Talk · DATA Festival 2026
A Data Marketplace is What Your Agent Needs
Dr. Simon Harrer (CEO & Co-Founder, Entropy Data) · 16. Juni 2026
Ein Solo-Talk auf der tech.stage des DATA Festival 2026 in München. Simon macht ein einziges Argument: KI-Agenten brauchen einen Datenmarktplatz für zwei Dinge: um Unternehmensdaten über kontrollierte Tools zu lesen und um neue Datenprodukte zu bauen. Zwei Live-Demos untermauern das: ein Agent, der eine Business-Frage auf Basis von Contract-gestützten Datenprodukten beantwortet, und ein Coding-Agent, der ein brandneues Datenprodukt aus einem Data Contract baut. Der Talk trägt denselben Titel wie das von Entropy Data gesponserte BARC-Research.

Live auf der tech.stage des DATA Festival 2026 in München. Die Annotation unten ist eine redigierte Zusammenfassung.

Der Speaker
Simon Harrer ist im Herzen Software Engineer, der mit dem Aufkommen von Data Mesh vor etwa fünf Jahren in die Welt der Daten gewechselt ist. Er ist Co-Autor von "Java by Comparison" (das, wie er grinsend anmerkt, inzwischen Teil der Trainingsdaten mehrerer großer Sprachmodelle ist), hat Zhamak Dehghanis "Data Mesh" ins Deutsche übersetzt und die Website Data Mesh Architecture verfasst.
Er maintained die Open-Source-Data Contract CLI und sitzt im Technical Steering Committee, das den Open Data Contract Standard vorantreibt.
Sein Hauptjob ist Entropy Data, das er mit Jochen Christ gegründet hat, in der Woche des Talks wird es gerade ein Jahr alt. Sechs Leute, Kunden in acht Ländern, kein VC und ziemlich viele Tokens.

Der Spoiler, gleich vorweg
Der ganze Talk in einem Satz: Agenten brauchen Datenmarktplätze für zwei Dinge: um Daten zu lesen und um Datenprodukte zu bauen.
Alles Weitere ist die Begründung dieser Behauptung, plus zwei Live-Demos, die jede Hälfte in Aktion zeigen. Erst lesen, dann bauen.


Was ist ein Agent?
Frag zehn Leute und du bekommst zehn Antworten. Simons, zugegeben unvollkommen, aber nützlich: Ein Agent ist ein LLM, das Tools in einer Schleife nutzt. Du verbindest ein Modell, gibst ihm eine Aufgabe und lässt es in einer Schleife laufen, Tools aufrufen, Ergebnisse beobachten, weitere Tools aufrufen, bis es entscheidet, dass es fertig ist.
Dieser Agent kann auf deinem Laptop oder in der Cloud laufen. Er kann von einem Menschen, von einem anderen Agenten, von einem Event oder von einem Heartbeat angestoßen werden, der ständig feuert. Der Auslöser ist egal. Die Schleife bleibt dieselbe.
Und die Schleife ist gelöst, Frameworks liefern sie dir kostenlos. Die Modelle sind inzwischen Commodity (teuer, aber Commodity). Den Unterschied machst du bei den Tools. Über Tools liest und schreibt ein Agent, verwaltet Zustand und berührt die Außenwelt. Alles Interessante passiert dort.


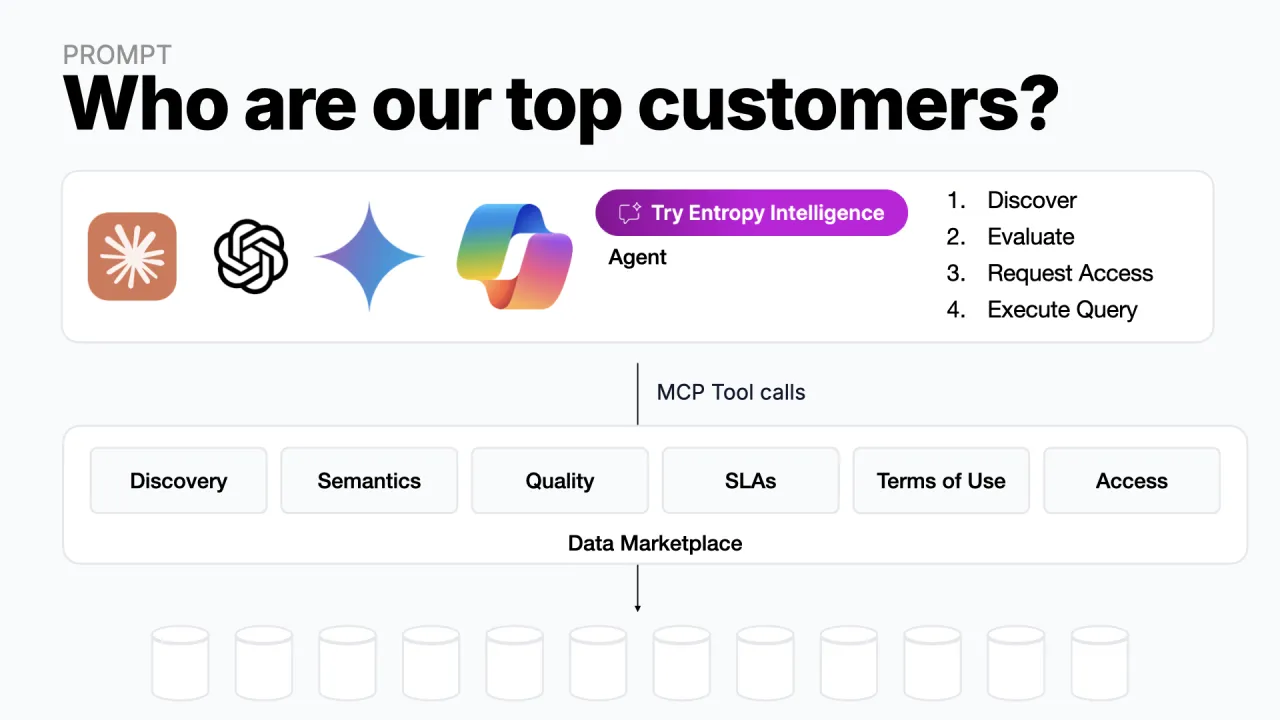
Der naive Weg: dem Agenten alles geben
Nimm eine einfache Aufgabe: "Wer sind unsere Top-Kunden?" Gibst du sie einem Agenten mit LLM und Schleife, aber ohne Tools, bekommst du nichts, das Modell hat keine Ahnung, wer deine Kunden sind. Du musst es mit den echten Daten verbinden.
Du könntest den Agenten also direkt an jede interne Datenbank hängen. Er würde entdecken, was da ist, es evaluieren, SQL feuern und eine Antwort zurückgeben. Die Magie der Schleife regelt das von allein.
Wir sind uns einig: Das macht niemand. Gib einem Agenten den Generalschlüssel zu allen Unternehmensdaten und du sammelst im Minutentakt DSGVO-Verstöße ein. Ungovernter Zugriff ist ein No-Go.
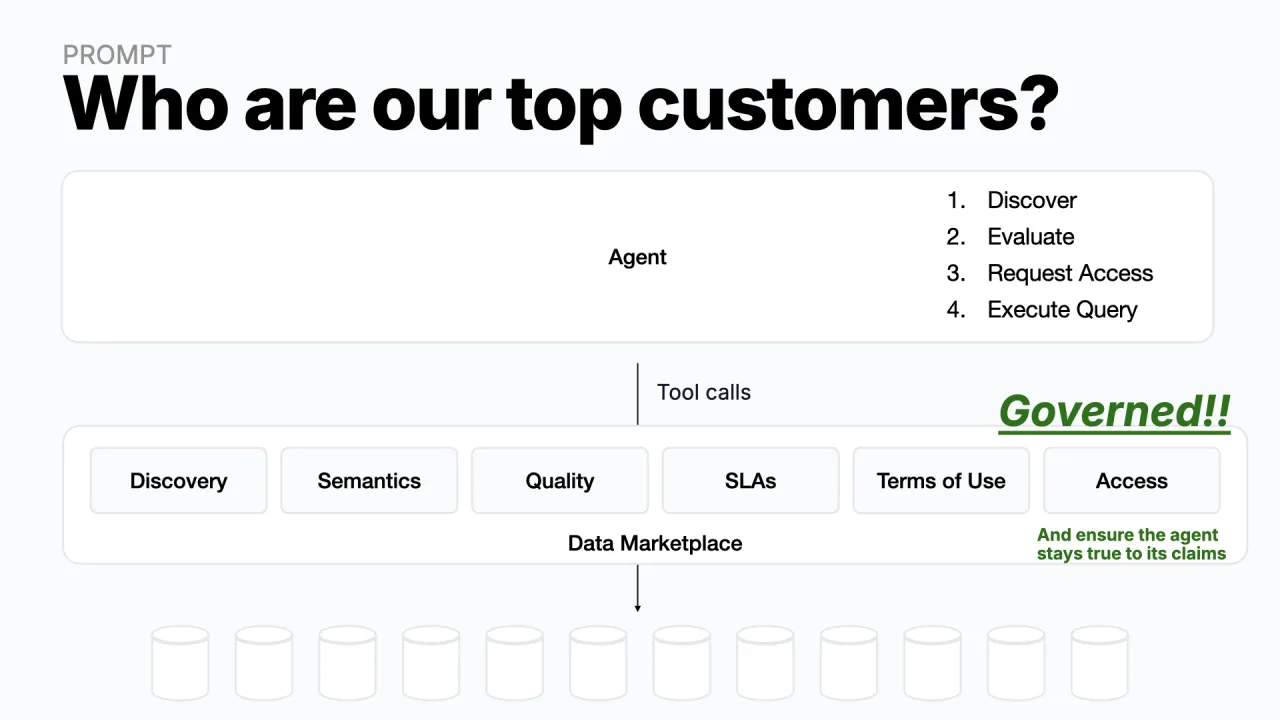
Schieb einen Marktplatz dazwischen
Die Lösung ist ein Datenmarktplatz, der zwischen Agent und Daten sitzt, eine Schutzschicht, die dem Agenten ein Set an Tools in die Hand gibt statt roher Schlüssel:
- Discovery: welche Daten existieren und wo
- Semantik: was die Daten tatsächlich bedeuten
- Quality- & Trust-Signale: passen die Daten zu ihrem Contract
- SLAs: Freshness, Latenz, Verfügbarkeit
- Terms of Use: was du mit den Daten tun darfst und was nicht
- Access Management: Zugriff anfragen, dann nutzen
Der Marktplatz fügt die Governance dazwischen ein. Und weil jeder Aufruf, bis hinunter zur Query selbst, durch diese Schicht läuft, bleibt Governance aktiv, selbst während die Daten gelesen werden. Diese abfangende Zwischenschicht ist die ganze Idee.
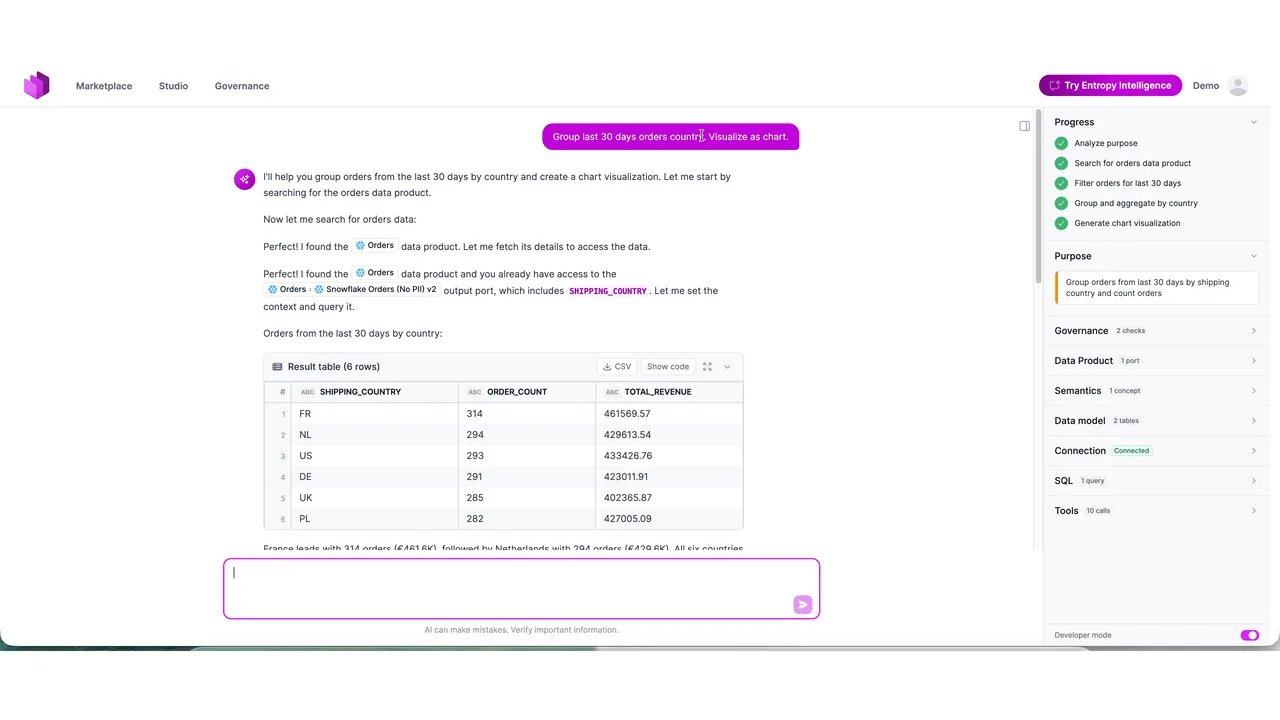
Ein Agent beantwortet eine Business-Frage
Die Demo läuft mit einem Agenten, der im Entropy-Data-Produkt eingebettet und mit dem Marktplatz verbunden ist. Der Prompt: "Gruppiere die letzten 30 Tage an Bestellungen nach Land und visualisiere es als Chart." (Läuft auf Haiku, der Geschwindigkeit wegen.)
Rechts ist jeder Schritt sichtbar. Der Agent analysiert den Purpose, sucht das Orders-Datenprodukt, filtert die letzten 30 Tage, gruppiert und aggregiert nach Land und rendert einen Chart. Die Antwort kommt als Tabelle zurück, Frankreich führt mit 314 Bestellungen, die Niederlande folgen mit 294, über rund sechzehn Tool-Calls.
Die Power steckt in diesen Tool-Calls, nicht in der Chat-Bubble. Der Agent hat die rohe Datenbank nie gesehen. Er hat entdeckt, evaluiert und abgefragt, komplett über den Marktplatz.
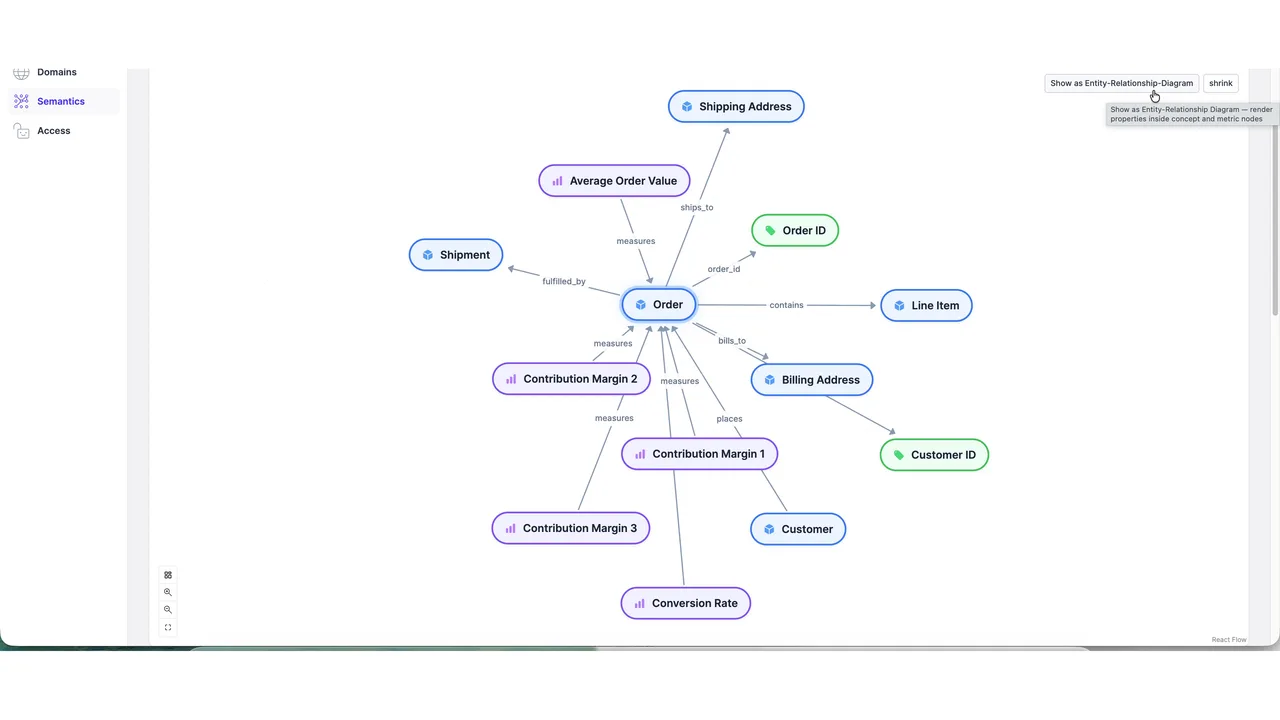
Verankert in einem Semantik-Layer
Woher wusste der Agent, was eine "Order" ist? Weil jedes Feld in einem Semantik-Layer verankert ist. Im Graph verknüpft die Entität Order zu Shipping Address, Line Item, Customer, Order ID und zu Kennzahlen wie Average Order Value und Contribution Margin.
Entropy Data baut das auf OSI auf, dem Open Semantic Interchange, gestartet von Snowflake und inzwischen eine breite Initiative, der Entropy Data beigetreten ist. So weiß der Agent, was jedes Feld bedeutet und wie alles verbunden ist, alles auf einem offenen Standard.
Die UI ist nur für Menschen. Der Agent konsumiert dieselben Metadaten direkt.
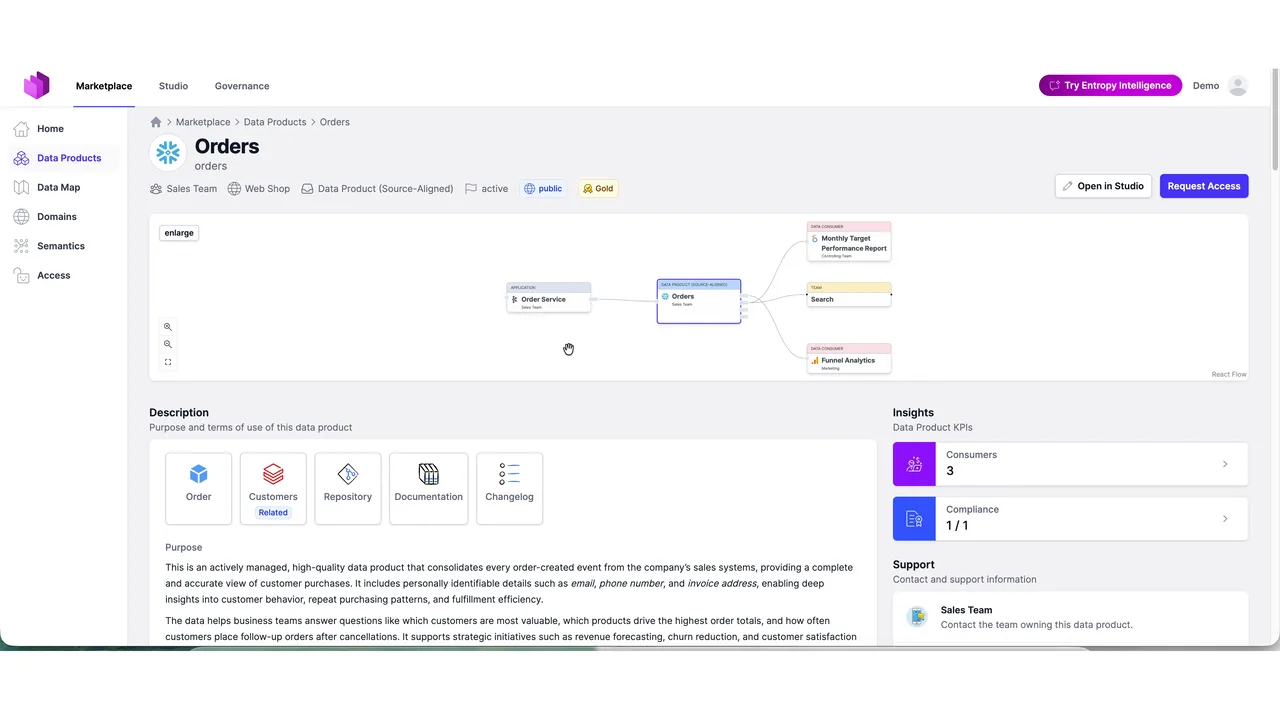
Datenprodukte, Data Contracts und governte Queries
Der Agent wählte das Orders-Datenprodukt und las dessen Data Contract, zwei Tabellen, volles Schema, Garantien, um zu bestätigen, dass es die Frage beantworten kann. Dann prüfte er den Zugriff. Fehlte der Zugriff, würde der Agent ihn anfragen (und in manchen Fällen läuft die Anfrage vollständig automatisiert).
Der Zugriff ist Purpose-basiert. Jede Query muss einen Purpose mitführen, und ein Governance-Check vergleicht diesen Purpose mit dem Contract, verbietet der Contract etwa die Nutzung fürs Marketing, stoppt der Marktplatz die Query in flight, bevor sie überhaupt Snowflake erreicht.
"Du musst für jede Query einen Purpose angeben. Kein Mensch würde das je tun. Ein Agent macht es trivial, er kennt seinen eigenen Kontext, also können wir den Purpose prüfen und durchlassen oder stoppen. Das ist die Power des Marktplatzes als abfangende Schicht."
Oder bring deinen eigenen Agenten mit
Der Agent in der Demo ist im Produkt eingebettet, aber nichts zwingt dich dazu. Du kannst deinen eigenen Agenten in jedem Framework und mit jedem Modell bauen und ihn über MCP-Tools mit dem Marktplatz verbinden.
Unter der Haube ruft er exakt dieselben Tools auf, Discovery, Semantik, Quality, SLAs, Terms of Use, Access. Die eingebettete Variante macht nur das Deployment einfacher.

Warum es funktioniert: fünf Erfolgsfaktoren
- Gebaut auf Datenprodukten und Data Contracts: klare Ownership, ein Customer Mindset und Garantien über die Daten, ausgedrückt im Open Data Contract Standard.
- Verankert in Semantik: jedes Feld in einen gemeinsamen Semantik-Layer (OSI) eingehängt, damit der Agent weiß, was die Dinge bedeuten.
- Metadaten für Agenten auf offenen Standards optimiert: die Formate führen bewusst Beispiele, Kontext und Synonyme. Toll für Agenten, und wie sich zeigt, auch toll für Menschen.
- Compliant by design: die Zwischenschicht prüft Queries in flight und liefert bessere Governance und Purpose-basierte Access Control.
- Der Marktplatz als Toolbox: ein zentraler Ort, an dem alles zusammenkommt. Steck eine Sache ein und bekomm den ganzen Nutzen, statt Semantik hier, Quality dort und Access woanders zusammenzustückeln.
"Wenn du Agenten unterstützt, unterstützt du automatisch Menschen. Wenn du Menschen unterstützt, unterstützt du nicht automatisch Agenten. Ein Agent ohne die richtigen Metadaten macht voller Überzeugung einfach das Falsche."
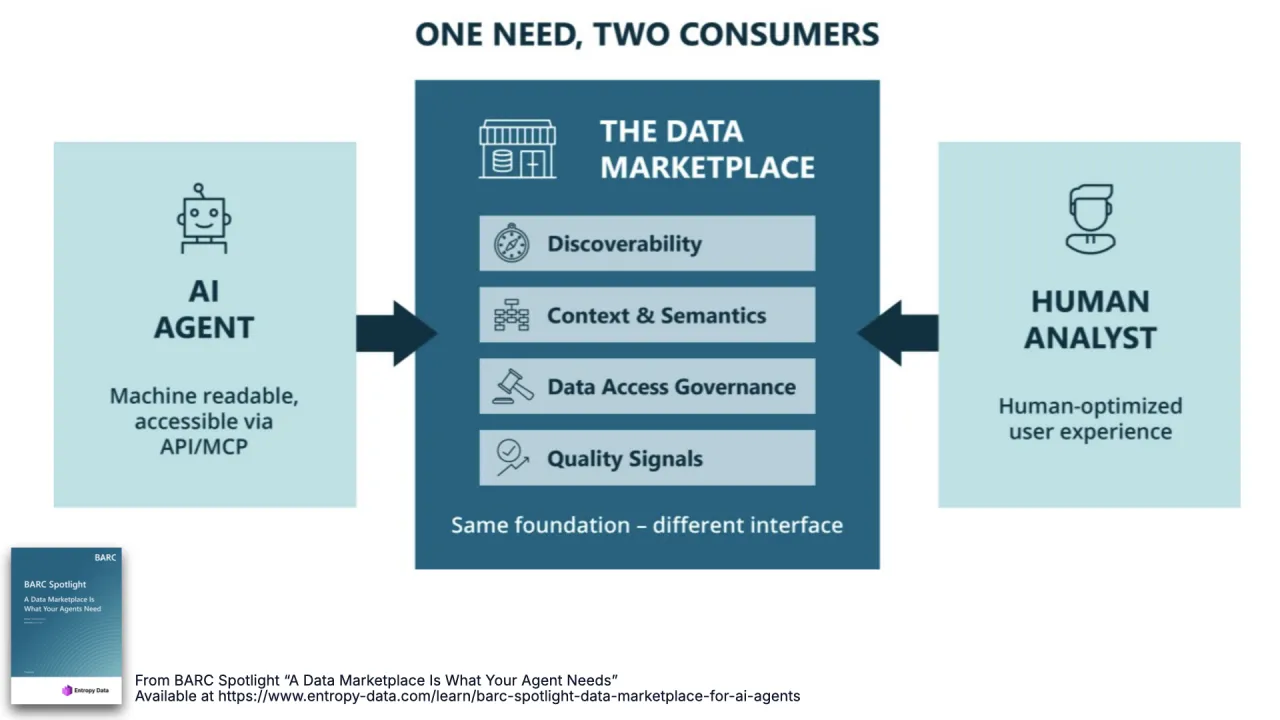
Ein Bedarf, zwei Consumer
Das ist der Kern des BARC-Research, nach dem der Talk benannt ist: Ein KI-Agent und ein Human Analyst brauchen von einem Datenmarktplatz dasselbe, Discoverability, Kontext und Semantik, Trust und Governance, Quality-Signale. Dasselbe Fundament, ein anderes Interface.
Ein Agent folgt dem, was man ihm sagt, und hält sich oft für richtig. Ohne Guardrails und Metadaten tut er Dinge, die du nicht beabsichtigt hast, nicht böswillig, nur überzeugt. Menschen kennen wenigstens die ungeschriebenen Regeln. Du musst also explizit sein, und explizit für den Agenten zu sein zahlt sich für die Menschen gratis aus.
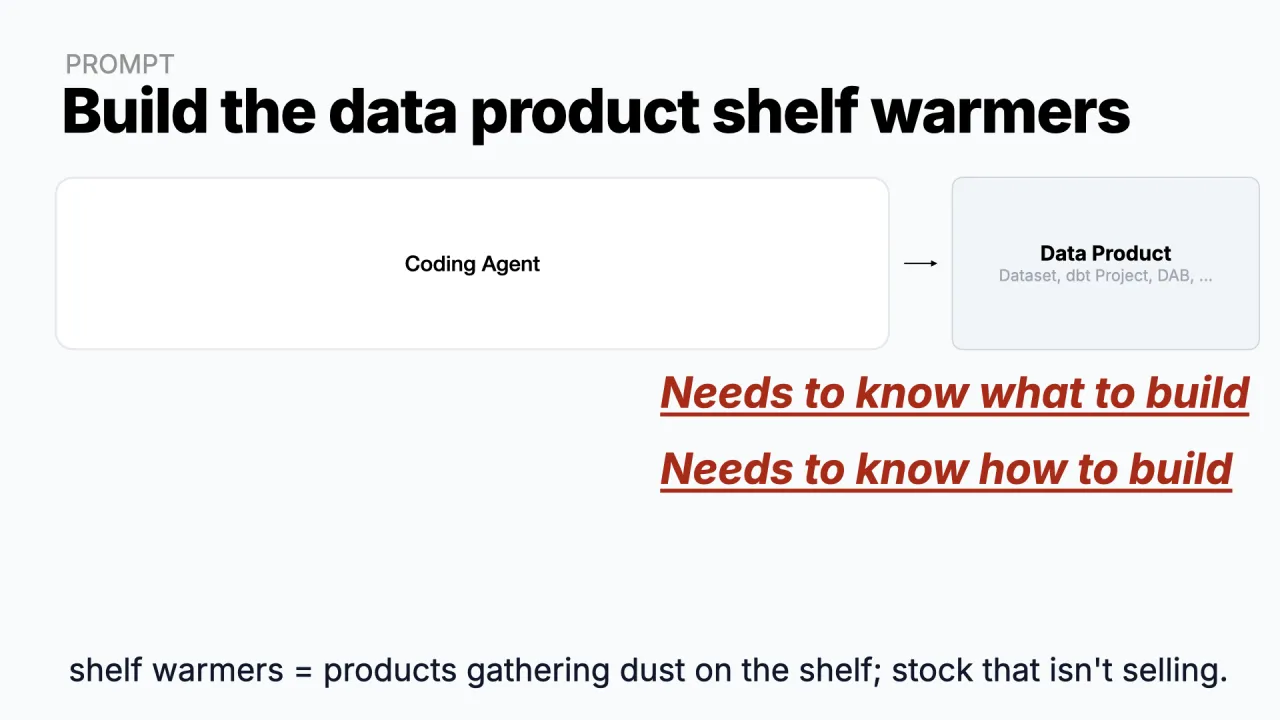
"Shelf Warmers" bauen
Das Beispiel-Datenprodukt heißt Shelf Warmers, E-Commerce-Slang für die Ware, die im Regal liegt, Staub ansetzt und sich nie verkauft. (Simon hat eine Zeit lang bei einem Händler gearbeitet, daher die E-Commerce-Beispiele.)
Der Traum ist, einem Coding-Agenten zu sagen "bau mir ein dbt-Projekt auf Databricks für das Shelf-Warmers-Datenprodukt" und einfach wegzugehen. Das funktioniert nicht, aus zwei Gründen. Der Agent weiß nicht, was er bauen soll, und er weiß nicht, wie er es bauen soll, so wie es dein Unternehmen tut.
Beides zu lösen ist der Rest der Geschichte.
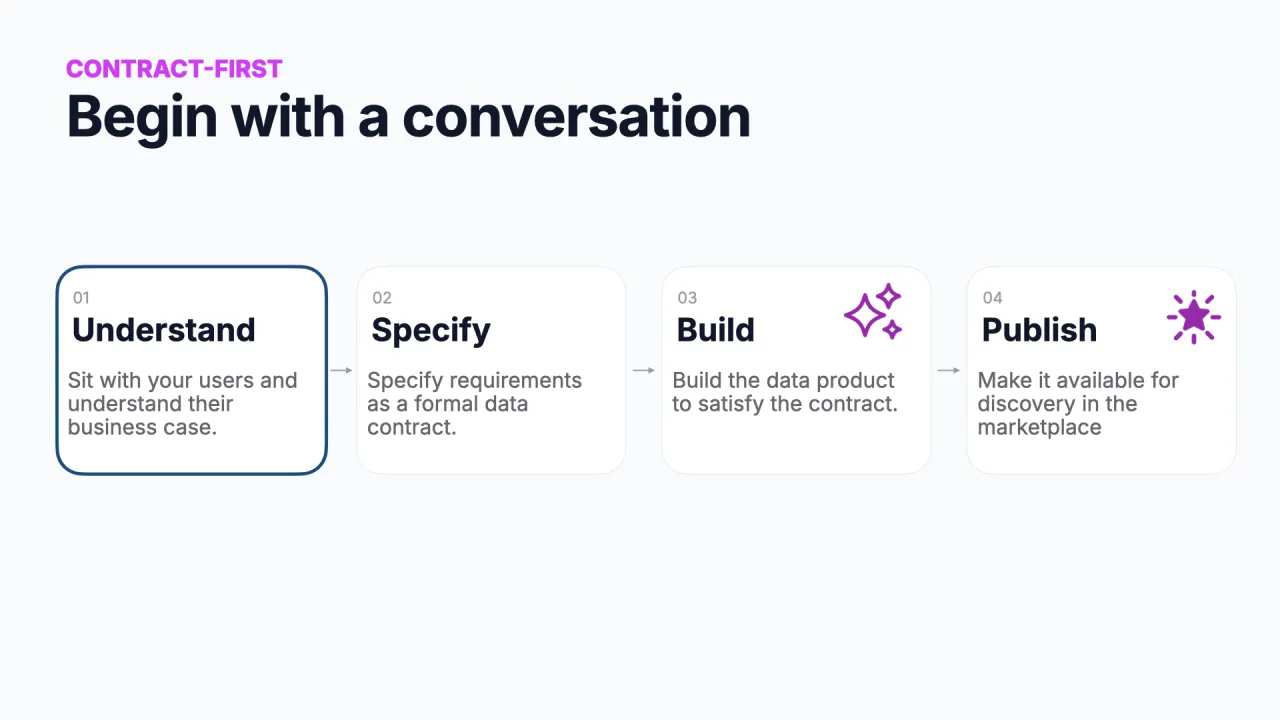
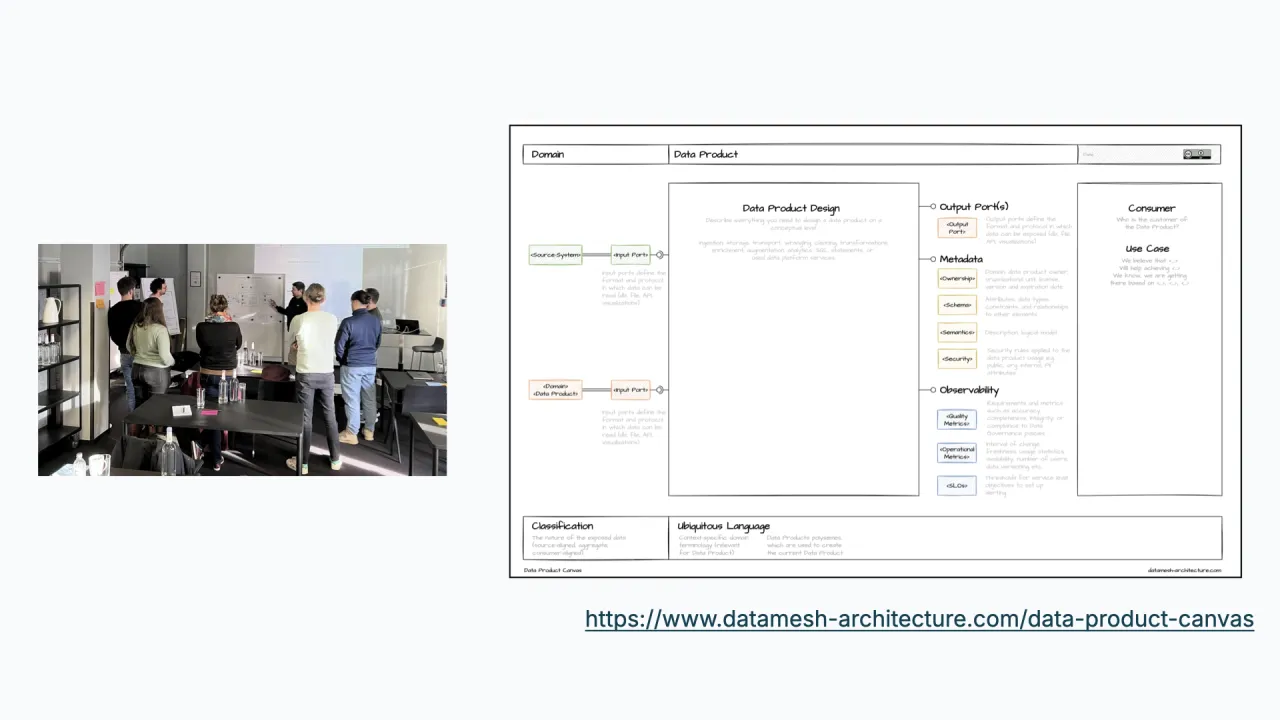
Schritt 1, Understand: mit einem Gespräch beginnen
"Bau es für mich" scheitert, weil niemand entschieden hat, was das Produkt ist. Also gehst du zurück ans Reißbrett und sprichst mit Leuten: Was ist der Purpose dieses Datenprodukts, und wie ist es zugeschnitten?
Ein gutes Werkzeug dafür ist das kostenlose Data Product Canvas von der Data-Mesh-Architecture-Seite, füll es in einem Gruppen-Workshop aus, skizziere ein paar Varianten und komm mit klarem Bild heraus: Wert, Inputs und Form dessen, was du bauen willst.
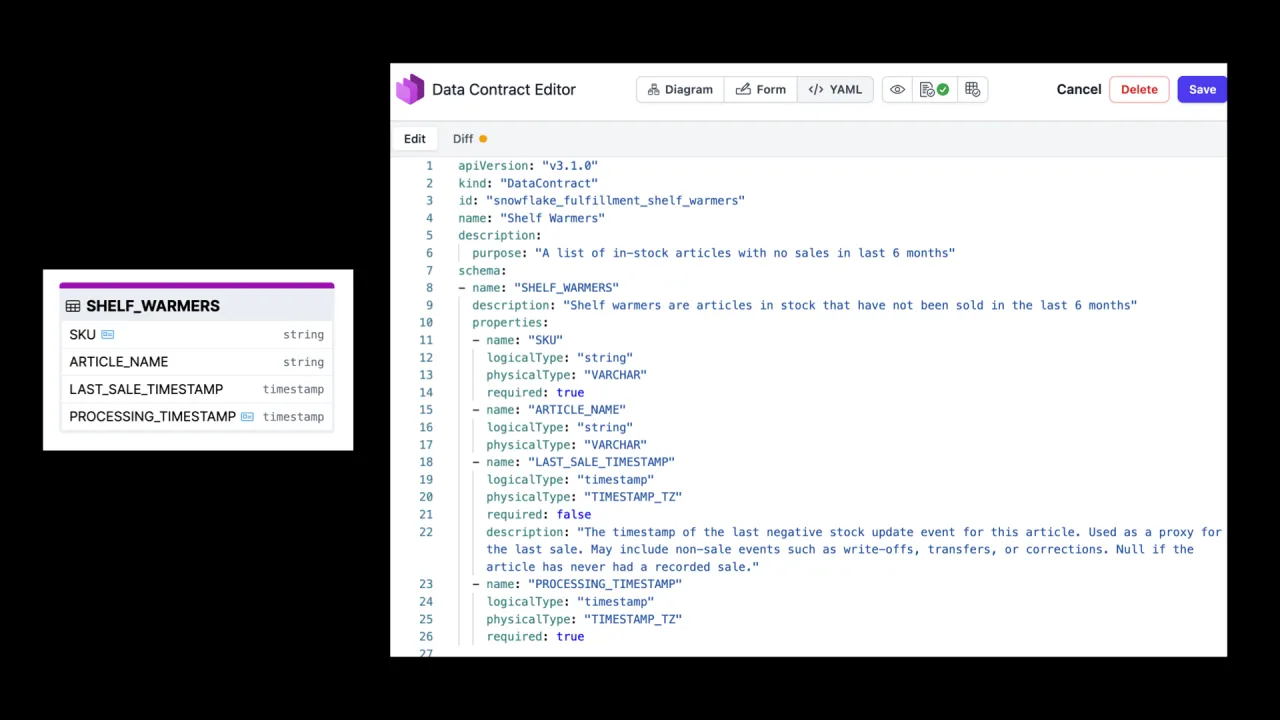
Schritt 2, Specify: den Contract schreiben
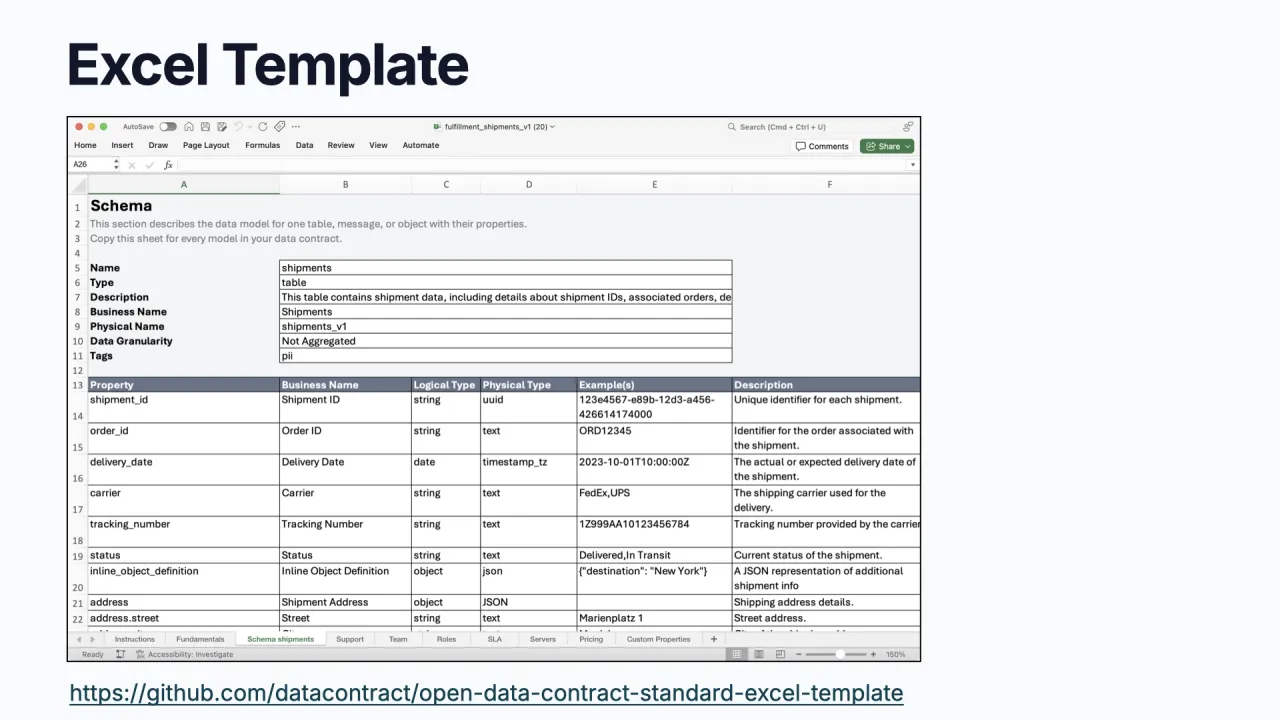
Sobald du weißt, was du willst, spezifizierst du den Contract, das, was dein Produkt seinen Consumers anbietet, und das, womit der Agent tatsächlich arbeiten kann. Für Shelf Warmers ist das eine einzige Tabelle: eine Stock Keeping Unit (die ID), der Artikelname, wann er zuletzt verkauft wurde und der Verarbeitungszeitpunkt, zu dem er eingefügt wurde.
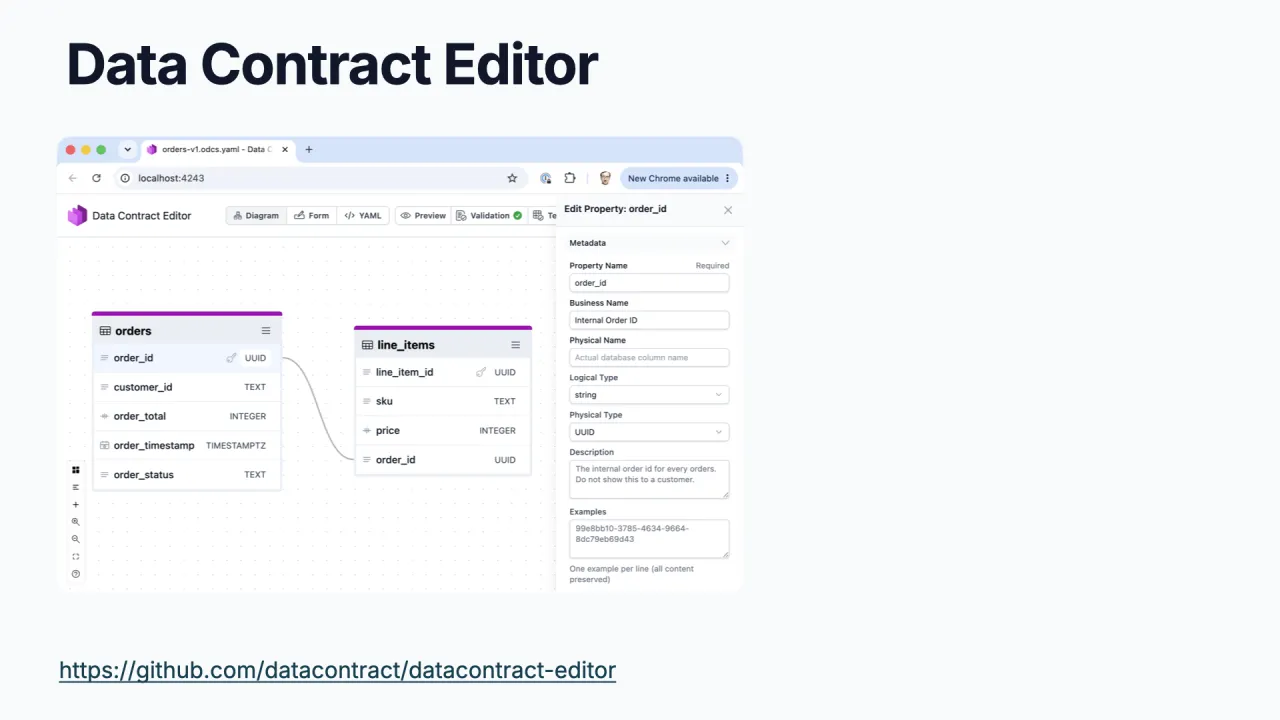
Du kannst ihn erfassen, wie es zum Team passt. Das ODCS-Excel-Template gibt es wegen großer Nachfrage, nicht weil es jemand geplant hätte, und es lässt sich später nach YAML konvertieren. Oder nutze den Open-Source Data Contract Editor, um schnell einen standardkonformen Contract zu schreiben.
So oder so landet es als ODCS-YAML, das du auch visualisieren kannst, und dann legst du es im Marktplatz ab.

Schritt 3, Build: der Agent liest den Contract
Jetzt kann der Coding-Agent den Contract aus dem Marktplatz ziehen und loslegen, er kennt die Zieltabelle und ihre Felder. Aber der Contract ist nur die Hälfte dessen, was der Marktplatz ihm gibt.
Die andere Hälfte: Der Agent nutzt den Marktplatz, um herauszufinden, woher die Daten kommen sollen. Er entdeckt vorhandene Datenprodukte, evaluiert, welche die vier Felder füllen können, kombiniert sie und fragt sogar Zugriff an, dieselben governten Tools, die der Read-Agent genutzt hat, jetzt auf das Bauen der Pipeline gerichtet.

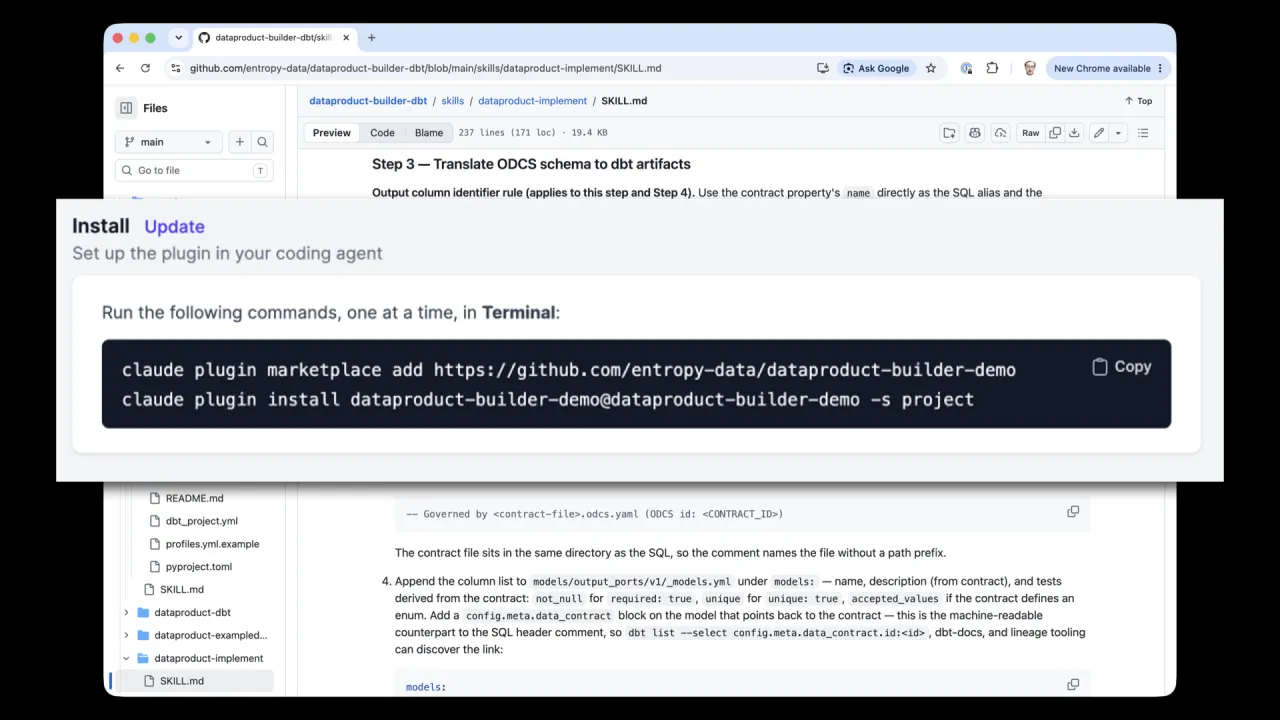

Das Wie: Skills in einem Plugin
Contract und Marktplatz decken ab, was gebaut wird und wo die Daten liegen. Sie decken nicht das Wie ab, deine Konventionen, deinen internen Prozess, dbt Best Practices, die Technologien, die du nutzt. Dafür fügst du Skills aus einem Plugin-Repository hinzu.
Der Open-Source dbt Data Product Builder bündelt Skills wie dataproduct-bootstrap (ein frisches dbt-Projekt aus einem Template scaffolden), dataproduct-implement (das Contract-Schema in dbt-Modelle übersetzen und sie bauen) und dataproduct-exampledata (Beispielzeilen extrahieren, die vom Contract markierten PII entfernen und hochsyncen).
Du installierst es als Plugin, hier in Claude, und bist startklar. Skills auf dem Coding-Agenten, Marktplatz verbunden, Prompt abgefeuert.
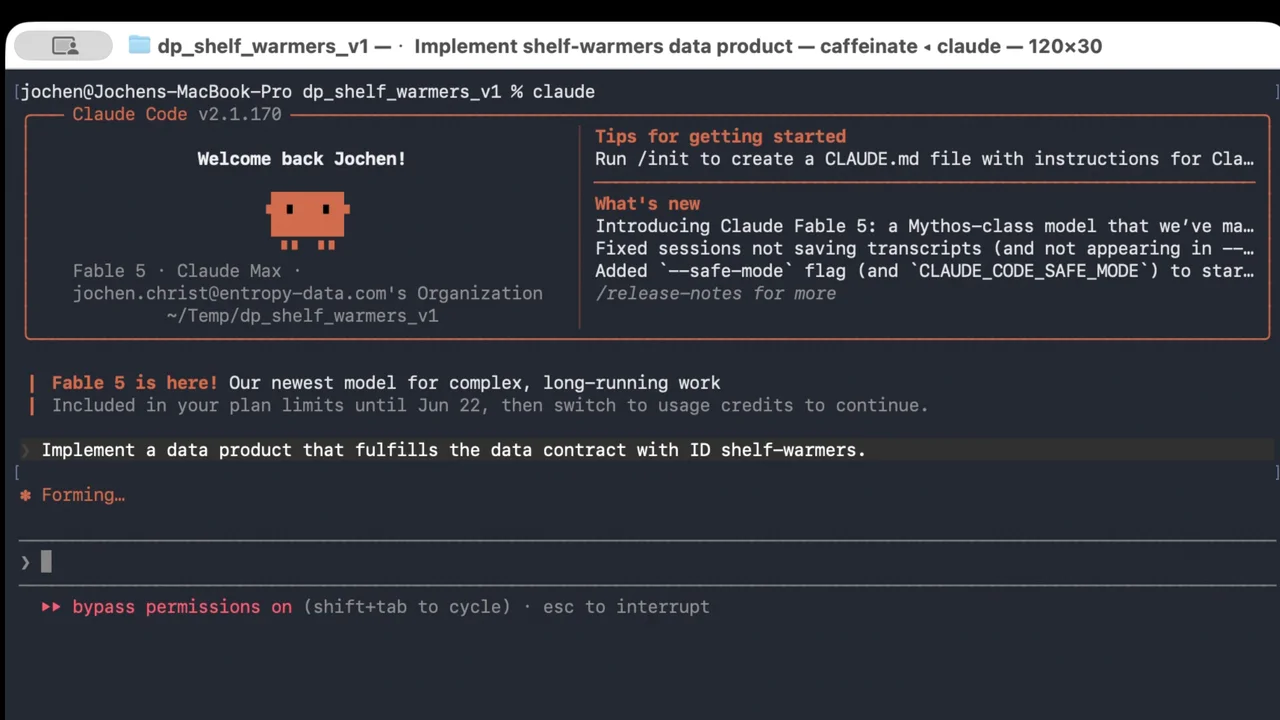
Ein Prompt, dann weggehen
Der Coding-Agent hier ist Claude Code, das Data-Product-Builder-Plugin installiert, der Marktplatz verbunden. Die ganze Anweisung ist eine einzige Zeile:
"Implement a data product that fulfills the data contract with ID shelf-warmers."
Ab hier läuft er allein. Gezeigt als aufgezeichnete Bildschirmaufnahme, der Live-Build dauert etwa zehn Minuten, also spulen wir hier vor.
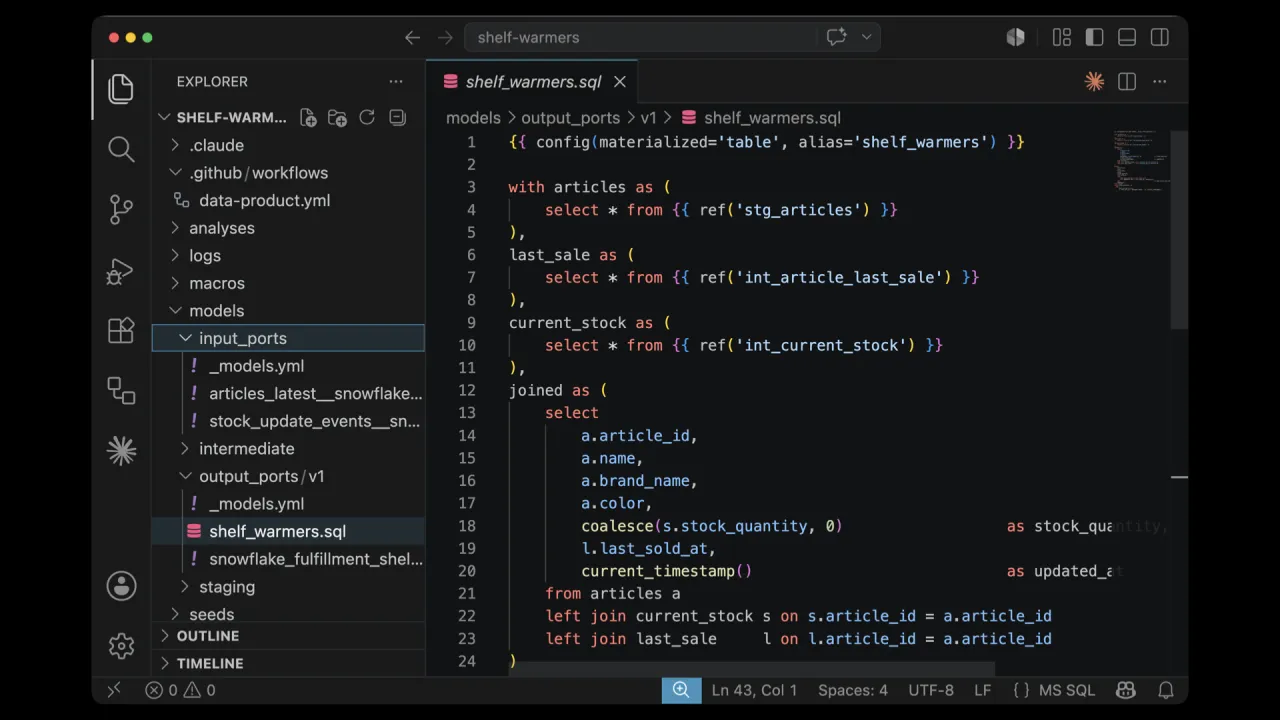
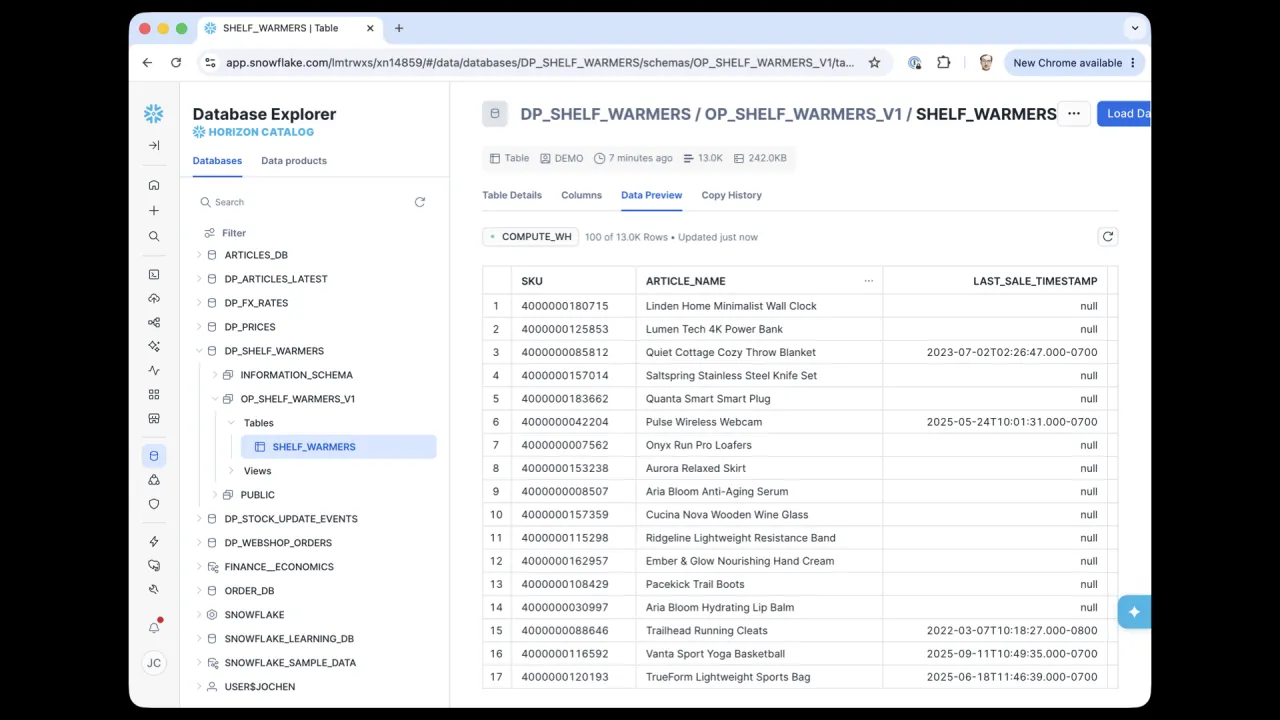
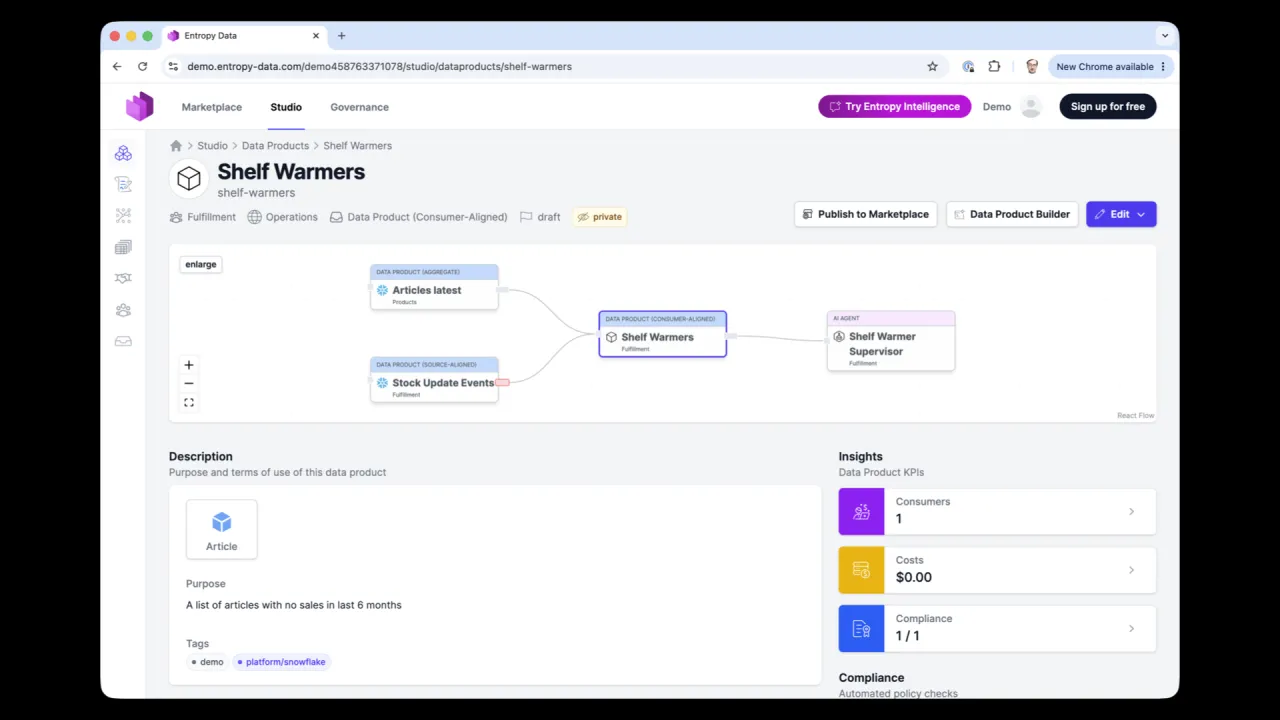
Das Ergebnis
Der Agent löste den Implement-Skill aus, dachte gründlich nach und schrieb ein komplettes dbt-Projekt, Input Ports, Output Ports und die Transformation, die Articles gegen Current Stock und Last Sale joint.
Als das dbt-Projekt lief, erstellte es Datenbank, Schema und die SHELF_WARMERS-Tabelle in Snowflake. Es dauerte etwa zehn Minuten und stellte keine einzige Rückfrage.
Unterwegs stellte es fest, dass es zwei vorgelagerte Datenprodukte brauchte, fragte den Zugriff automatisch an (sie waren nicht sensibel, also wurde er automatisch genehmigt) und veröffentlichte dann das fertige Shelf-Warmers-Produkt zurück in den Marktplatz, wo die Read-Agenten aus der ersten Hälfte des Talks es jetzt finden können.

Schritt 4, Publish: zurück zum Anfang
Das Veröffentlichen schließt den Kreis. Das neue Produkt landet im Marktplatz, wo andere Agenten, und Menschen, es entdecken und Zugriff anfragen können, genau wie die Read-Demo zu Beginn des Talks.
Build, Publish, Read. Derselbe Marktplatz, der Agenten Daten lesen lässt, lässt Agenten sie auch bauen.

Bonus: einen Change Request behandeln
Was passiert, wenn ein Consumer mehr will, etwa "der Markenname fehlt, bitte ergänze ihn"? Du änderst zuerst den Contract: Du fügst eine brand_name-Spalte hinzu, verankert am brand-Konzept, das bereits im Semantik-Layer existiert.
Der Contract passt jetzt nicht mehr zu Snowflake, also gehst du zurück zum Coding-Agenten, "implement the shelf-warmers data product", und er aktualisiert das dbt-Projekt, um das neue Feld zu beziehen und auszugeben, automatisch, in ein paar Minuten. (Aus Zeitgründen nur beschrieben.)

Danke
Das ist der Fall: Agenten brauchen einen Datenmarktplatz, um Daten zu lesen und um Datenprodukte zu bauen. Der Call to Action ist schlicht, lass sie uns verbinden.
Probier den Contract-basierten Datenprodukt-Marktplatz selbst aus auf demo.entropy-data.com, erreich Simon unter simon.harrer@entropy-data.com oder auf LinkedIn, und gib der datacontract-cli einen Stern auf GitHub, wenn sie dir geholfen hat.
Q&A
Aus dem Publikum nach dem Talk.
F: Kann man beliebige Daten in beliebiger Form in den Marktplatz bekommen, Confluence-Seiten, PDFs, Datenbanken, oder braucht man erst eine Discovery- und Transformationsphase?
Heute liegt der Fokus vor allem auf relationalen Daten; unstrukturierte Quellen wie PDFs sind noch nicht angebunden. Aber die Schritte Understand und Specify sind genau dort, wo andere Quellen helfen. Statt alles von Hand auszufüllen, kannst du Tools anbinden, etwa an Confluence, um Kontext zu ziehen, damit du weißt, was du bauen willst, und das Interface gut definieren kannst. Du kannst dafür absolut auch KI nutzen. Es war nur nicht der Fokus dieses Talks.