Wissen
Data Product Builder: Datenprodukte mit deinem Coding Agent bauen
Schreib als Data Contract auf, was du willst, und lass deinen Coding Agent es bauen. In Minuten implementiert, vollständig konform mit deinen Konventionen, vollständig in Entropy Data integriert.
Datenprodukte im Zeitalter der Coding Agents implementieren
Data Engineers bauen Datenprodukte heute mit Coding Agents wie Claude Code oder OpenAI Codex. Ein Data Product Builder ist ein Plugin für den Coding Agent, das die Konventionen, Qualitätsstandards, Deployment-Patterns und Marketplace-Integration deiner Organisation in Entropy Data kodiert. Der Agent nutzt diese, um in Minuten ein produktionsreifes Datenprodukt zu scaffolden. Vollständig getestet, konform mit der Governance von Entropy Data, bereit zum Ausliefern.
Contract-Driven Development
Aber was soll der Coding Agent eigentlich implementieren? Ein Data Contract beschreibt, was ein Datenprodukt liefert: Schema, Semantik, Qualitätsregeln, SLAs und Nutzungsbedingungen. Es ist die Spezifikation, die ein Consumer lesen kann und ein Producer erfüllen muss.
Behandle diese Spezifikation als Input für die Implementierung durch den Coding Agent. Schreib oder erweitere zuerst den ODCS-Contract. Übergib ihn dann dem Agent, der die Datenpipeline, Tests, den CI-Workflow und die Lineage-Verdrahtung generiert, die ihn erfüllen.
Der Coding Agent kann den Entropy-Data-Marketplace nach Datenquellen durchsuchen, die zu den Anforderungen passen.
Am Ende läuft datacontract test gegen das Ergebnis und bestätigt, dass die Live-Daten passen.
Datenprodukte bauen und weiterentwickeln
Für ein neues Produkt: Entwirf den Contract (Schema, Typen, Qualitätsregeln) im Entropy-Data-Editor oder in YAML. Öffne den Builder-Tab auf der Datenprodukt-Seite, kopiere den vorgefüllten Prompt und füge ihn in deinen Coding Agent ein. Der Agent scaffoldet das dbt-Projekt, die Output-Port-Modelle, den GitHub-Actions-Workflow und öffnet einen Pull Request. CI führt datacontract test aus, um zu verifizieren, dass die Live-Daten den Contract erfüllen. Dann releasest du.
Für ein bestehendes Produkt: Drift Detection meldet, wenn die Live-Implementierung nicht zum Contract passt. Beispiel: Das Shelf-Warmers-Produkt braucht eine neue Spalte brand. Bearbeite den Contract („Add a brand column of type string, not null"), bitte den Agent, die dbt-Modelle neu zu implementieren, und führe datacontract test aus, um zu bestätigen. Gleicher Workflow, gleicher Agent, gleiche Validierung.
Verfügbare Templates
Entropy Data stellt Open-Source-Templates für den Data Product Builder bereit: Git-Repositories mit Skills, Hooks und File-Scaffolding. Jedes Template bringt einem Coding Agent bei, wie er Datenprodukte auf einem bestimmten Stack baut. Nutze ein Template wie es ist, oder forke es und passe es an die Konventionen deiner Organisation an.
- dataproduct-builder-dbt. dbt auf beliebigen Adaptern: Snowflake, BigQuery, Databricks, Redshift, Postgres, DuckDB. GitHub Actions für CI. Volle Integration mit Entropy Data: ODPS, ODCS, OpenLineage-Lineage und Drift Detection.
- Databricks Asset Bundles. Kommt bald.
- Snowflake Native Apps Framework. Kommt bald.
- AWS Glue. Kommt bald.
Community- und Custom-Templates sind willkommen. Reiche einen Pull Request für die dataproduct-builders-Registry ein, um dein Template zu listen.
Wie es funktioniert
Coding Agents arbeiten mit anpassbaren Templates: Git-Repositories mit Skills, Hooks und Scaffolding. Forke ein Template, pass es an die Konventionen deiner Organisation an und bleib bei Updates synchron.
Git-Repository
Ein Template ist ein Git-Repository mit Skills (Prompts, die den Agent bei bestimmten Aufgaben anleiten), Datei-Templates (das Scaffolding für deinen Stack), Hooks (Validatoren, die nach Tool-Aufrufen laufen) und optionalen Subagenten. Zum Beispiel deckt dataproduct-builder-dbt dbt auf beliebigen Adaptern ab. Nutze es wie es ist, oder kopiere es in deine eigene Organisation und passe es an: Ersetze die Model-Layer-Benennung, tausche GitHub Actions gegen Airflow, ergänze interne Lint-Regeln, bette deine PII-Taxonomie ein.
Entropy Data CLI
Die Entropy Data CLI ist die Brücke zwischen deinem lokalen Repository und der Entropy-Data-Plattform. Sie verbindet sich mit Entropy Data, um Upstream-Data-Products im Marketplace zu finden, ihre Contracts und Semantik abzurufen (um Join-Keys und Feld-Definitionen zu verstehen), Metadaten und Lineage deines Datenprodukts zu aktualisieren und Contract-Test-Ergebnisse zu publizieren. Einmal pro Repository installieren, mit einem API-Key autorisieren, und die Sync- und Publish-Skills nutzen sie automatisch.
Wir haben uns für die CLI statt MCP entschieden, weil sie in CI/CD-Pipelines funktioniert (nicht nur mit Coding Agents) und für LLMs auf weniger Kontext optimiert ist: sie liefert strukturierte Daten, die der Agent schnell parsen kann, ohne Token-Overhead.
Beispiel: Wenn ein Produkt gebaut werden soll, das Kunden- und Bestelldaten braucht, führt der Agent aus:
entropy-data search query "customer order" -o json
Die CLI fragt Entropy Data über alle Ressourcen ab und liefert passende Datenprodukte mit ihren ODCS-Contracts und Semantik. Der Agent liest die Ergebnisse, versteht Schema und Join-Keys und generiert models/input_ports/*.odcs.yaml-Dateien, die darauf verweisen.
Anleitung in Entropy Data
Ein Data-Product-Builder-Repository wird in Entropy Data als Builder registriert, unter Governance → Data Product Builders. Hier definieren Data Engineers die Experience für die Teams, die ihn nutzen werden:
- Installationsanleitung für die unterstützten Coding Agents (Claude Code, OpenAI Codex, GitHub Copilot CLI). Die Install-Kommandos werden aus der Repo-URL generiert.
- Usage-Prompts mit Varianten pro Lifecycle-Stufe. Ein Datenprodukt im Status
draftbekommt einen Bootstrap-Prompt; eines im StatusactiveEvolve- und Test-Prompts.
Entropy Data steuert auch die Sichtbarkeit: Verschiedene Teams sehen unterschiedliche Data-Product-Builder-Plugins, je nach Archetyp des Datenprodukts, Owner-Team, Tags und Status. Ein Team, das ein Databricks-consumer-aligned-Produkt baut, sieht einen Databricks-optimierten Builder. Ein anderes Team, das ein Snowflake-source-aligned-Produkt baut, sieht einen Snowflake-Builder. Jedes Team arbeitet mit dem Builder, der zu Stack und Konventionen passt.
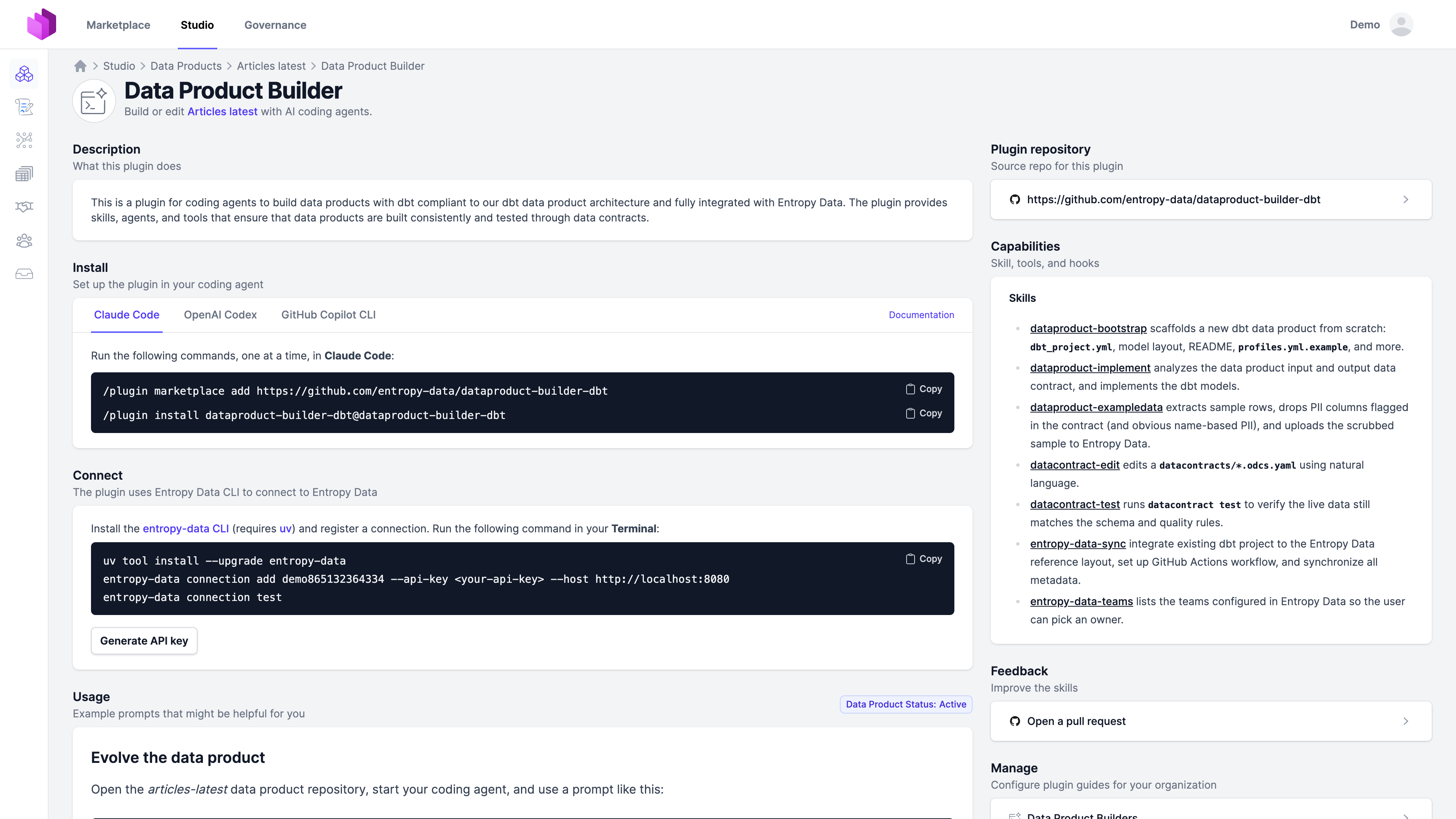
Skills (Beispiele)
Ein Skill ist eine Markdown-Datei, die der Agent lädt, wenn die passende Aufgabe ansteht. Die sieben Skills unten sind die, die das dbt-Referenz-Template (entropy-data/dataproduct-builder-dbt) mitliefert. Dein Fork kann beliebige davon ergänzen, entfernen oder ersetzen.
- datacontract-edit ändert einen Output-Port-Contract auf Basis einer Natural-Language-Anweisung. Der Contract bleibt der Einstiegspunkt.
- dataproduct-bootstrap scaffoldet ein neues dbt-Projekt:
dbt_project.yml, das Vier-Schichten-Modelllayout, README,profiles.yml.example. - dataproduct-implement liest die Input- und Output-Contracts und schreibt die dbt-Modelle, die sie erfüllen.
- datacontract-test führt
datacontract testgegen die Live-Daten aus und meldet Schema- und Qualitätsergebnisse zurück. - dataproduct-exampledata extrahiert Beispielzeilen, entfernt im Contract als PII markierte Spalten und lädt die bereinigte Stichprobe in Entropy Data hoch.
- entropy-data-sync nimmt ein bestehendes dbt-Projekt, richtet es nach dem Referenzlayout aus, setzt den Deployment-Workflow auf und synchronisiert ODPS, ODCS und Lineage-Metadaten.
- entropy-data-teams listet die in deinem Tenant konfigurierten Teams, sodass der Agent den User um einen Owner bitten kann.
Für das resultierende dbt-Projektlayout und die Rolle jeder Komponente siehe Datenprodukte mit dbt bauen.
Unterstützte Coding Agents
- Claude Code
- OpenAI Codex
- GitHub Copilot CLI
- Cursor, Aider und jeder andere Agent, der
AGENTS.mdliest (oder direkt denskills/-Ordner aufgreift)
Die exakten Install-Kommandos für dein Datenprodukt, mit deiner Repo-URL vorgefüllt, werden auf dem Builder-Tab gerendert.
Setup
Zwei einmalige Schritte pro Repository: Plugin installieren und CLI verbinden.
claude plugin marketplace add https://github.com/entropy-data/dataproduct-builder-dbt
claude plugin install dataproduct-builder-dbt@dataproduct-builder-dbt -s projectuv tool install --upgrade entropy-data
entropy-data connection add default --api-key <dein-api-key> --host <dein-entropy-data-host>Den API-Key generierst du unter Organization Settings → API Keys. Für CI nutze einen Team- oder organisationsweiten Key, der als Repository-Secret abgelegt ist. Der Builder-Tab liefert beide Kommandos mit Host und Key vorgefüllt.
Entropy Data
Entropy Data ist ein Marktplatz für Datenprodukte, durchgesetzt mit Data Contracts. Der Data Product Builder schließt den Kreis zwischen Contract und Implementierung: Du bearbeitest den Contract im Marketplace, übergibst den Prompt an deinen Agent, und das Datenprodukt geht mit Output Ports, Tests, Lineage und Metadaten bereits verdrahtet live.
Kostenlos starten, die Demo ausprobieren oder die Data-Product-Builder-Dokumentation lesen.