Talk · 2026
Data-first or Contract-first?
Jochen Christ (CTO & Co-Founder, Entropy Data) · June 11, 2026
When you build a data product, where do you start? Jochen walks two routes to the same destination. The traditional data-first path pulls production data, explores it, and ships what is there. The contract-first path starts with a conversation, writes the contract before the data exists, and lets a coding agent build the product from it. Along the way: data contracts, the Open Data Contract Standard, the Data Contract CLI, and a live build of the same shelf-warmers product that runs in about ten minutes.

Annotated slide notes from Jochen Christ's conference talk. The text below is an edited summary.
The Speaker
Jochen Christ is a software engineer into data who, in his own words, builds tools that help data, people, and AI work together. He is co-founder and CTO of Entropy Data, author of the Data Mesh Architecture website, maintainer of the Data Contract CLI, and a TSC member of the Linux Foundation's Bitol project, home of the Open Data Contract Standard.
Entropy Data is a data product marketplace built on data contracts and semantics, with the goal of making high-quality data available to both humans and agents.

Where Does the Journey Begin?
One question frames the whole talk: when you set out to build a data product, what is your starting point?
- Path A, traditional: start with the data. Pull production data, explore it, build a product, then define the contract to it.
- Path B, alternative: start with the contract. Agree the interface with the data consumers first, specify the contract, then build it.
Is the second route a detour, a shortcut, or just a different path to the same goal? That is what the talk sets out to answer.
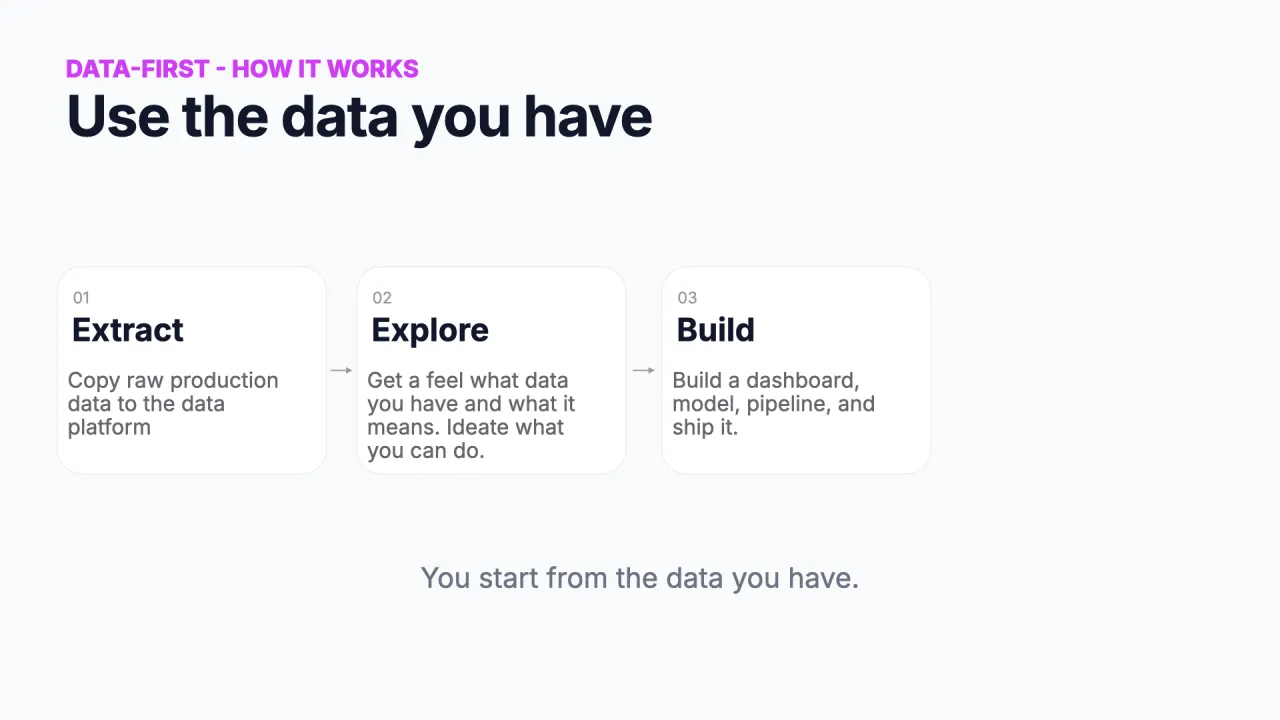

Use the Data You Have
This is how data engineers have always worked. You extract data from production into your data platform, you explore it to discover use cases and patterns, and you build a dataset, dashboard, or report to ship. It is the natural rhythm of data engineering and analytics.
It has real strengths: creativity (you see patterns and errors you would never have thought to ask for), speed (a SQL query gives you a prototype in minutes), and it is grounded in reality, because you are working with the actual data that exists.


But Exploration Alone Is Not a Product
The catch with data-first is that what you have is not yet a product. Four problems show up again and again:
- Undefined ownership, the core issue of data mesh: who owns this dataset long-term?
- No documentation: a column called
TX021is a timestamp, but the order date, the payment time, or something else? - Not yet production ready: no quality rules, no checks, no expectations.
- Large technical datasets: copying production gives you wide, raw tables nobody can navigate.
The first fix is to put the data under contract, which adds a fourth step to the path: test.


What Is a Data Contract?
A data contract is a YAML document that captures who owns the data, its terms of use, a description, and its schema, semantics, quality, and SLAs.
Think of it as an API specification, but for data. REST APIs have OpenAPI, messages and Kafka topics have AsyncAPI, and shared datasets have the Open Data Contract Standard. Same idea, different interface.
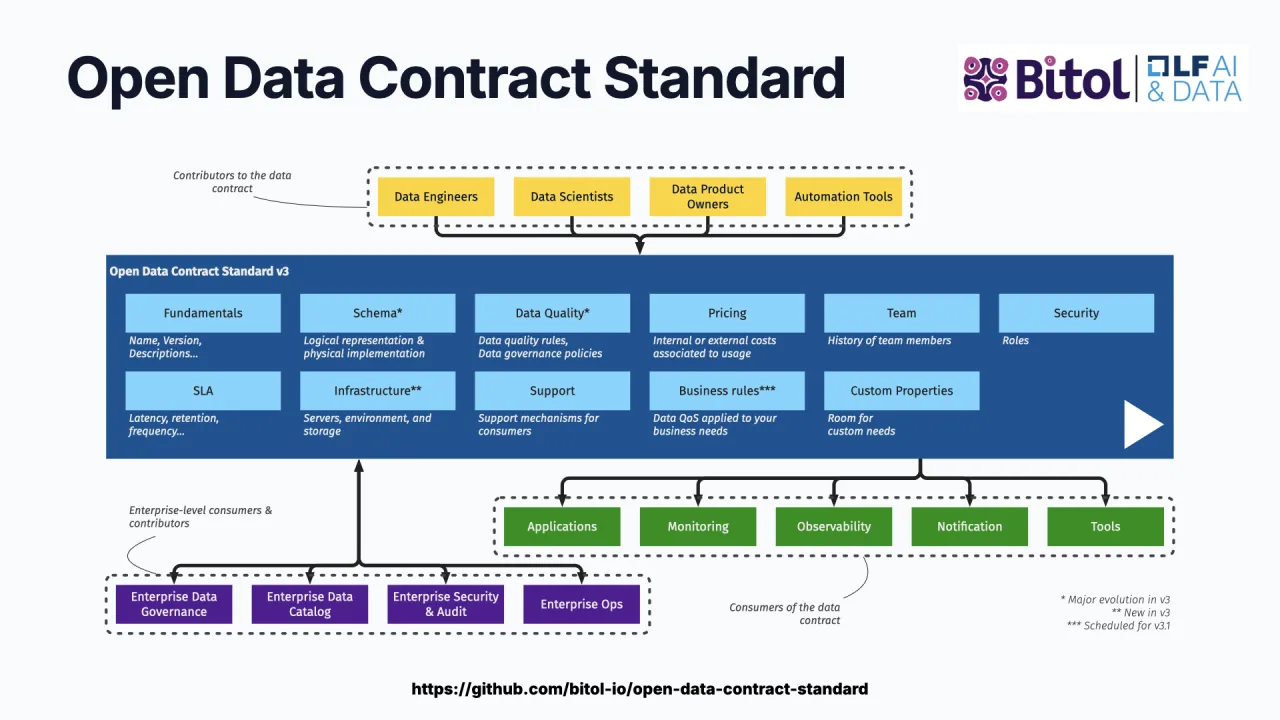
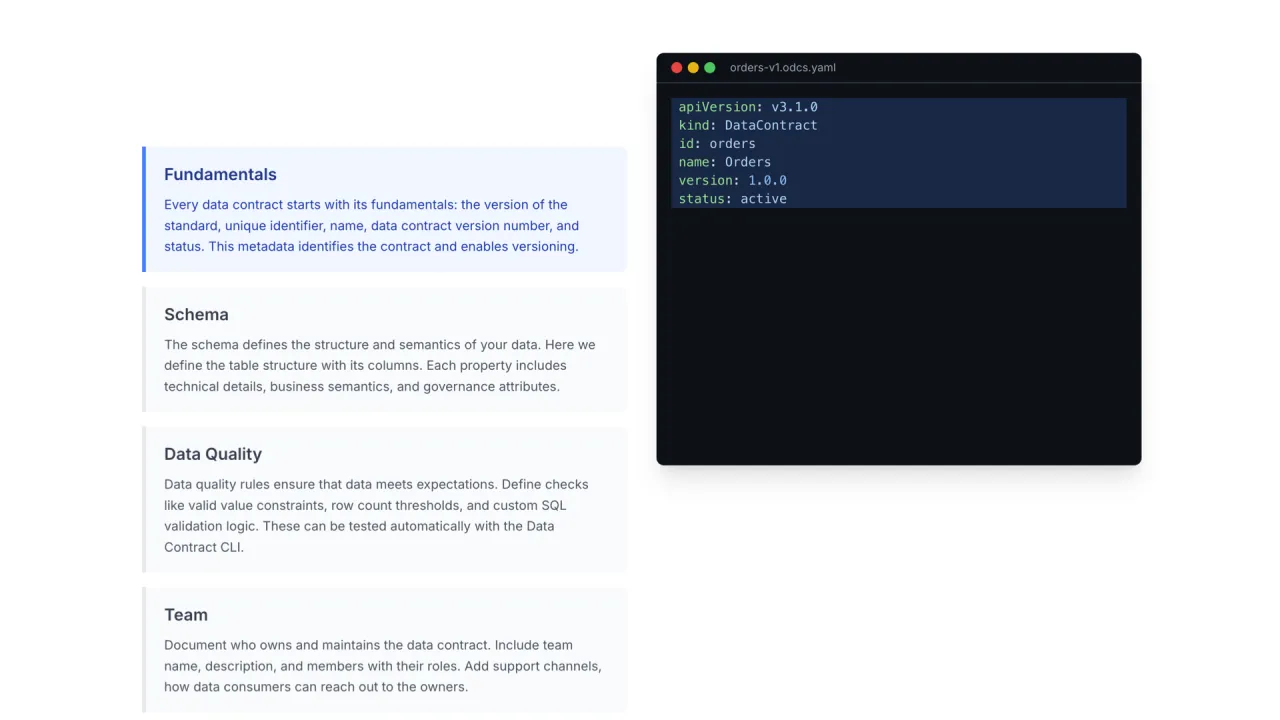
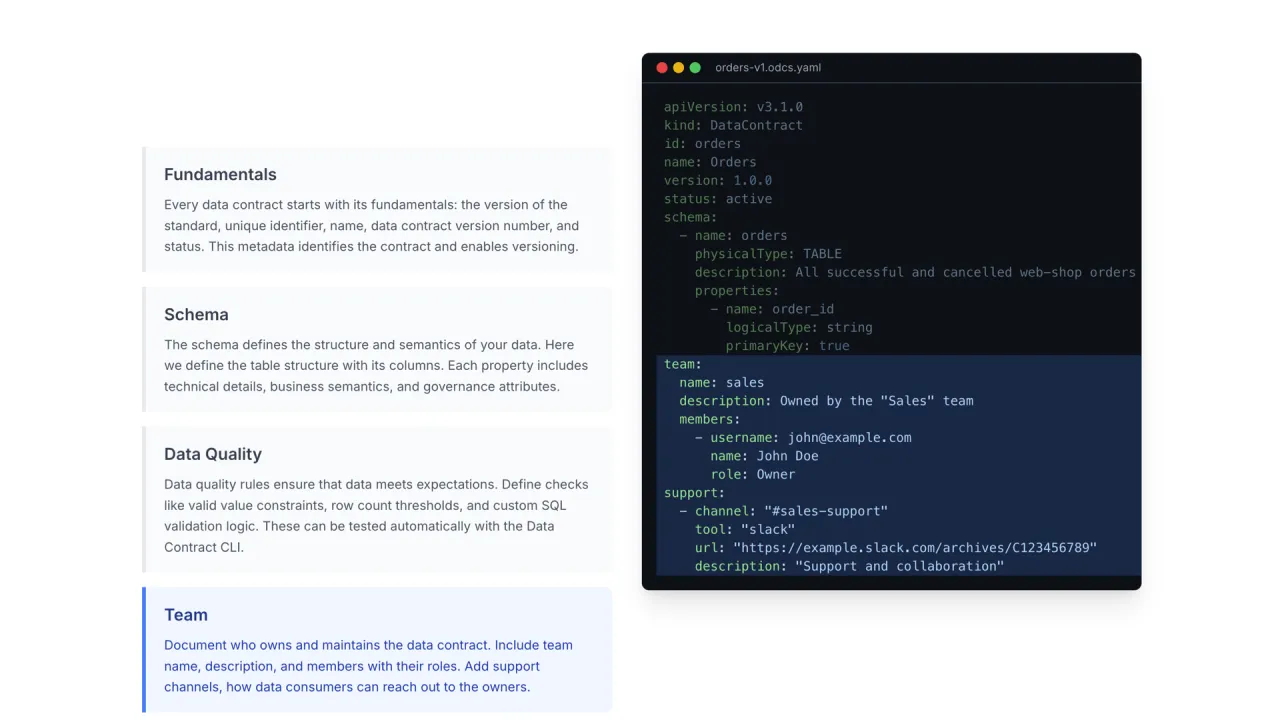
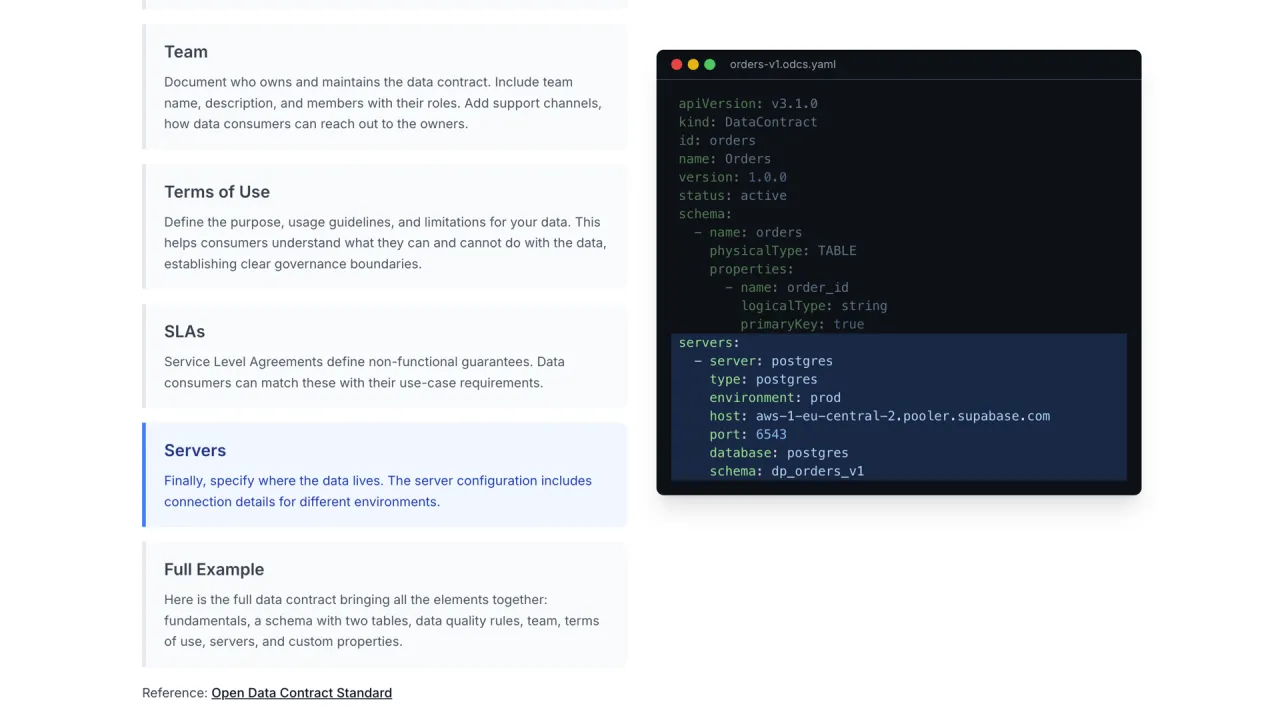
The Standard: ODCS
The industry standard for data contracts is ODCS, the Open Data Contract Standard, governed by the Bitol project at the Linux Foundation. A single YAML file holds everything a consumer needs:
- Fundamentals: name, version, status.
- Schema: tables and columns with examples, classifications, and tags, so it is more than a bare SQL schema.
- Quality as code: presets like "number of invalid values must be zero", or arbitrary SQL checks that actually execute.
- Team: the owner of the data product and contact information.
- Terms of use: the intended purpose and the limitations, for example "this order data may not be used for marketing".
- SLAs and servers: the guarantees, and where the data actually lives.
The terms of use are arguably the most important part: they say what the product is for, and what it must never be used for.

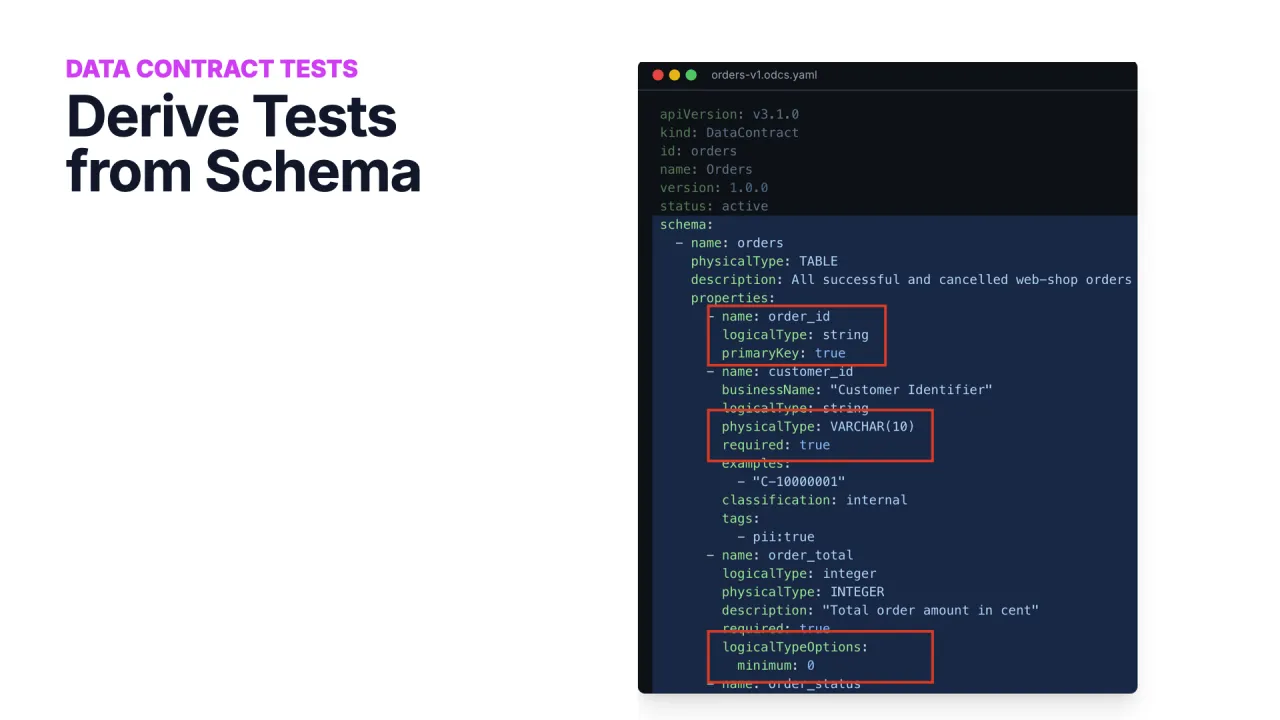
Turn the Contract Into a Test
A contract is only worth something if you can enforce it. The open-source Data Contract CLI reads the YAML, connects to your data product on Snowflake, Databricks, BigQuery, Postgres, or wherever it lives, and turns the schema, quality rules, and SLAs into SQL statements it executes against the real data.
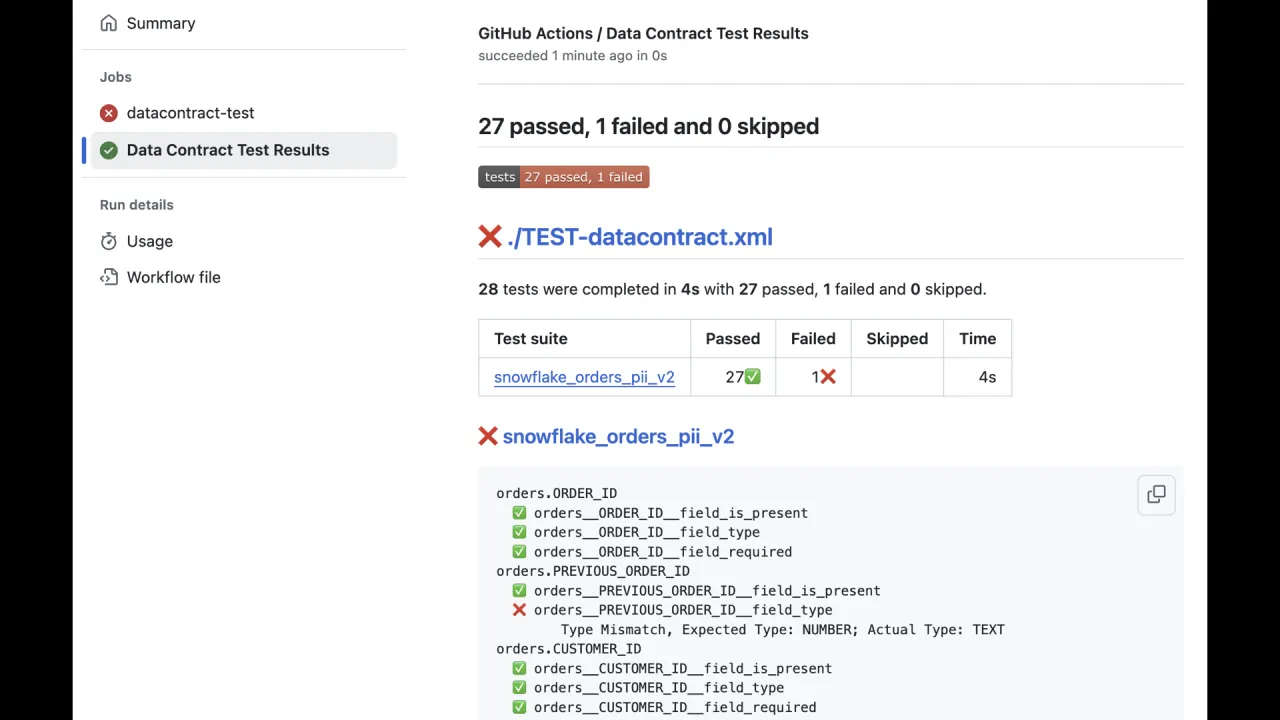
Run datacontract test and you get an exit code: zero is good, non-zero means something broke. Drop it into a deployment pipeline, an Airflow DAG, or a Databricks job to verify, on every change, that the running product still honours every guarantee in the YAML.
In the CI run on the slide, 27 checks pass and one fails, catching a type mismatch where a column the contract expects to be a number is actually text.

There Is More: Publish It
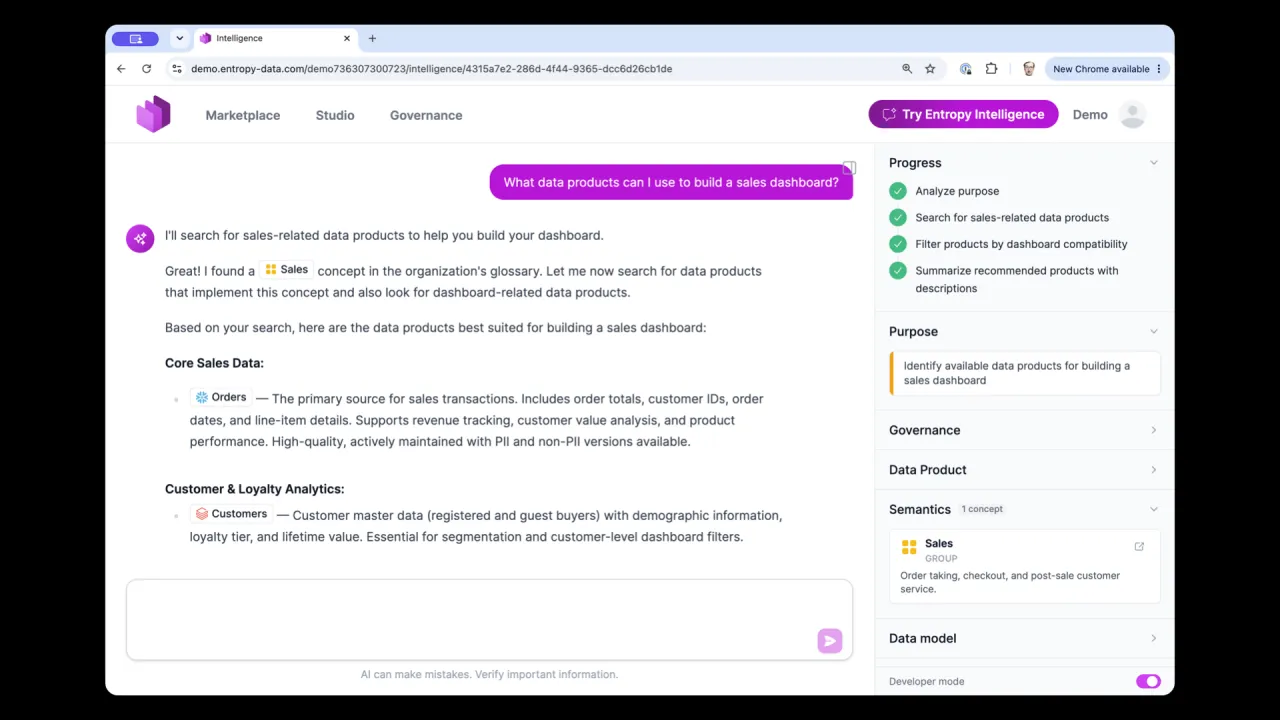
Data mesh is about sharing data products across team boundaries, so the path gains a fifth step: publish. The same YAML can be pushed into a metadata tool, catalog, or marketplace such as Entropy Data, making the product discoverable, readable, and approachable rather than just a raw YAML file.
And because it is metadata on an open standard, agents can read it too. They can search the marketplace, then chat with or autonomously query the data, while respecting the terms of use defined in the contract, the purpose and the limitations, so access stays secure.

Three of Four, Solved
Putting the data under contract fixes three of the four problems: now there is a named owner, an agreed interface with documentation, and executable quality tests.
What it does not fix is the large technical dataset. Data-first tends to publish whatever came out of the source system, so you still get wide tables of lookalike columns where nobody knows which ones the business actually cares about. To solve that, you have to change where you start.


Begin With a Conversation
Contract-first does not start with the data. It starts with a conversation. Before you look at a single column, you meet your data consumers and understand what they actually want to do: an AI model, a CFO dashboard, an operational use case. Then you specify those requirements as a contract, build the product, and test it.
Writing the contract up front is also the best documentation you will ever get, because you still have the energy to write it. Nobody writes good docs after the product ships.
The benefits compound: collaboration and sympathy (you know someone actually needs this), business language (you use the consumer's terms, not raw column names), real expectations (quality rules that mean something), and a right-sized data product with only the fields that are truly needed, which is exactly what fixes the large-dataset problem.
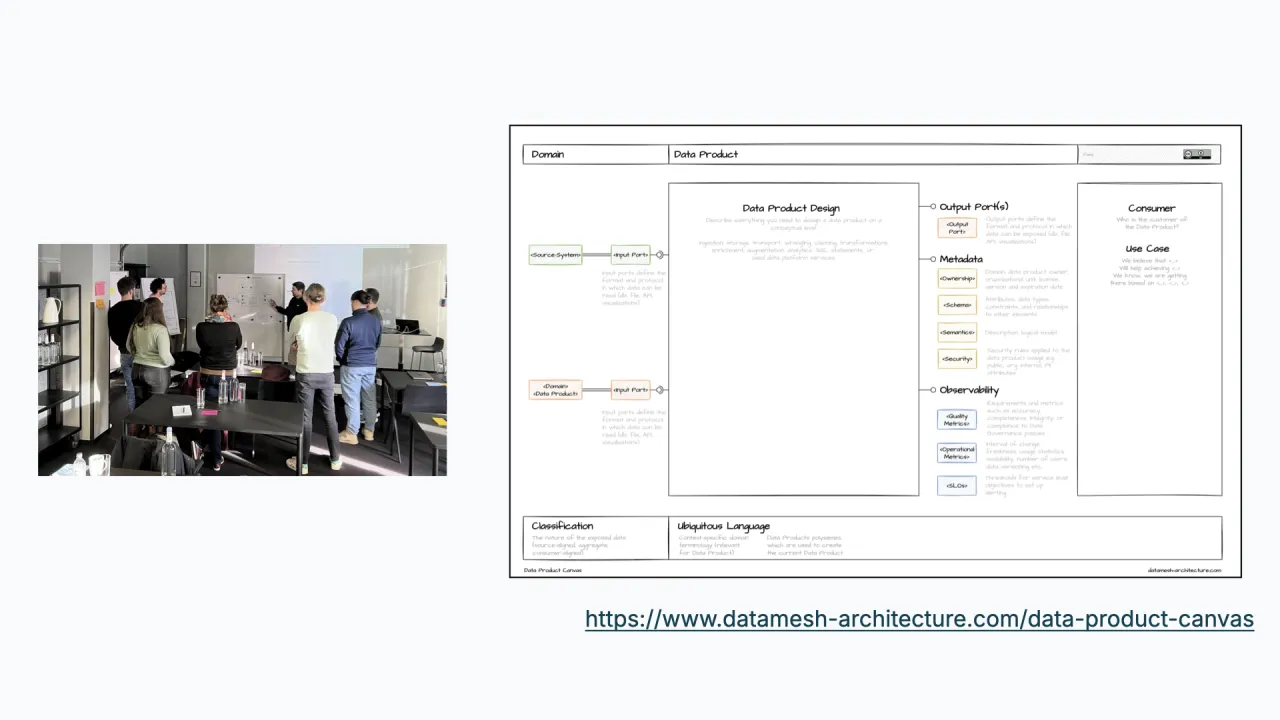

Drive It From the Business Case
You start with a workshop, ideally on site, with stakeholders and the future data product owner. A data product canvas structures it: you fill it from the right, beginning with the business case, and let that drive the interface and the sources you will need.
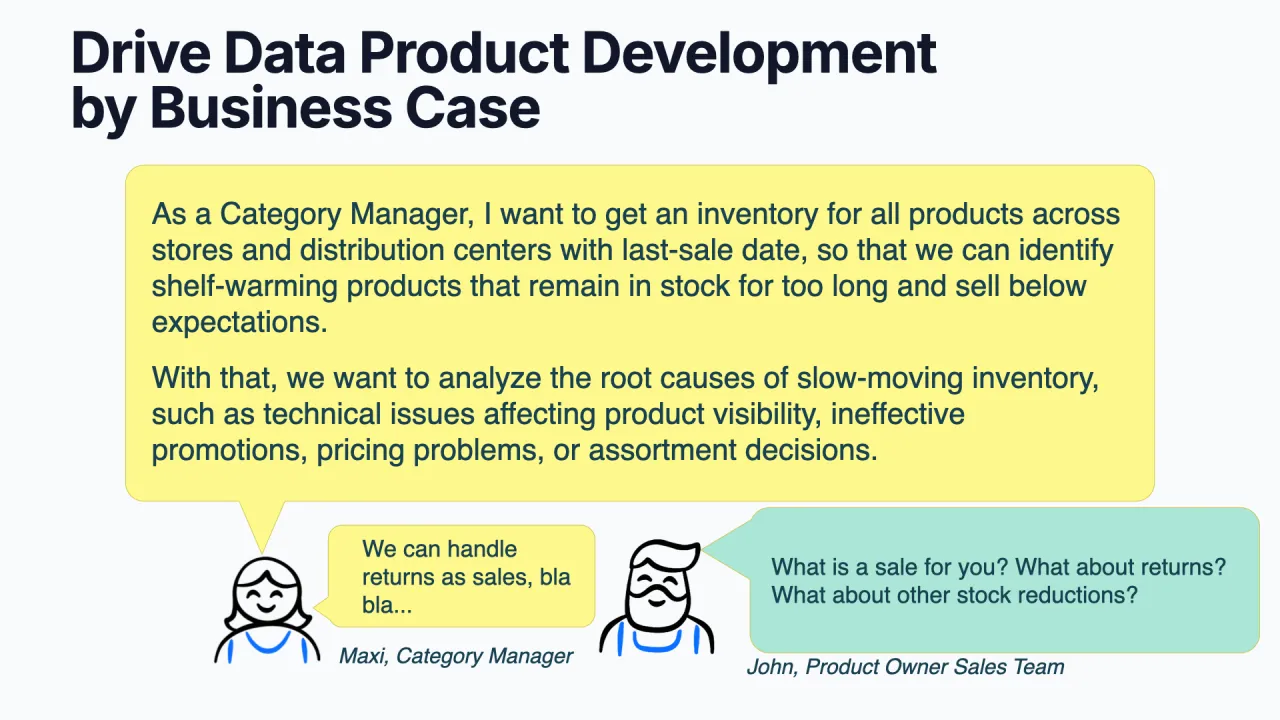
The running example: Maxi, a category manager at an e-commerce company, wants an inventory of products that have not sold in the last six months, the so-called shelf warmers that sit in the warehouse gathering dust. "Shelf warmer" is the business term, and that is the point.
John, the product owner in the sales team, pushes back with the questions that sharpen the contract: what counts as a sale? Do returns count? What about write-offs or stolen stock? Those answers become the contract's semantics.
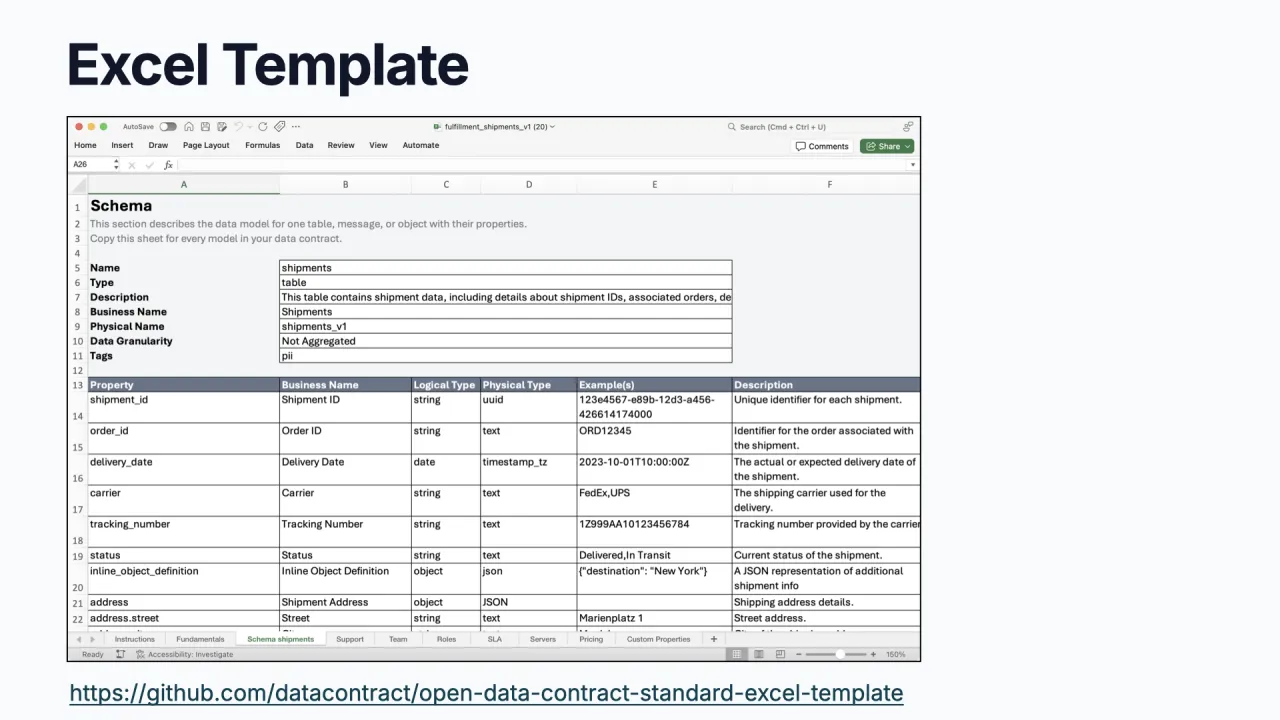
Capture It Where Business Can
Raw YAML is not accessible to business users. After seeing three customers independently capture contracts in Excel, the team shipped an official ODCS Excel template, plus a CLI converter between Excel and YAML in both directions. Product owners fill in the sheet, pass it around, and convert when they are happy.
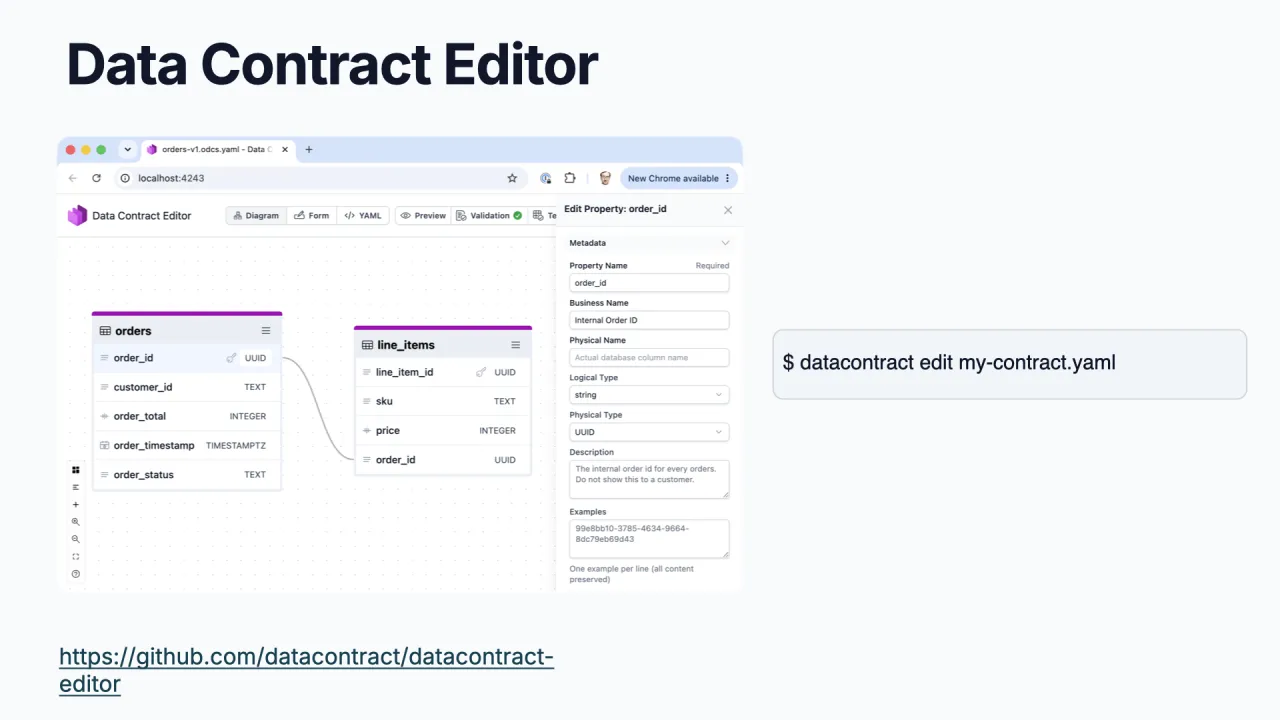
For engineers, the open-source Data Contract Editor turns a contract into a visual experience with diagram and entity-relationship views. It is now built into the CLI, so datacontract edit <name> pops the editor straight open.
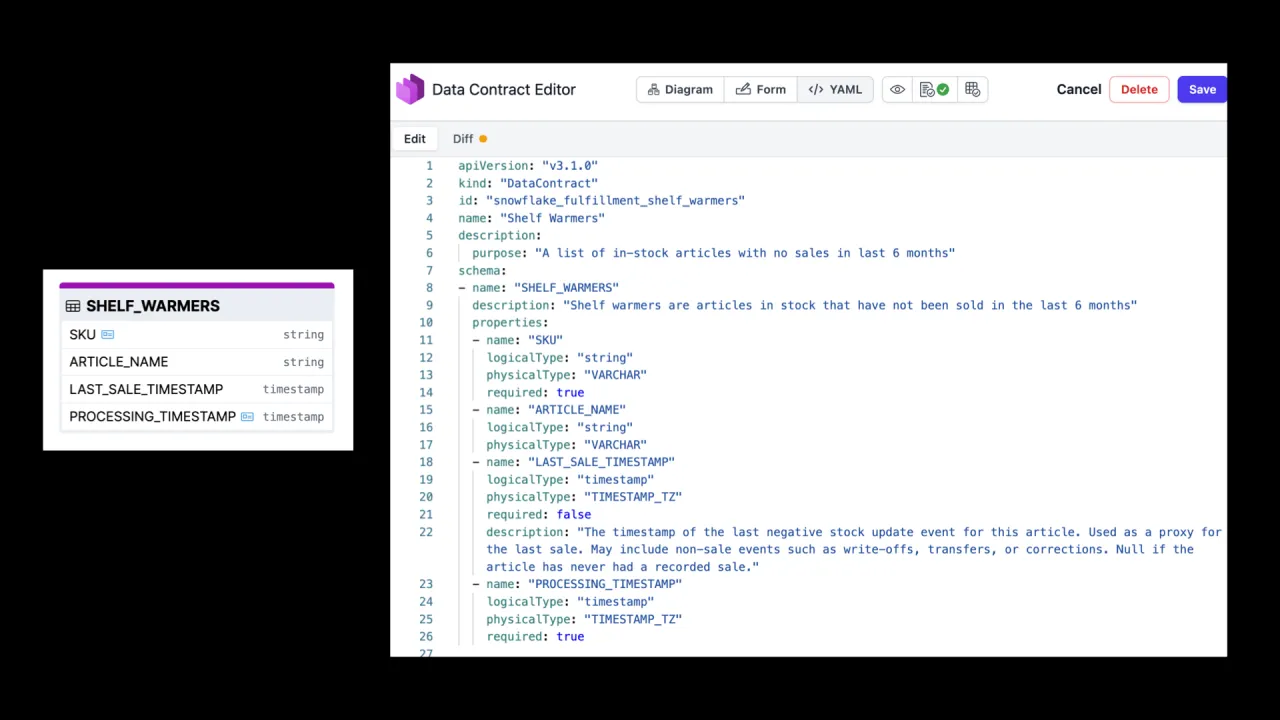
A Right-Sized Contract
The requirement, once understood, is tiny. Maxi does not need the full orders table or the full stock table. She needs one table, shelf_warmers, with four columns: an SKU (the article number), an article name, a last-sale timestamp, and, by organisational convention, a processing timestamp.
The work that matters here is the semantics: spelling out what "last sale" really means. The description notes it is the timestamp of the last negative stock movement, may include non-sale events like write-offs, and is null if the article has never had a recorded sale. That sentence is the difference between a usable product and a guessing game.

Build It With a Coding Agent
With the contract specified, you build, and today that means a coding agent (Claude Code, Codex, Copilot CLI). The agent needs two inputs. The first is the contract YAML: what to build. The second is how your organisation builds data products, because the agent does not know whether you use Snowflake, dbt, or your own naming conventions.
That "how" is delivered as skills: instructions for the coding agent, kept in a git repository.

Skills: Teach the Agent Your Stack
The open-source dbt Data Product Builder is a template repository you clone and adapt to your conventions. Each skill is just a markdown document with the steps to follow: a bootstrap skill for a brand-new product, an implement skill for changes, plus skills for metadata and testing.
A skill can, for instance, define how an ODCS field maps to a dbt model, or carry a template for what a dbt project looks like in your organisation, which the agent then respects. You install it through your agent's plugin marketplace and connect it to your metadata and dbt project.
"Testing is cheap, so you can add more and more skills, and skills can reference other skills."
The Build
The whole instruction is one line: implement the data product for the contract. The agent reads the contract, recognises this is a new product, loads the bootstrap skill with its dbt template, and goes to work in YOLO mode, setting up the dbt models and OpenLineage wiring the skills prescribe. Shown in the talk as a screen recording; the live build takes about eleven minutes.
Crucially, it also uses the marketplace to find its upstream sources. To fulfil the contract it looks for stock-update events and article master data, finds those existing data products, and requests access as part of the generated code.
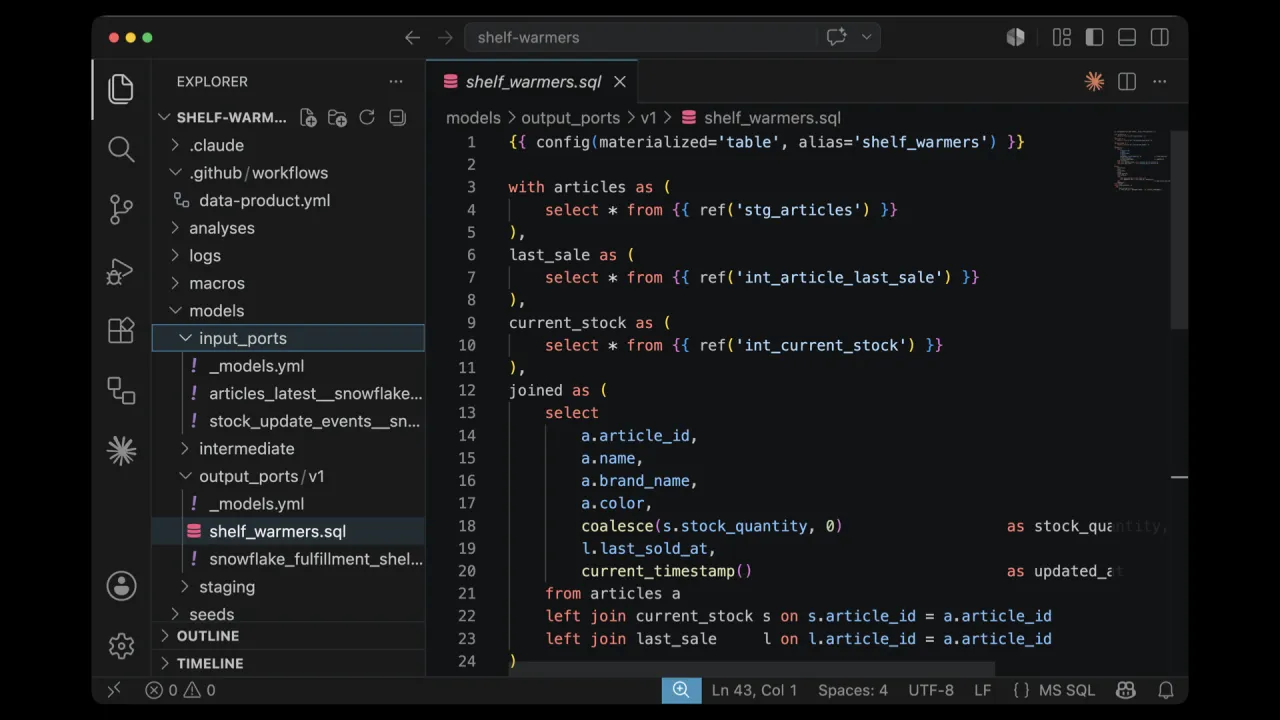
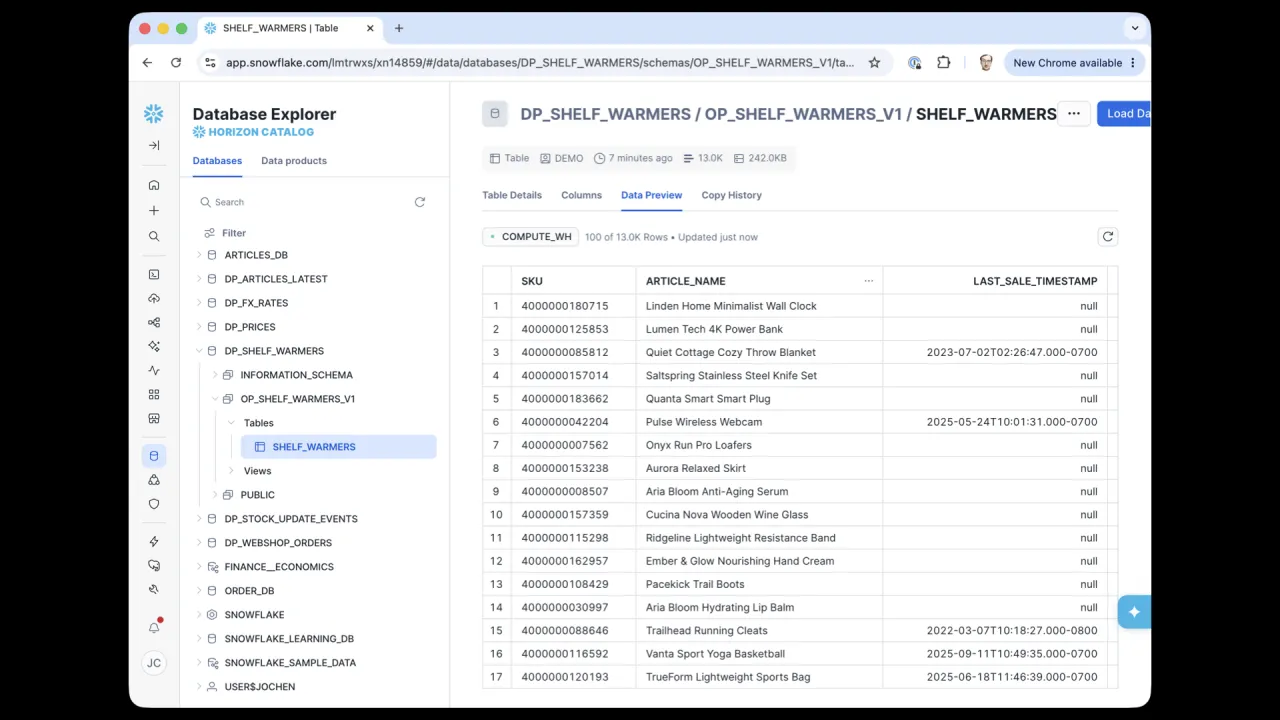
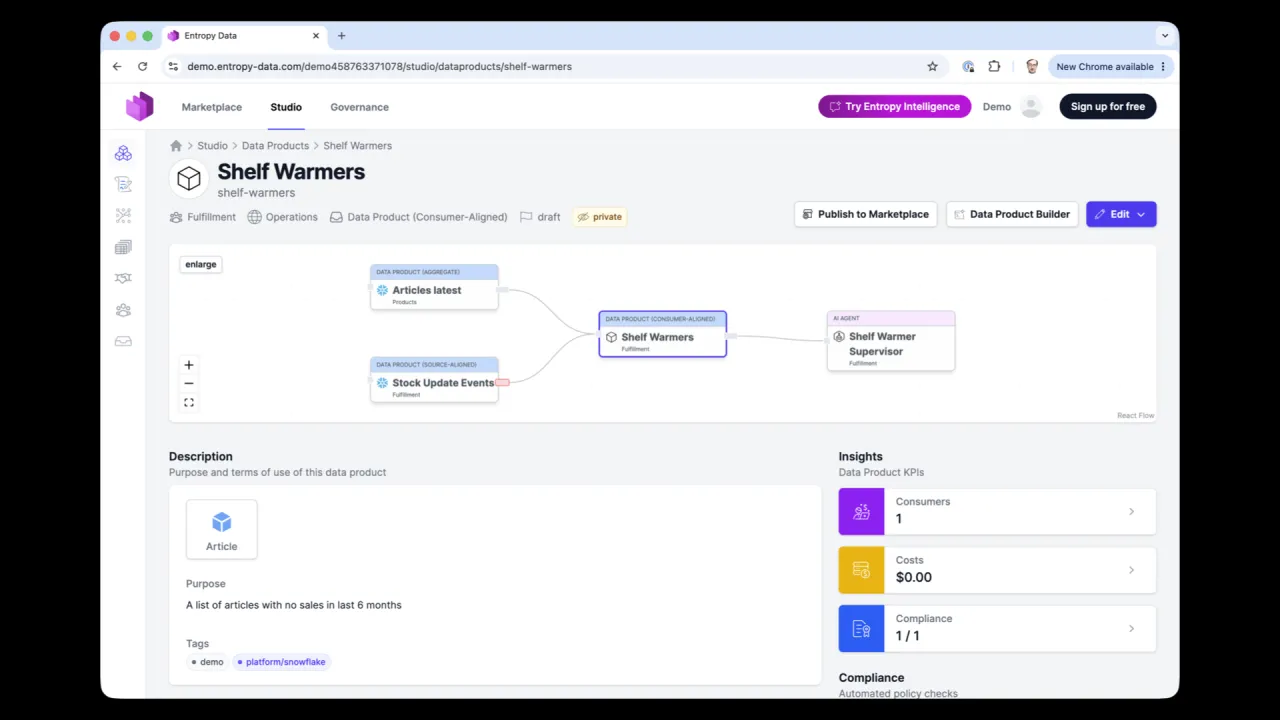
The Result
About eleven minutes later, the product is built: a full dbt project with input and output ports, the SHELF_WARMERS table populated in Snowflake, and the data product published to the marketplace in private mode, ready for its owner to make public.
The contract tests, also part of the skills, run as a step in CI or your data pipeline. When the contract is green, you ship. Implementation by a coding agent, but the requirements, semantics, and guarantees are all yours.

Ship When the Tests Are Green
Contract-first runs understand, specify, build, test. You spend the time up front to understand and specify the requirements as a contract, the coding agent implements it, the contract tests run in your pipeline, and when they are green you ship.

There Is No Wrong Path
Both routes reach the same destination: a product in production, delivering value. So what is the answer? Three takeaways:
- A contract is what makes data trustworthy. It captures requirements and semantics and automates testing, so when something would break a consumer's expectations, it turns red and you get notified.
- Talk with your data stakeholders. There is no shortcut. If you do not understand the business value of a data product, it is probably not worth building. Take product ownership seriously.
- Coding agents implement what you specify. The better your specification and descriptions, the better the agent builds, and the better it can flag what is missing or off.
"Data contracts are what make the difference. They are what make your data product trustworthy."
Q&A
Selected questions from the audience after the talk.
Q: If the agent generates the dbt models, who maintains them afterwards? Do I edit the dbt code, or go back to the contract and regenerate?
It depends on your culture and engineering maturity, but personally I would not look too much into the dbt code anymore. I would change the requirements in the contract, and if the output is not right, improve the skills. Build a feedback loop into your skill repository and optimise from there, rather than hand-patching generated code.
Q: Do you distinguish a marketplace from a data catalog, or treat them as the same?
We distinguish them. A catalog is a technical index of every dataset that exists, often millions of assets. A marketplace only holds data products that are meant to be shared and consumed by other teams, usually a few hundred. The marketplace is where the contextual, contract-level information lives.
Q: Data-first often surfaces insights nobody asked for. Doesn't always going contract-first mean you only ever answer what people already know to ask?
A fair point, and you do want to keep explorative capability. The key is the boundary: inside your own domain, where you already understand what the data means, keep simple explorative, data-first access. Data contracts matter when you cross an organisational boundary, because that is where a new bounded context begins and shared data needs an agreed, documented interface.
Q: Should the contract specify the physical schema up front, or just the purpose and conceptual model, and let the agent figure out the physical schema?
In the contract I would define the conceptual and logical model and leave the physical, technical implementation to the skill or the target data platform. The business knowledge goes into the model; the platform-specific detail goes into the skills.
Q: We see data contracts at the edges of the data flow, on sources and before consumption. Do you see them used in the middle, on every step of the lineage?
My view is that a data contract provides a new boundary of trust. You probably do not need a contract back to the very first source on every hop; you need lineage back to the last data contract you rely on. Between contracts you can use technical lineage, which is the internal wiring of a data product's pipeline. Trust is anchored at the source contract.