Knowledge
Data Product Builder: Build Data Products with your Coding Agent
Write what you want as a data contract, then ask your coding agent to build it. Implement in minutes, fully compliant with your conventions, fully integrated with Entropy Data.
Implementing Data Products in the Age of Coding Agents
Data engineers today build data products using coding agents such as Claude Code or OpenAI Codex. A Data Product Builder is a plugin to the coding agent, encoding your organization's conventions, quality standards, deployment patterns, and marketplace integration in Entropy Data. The agent uses these to scaffold a production-ready data product in minutes. Fully tested, compliant with Entropy Data governance, ready to ship.
Contract-Driven Development
But what should the coding agent implement? A data contract describes what a data product delivers: schema, semantics, quality rules, SLAs, and terms of use. It is the specification a consumer can read and a producer must meet.
Treat that spec as the input to the implementation for the coding agent. Write or extend the ODCS contract first. Then hand it to the agent and let it generate the data pipeline, tests, CI workflow, and lineage wiring that satisfy it.
The coding agent can look up the Entropy Data marketplace for data sources that match to the requirements.
And finally, run datacontract test against the result to confirm the live data matches.
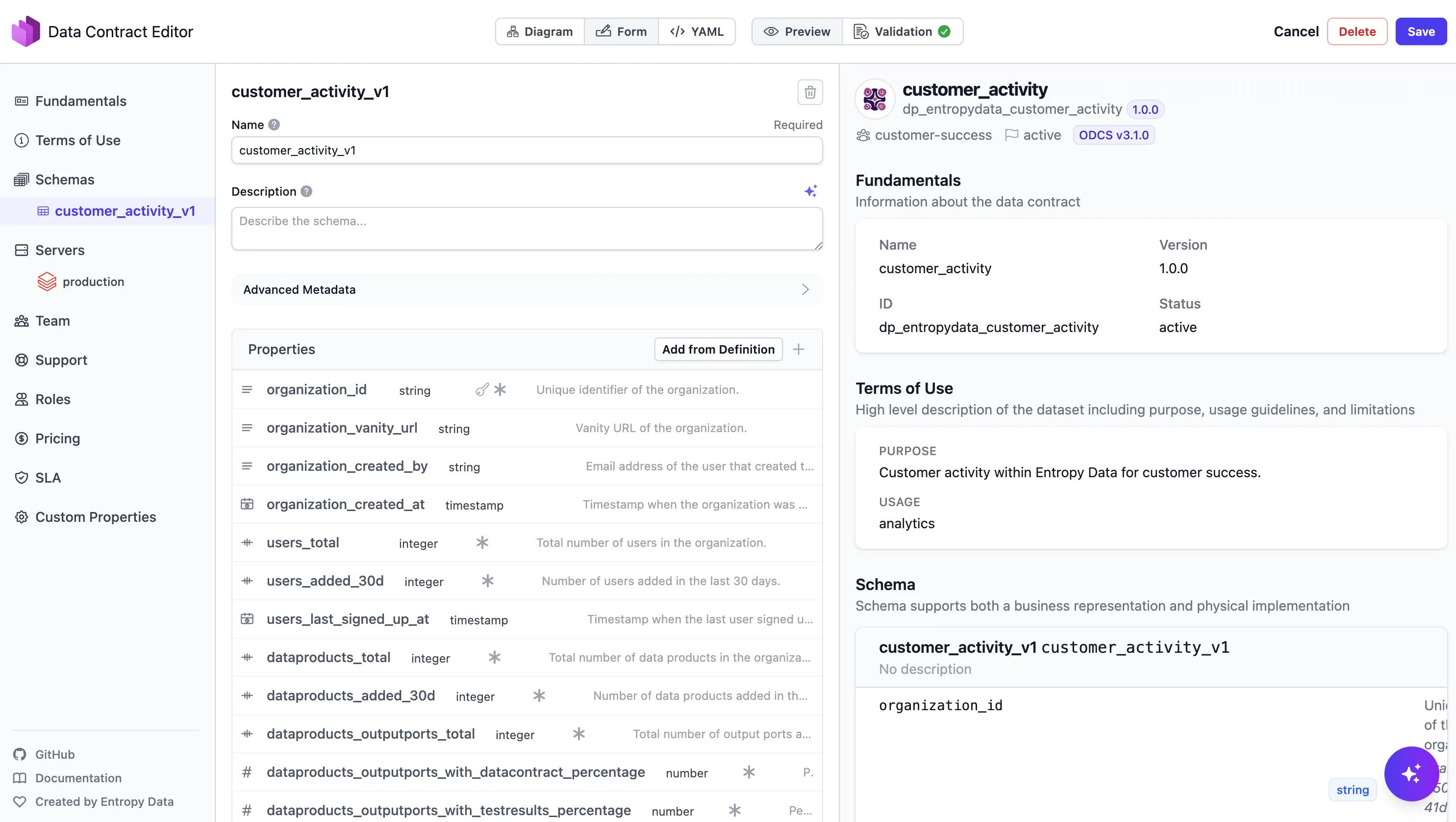
Building and Evolving Data Products
For a new product, draft the contract (schema, types, quality rules) in the Entropy Data editor or in YAML. Open the Builder tab on the data product page, copy the prefilled prompt, and paste it into your coding agent. The agent scaffolds the dbt project, output-port models, GitHub Actions workflow, and opens a PR. CI runs datacontract test to verify the live data matches the contract, then you release.
For an existing product, drift detection flags when the live implementation doesn't match the contract. Example: the Shelf Warmers product needs to add a brand column. Edit the contract ("Add a brand column of type string, not null"), ask the agent to reimplement the dbt models, and run datacontract test to confirm. Same workflow, same agent, same validation.
Available Templates
Entropy Data provides open-source Data Product Builder templates—Git repositories with skills, hooks, and file scaffolding. Each template teaches a coding agent how to build data products on a specific stack. Use a template as-is, or fork it and customize it for your organization's conventions.
- dataproduct-builder-dbt. dbt on any adapter: Snowflake, BigQuery, Databricks, Redshift, Postgres, DuckDB. GitHub Actions for CI. Full integration with Entropy Data: ODPS, ODCS, OpenLineage lineage, and drift detection.
- Databricks Asset Bundles. Coming soon.
- Snowflake Native Apps Framework. Coming soon.
- AWS Glue. Coming soon.
Community and custom templates are welcome. Submit a pull request to the dataproduct-builders registry to list your template.
How it works
Coding agents work via customizable templates—Git repositories with skills, hooks, and scaffolding. Fork a template, customize it for your organization's conventions, and stay in sync with updates.
Git repository
A template is a Git repository that contains skills (prompts that guide the agent on specific tasks), file templates (the scaffolding for your stack), hooks (validators that run after the agent uses a tool), and optional subagents. For example, dataproduct-builder-dbt covers dbt on any adapter. Use it as-is, or copy it into your own organization and customize it: replace the model-layer naming, swap GitHub Actions for Airflow, add internal lint rules, embed your PII taxonomy.
Entropy Data CLI
The Entropy Data CLI is the bridge between your local repository and the Entropy Data platform. It connects to Entropy Data to discover upstream data products in the marketplace, retrieve their contracts and semantics to understand join keys and field definitions, update your data product's metadata and lineage, and publish contract test results. Install it once per repository, authorize it with an API key, and the sync and publish skills will use it automatically.
We chose the CLI over MCP because it works in CI/CD pipelines (not just with coding agents) and is optimized for LLMs to consume less context—returning structured data that the agent can parse quickly without token overhead.
Example: when building a product that needs customer and order data, the agent runs.
entropy-data search query "customer order" -o json
The CLI queries Entropy Data across all resources, returns matching data products with their ODCS contracts and semantics. The agent reads the results, understands the schema and join keys, and generates models/input_ports/*.odcs.yaml files that reference them.
Guidance in Entropy Data
A Data Product Builder repository is registered as a builder in Entropy Data, under Governance → Data Product Builders. The builder is where data engineers define the experience for the teams that will use it:
- Installation instructions for the coding agents the template supports (Claude Code, OpenAI Codex, GitHub Copilot CLI). The install commands are generated from the repository URL.
- Usage prompts with variants per lifecycle stage. A data product in
draftgets a bootstrap prompt; one that isactivegets evolve and test prompts.
Entropy Data also controls visibility: different teams see different Data Product Builder plugins depending on the data product's archetype, owning team, tags, and status. One team building a Databricks consumer-aligned product sees a Databricks-optimized builder. Another team building a Snowflake source-aligned product sees a Snowflake builder. Each team works with the builder that fits their stack and conventions.
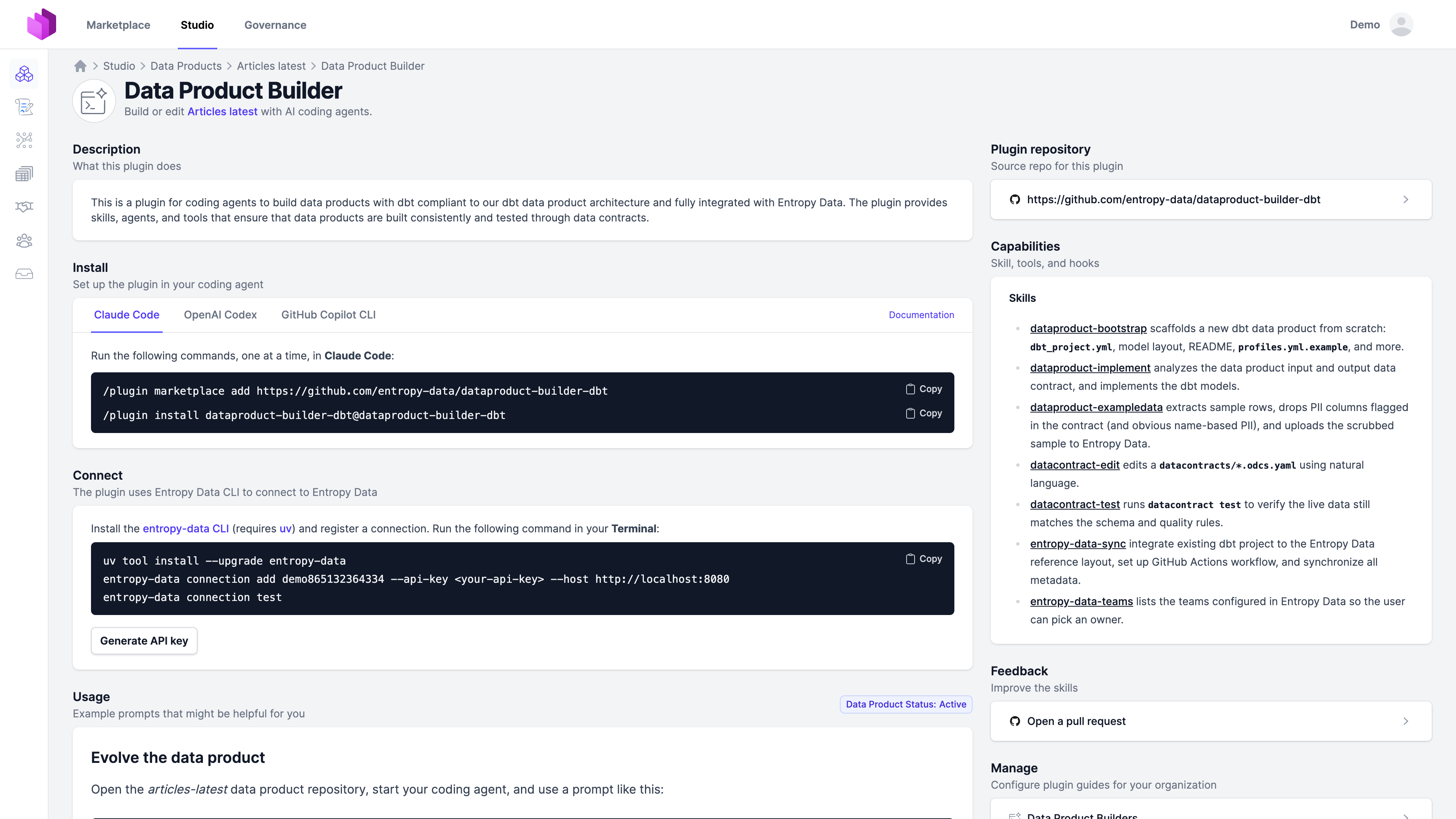
Skills (Examples)
A skill is a Markdown file the agent loads when the matching task comes up. The seven skills below are the ones shipped by the reference dbt template (entropy-data/dataproduct-builder-dbt); your fork can add, remove, or replace any of them.
- datacontract-edit changes an output-port contract from a natural-language instruction. The contract stays the entry point.
- dataproduct-bootstrap scaffolds a new dbt project:
dbt_project.yml, the four-layer model layout, README,profiles.yml.example. - dataproduct-implement reads the input and output contracts and writes the dbt models that fulfill them.
- datacontract-test runs
datacontract testagainst the live data and reports back schema and quality results. - dataproduct-exampledata extracts sample rows, drops columns flagged as PII in the contract, and uploads the scrubbed sample to Entropy Data.
- entropy-data-sync takes an existing dbt project, aligns it with the reference layout, sets up the deployment workflow, and synchronizes ODPS, ODCS, and lineage metadata.
- entropy-data-teams lists the teams configured in your tenant so the agent can ask the user to pick an owner.
For the resulting dbt project layout and the role of each component, see Building Data Products with dbt.
Supported Coding Agents
- Claude Code
- OpenAI Codex
- GitHub Copilot CLI
- Cursor, Aider, and any other agent that reads
AGENTS.md(or pick up theskills/folder directly)
The exact install commands for your data product, with your repo URL prefilled, are rendered on the Builder tab.
Setup
Two one-time steps per repository: install the plugin and connect the CLI.
claude plugin marketplace add https://github.com/entropy-data/dataproduct-builder-dbt
claude plugin install dataproduct-builder-dbt@dataproduct-builder-dbt -s projectuv tool install --upgrade entropy-data
entropy-data connection add default --api-key <your-api-key> --host <your-entropy-data-host>Generate the API key under Organization Settings → API Keys. For CI, use a team- or organization-scoped key stored as a repository secret. The Builder tab provides both commands with host and key prefilled.
Entropy Data
Entropy Data is a marketplace for data products governed by data contracts. The Data Product Builder closes the loop between contract and implementation: edit the contract in the marketplace, hand the prompt to your agent, and the data product ships with output ports, tests, lineage, and metadata already wired up.
Start for Free, browse the demo, or read the Data Product Builder docs.