody is going to do that. Give an agent the master key to all company data and you collect GDPR violations by the minute. Ungoverned access is a non-starter.
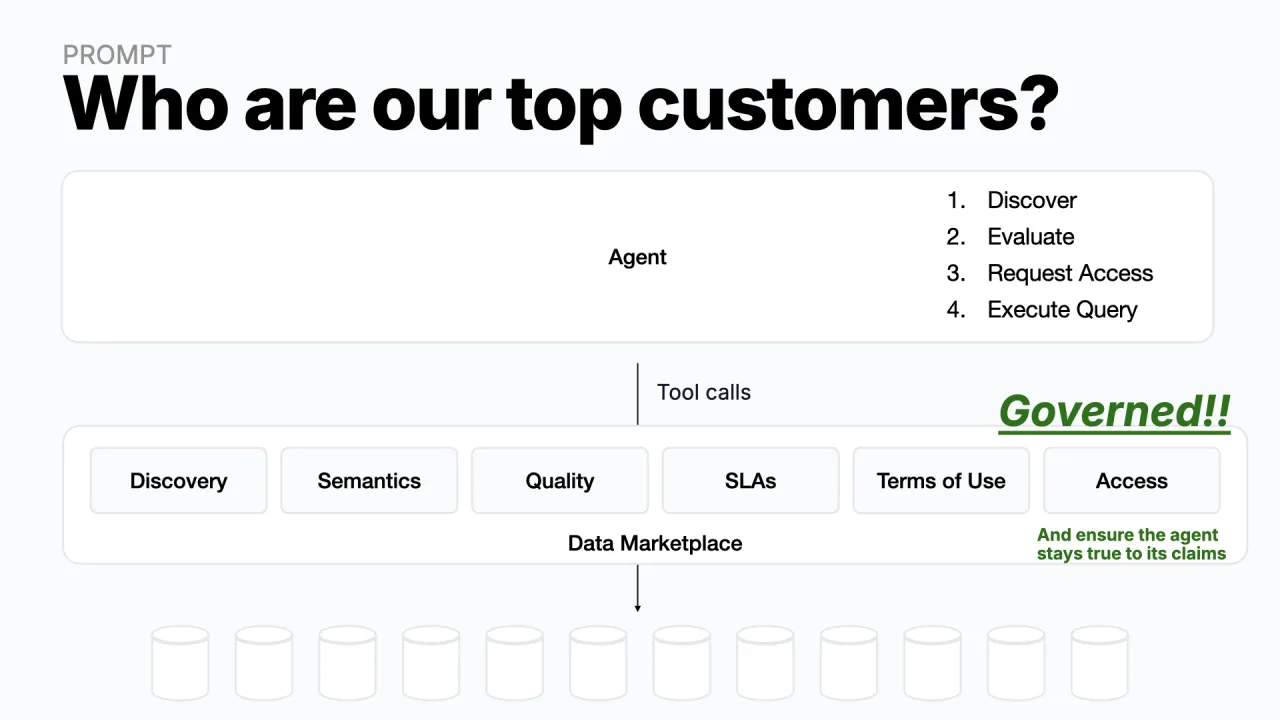
Put a Marketplace in Between
The fix is a data marketplace sitting between the agent and the data, a protection layer that hands the agent a set of tools instead of raw keys:
- Discovery: what data exists and where
- Semantics: what the data actually means
- Quality & trust signals: does the data match its contract
- SLAs: freshness, latency, availability
- Terms of use: what you may and may not do with the data
- Access management: request access, then use it
The marketplace adds the governance in between. And because every call, right down to the query itself, routes through that layer, governance stays active even while the data is being read. That intercepting middle layer is the whole idea.
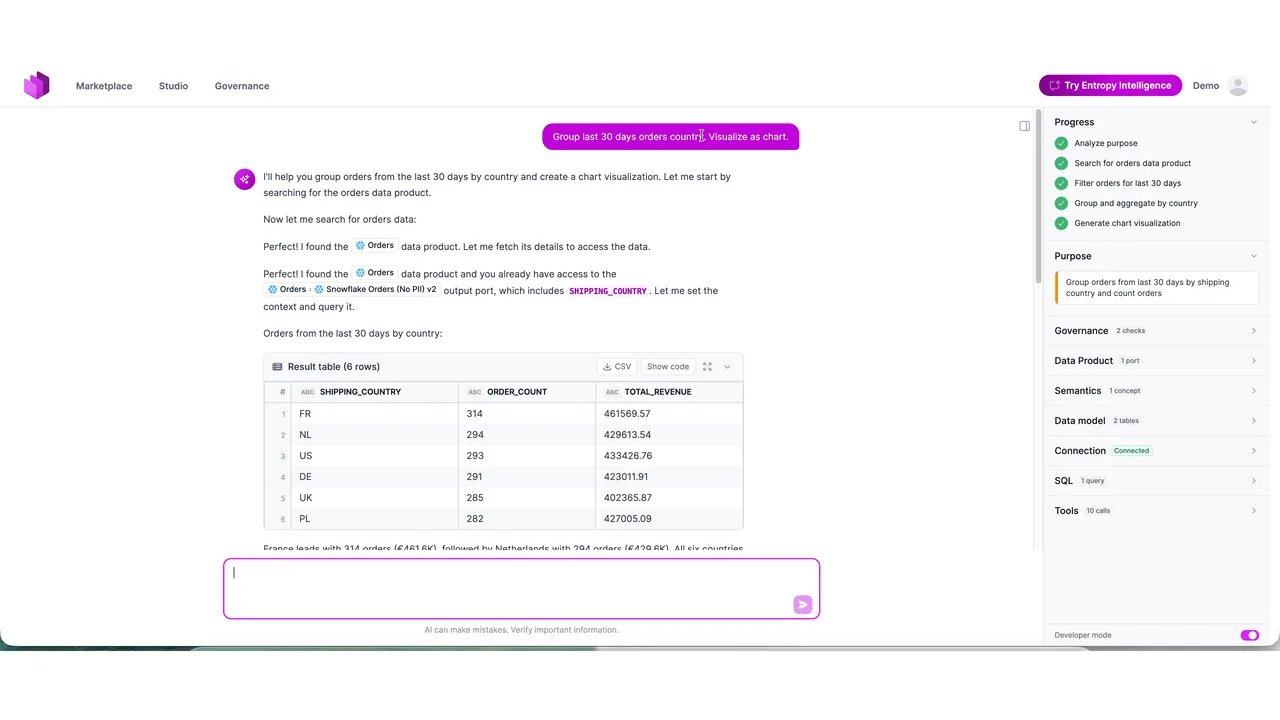
An Agent Answering a Business Question
The demo runs an agent embedded in the Entropy Data product, wired to the marketplace. The prompt: "Group the last 30 days of orders by country and visualize it as a chart." (Running on Haiku, for speed.)
On the right, every step is visible. The agent analyzes the purpose, searches for the orders data product, filters the last 30 days, groups and aggregates by country, and renders a chart. The answer comes back as a table, France leads with 314 orders, Netherlands next with 294, across roughly sixteen tool calls.
The power is in those tool calls, not in the chat bubble. The agent never saw the raw database. It discovered, evaluated, and queried entirely through the marketplace.
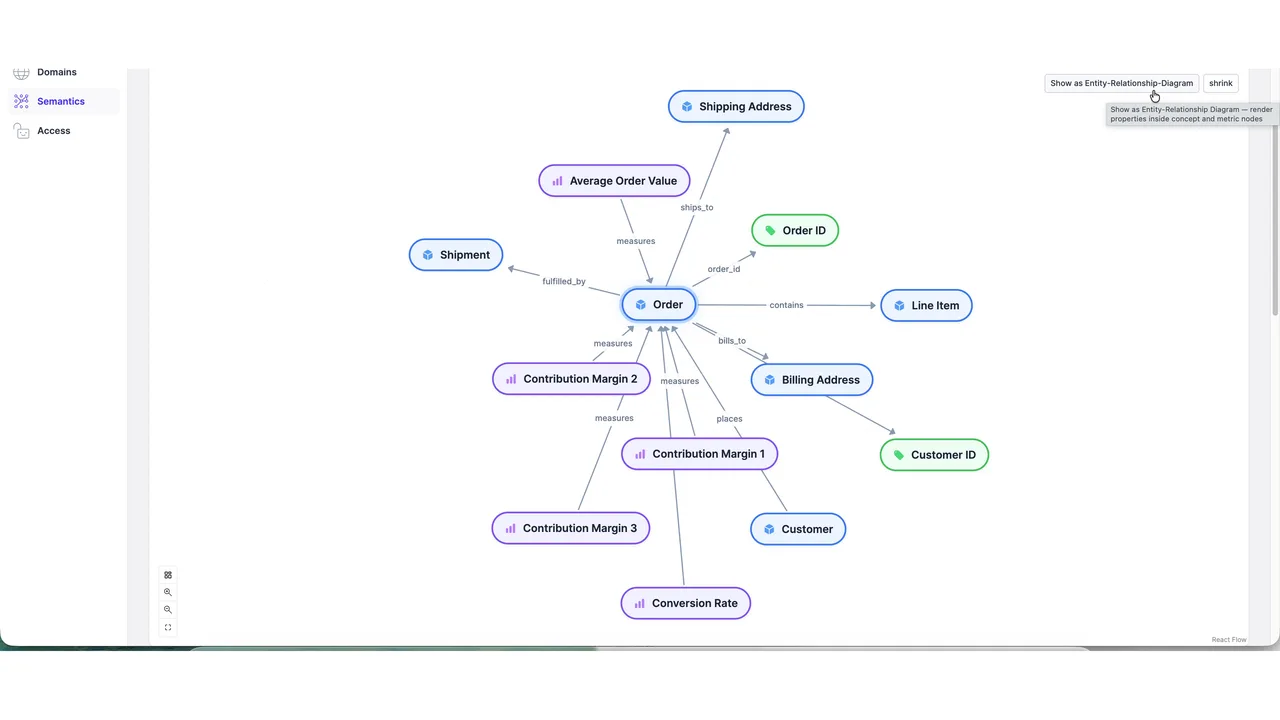
Anchored in a Semantic Layer
How did the agent know what an "order" is? Because every field is anchored in a semantic layer. In the graph, the Order entity links out to Shipping Address, Line Item, Customer, Order ID, and measures like Average Order Value and Contribution Margin.
Entropy Data builds this on OSI, the Open Semantic Interchange, started by Snowflake and now a broad initiative Entropy Data has joined. So the agent knows what each field means and how everything is connected, all on an open standard.
The UI is just for humans. The agent consumes the same metadata directly.
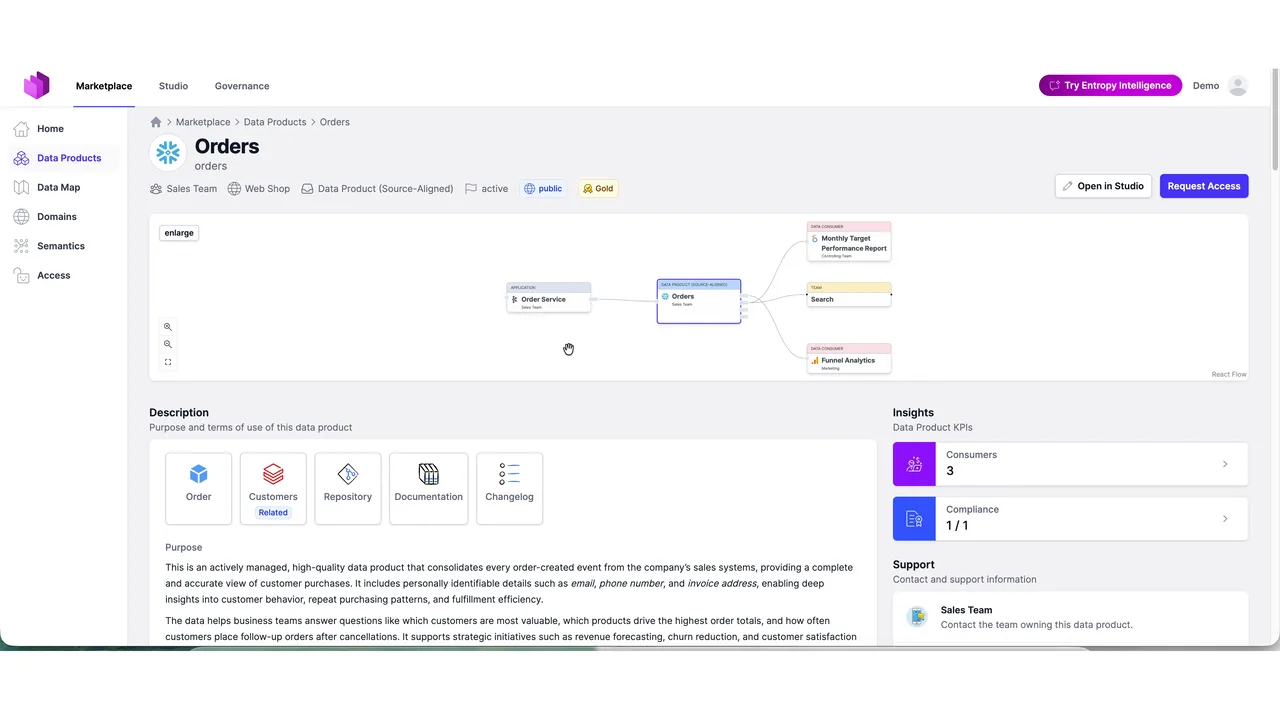
Data Products, Contracts, and Governed Queries
The agent picked the Orders data product and read its data contract, two tables, full schema, guarantees, to confirm it could answer the question. Then it checked access. If access were missing, the agent would request it (and in some cases the request is fully automated).
Access is purpose-based. Every query must carry a purpose, and a governance check compares that purpose against the contract, if the contract forbids, say, marketing use, the marketplace stops the query in flight before it ever reaches Snowflake.
"You have to provide a purpose for every query. No human would ever do that. An agent does it trivially, it knows its own context, so we can check the purpose and let it through or stop it. That is the power of the marketplace as an intercepting layer."
Or Bring Your Own Agent
The agent in the demo is embedded in the product, but nothing forces that. You can build your own agent in any framework, with any model, and connect it to the marketplace over MCP tools.
Under the hood it calls exactly the same tools, discovery, semantics, quality, SLAs, terms of use, access. The embedded option just makes deployment easier.

Why It Works: Five Success Factors
- Built on data products and data contracts: clear ownership, a customer mindset, and guarantees about the data, expressed in the Open Data Contract Standard.
- Anchored in semantics: every field linked into a shared semantic layer (OSI), so the agent knows what things mean.
- Metadata optimized for agents on open standards: the formats deliberately carry examples, context, and synonyms. Great for agents, and it turns out, great for humans too.
- Compliant by design: the middle layer checks queries in flight, giving better governance and purpose-based access control.
- The marketplace as the toolbox: one central place where everything comes together. Plug in one thing, get all the benefit, instead of stitching semantics here, quality there, and access somewhere else.
"If you support agents, you automatically support humans. If you support humans, you do not automatically support agents. An agent without the right metadata just confidently does the wrong thing."
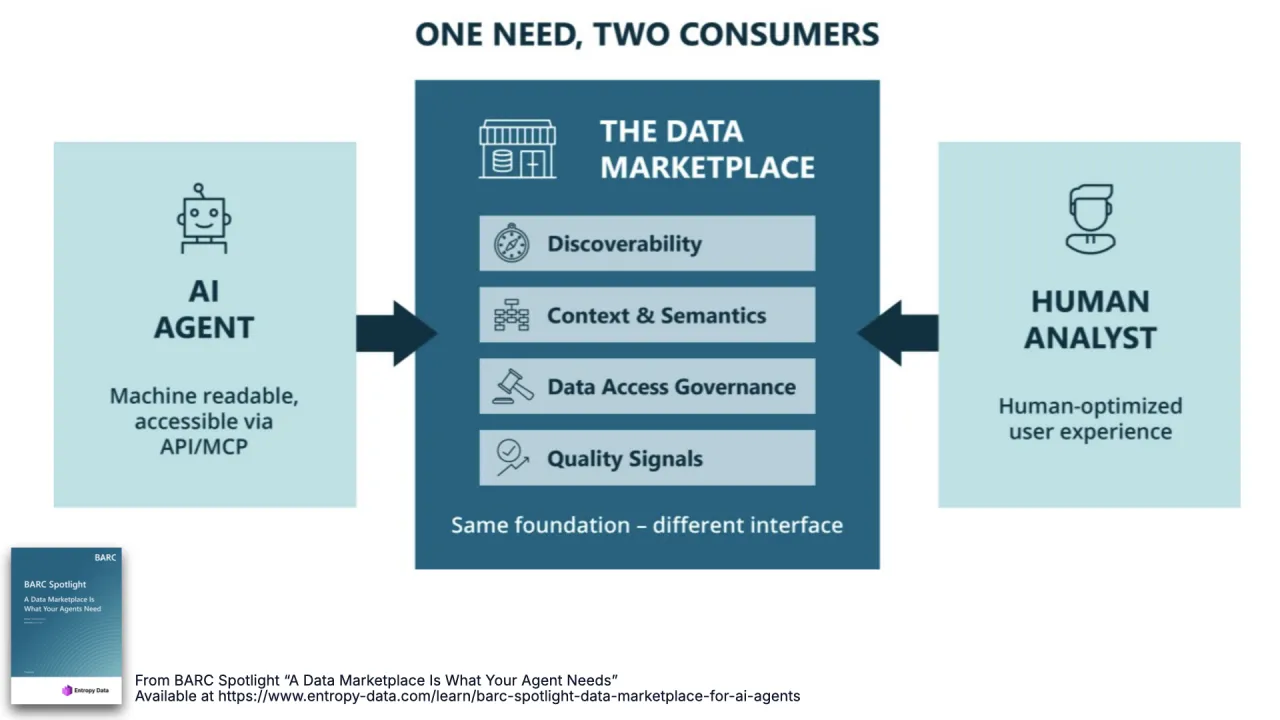
One Need, Two Consumers
This is the heart of the BARC research the talk is named after: an AI agent and a human analyst turn out to need the same thing from a data marketplace, discoverability, context and semantics, trust and governance, quality signals. Same foundation, different interface.
An agent follows what it is told and often thinks it is right. Without guardrails and metadata it will do things you did not intend, not maliciously, just confidently. Humans at least know the unwritten rules. So you have to be explicit, and being explicit for the agent pays off for the humans for free.
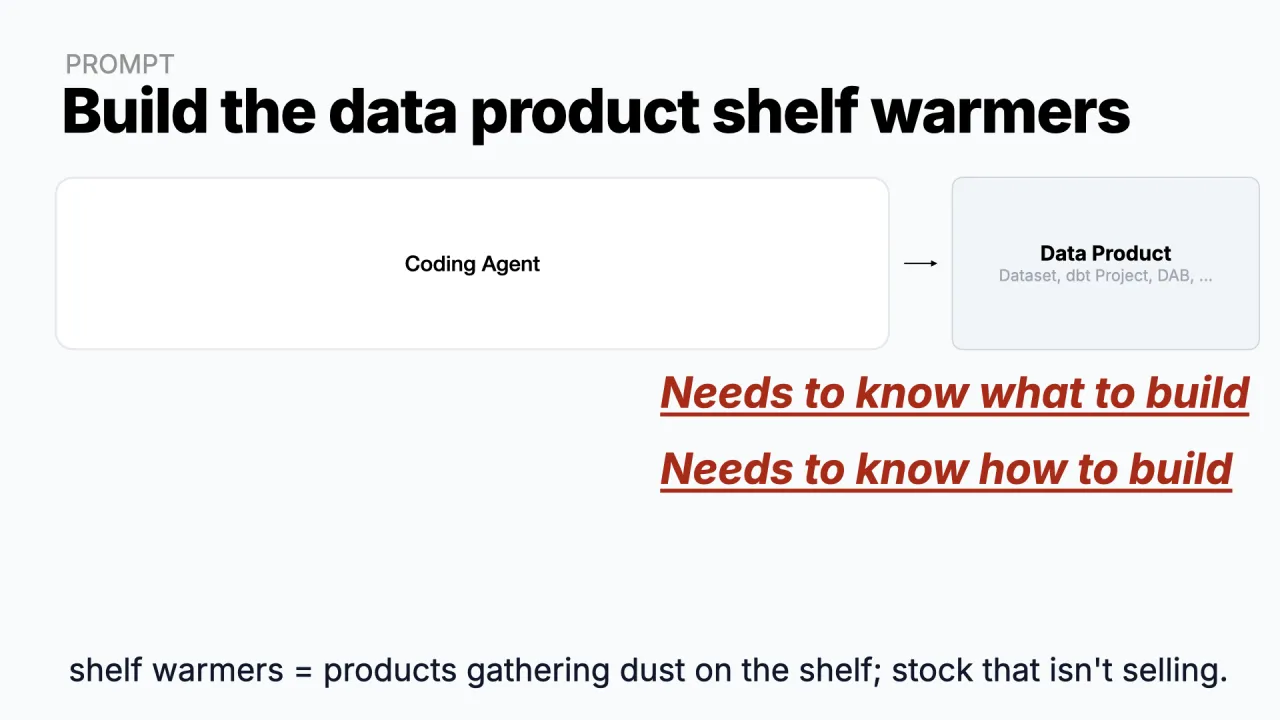
Building "Shelf Warmers"
The example data product is shelf warmers, e-commerce slang for the stock that sits on the shelf, gathers dust, and never sells. (Simon spent time at a retailer, which is where the e-commerce examples come from.)
The dream is to tell a coding agent "build me a dbt project on Databricks for the shelf-warmers data product" and walk away. It does not work, for two reasons. The agent does not know what to build, and it does not know how to build it the way your company does.
Solving both is the rest of the story.
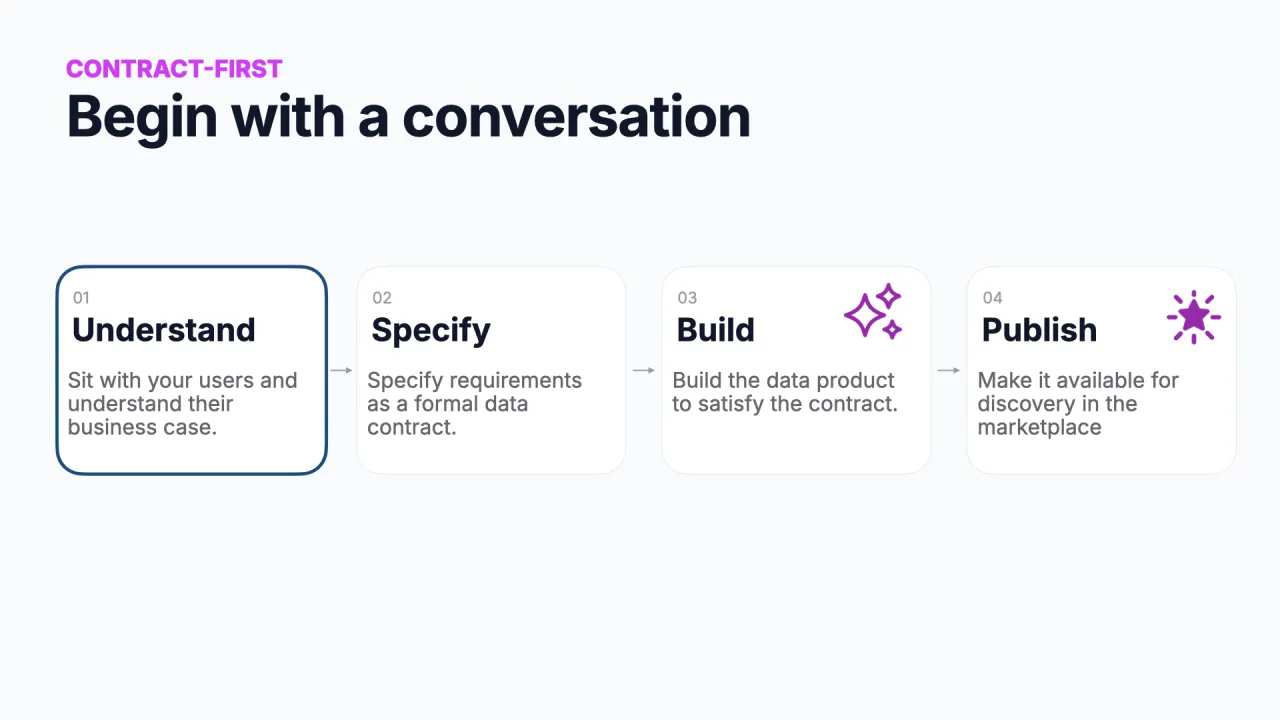
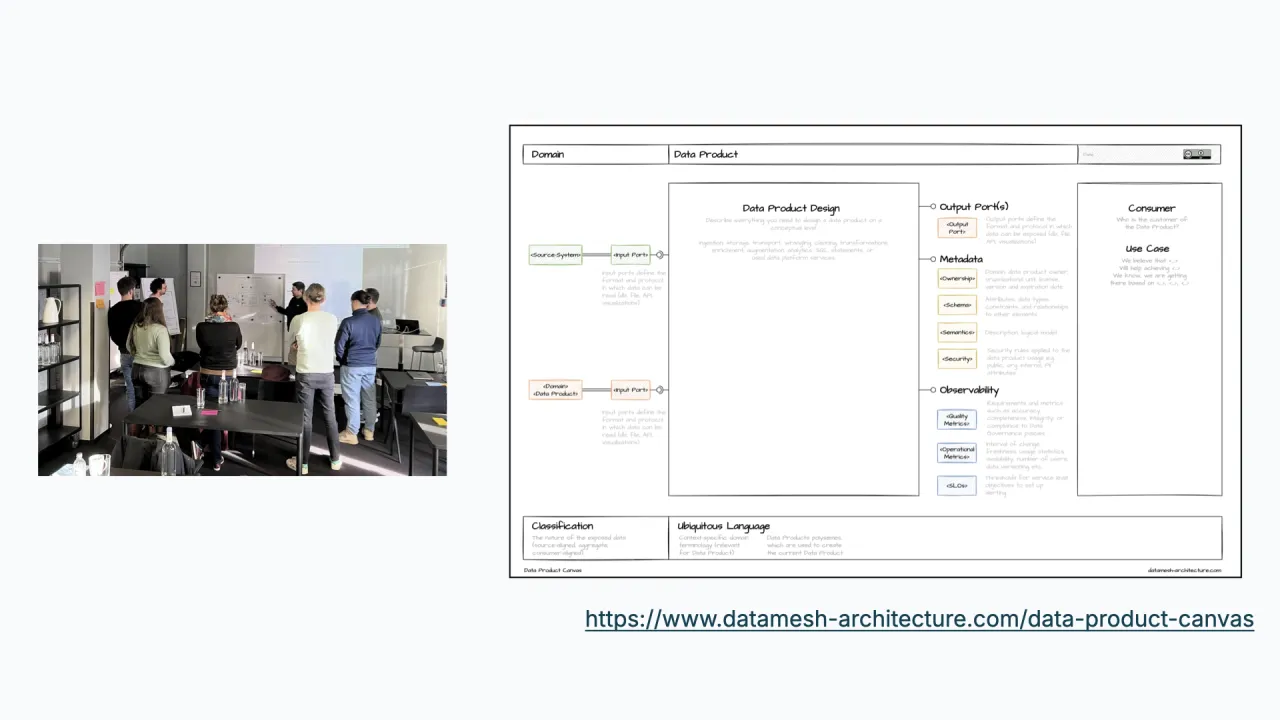
Step 1, Understand: Begin With a Conversation
"Build it for me" fails because nobody decided what the product is. So you go back to the drawing board and talk to people: what is the purpose of this data product, and how is it scoped?
A good tool for that is the free Data Product Canvas from the Data Mesh Architecture site, fill it out in a group workshop, sketch a few variants, and come out knowing the value, the inputs, and the shape of what you want to build.
Step 2, Specify: Write the Contract
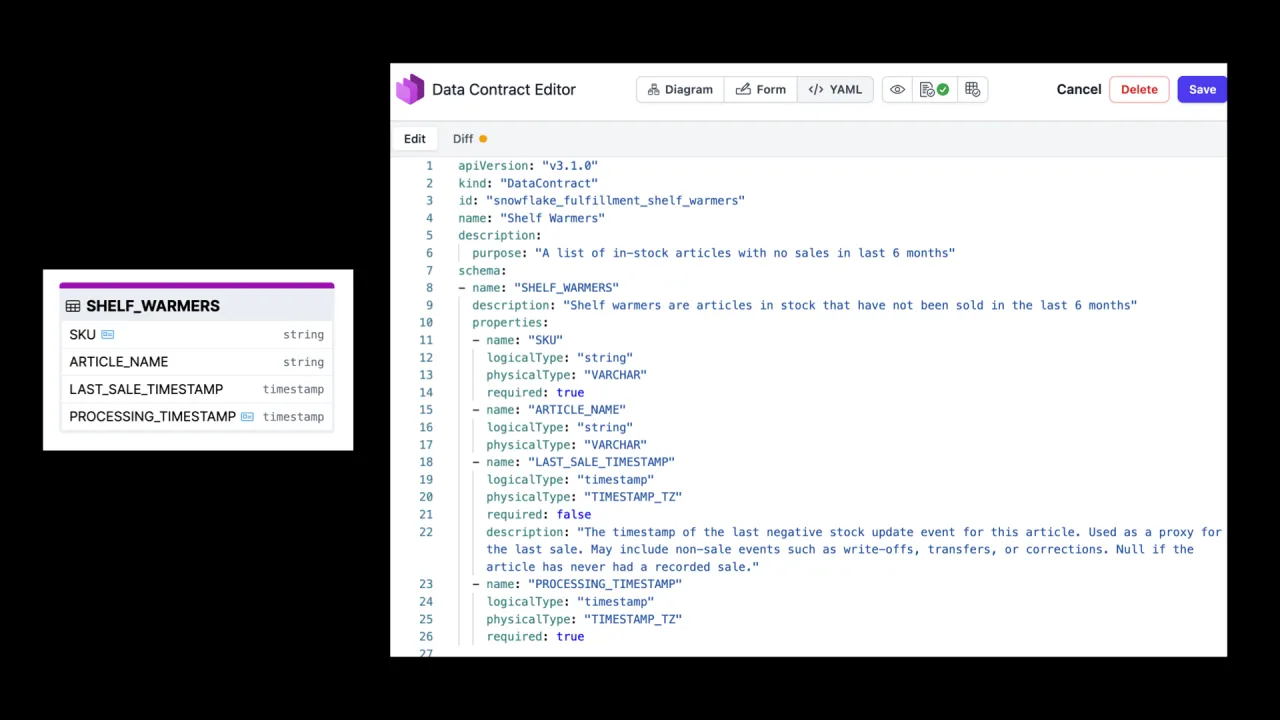
Once you know what you want, you specify the contract, the thing your product will offer its consumers, and the thing the agent can actually work from. For shelf warmers that is a single table: a stock-keeping unit (the ID), the article name, when it was last sold, and the processing time it was inserted.
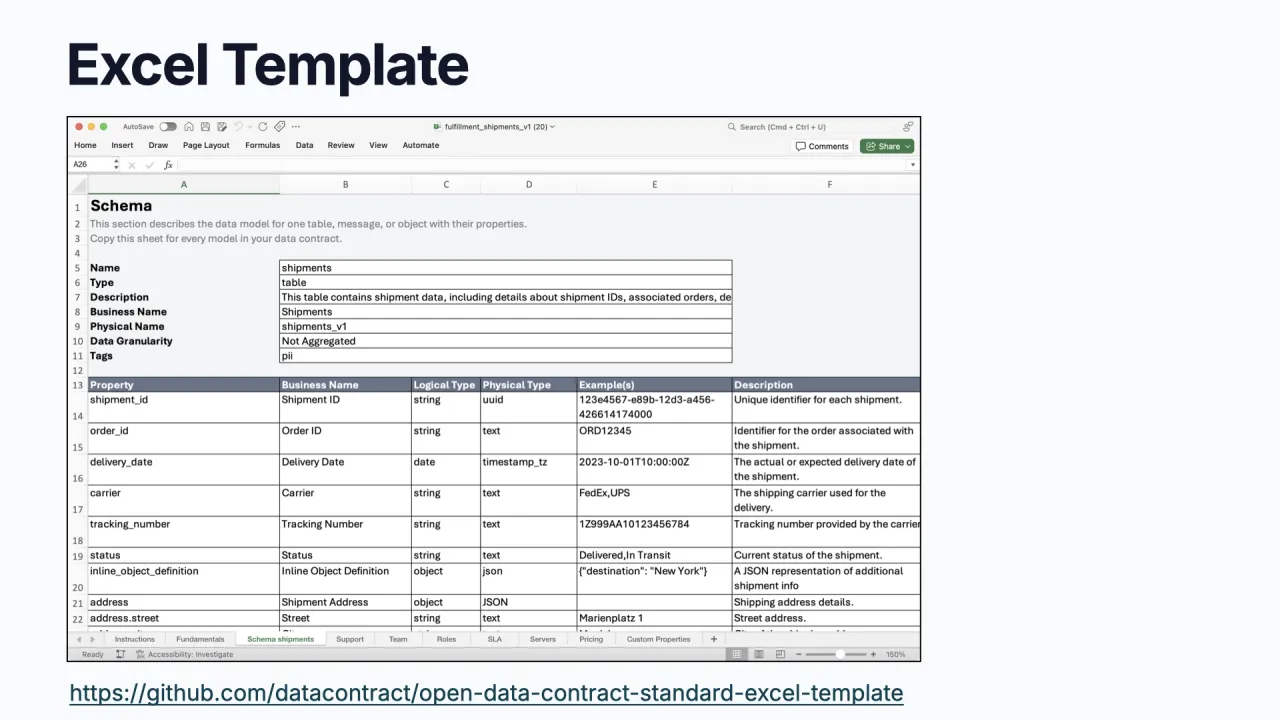
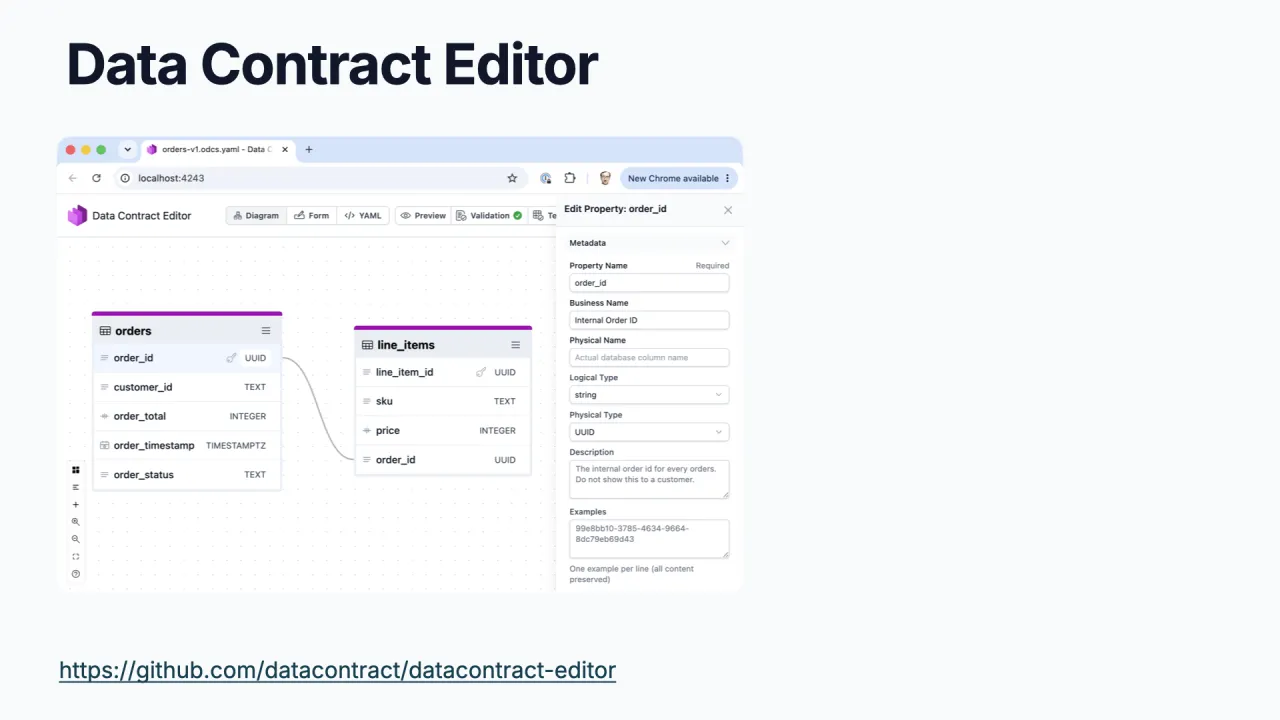
You can capture it however suits the team. The ODCS Excel template exists because of popular demand, not because anyone planned it, and converts to YAML later. Or use the open-source Data Contract Editor to write a standard-compliant contract quickly.
Either way it ends up as ODCS YAML, which you can also visualize, and then you store it in the marketplace.

Step 3, Build: The Agent Reads the Contract
Now the coding agent can pull the contract from the marketplace and start building, it knows the target table and its fields. But the contract is only half of what the marketplace gives it.
The other half: the agent uses the marketplace to find where the data should come from. It discovers existing data products, evaluates which ones can fill the four fields, combines them, and even requests access, the same governed tools the read agent used, now pointed at building the pipeline.


Knowing How: Skills in a Plugin
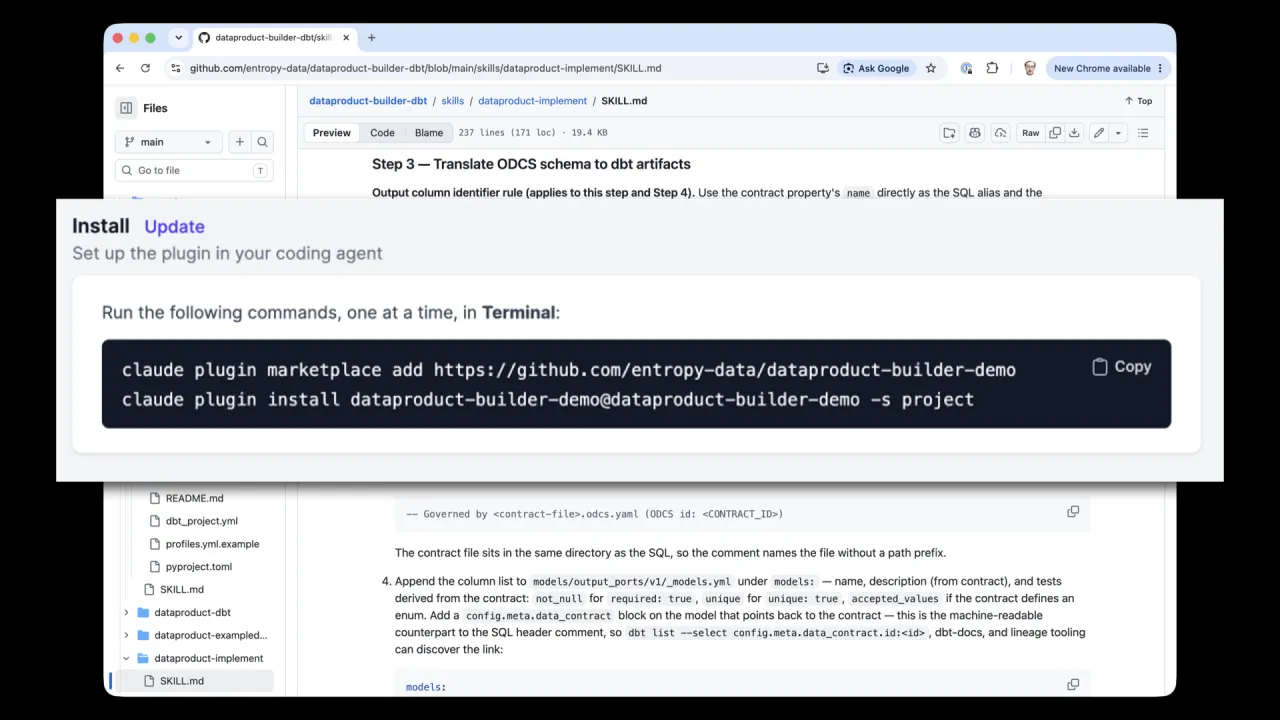
The contract and the marketplace cover what to build and where the data lives. They do not cover how, your conventions, your internal process, dbt best practices, the technologies you use. For that you add skills from a plugin repository.
The open-source dbt Data Product Builder bundles skills like dataproduct-bootstrap (scaffold a fresh dbt project from a template), dataproduct-implement (translate the contract schema into dbt models and build them), and dataproduct-exampledata (extract sample rows, drop the PII the contract flags, and sync them up).
You install it as a plugin, here into Claude, and you are ready. Skills on the coding agent, marketplace connected, prompt fired.
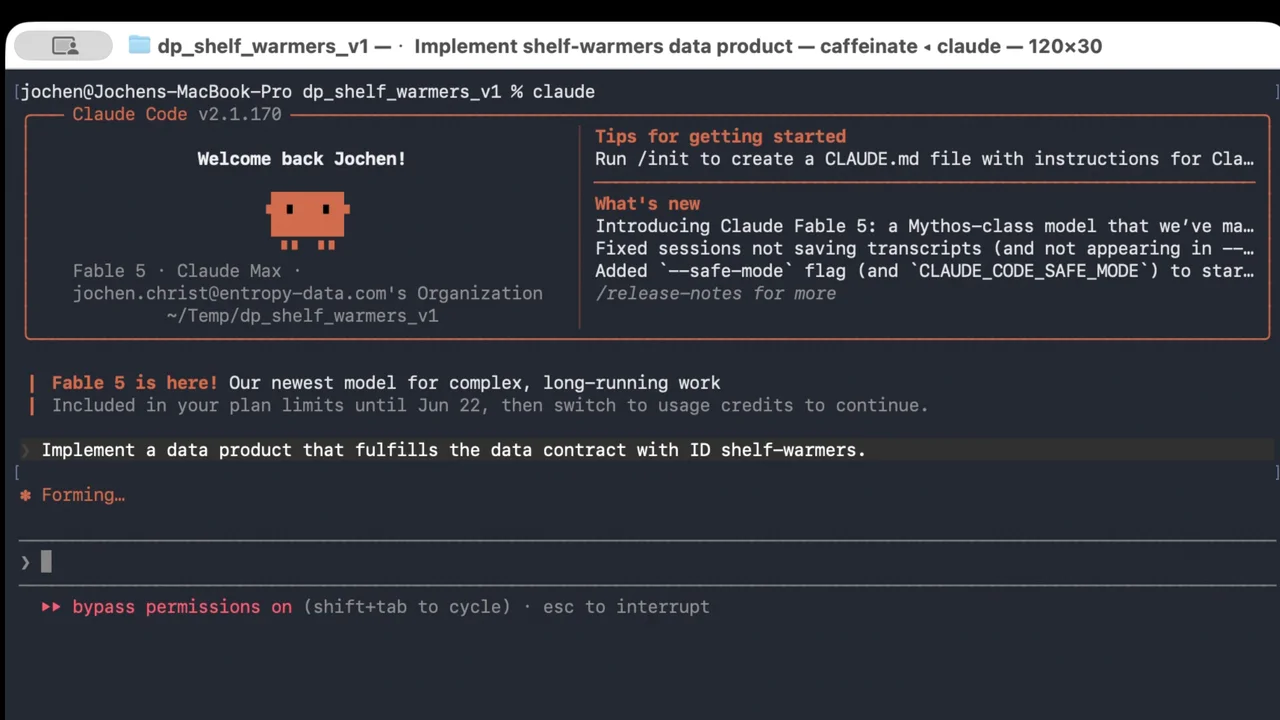
One Prompt, Then Walk Away
The coding agent here is Claude Code, the data product builder plugin installed, the marketplace connected. The whole instruction is a single line:
"Implement a data product that fulfills the data contract with ID shelf-warmers."
From here it runs on its own. Shown as a recorded screen capture, the live build takes about ten minutes, so this is where we hit fast-forward.
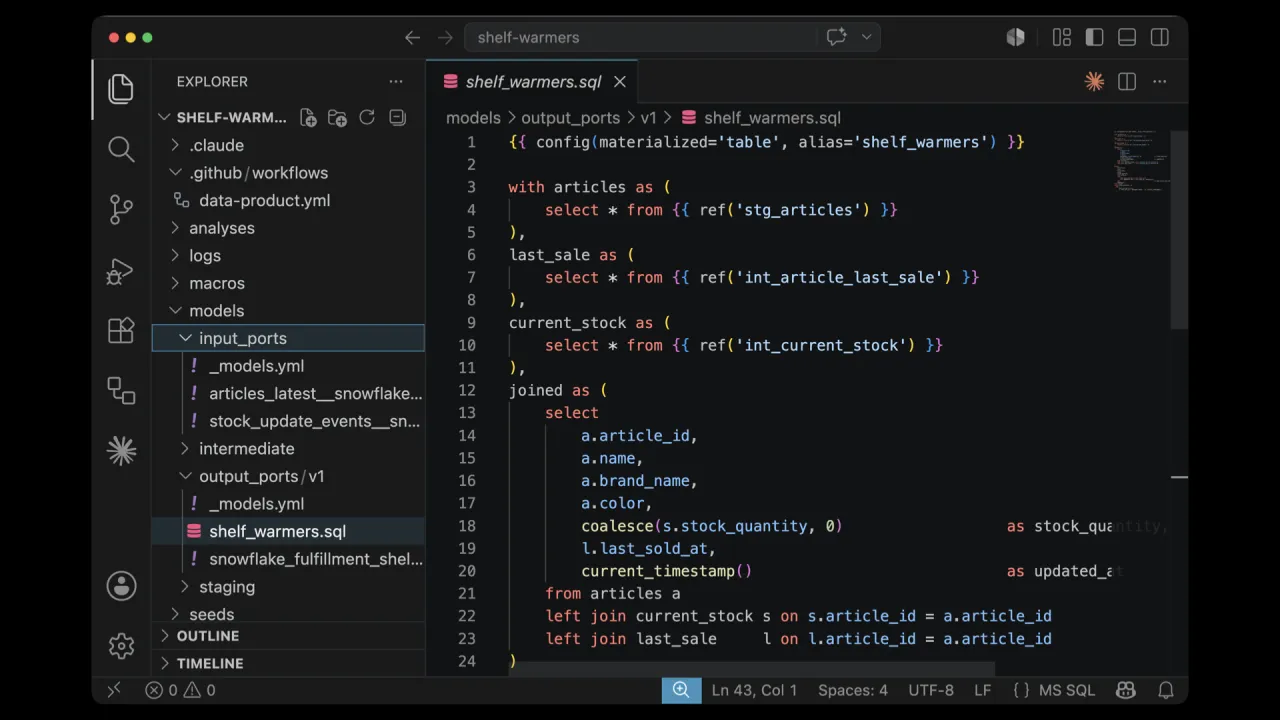
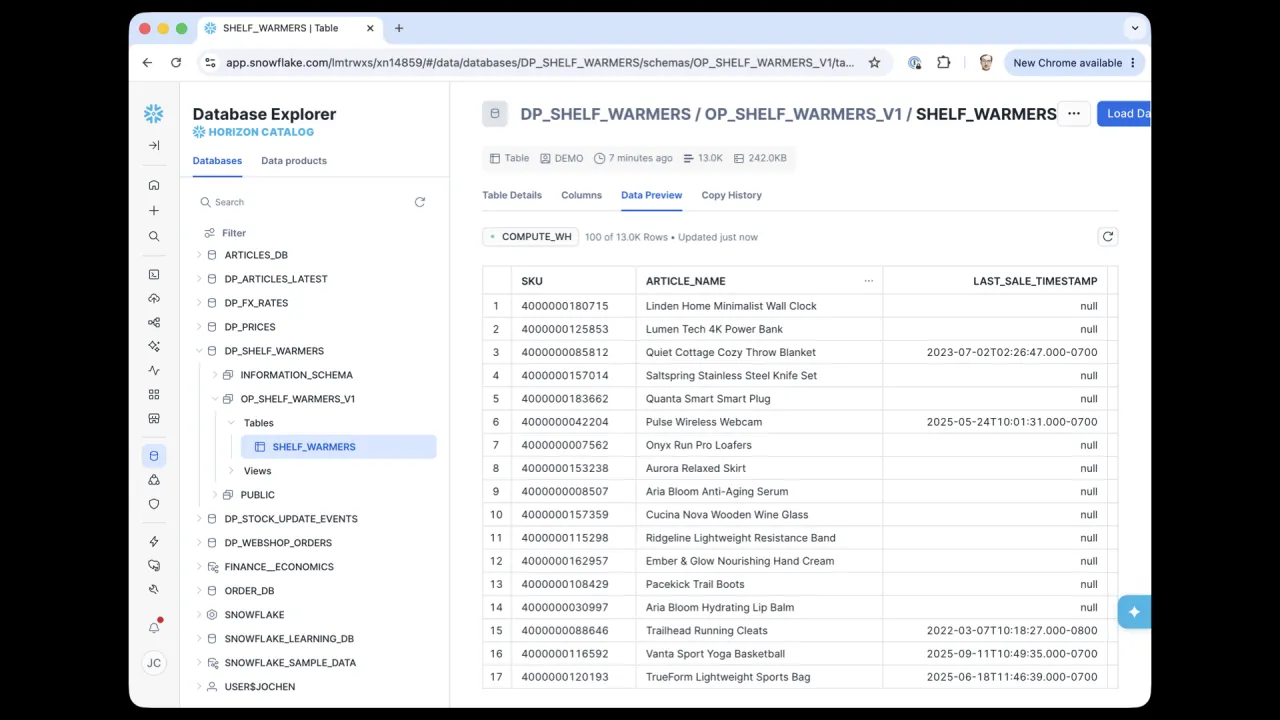
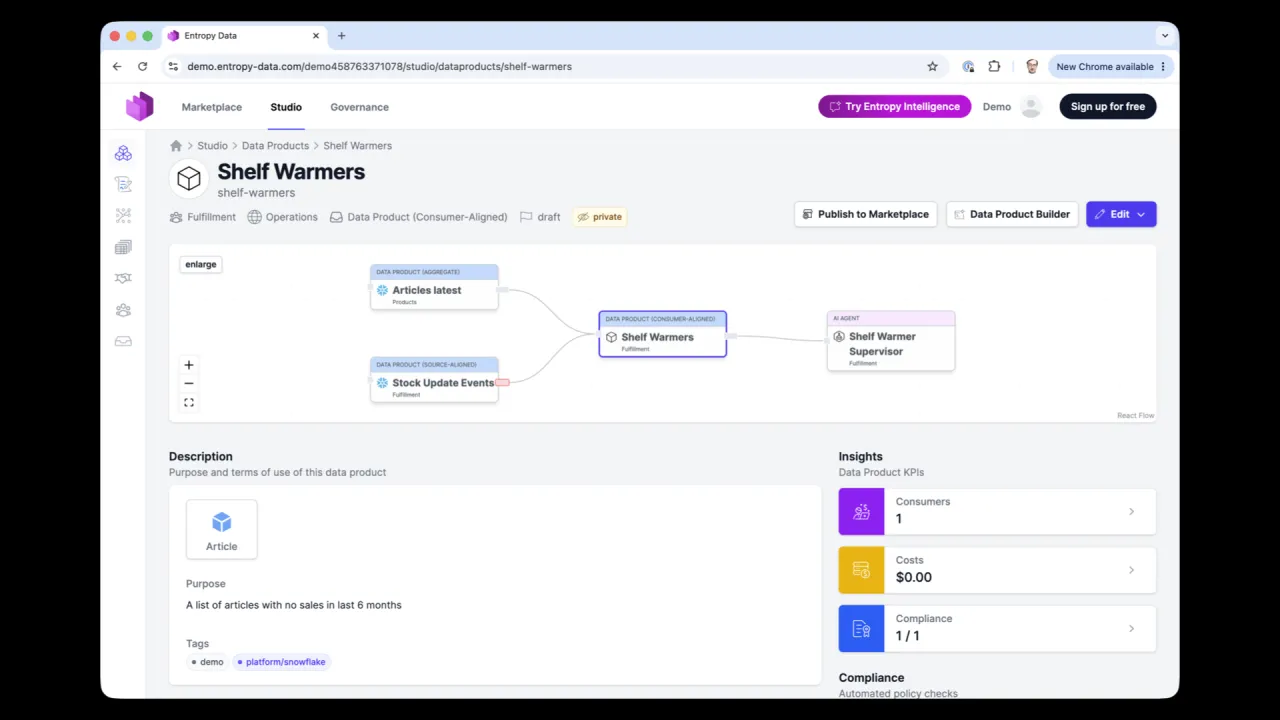
The Result
The agent triggered the implement skill, thought hard, and wrote a full dbt project, input ports, output ports, and the transformation that joins articles against current stock and last sale.
When the dbt project ran, it created the database, schema, and SHELF_WARMERS table in Snowflake. It took about ten minutes and never asked a single follow-up question.
Along the way it determined it needed two upstream data products, requested access automatically (they were not sensitive, so it was auto-approved), and then published the finished Shelf Warmers product back into the marketplace, where the read agents from the first half of the talk can now find it.

Step 4, Publish: Back Where We Started
Publishing closes the loop. The new product lands in the marketplace, where other agents, and humans, can discover it and request access, exactly as the read demo did at the start of the talk.
Build, publish, read. The same marketplace that lets agents read data is the one that lets agents build it.

Bonus: Handling a Change Request
What happens when a consumer asks for more, say, "the brand name is missing, please add it"? You change the contract first: add a brand_name column, anchored to the brand concept that already exists in the semantic layer.
The contract now no longer matches Snowflake, so you go back to the coding agent, "implement the shelf-warmers data product", and it updates the dbt project to source and expose the new field, automatically, in a couple of minutes. (Shown in description only, for time.)

Thank You
That is the case: agents need a data marketplace to read data and to build data products. The call to action is simply, let's connect them up.
Try the contract-based data product marketplace yourself at demo.entropy-data.com, reach Simon at simon.harrer@entropy-data.com or on LinkedIn, and give datacontract-cli a star on GitHub if it has been useful.
Q&A
From the audience after the talk.
Q: Can you get any data in any form into the marketplace, Confluence pages, PDFs, databases, or do you need a discovery and transformation phase first?
Today the focus is mostly on relational data; unstructured sources like PDFs are not wired in yet. But the understand and specify steps are exactly where other sources help. Rather than filling everything in by hand, you can connect tools, for example to Confluence, to pull in context so you know what you want to build and can define the interface well. You can absolutely use AI for that part too. It just was not the focus of this talk.