Talk · TDWI München 2026
Open Standards for Data Products
Dr. Simon Harrer (CEO & Co-Founder, Entropy Data) · June 23, 2026
A solo talk at TDWI München 2026. Simon opens with a glimpse of the future — a coding agent building a data product on its own — then rewinds to show that the future is already here, built on a stack of open standards: ODCS for data contracts, ODPS for data products, and OSI for semantics, all wrapped in open-source tooling. The closing ask: help make history by getting these standards over the line.

Live at TDWI München 2026. The annotation below is an edited summary of the slides.

The Speaker
Simon Harrer describes himself as a software engineer into data: he builds tools that help data, people, and agents work together. He co-authored "Java by Comparison," translated Zhamak Dehghani's "Data Mesh" into German, and authored the Data Mesh Architecture website.
He maintains the open-source Data Contract CLI and data-landscape.com, sits on the Technical Steering Committee for the Bitol standards (ODCS & ODPS), and contributes to the Open Semantic Interchange (OSI).
His day job is Entropy Data — a data product marketplace built on data contracts and semantics, making high-quality data available to agents and humans alike. ISO 27001 certified, six product engineers, customers in the US, EU, CH, and AU. No VC, and profitable despite the tokens.

The Plan
Three movements. First, peek into the future — watch a coding agent build a data product from nothing but a contract. Then learn the standards that make that possible, the unglamorous plumbing that turns a demo into something you can run in production.
And finally, make history — because these standards are still being written, and the room can help decide whether they stick.

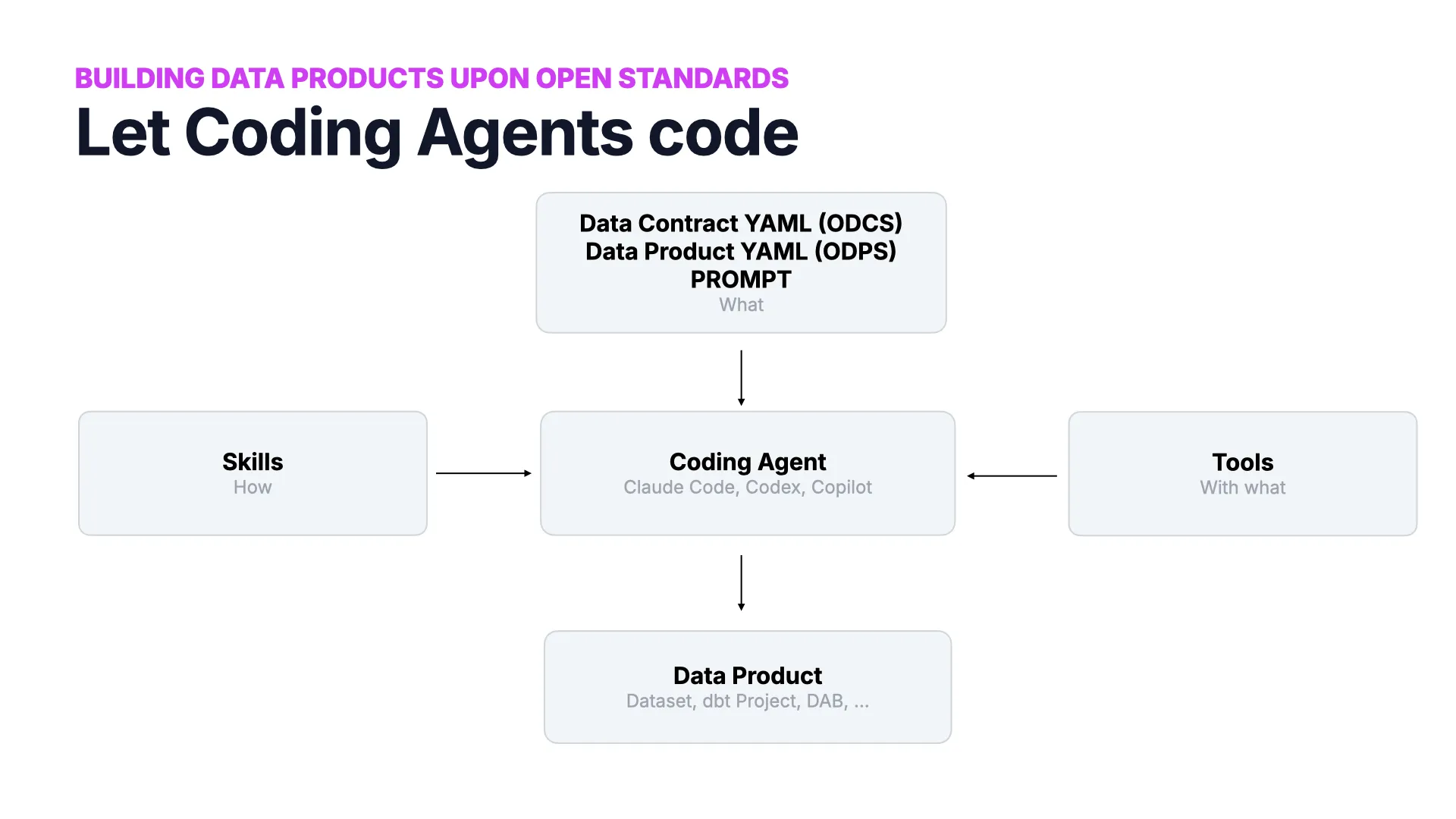
A Glimpse Into the Future
The framing question: what if we already were using open standards for data products? Simon's answer is to build one live — with a coding agent and nothing hand-written.
The recipe is four ingredients around a coding agent (Claude Code, Codex, Copilot). The what comes from machine-readable specs — a Data Contract in ODCS YAML, a Data Product in ODPS YAML, and a prompt. The how comes from Skills that encode your conventions. The with what comes from Tools connecting the agent to your systems.
Out the other side: a real data product — a dataset, a dbt project, a Databricks Asset Bundle. The rest of the talk is the standards under each of those boxes.
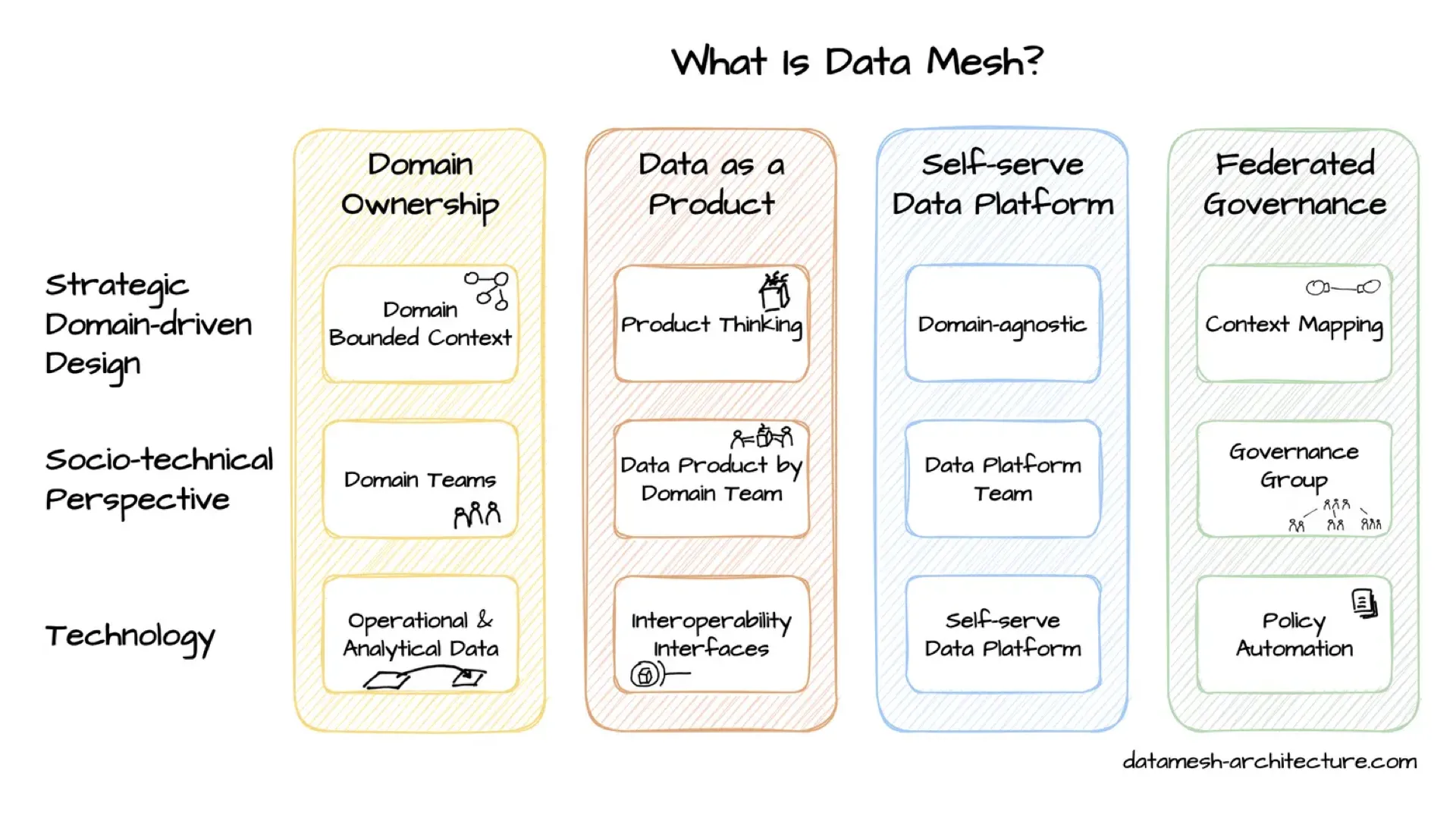
Where Data Products Come From
A quick grounding: the data product is the second of the four Data Mesh principles — domain ownership, data as a product, the self-serve data platform, and federated governance.
"Data as a product" means applying product thinking to data: clear ownership, a consumer mindset, and interoperable interfaces. That last word — interoperable — is exactly where open standards earn their keep.
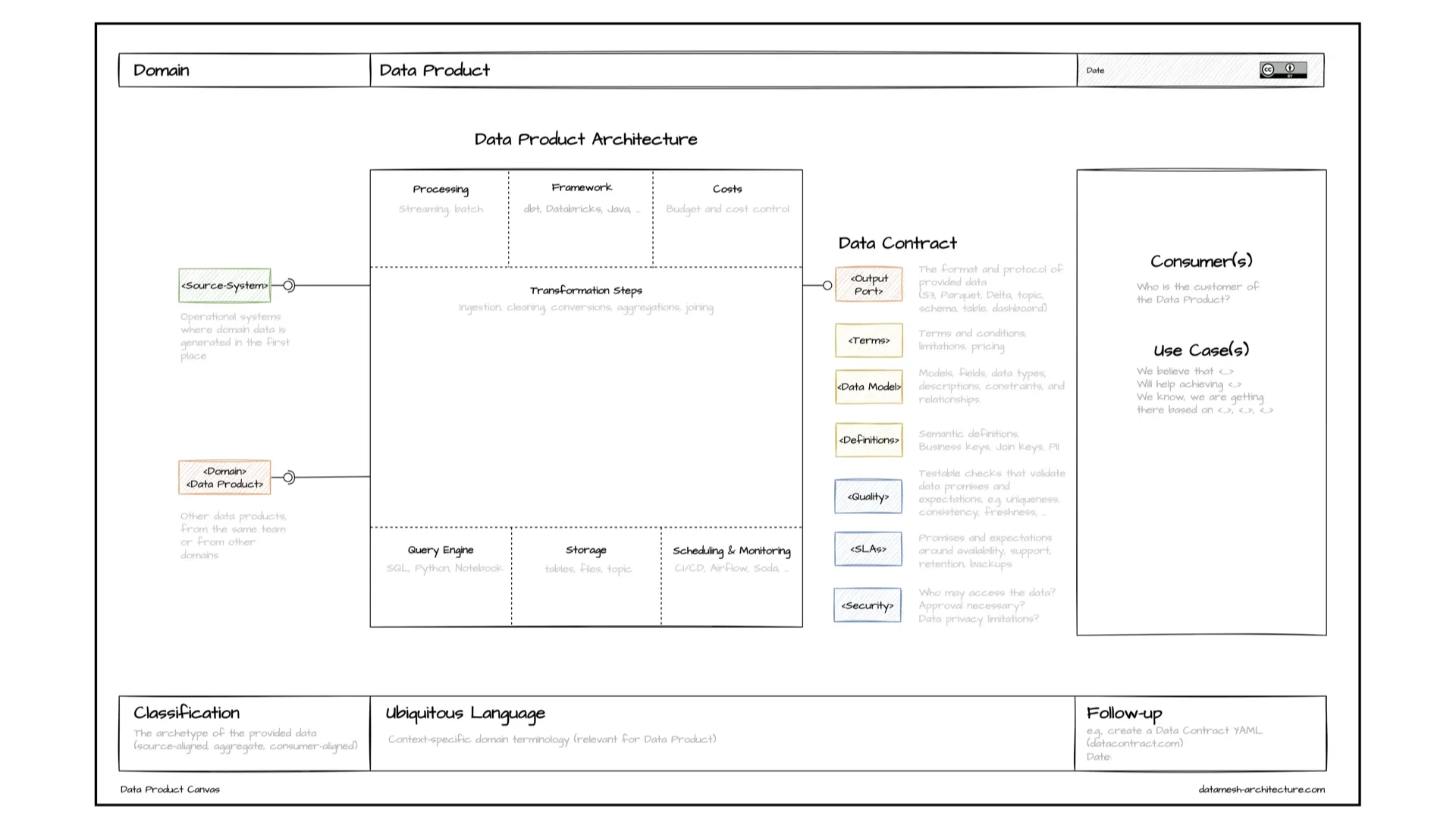
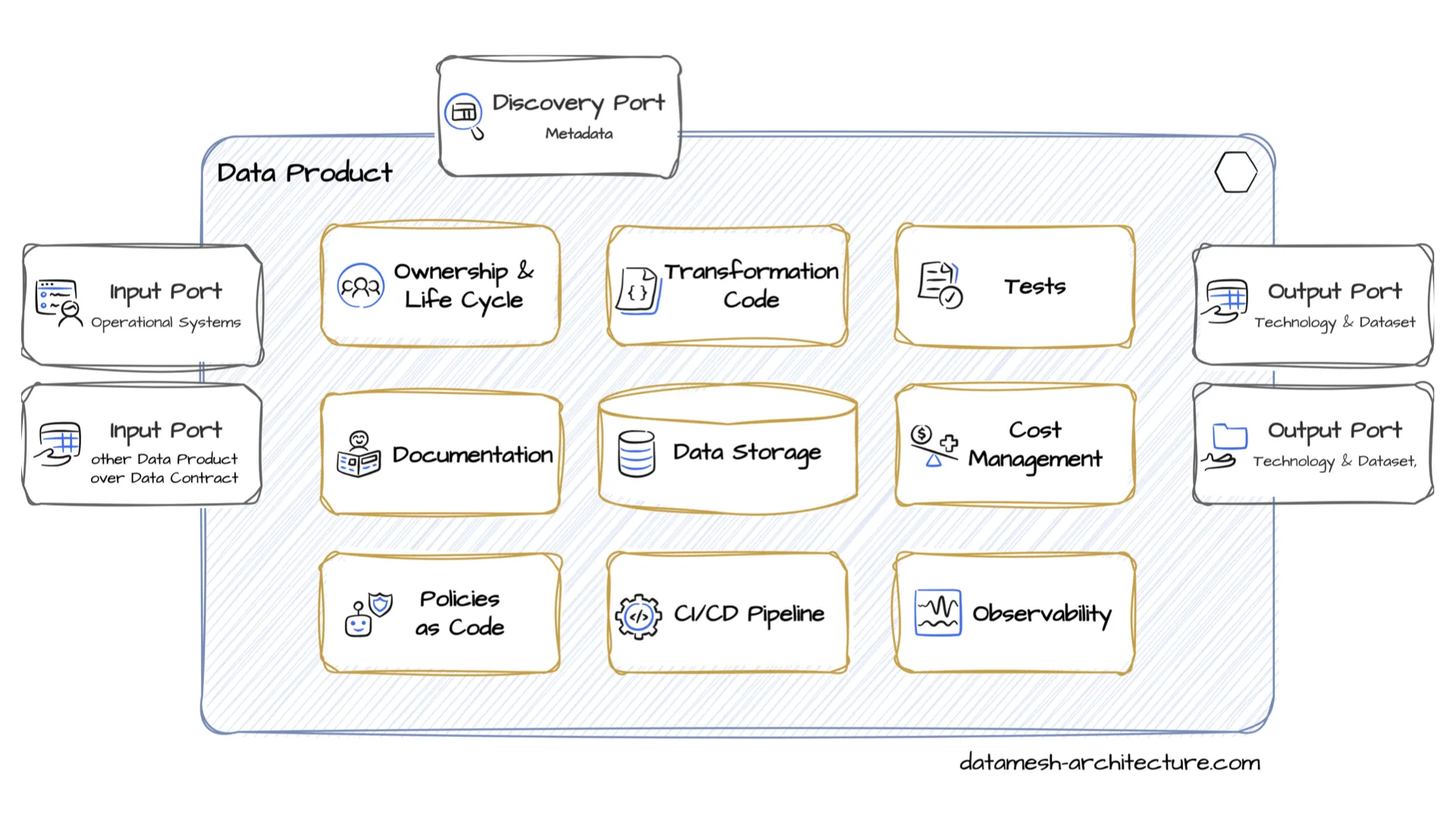
What a Data Product Actually Is
Before standardizing anything, you need a shared picture of the thing. The free Data Product Canvas captures the purpose, the output ports, the data contract, and the consumers — the conversation you have before writing code.
Architecturally, a data product is a self-contained unit with input ports, output ports, and a discovery port for metadata, wrapping the transformation code, storage, tests, policies, CI/CD, and observability inside. Each of those edges and pieces is a candidate for a standard.


What Is a Standard — and Why Bother?
A standard is just an agreement on how to do something, so that different people and tools can interoperate without negotiating it each time. ISO 8601 dates (2013-02-27) are the canonical example — one format everyone can parse.
And the canonical risk is the obligatory xkcd: someone looks at 14 competing standards, decides to unify them, and now there are 15. Avoiding that outcome is the whole game in the data product space right now.

Four Dimensions to Judge a Standard
- De facto vs. de jure — is it standard because people actually use it, or because a body declared it so? (Usage)
- Initiative vs. vendor — is it stewarded by a neutral community, or owned by one company? (Owner)
- Many vs. one — is control spread across contributors, or held by a single party? (Control)
- Open vs. paywall — can anyone read and adopt it for free, or does it cost money? ($$$)
The standards worth betting on lean left on all four: used in the wild, community-owned, broadly governed, and open. Keep this scorecard in mind for everything that follows.
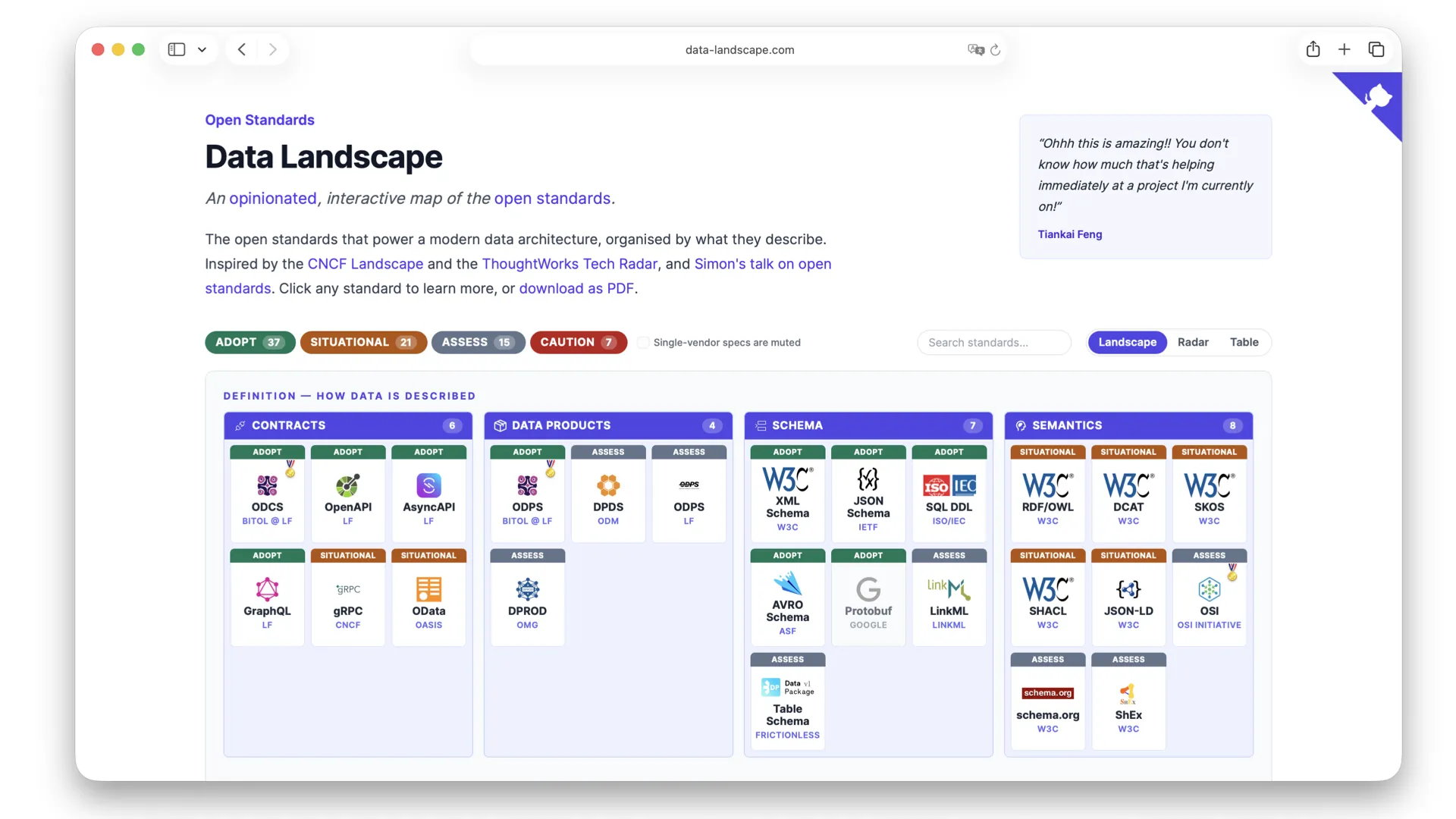
A Map of the Open Standards
To see the whole field at once, Simon maintains data-landscape.com — an opinionated, interactive map of the open standards that power a modern data architecture, organized by what they describe: contracts, data products, schema, and semantics.
Inspired by the CNCF Landscape and the ThoughtWorks Tech Radar, each standard is rated adopt / situational / assess / caution. The rest of the talk walks the three columns that matter most for data products: contracts, products, and semantics.
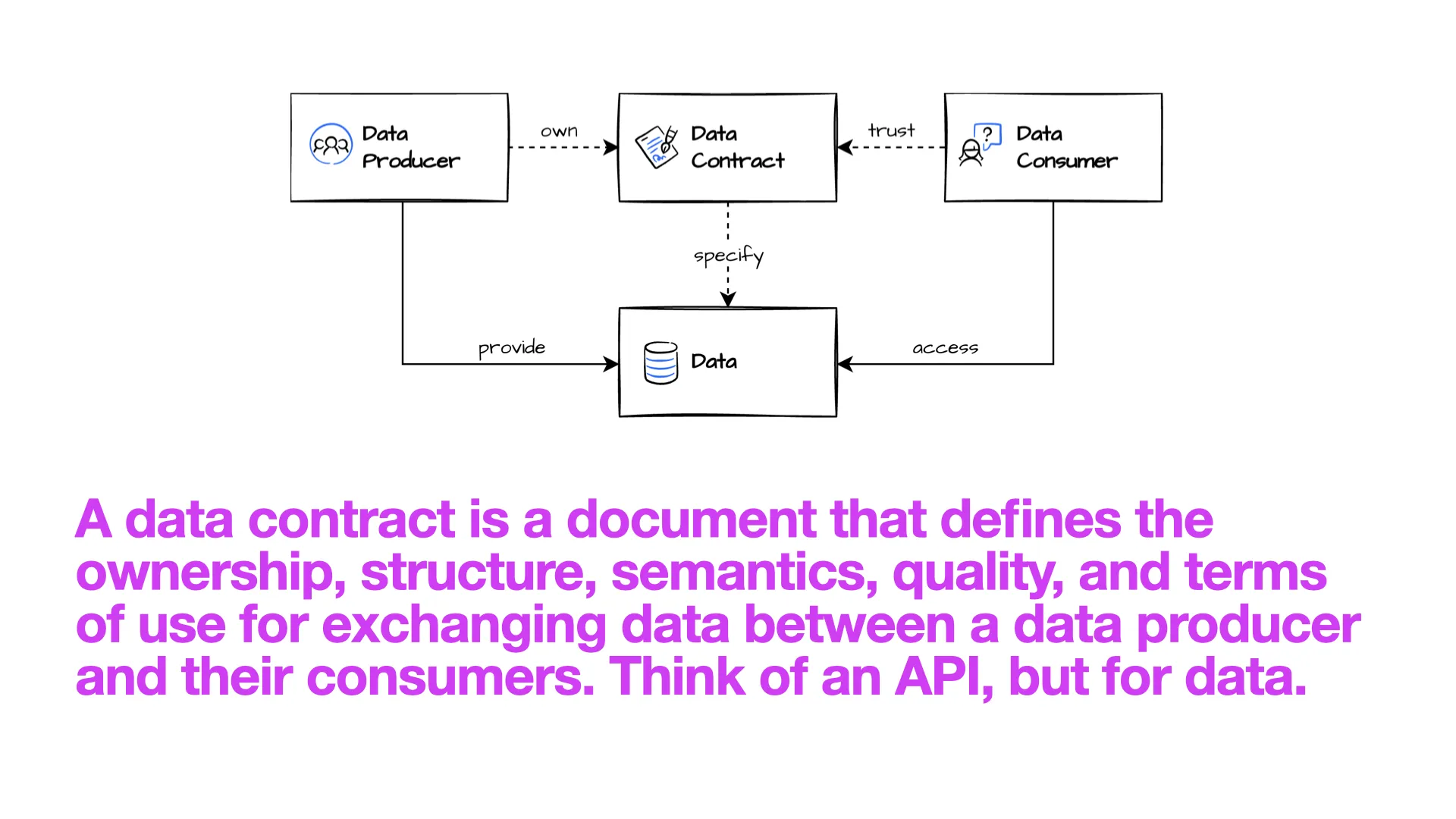
What Is a Data Contract?
A data contract is a document that defines the ownership, structure, semantics, quality, and terms of use for exchanging data between a data producer and their consumers. Think of an API, but for data.
The producer owns the contract and provides the data; the consumer trusts the contract and accesses the data. Everything the consumer needs to rely on is written down — and, crucially, machine-readable. (More in What is a Data Contract?)

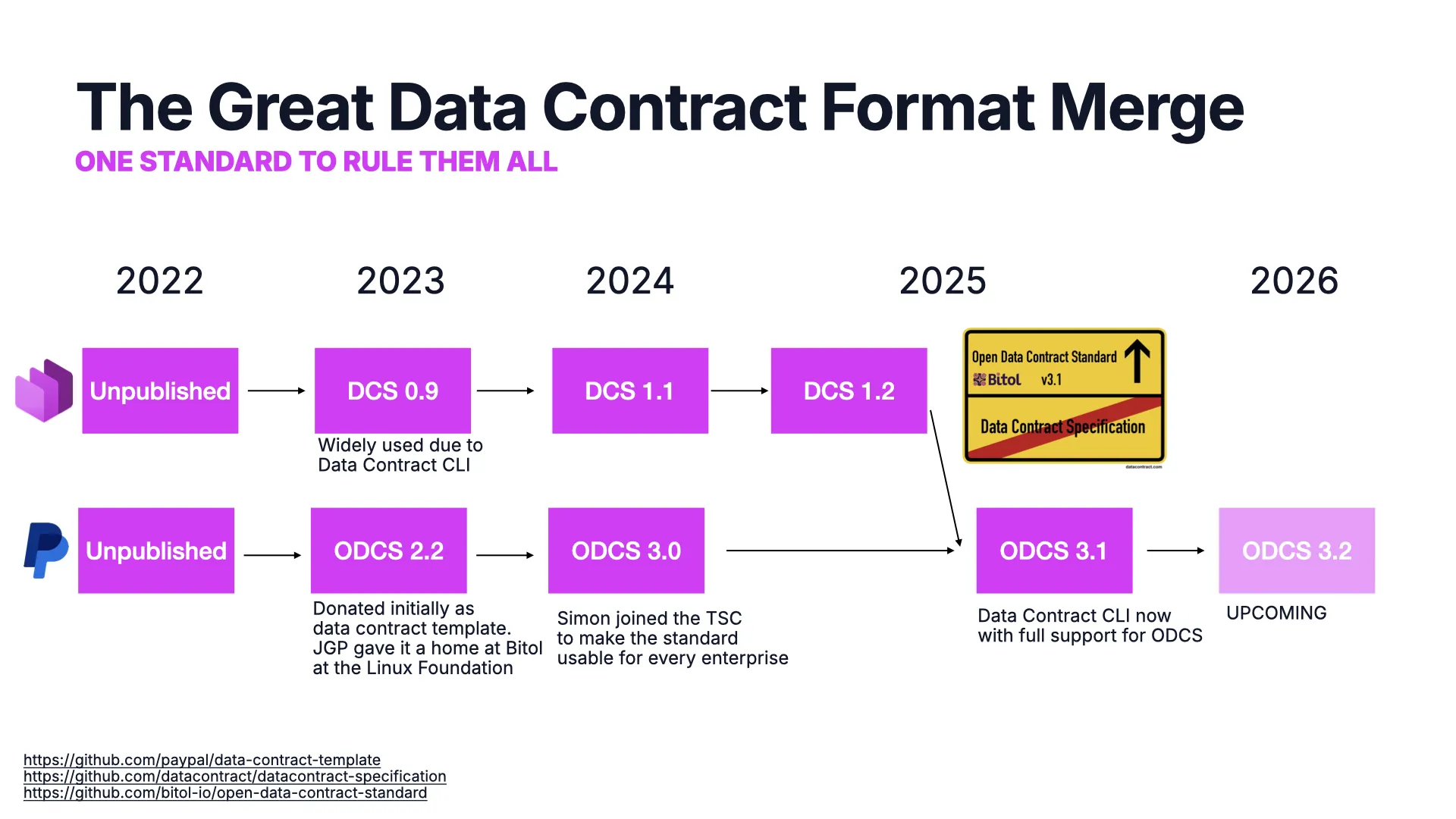
The Great Format Merge
Once upon a time, every company rolled its own data contract format — the exact xkcd trap. Then two lineages emerged: the Data Contract Specification (used widely thanks to the Data Contract CLI) and ODCS (donated by PayPal as a template).
Rather than make it 15 standards, the two camps merged. ODCS found a neutral home at Bitol in the Linux Foundation, Simon joined the TSC, and the Data Contract CLI now fully supports ODCS. One standard to rule them all — de facto and de jure.
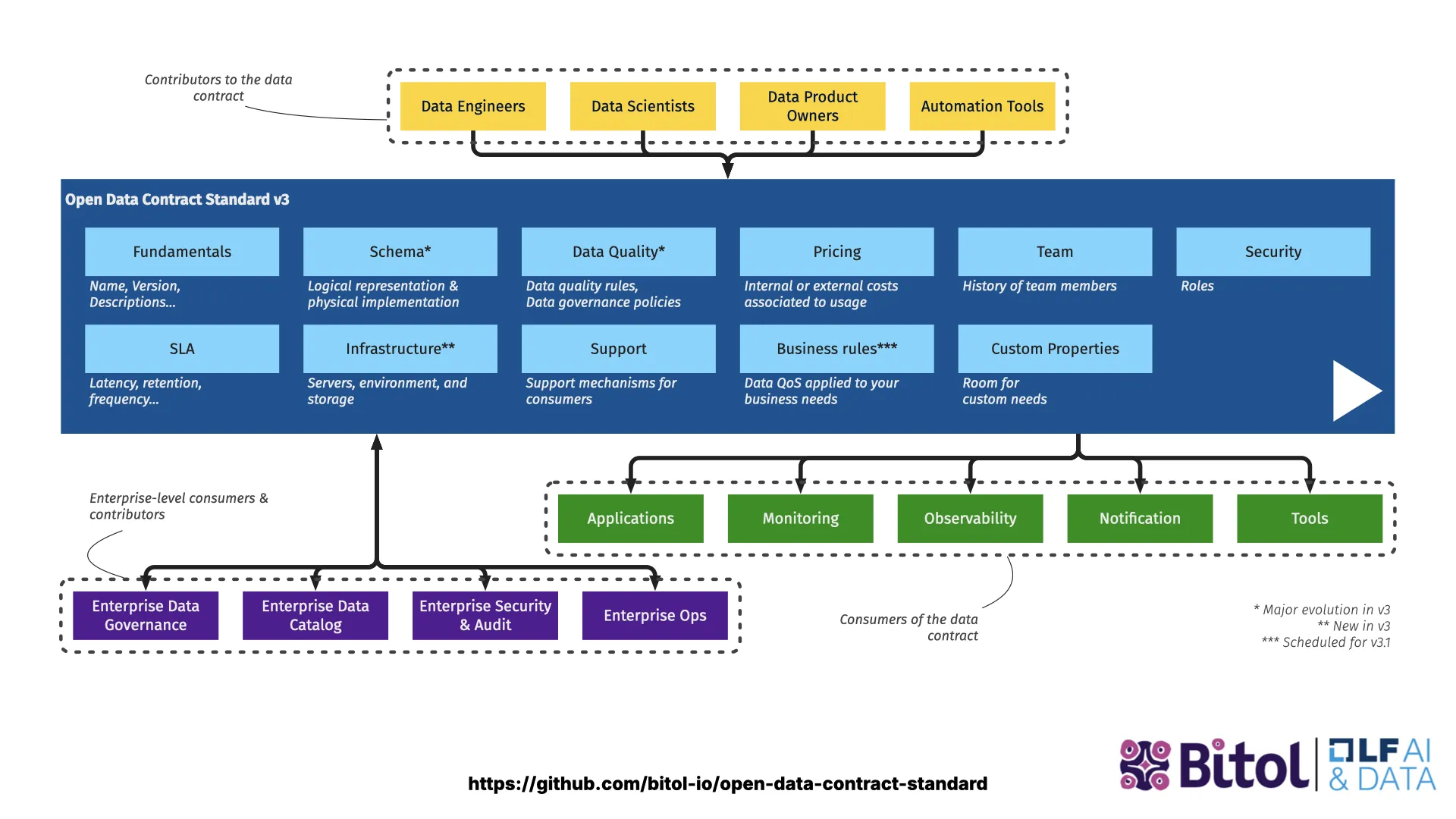
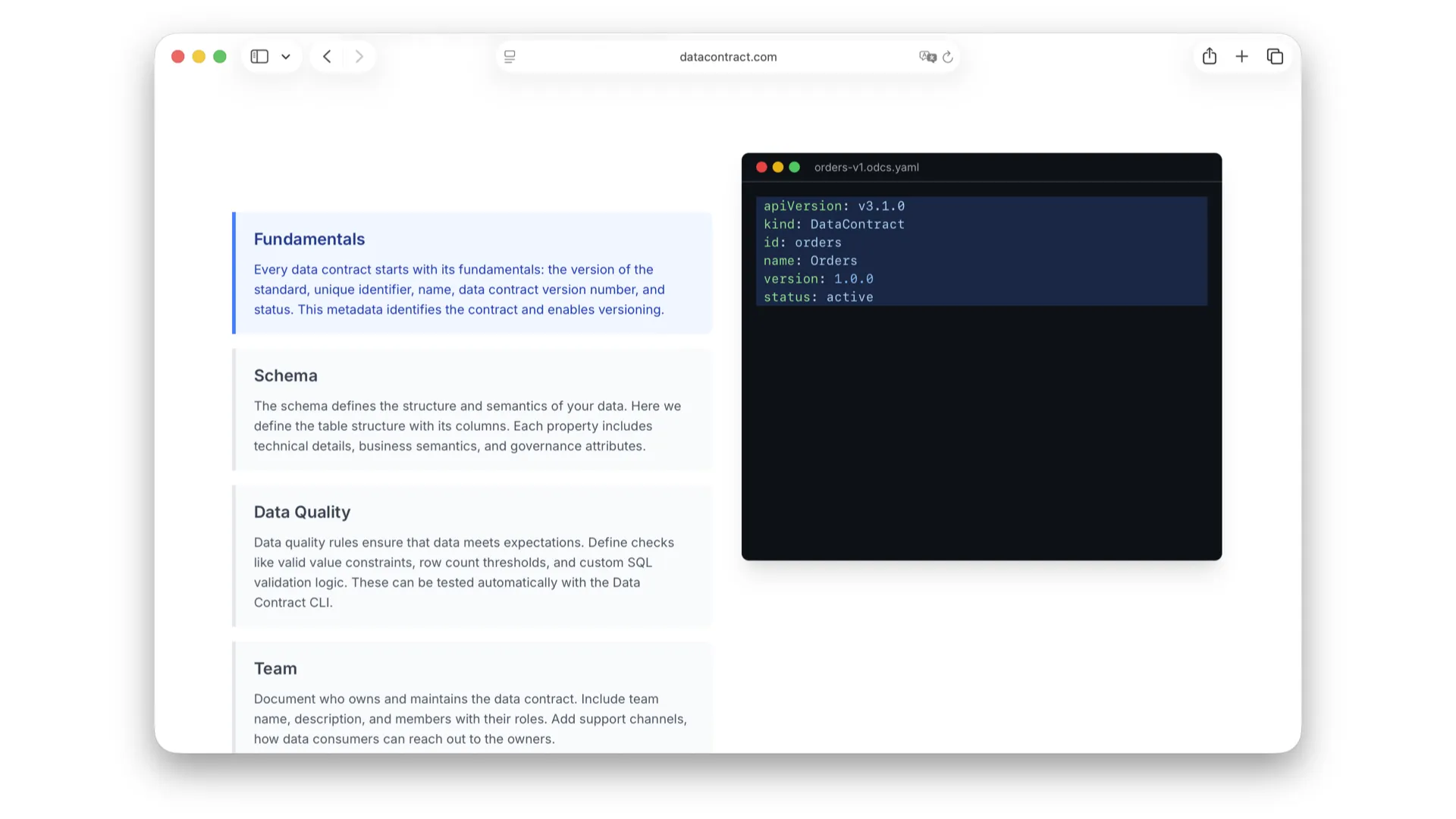
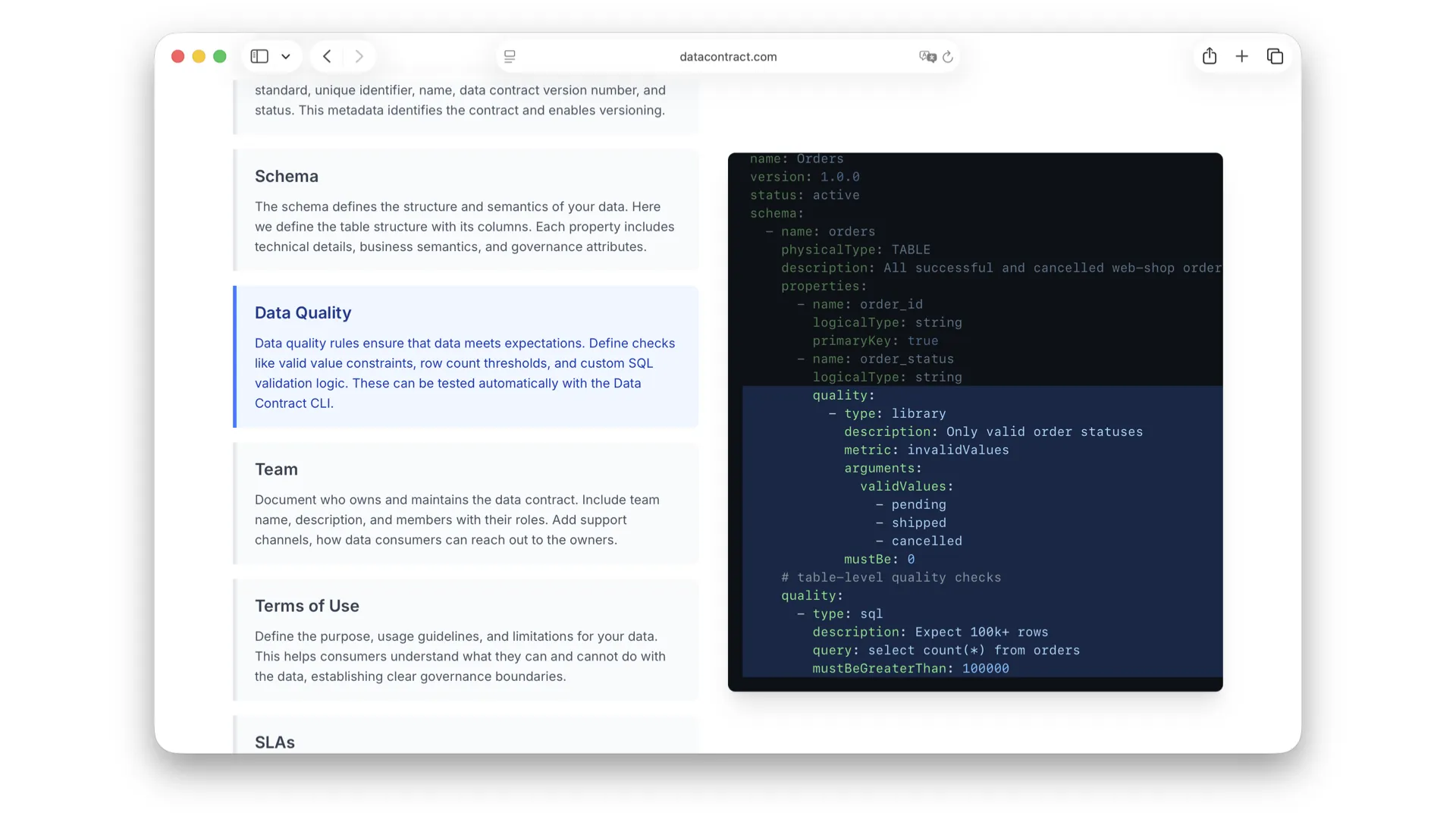
The Open Data Contract Standard
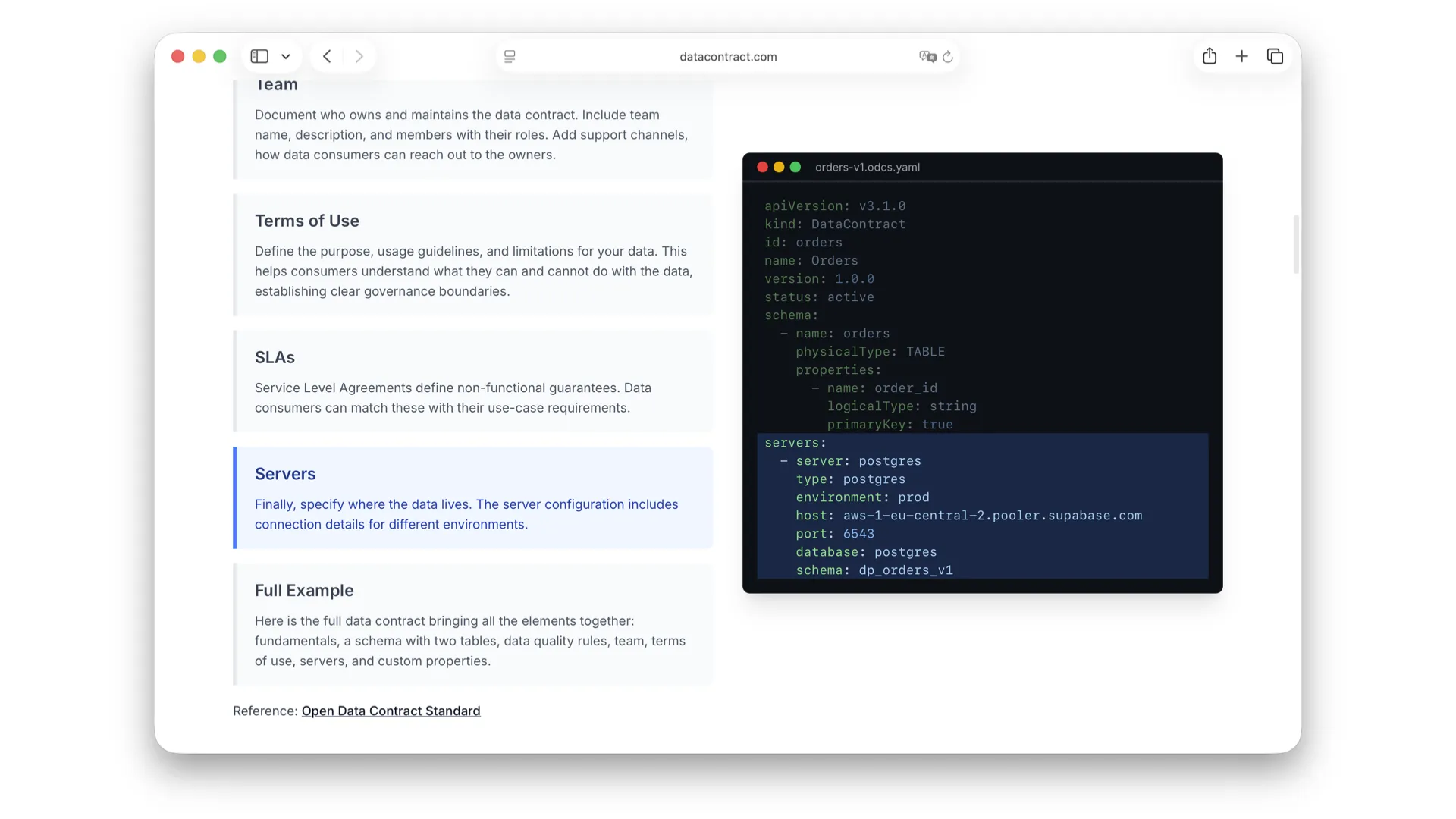
ODCS v3 is the building block. One YAML file carries the fundamentals (version, name, status), the schema (tables, columns, semantics), data quality rules, team and ownership, terms of use, SLAs, servers, and arbitrary custom properties.
Each section is just a few lines of readable YAML — fundamentals first, then schema, then quality rules that can be executed automatically. It is enough for a human to understand the data and enough for a machine to act on it. (Background: Open Data Contract Standard.)

Now What? Automate All the Things
A YAML file is only worth writing if something reads it. Once a contract is machine-readable, it becomes the single source that drives the rest:
- Code generation: Java, Pydantic, dbt models, SQL DDL
- Testing: compare the contract against real data, catch breaking changes in PRs, monitor continuously
- Metadata distribution: push to metastores, catalogs (Collibra), and marketplaces (Entropy Data)
- Infrastructure provisioning: output ports, input ports, anonymization, access control
- Collaboration & governance: naming conventions, schema evolution, usage agreements, approval workflows
One file in, a whole toolchain out.

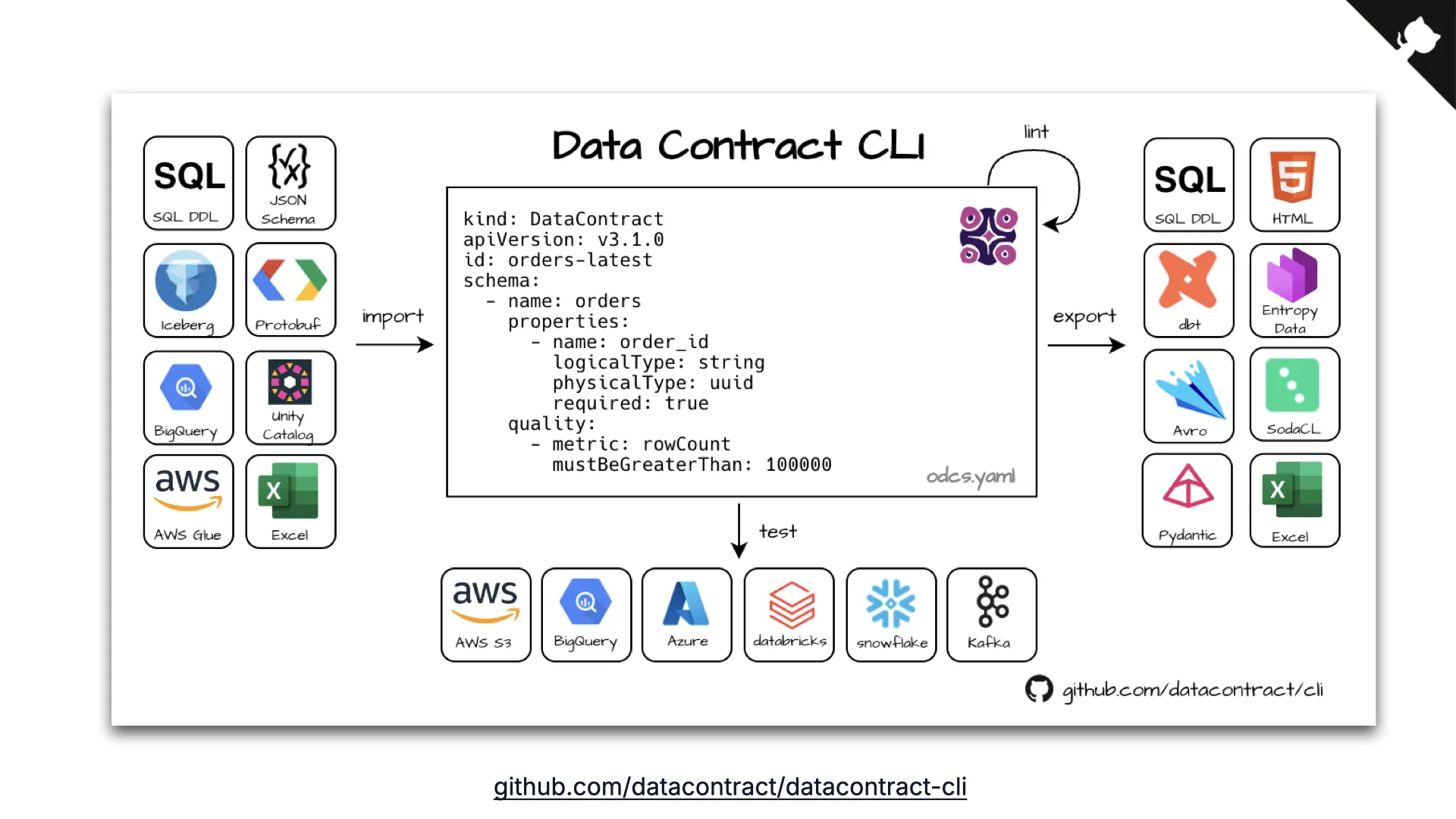
Open Source Tooling: the CLI
The workhorse is the open-source Data Contract CLI. It imports contracts from existing sources (SQL DDL, JSON Schema, Iceberg, dbt, BigQuery), exports to a dozen targets (SQL, HTML, dbt, Pydantic), and tests a contract against the real data in S3, BigQuery, Azure, Databricks, Snowflake, or Kafka.
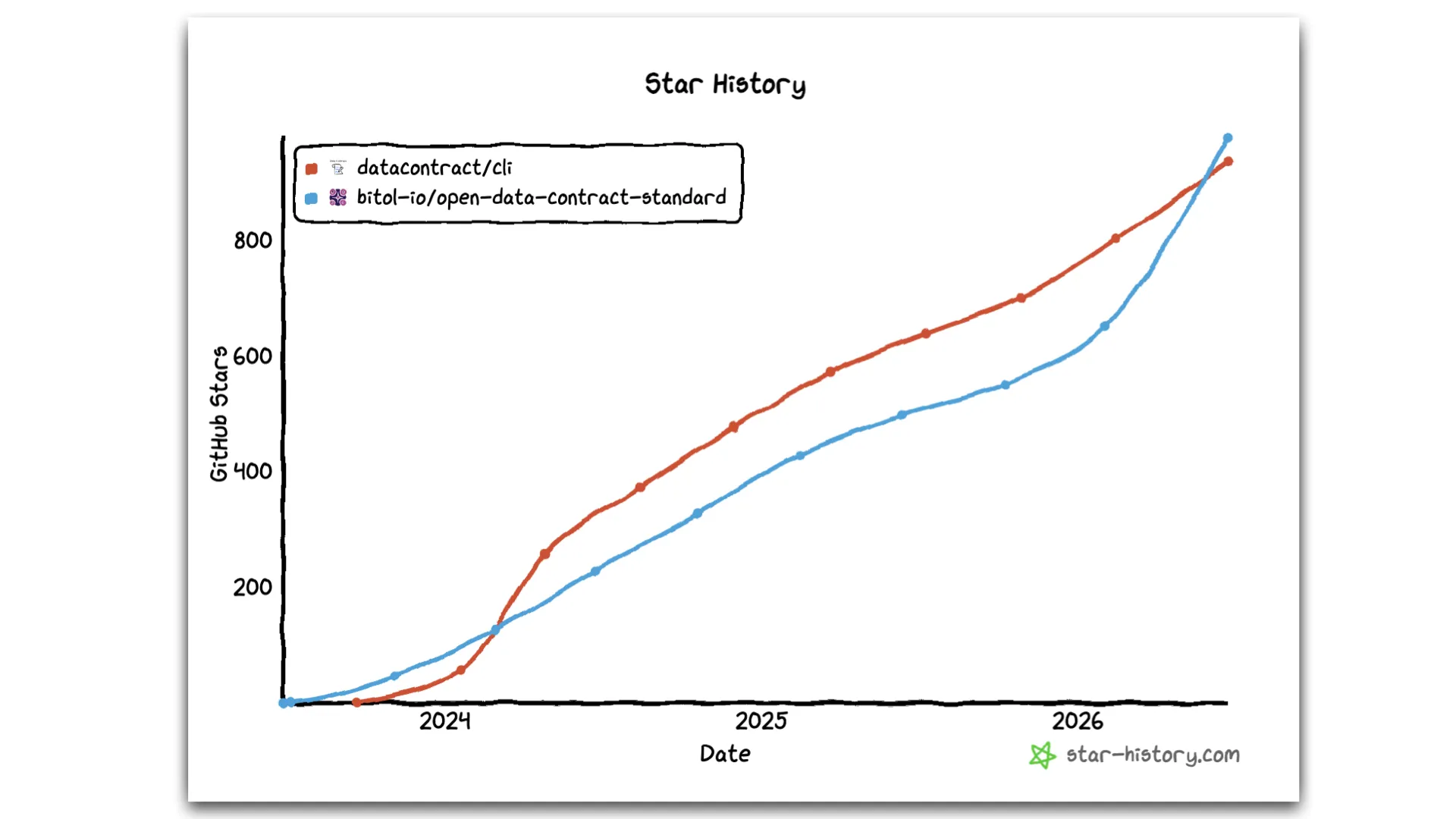
The star-history curve tells the adoption story: both the CLI and the ODCS repo are climbing steeply toward 1,000 GitHub stars — the kind of de-facto traction that keeps a standard alive.

Write It However You Like
Nobody should hand-edit YAML if they don't want to. The open-source Data Contract Editor gives a standard-compliant authoring experience with live preview and validation.
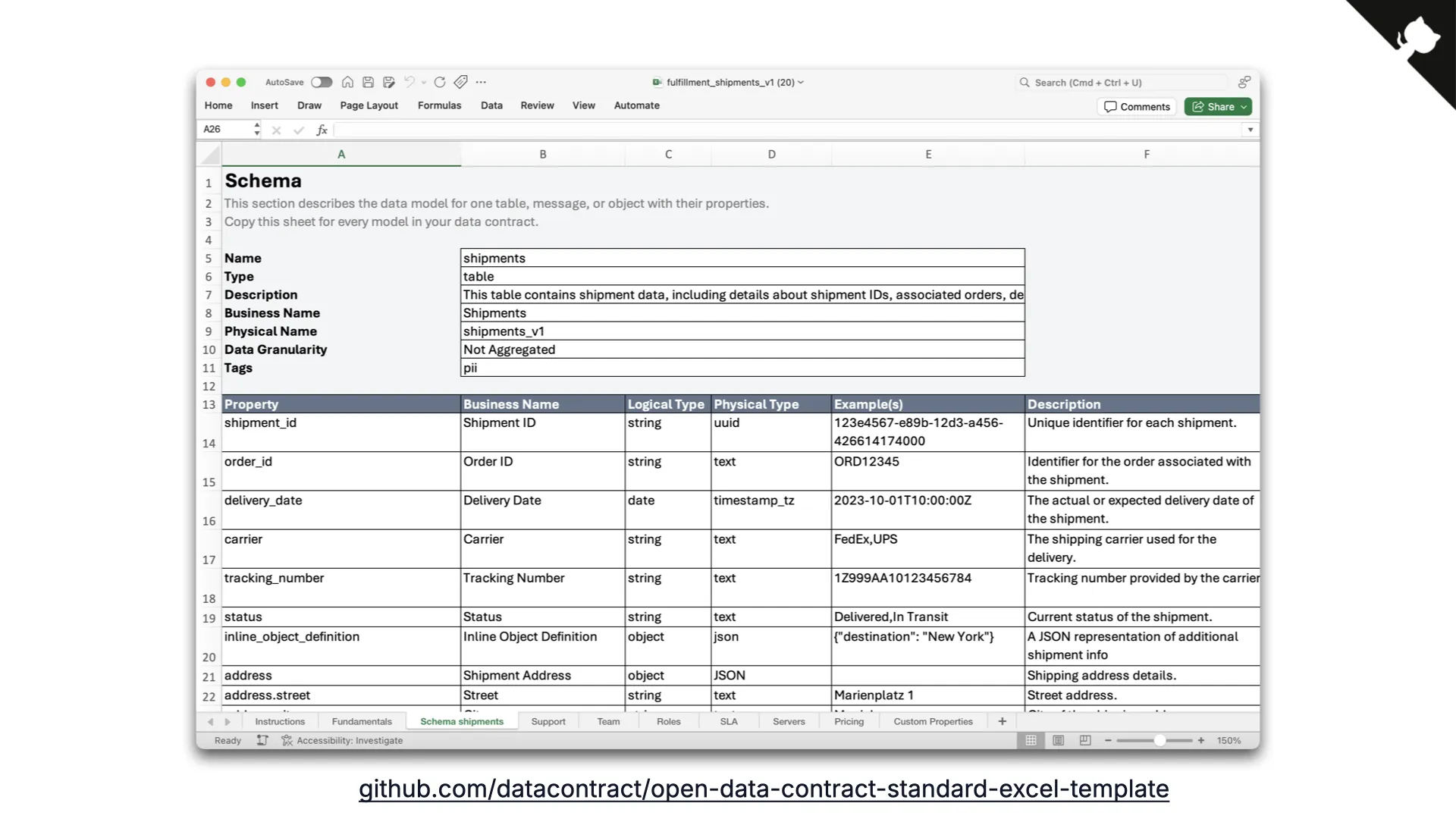
And for the spreadsheet crowd, the ODCS Excel template — born of popular demand — captures the schema in Excel and converts to YAML later. The standard, the editor, the CLI, and the template: four free tools, one format.
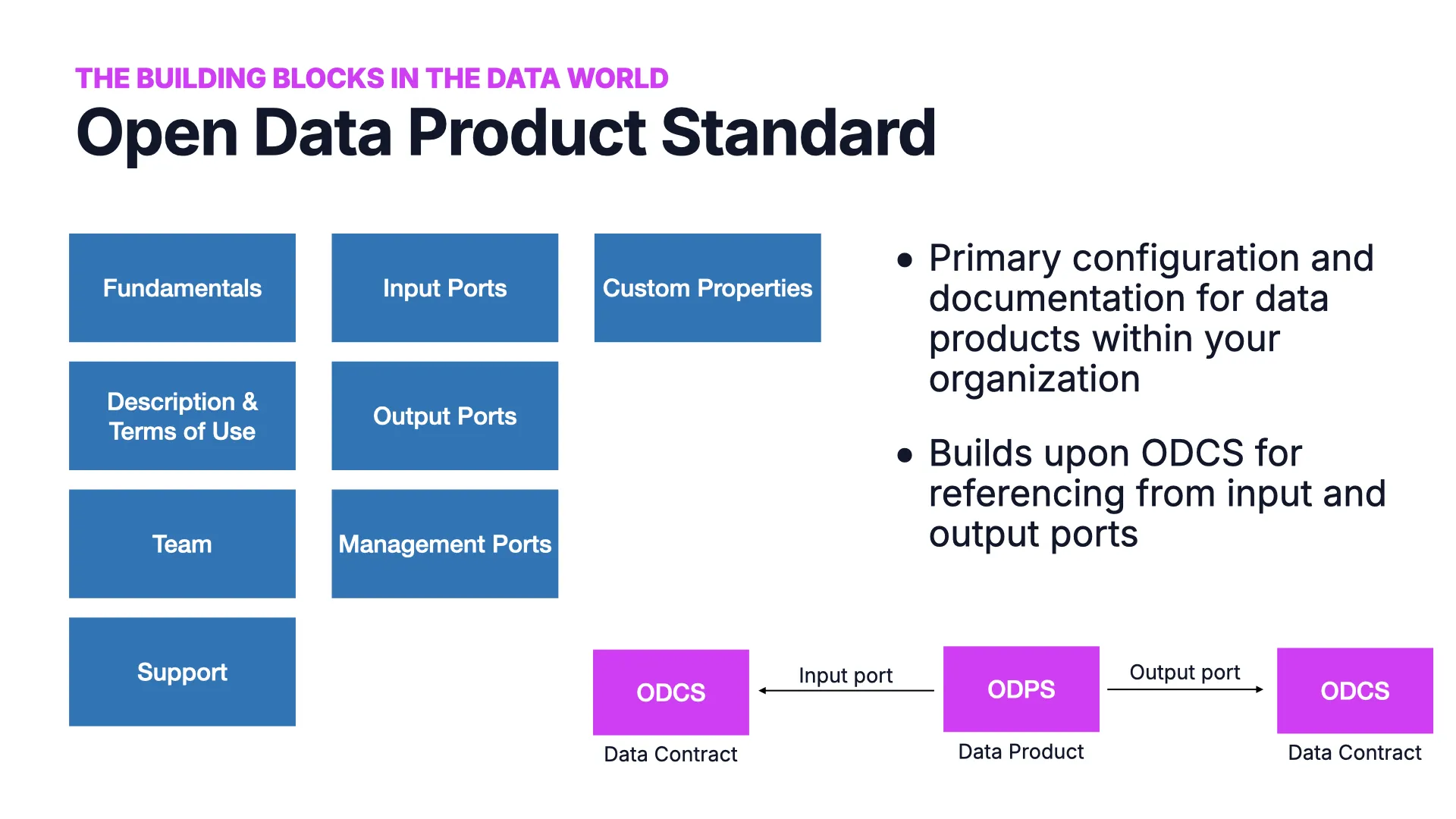


The Open Data Product Standard
If ODCS describes a single interface, ODPS — the Open Data Product Standard — describes the product that exposes them. It is the primary configuration and documentation for a data product, and it builds upon ODCS: its input and output ports reference data contracts by ID.
One ODPS YAML can declare several versioned output ports — say an orders_pii port and an orders_npii port — each backed by its own contract, plus the input ports it consumes.
Because ports point at contracts, you get lineage for free: applications feed data products, which feed other data products and consumers, in a graph you can actually trace. (See What is a Data Product?)
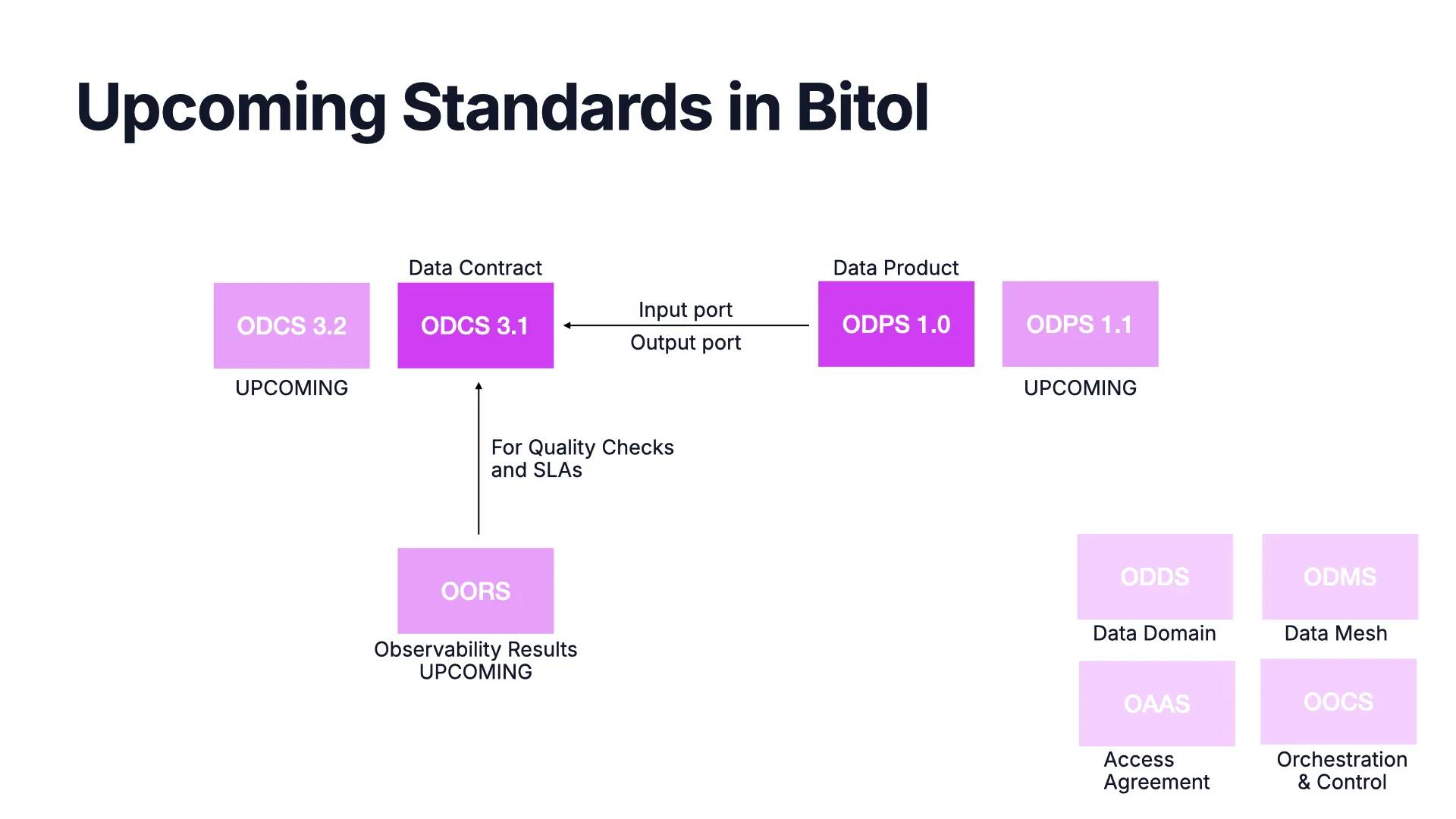
What's Coming in Bitol
The Bitol family is growing. Beyond ODCS (3.1 now, 3.2 upcoming) and ODPS (1.0 now, 1.1 upcoming), there is OORS for observability results that feeds back into a contract's quality and SLA checks.
Further out sit drafts for data domains (ODDS), data mesh (ODMS), access agreements (OAAS), and orchestration & control (OOCS) — a coordinated set rather than 15 rival ones.

Mind the Name Clash
A real-world wrinkle, delivered with a grin: "ODPS" is two different things. There is the Open Data Product Standard (part of the Bitol family, links to ODCS via input and output ports, simple pricing, no i18n) and the Open Data Product Specification (standalone, limited output-port support, strong on pricing plans and i18n).
Both abbreviate to ODPS, both sit under LF AI & Data. So when you tell a coding agent to "use ODPS," be aware which one you mean — the messy reality of standards still being sorted out.
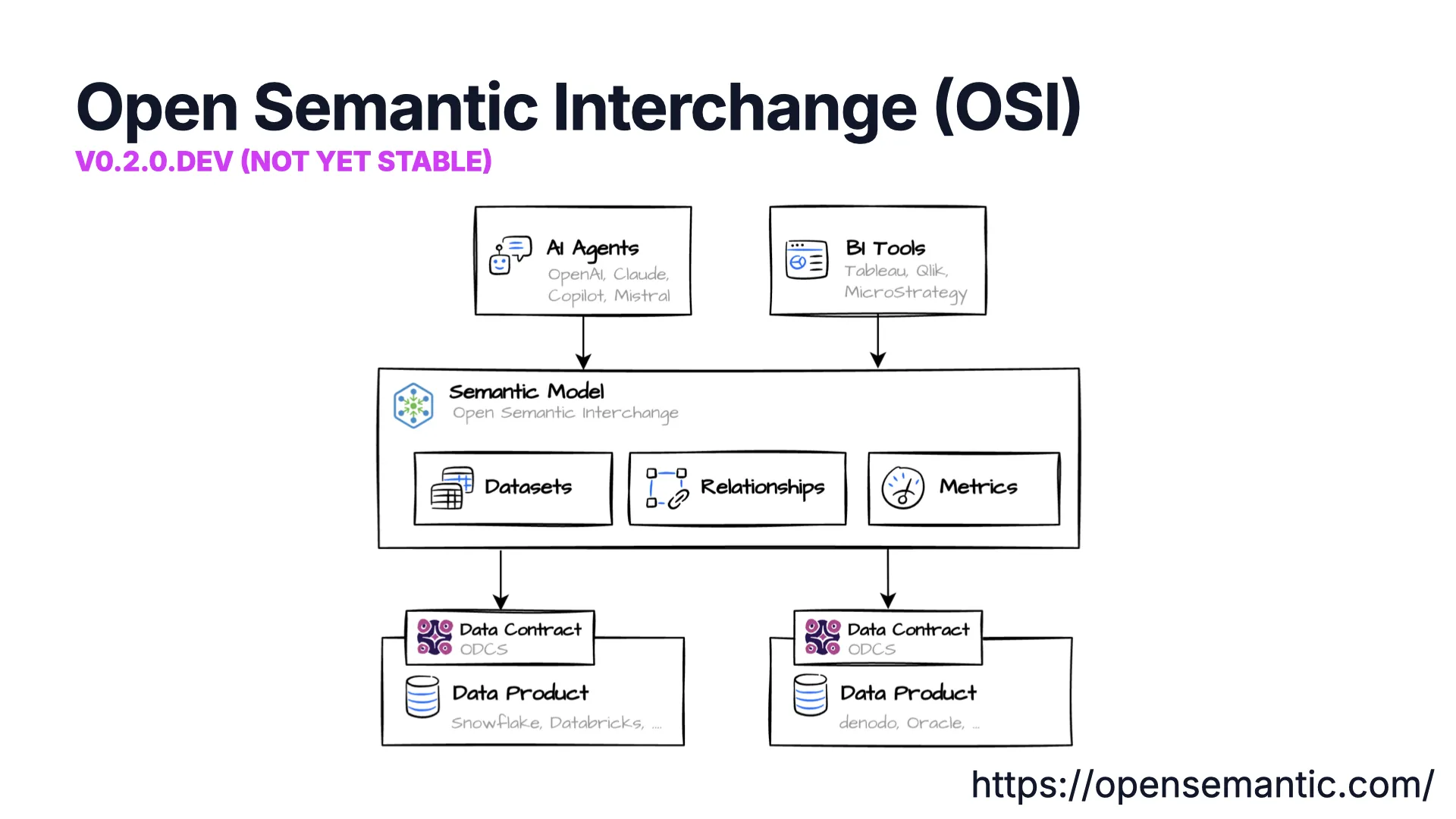

Open Semantic Interchange
The third pillar is meaning. Open Semantic Interchange (OSI, still v0.2.0.dev) defines a shared semantic model — datasets, relationships, and metrics — that both AI agents and BI tools (Tableau, Qlik, MicroStrategy) can consume from one place.
It is the layer that tells a tool what an "order" or an "average order value" actually is, rather than leaving every consumer to guess. Data contracts and data products point at it. (More: Semantics.)

Contract vs. Semantic Model
ODCS and OSI overlap, but they pull in different directions. Both cover schema, relationships, and custom properties. OSI adds first-class metrics, dynamic fields, and AI context; ODCS adds terms of use and quality & SLAs.
The two are complementary — the contract governs the exchange, the semantic model carries the meaning — and the gaps on each side (metrics for ODCS, governance for OSI) are exactly what the working groups are closing.

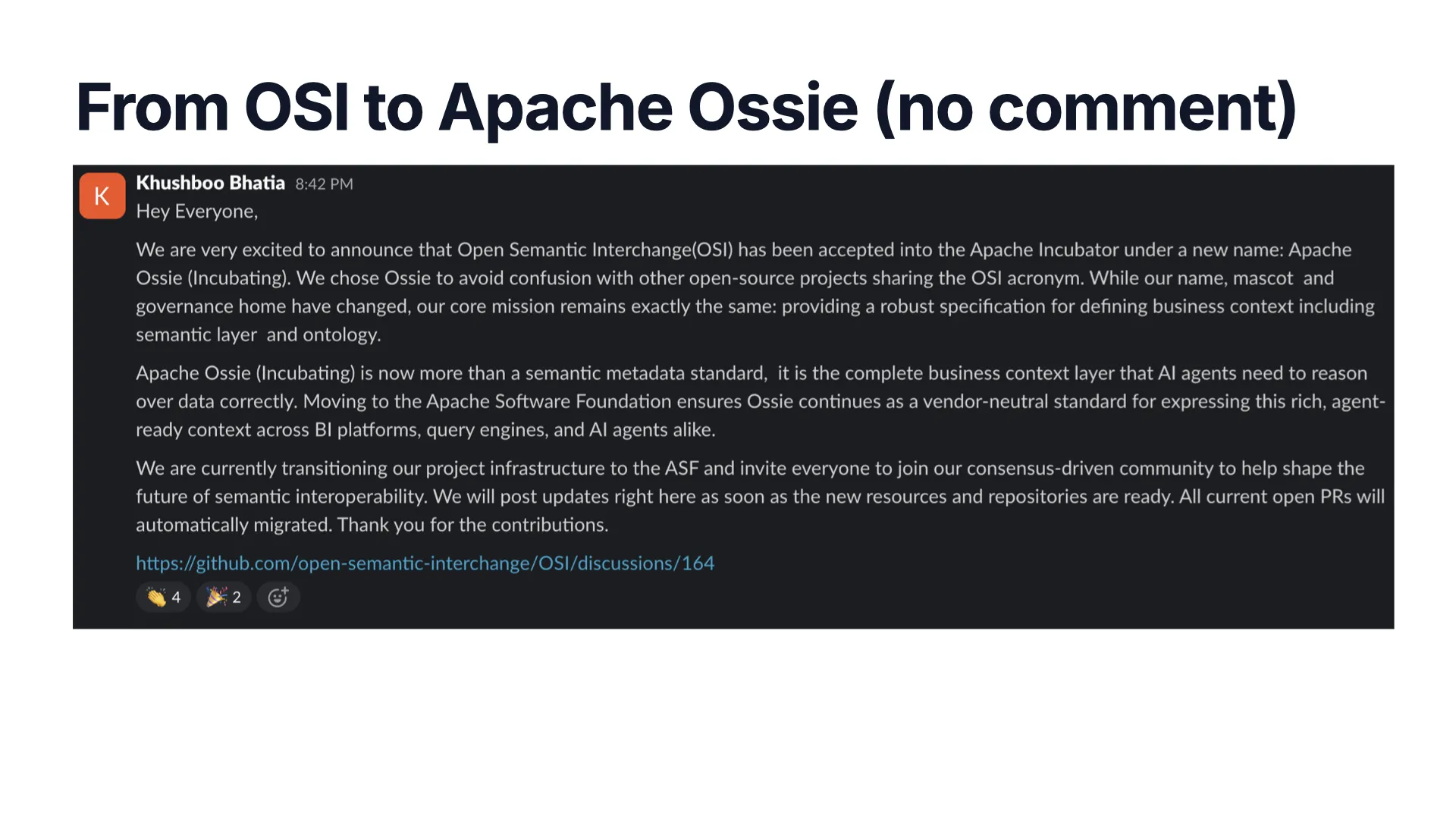
A Lot of Power Behind It
OSI has serious momentum — working groups on advanced metrics and an expression language, composability, catalog integration, ontology representation (already landing in 0.2.0.dev), and model converters.
The headline: OSI has been accepted into the Apache Incubator under a new name, Apache Ossie — moving to a vendor-neutral home so it can keep growing as the shared business-context layer that AI agents and BI tools both need.
The Future Is Now
Back to the opening question — what if we already were using open standards for data products? — and the answer lands: we do. Simon drops into a fresh project, points a coding agent at an ODCS/ODPS spec, and lets it build a real data product on Snowflake.
The contract says what, ODPS wires the ports, OSI supplies the meaning, skills carry the how, and tools provide the access. Every box from the first slide is now a real, open standard — and the agent does the typing.
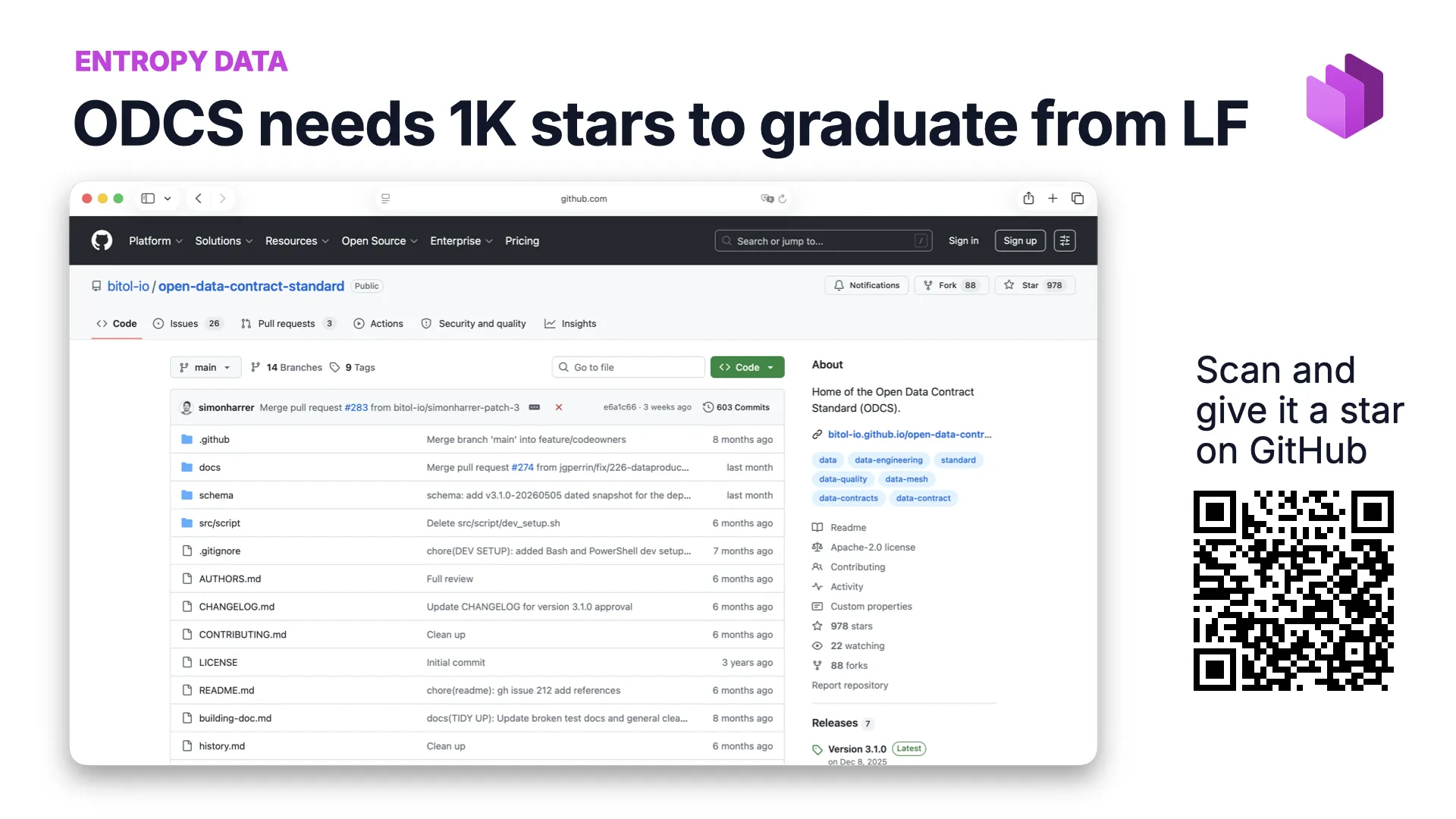
Help ODCS Make History
Here is how the room can help write the next chapter: ODCS needs 1,000 GitHub stars to graduate within the Linux Foundation. Graduation is a signal of adoption — exactly the de-facto traction that keeps a de-jure standard alive.
If the standards in this talk are useful to you, give the ODCS repo a star. It costs a click and helps an open standard stay open.

Thank You
That is the case: data products built on a stack of open standards — ODCS for contracts, ODPS for products, OSI for semantics — let agents and humans build and consume data the same way. The future isn't coming; it's a git clone away.
Try the contract-based data product marketplace yourself at demo.entropy-data.com, reach Simon at simon.harrer@entropy-data.com or on LinkedIn, and give datacontract-cli a star on GitHub if it has been useful.