Talk · 2026
Data-first or Contract-first?
Jochen Christ (CTO & Co-Founder, Entropy Data) · 11. Juni 2026
Wenn du ein Datenprodukt baust, wo fängst du an? Jochen geht zwei Wege zum selben Ziel ab. Der traditionelle Data-first-Weg zieht Produktionsdaten, exploriert sie und shippt, was da ist. Der Contract-first-Weg beginnt mit einem Gespräch, schreibt den Contract, bevor die Daten existieren, und lässt einen Coding-Agenten das Produkt daraus bauen. Mit dabei: Data Contracts, der Open Data Contract Standard, die Data Contract CLI und ein Live-Build desselben Shelf-Warmers-Produkts, der etwa zehn Minuten dauert.

Annotierte Folien-Notizen aus Jochen Christs Konferenz-Talk. Der Text unten ist eine redigierte Zusammenfassung.
Der Speaker
Jochen Christ ist ein Software Engineer mit Faible für Daten, der, in seinen eigenen Worten, Tools baut, die Daten, Menschen und KI zusammenarbeiten lassen. Er ist Co-Founder und CTO von Entropy Data, Autor der Website Data Mesh Architecture, Maintainer der Data Contract CLI und TSC-Mitglied im Bitol-Projekt der Linux Foundation, der Heimat des Open Data Contract Standard.
Entropy Data ist ein Datenprodukt-Marktplatz auf Basis von Data Contracts und Semantik, mit dem Ziel, hochwertige Daten für Menschen und Agenten verfügbar zu machen.

Wo beginnt die Reise?
Eine Frage rahmt den ganzen Talk: Wenn du loslegst, ein Datenprodukt zu bauen, was ist dein Ausgangspunkt?
- Weg A, traditionell: mit den Daten starten. Produktionsdaten ziehen, explorieren, ein Produkt bauen, dann den Contract dazu definieren.
- Weg B, alternativ: mit dem Contract starten. Erst das Interface mit den Data Consumers vereinbaren, den Contract spezifizieren, dann bauen.
Ist der zweite Weg ein Umweg, eine Abkürzung oder einfach ein anderer Weg zum selben Ziel? Genau das will der Talk beantworten.
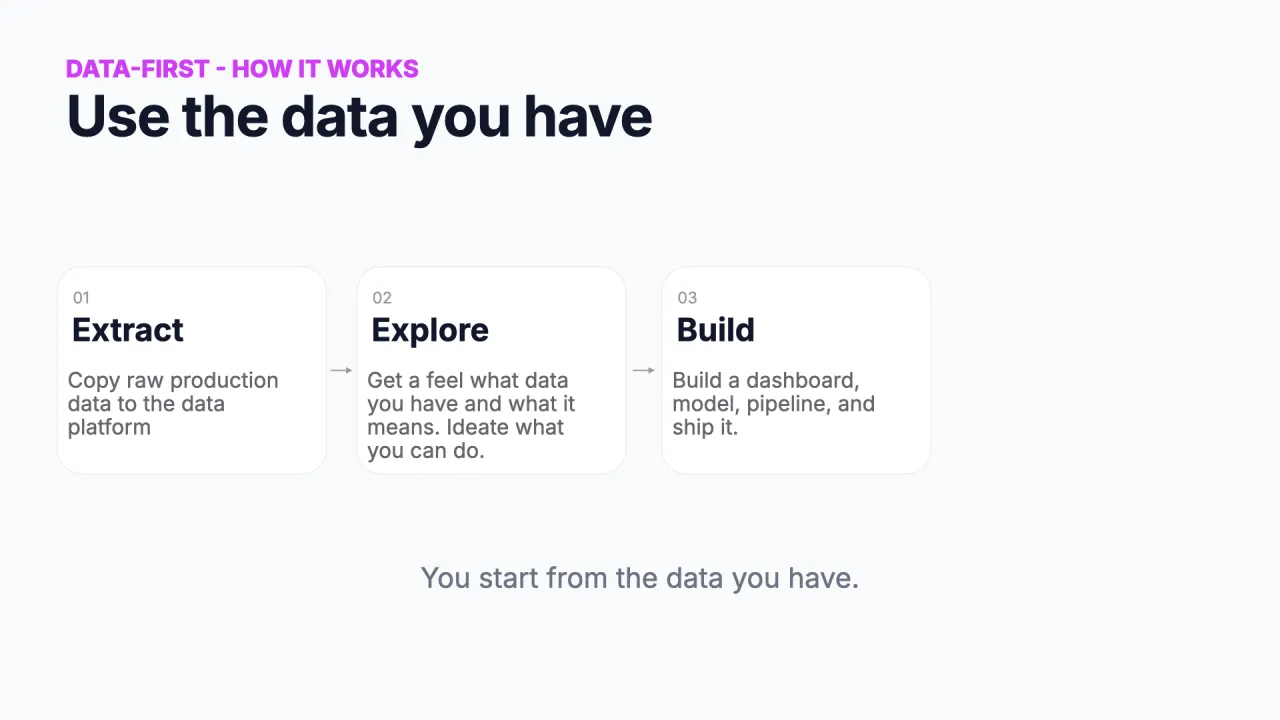

Nutze die Daten, die du hast
So haben Data Engineers schon immer gearbeitet. Du extrahierst Daten aus der Produktion auf deine Datenplattform, du explorierst sie, um Use Cases und Muster zu entdecken, und du baust einen Datensatz, ein Dashboard oder einen Report zum Ausliefern. Das ist der natürliche Rhythmus von Data Engineering und Analytics.
Er hat echte Stärken: Kreativität (du siehst Muster und Fehler, nach denen du nie gefragt hättest), Geschwindigkeit (eine SQL-Query liefert in Minuten einen Prototyp) und er ist in der Realität verankert, weil du mit den tatsächlich vorhandenen Daten arbeitest.


Aber Exploration allein ist kein Produkt
Der Haken an Data-first ist, dass das, was du hast, noch kein Produkt ist. Vier Probleme tauchen immer wieder auf:
- Undefinierte Ownership, das Kernproblem von Data Mesh: Wer besitzt diesen Datensatz langfristig?
- Keine Dokumentation: Eine Spalte namens
TX021ist ein Timestamp, aber das Bestelldatum, der Zahlungszeitpunkt oder etwas anderes? - Noch nicht produktionsreif: keine Quality-Regeln, keine Checks, keine Erwartungen.
- Große technische Datensätze: Das Kopieren der Produktion liefert breite, rohe Tabellen, durch die niemand navigieren kann.
Der erste Fix ist, die Daten unter Contract zu stellen, was dem Weg einen vierten Schritt hinzufügt: Test.


Was ist ein Data Contract?
Ein Data Contract ist ein YAML-Dokument, das festhält, wer die Daten besitzt, ihre Terms of Use, eine Beschreibung sowie Schema, Semantik, Quality und SLAs.
Stell ihn dir wie eine API-Spezifikation vor, aber für Daten. REST-APIs haben OpenAPI, Messages und Kafka-Topics haben AsyncAPI, und geteilte Datensätze haben den Open Data Contract Standard. Dieselbe Idee, ein anderes Interface.
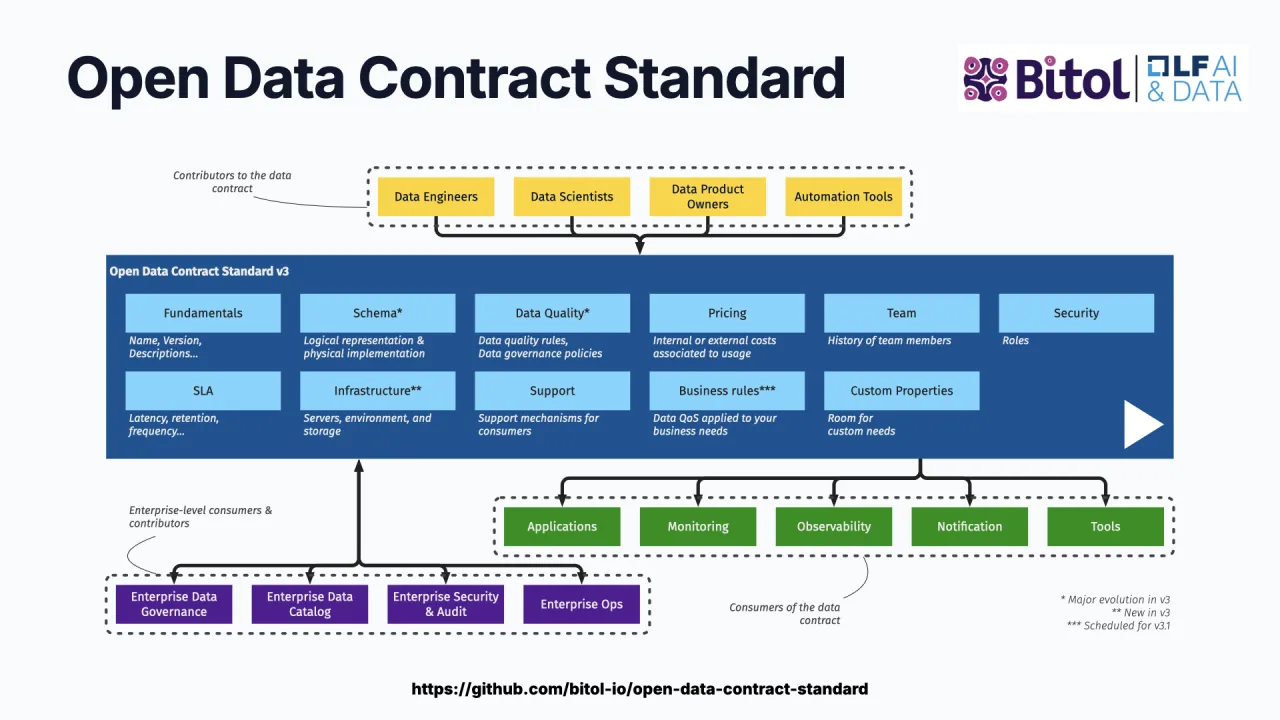
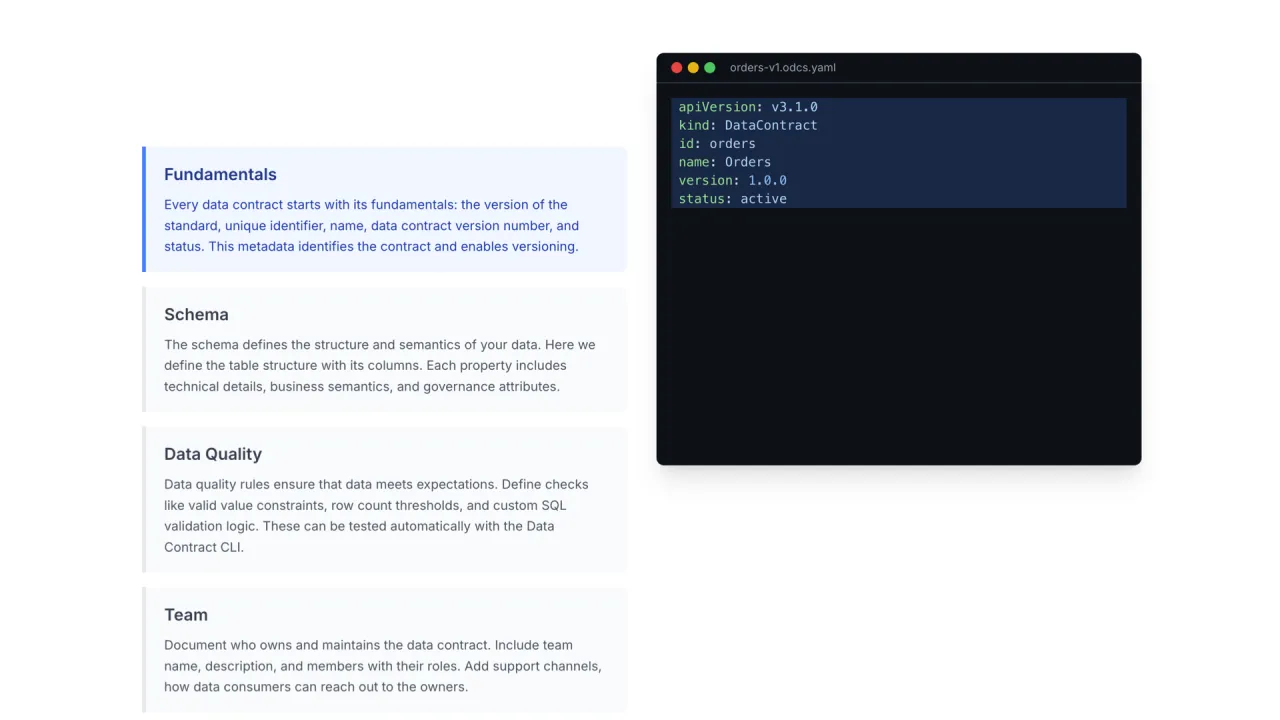
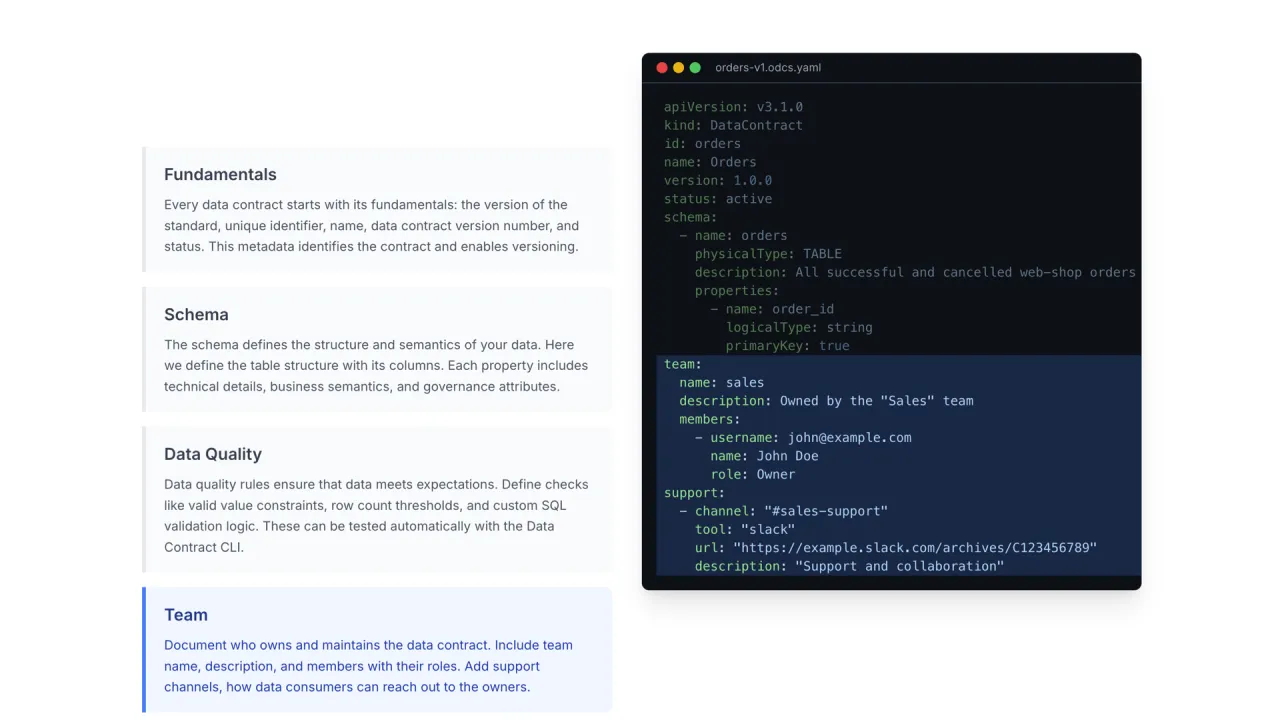
Der Standard: ODCS
Der Industriestandard für Data Contracts ist ODCS, der Open Data Contract Standard, verantwortet vom Bitol-Projekt der Linux Foundation. Eine einzige YAML-Datei enthält alles, was ein Consumer braucht:
- Fundamentals: Name, Version, Status.
- Schema: Tabellen und Spalten mit Beispielen, Klassifizierungen und Tags, also mehr als ein nacktes SQL-Schema.
- Quality as Code: Presets wie "Anzahl ungültiger Werte muss null sein", oder beliebige SQL-Checks, die tatsächlich ausgeführt werden.
- Team: der Owner des Datenprodukts und Kontaktinformationen.
- Terms of Use: der vorgesehene Zweck und die Limitationen, zum Beispiel "diese Bestelldaten dürfen nicht fürs Marketing genutzt werden".
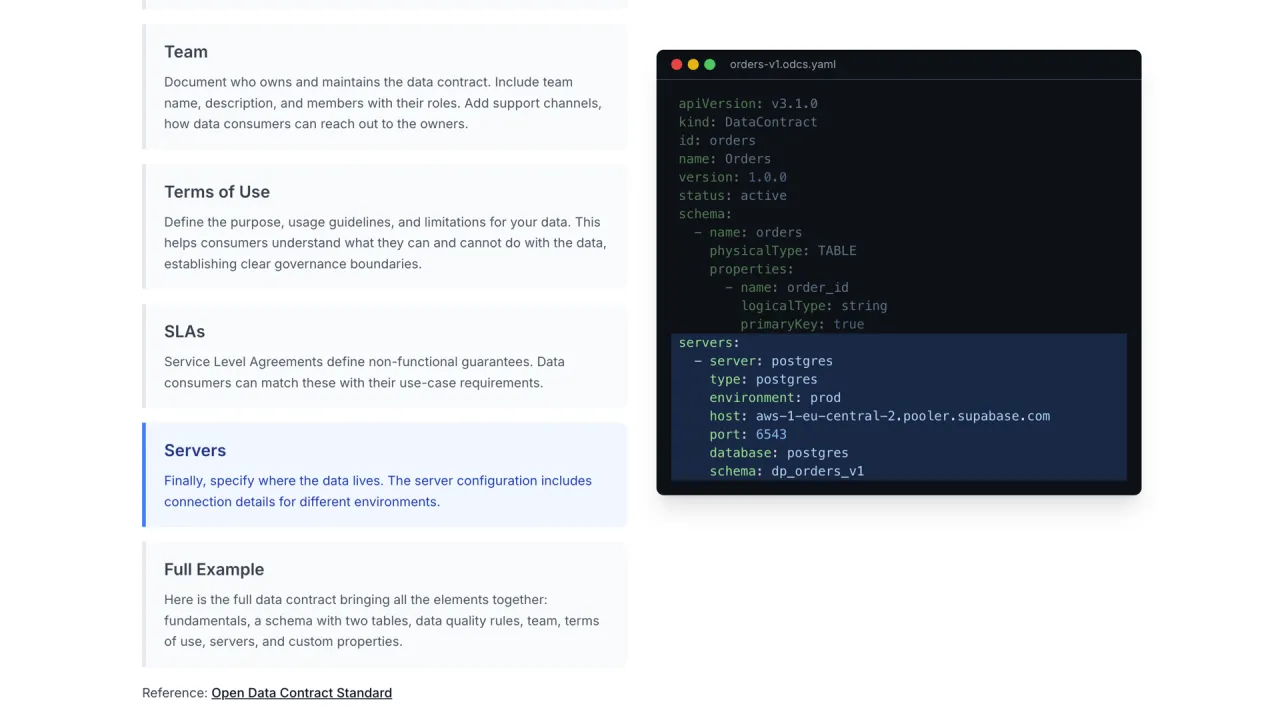
- SLAs und Server: die Garantien, und wo die Daten tatsächlich liegen.
Die Terms of Use sind wohl der wichtigste Teil: Sie sagen, wofür das Produkt da ist, und wofür es niemals genutzt werden darf.

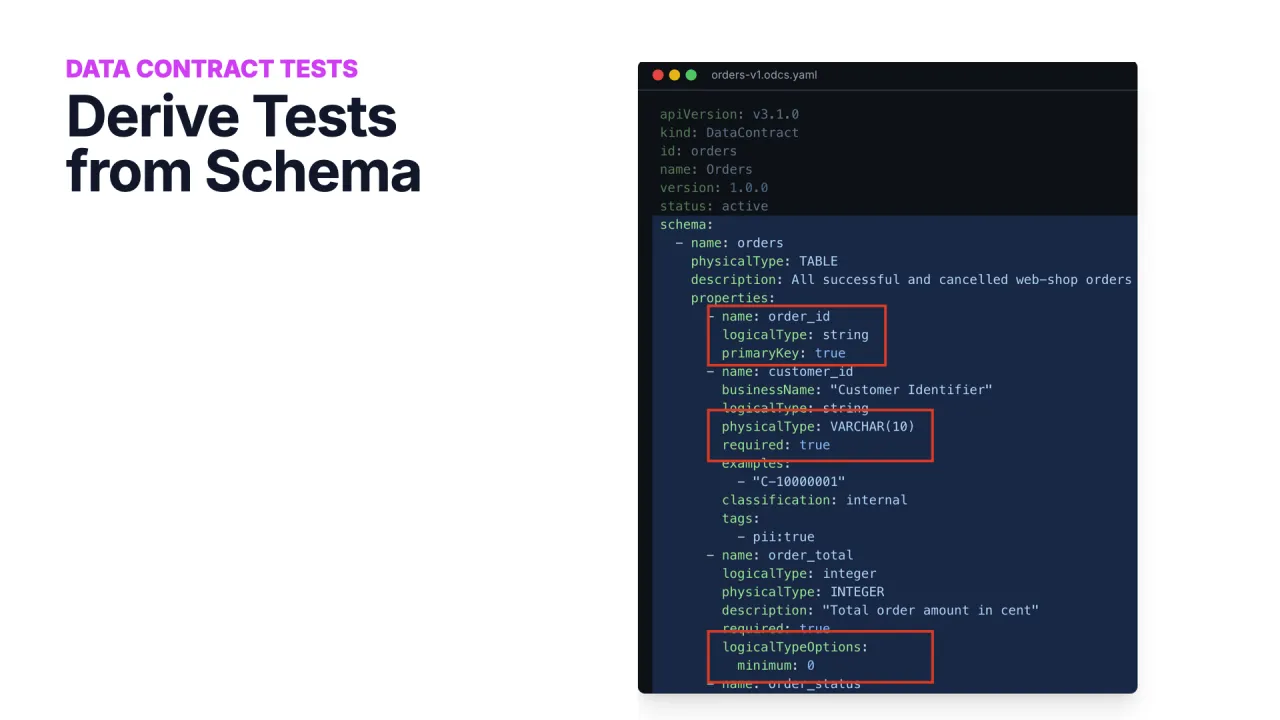
Mach aus dem Contract einen Test
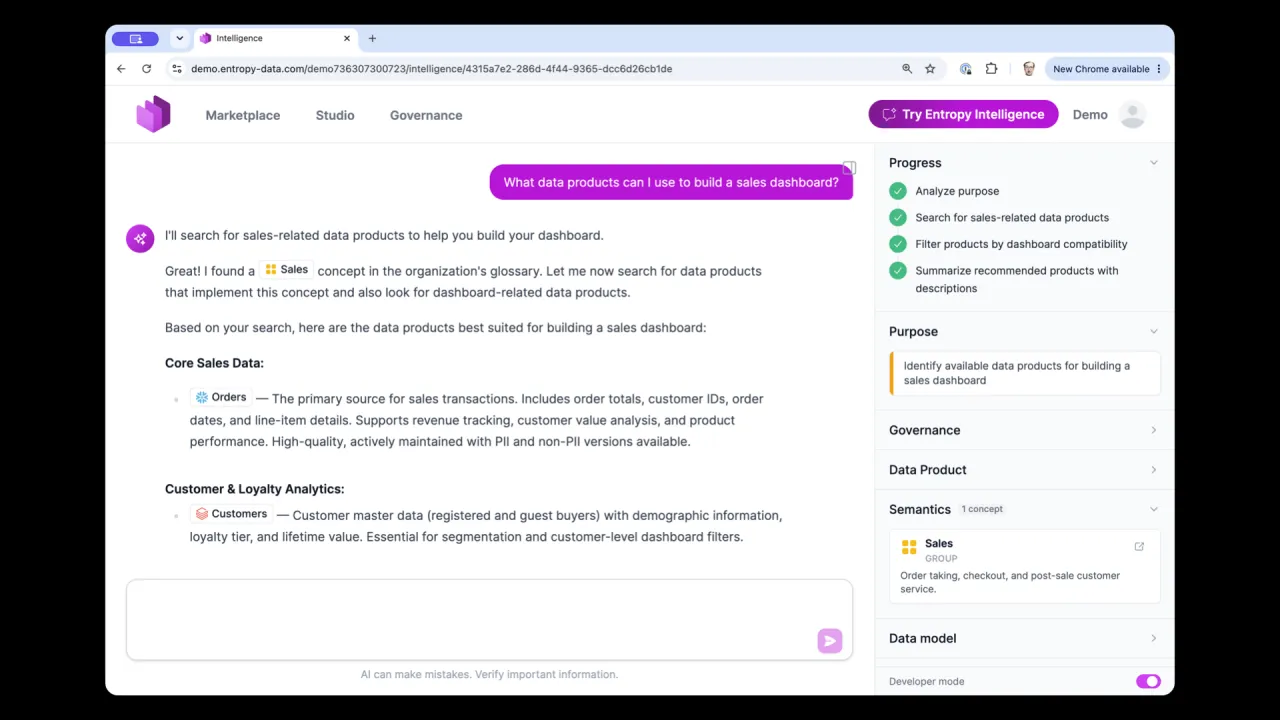
Ein Contract ist nur etwas wert, wenn du ihn durchsetzen kannst. Die Open-Source-Data Contract CLI liest die YAML, verbindet sich mit deinem Datenprodukt auf Snowflake, Databricks, BigQuery, Postgres oder wo auch immer es liegt, und macht aus Schema, Quality-Regeln und SLAs SQL-Statements, die sie gegen die echten Daten ausführt.
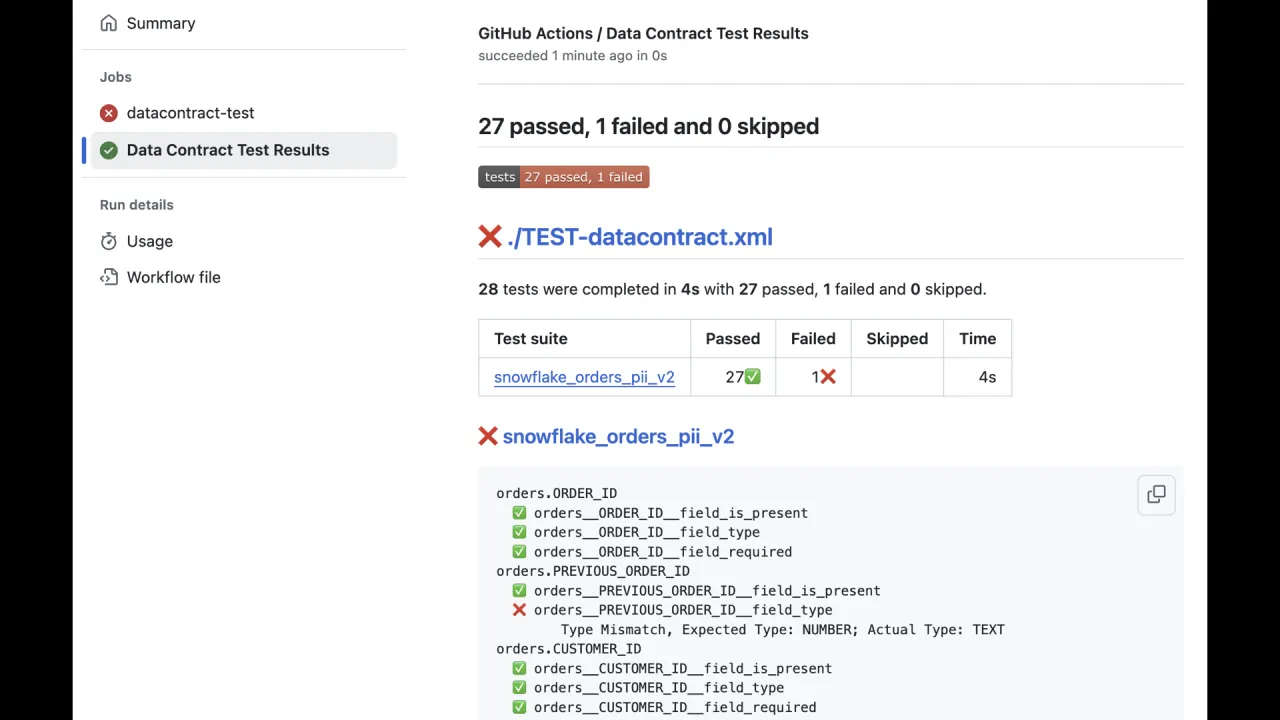
Führ datacontract test aus und du bekommst einen Exit-Code: null ist gut, ungleich null heißt, etwas ist kaputt. Häng es in eine Deployment-Pipeline, einen Airflow-DAG oder einen Databricks-Job, um bei jeder Änderung zu verifizieren, dass das laufende Produkt noch jede Garantie aus der YAML einhält.
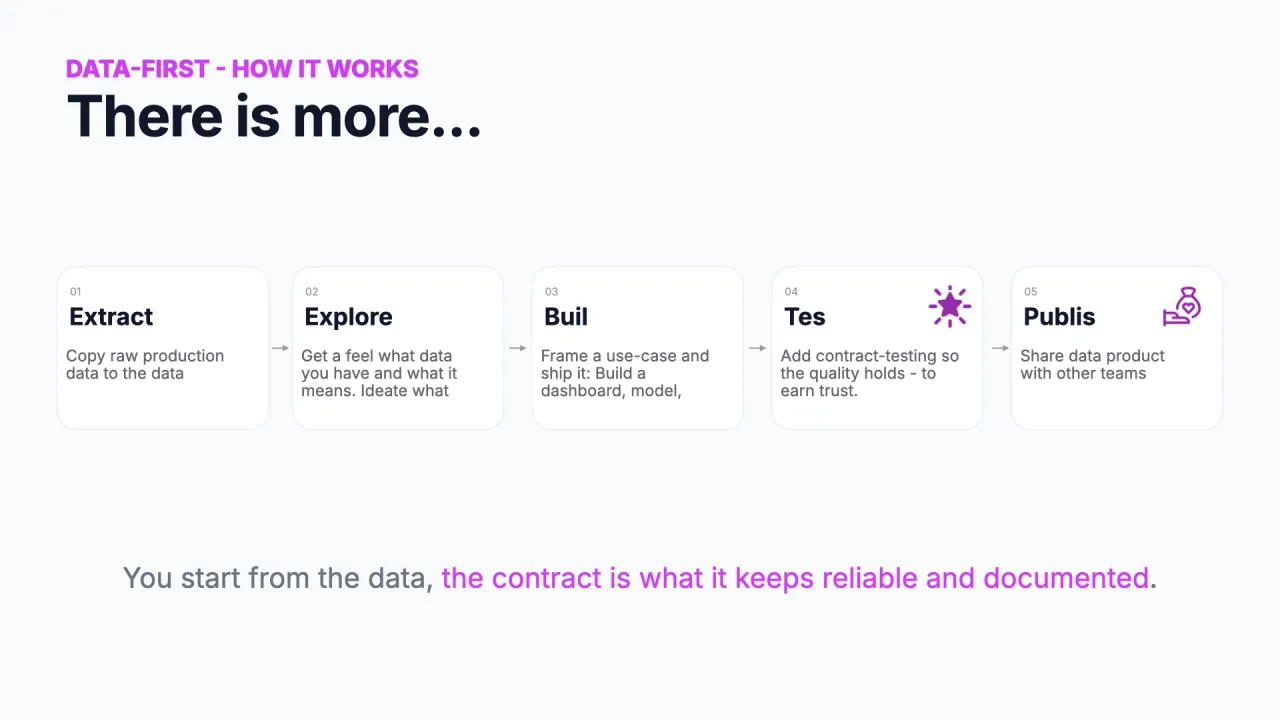
Im CI-Run auf der Folie bestehen 27 Checks und einer schlägt fehl, weil eine Spalte, die der Contract als Zahl erwartet, tatsächlich Text ist.

Es gibt mehr: veröffentliche es
Data Mesh geht es ums Teilen von Datenprodukten über Team-Grenzen hinweg, also bekommt der Weg einen fünften Schritt: Publish. Dieselbe YAML lässt sich in ein Metadaten-Tool, einen Katalog oder einen Marktplatz wie Entropy Data pushen und macht das Produkt auffindbar, lesbar und zugänglich, statt es nur als rohe YAML-Datei zu lassen.
Und weil es Metadaten auf einem offenen Standard sind, können auch Agenten sie lesen. Sie können den Marktplatz durchsuchen und dann im Chat oder autonom die Daten abfragen, während sie die im Contract definierten Terms of Use respektieren, den Zweck und die Limitationen, sodass der Zugriff sicher bleibt.

Drei von vier, gelöst
Die Daten unter Contract zu stellen löst drei der vier Probleme: Jetzt gibt es einen benannten Owner, ein vereinbartes Interface mit Dokumentation und ausführbare Quality-Tests.
Was es nicht löst, ist der große technische Datensatz. Data-first neigt dazu, einfach zu veröffentlichen, was aus dem Quellsystem kam, also bekommst du weiterhin breite Tabellen voller gleich aussehender Spalten, bei denen niemand weiß, welche das Business wirklich interessieren. Um das zu lösen, musst du ändern, wo du anfängst.


Beginne mit einem Gespräch
Contract-first startet nicht mit den Daten. Es startet mit einem Gespräch. Bevor du auch nur eine Spalte ansiehst, triffst du deine Data Consumers und verstehst, was sie wirklich tun wollen: ein KI-Modell, ein CFO-Dashboard, ein operativer Use Case. Dann spezifizierst du diese Anforderungen als Contract, baust das Produkt und testest es.
Den Contract vorab zu schreiben ist auch die beste Dokumentation, die du je bekommst, weil du noch die Energie dafür hast. Niemand schreibt gute Docs, nachdem das Produkt geshippt ist.
Die Vorteile summieren sich: Zusammenarbeit und Sympathie (du weißt, dass jemand das wirklich braucht), Business-Sprache (du nutzt die Begriffe der Consumer, nicht rohe Spaltennamen), echte Erwartungen (Quality-Regeln, die etwas bedeuten) und ein richtig dimensioniertes Datenprodukt mit nur den Feldern, die wirklich gebraucht werden, was genau das Problem der großen Datensätze löst.

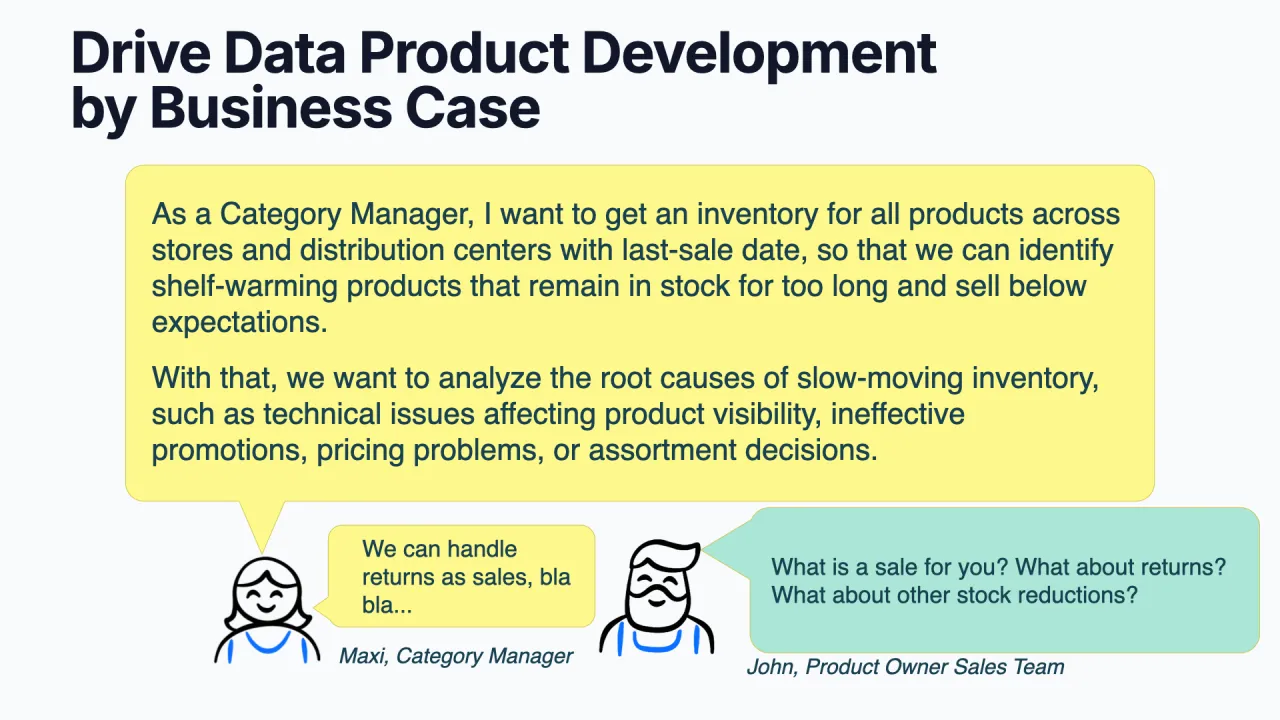
Treib es vom Business Case her
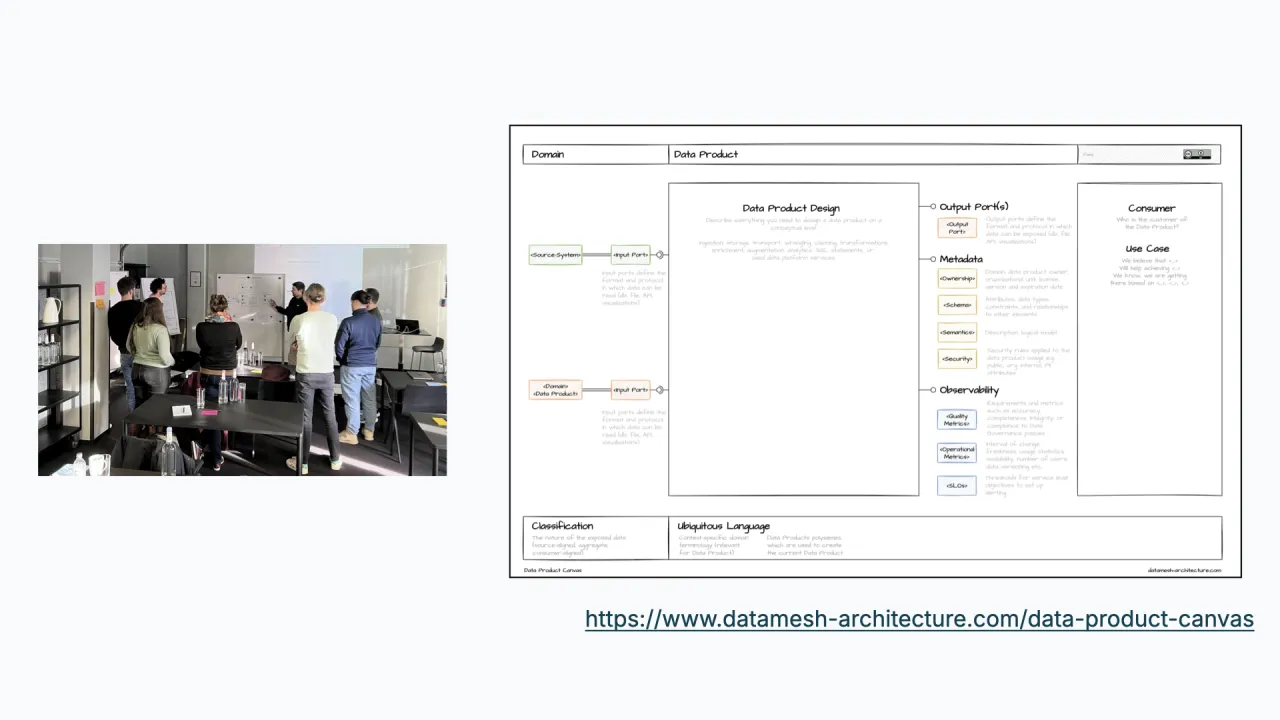
Du startest mit einem Workshop, idealerweise vor Ort, mit Stakeholdern und dem künftigen Data Product Owner. Ein Data Product Canvas strukturiert ihn: Du füllst ihn von rechts aus, beginnend mit dem Business Case, und lässt diesen das Interface und die Quellen treiben, die du brauchst.
Das laufende Beispiel: Maxi, eine Category Managerin bei einem E-Commerce-Unternehmen, will ein Inventar der Produkte, die sich in den letzten sechs Monaten nicht verkauft haben, die sogenannten Shelf Warmers, die im Lager liegen und Staub ansetzen. "Shelf Warmer" ist der Business-Begriff, und genau darum geht es.
John, der Product Owner im Sales-Team, hakt mit den Fragen nach, die den Contract schärfen: Was zählt als Verkauf? Zählen Retouren? Was ist mit Abschreibungen oder gestohlener Ware? Diese Antworten werden zur Semantik des Contracts.
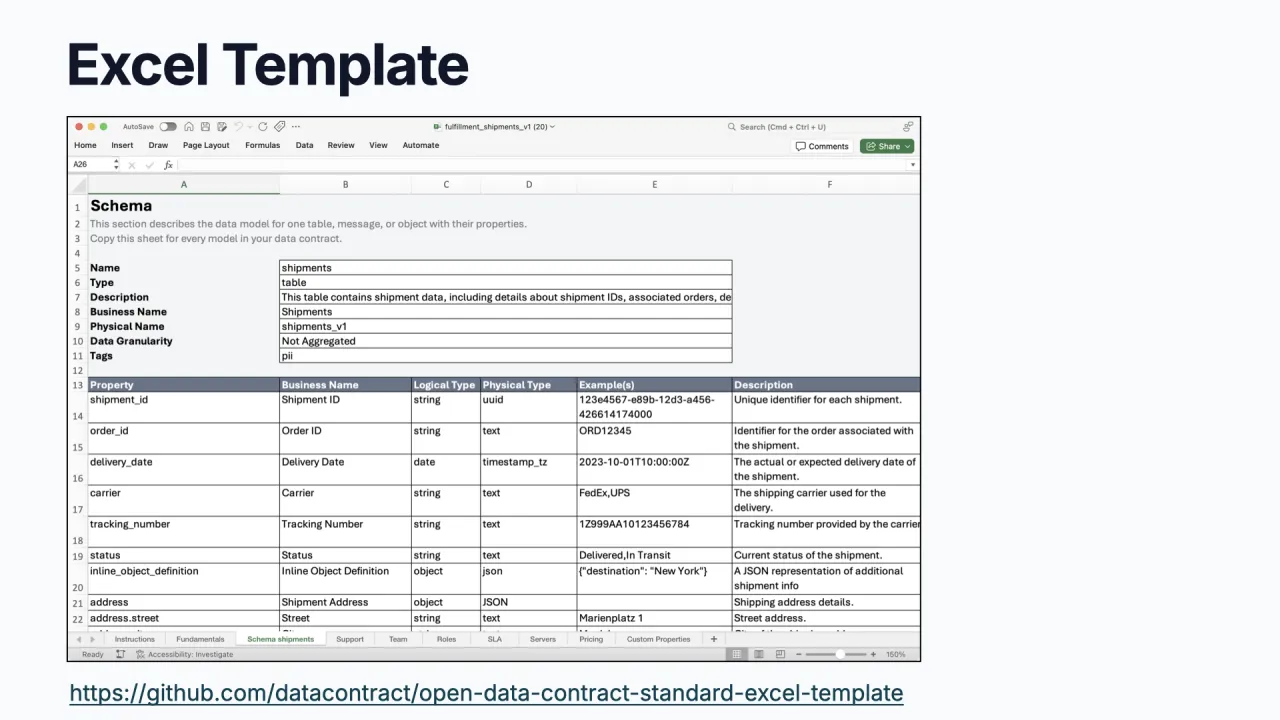
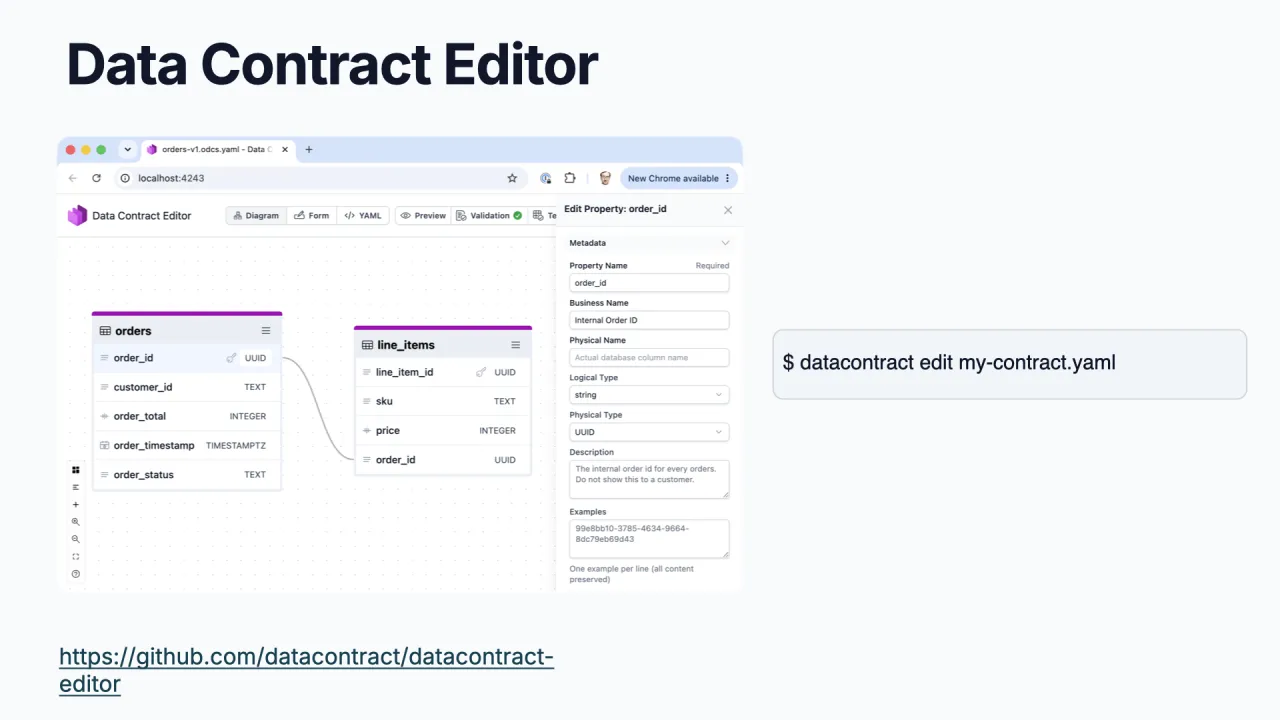
Erfasse es dort, wo Business kann
Rohes YAML ist für Business User nicht zugänglich. Nachdem drei Kunden unabhängig voneinander Contracts in Excel erfasst hatten, hat das Team ein offizielles ODCS-Excel-Template veröffentlicht, plus einen CLI-Konverter zwischen Excel und YAML in beide Richtungen. Product Owner füllen das Sheet aus, reichen es herum und konvertieren, wenn sie zufrieden sind.
Für Engineers macht der Open-Source Data Contract Editor aus einem Contract ein visuelles Erlebnis mit Diagramm- und Entity-Relationship-Ansichten. Er ist jetzt in die CLI eingebaut, also öffnet datacontract edit <name> den Editor direkt.
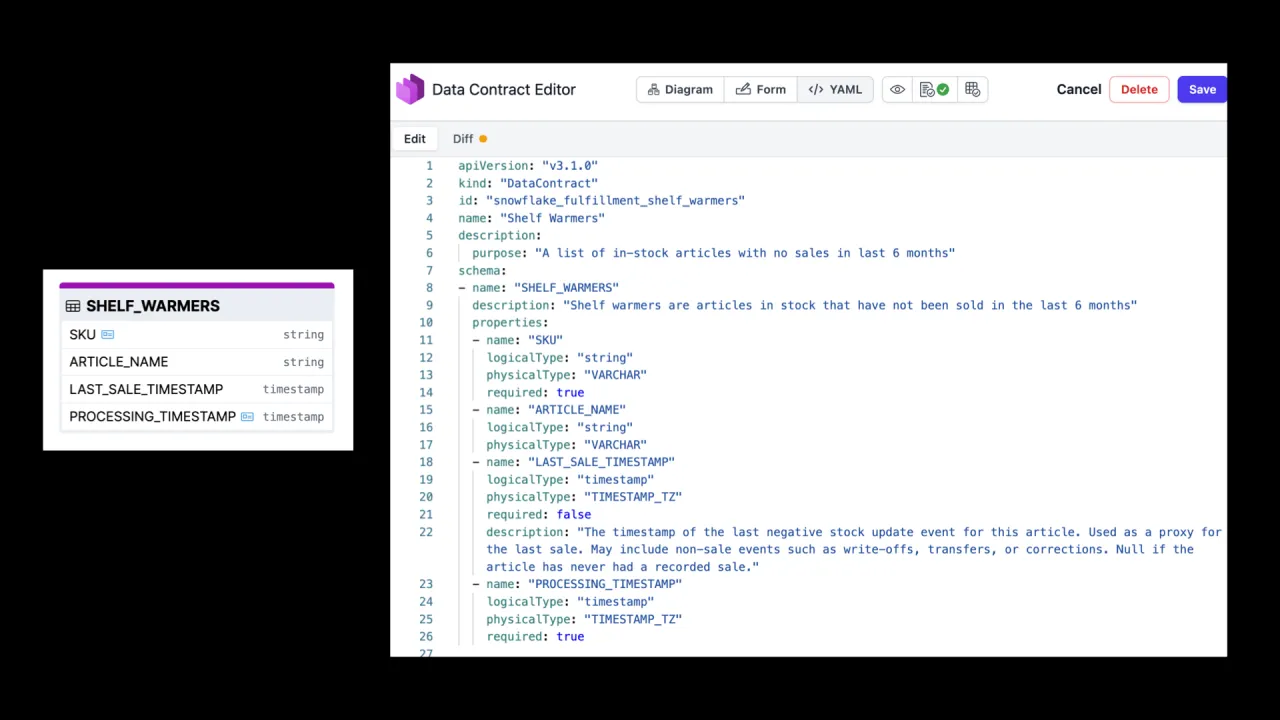
Ein richtig dimensionierter Contract
Die Anforderung ist, einmal verstanden, winzig. Maxi braucht nicht die volle Orders-Tabelle oder die volle Stock-Tabelle. Sie braucht eine Tabelle, shelf_warmers, mit vier Spalten: eine SKU (die Artikelnummer), einen Artikelnamen, einen Last-Sale-Timestamp und, nach Konvention der Organisation, einen Processing-Timestamp.
Die Arbeit, die hier zählt, ist die Semantik: auszubuchstabieren, was "Last Sale" wirklich bedeutet. Die Beschreibung notiert, dass es der Timestamp der letzten negativen Bestandsbewegung ist, Nicht-Verkaufs-Events wie Abschreibungen enthalten kann und null ist, wenn der Artikel nie einen erfassten Verkauf hatte. Dieser Satz ist der Unterschied zwischen einem nutzbaren Produkt und einem Ratespiel.

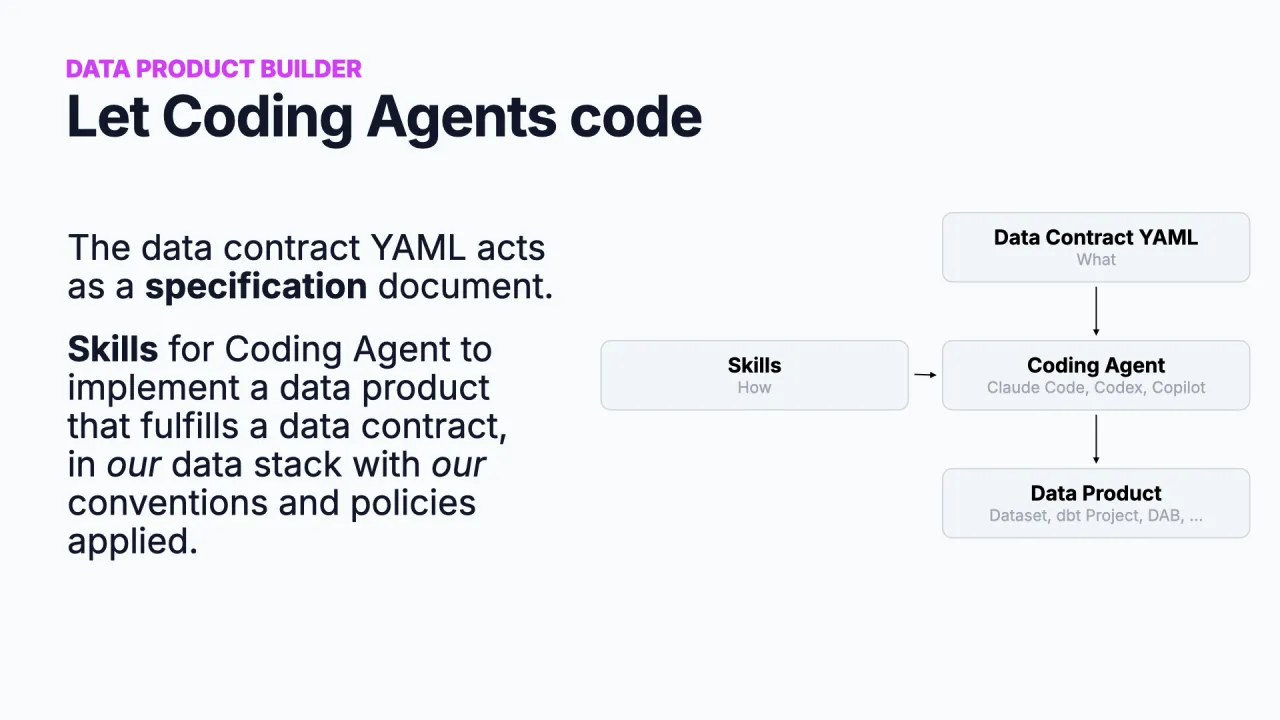
Bau es mit einem Coding-Agenten
Ist der Contract spezifiziert, baust du, und heute heißt das ein Coding-Agent (Claude Code, Codex, Copilot CLI). Der Agent braucht zwei Inputs. Der erste ist die Contract-YAML: was gebaut werden soll. Der zweite ist das Wie deine Organisation Datenprodukte baut, denn der Agent weiß nicht, ob du Snowflake, dbt oder deine eigenen Namenskonventionen nutzt.
Dieses "Wie" wird als Skills geliefert: Anweisungen für den Coding-Agenten, abgelegt in einem Git-Repository.

Skills: bring dem Agenten deinen Stack bei
Der Open-Source dbt Data Product Builder ist ein Template-Repository, das du klonst und an deine Konventionen anpasst. Jeder Skill ist nur ein Markdown-Dokument mit den Schritten, die zu befolgen sind: ein bootstrap-Skill für ein brandneues Produkt, ein implement-Skill für Änderungen, plus Skills für Metadaten und Testing.
Ein Skill kann zum Beispiel definieren, wie ein ODCS-Feld auf ein dbt-Modell abgebildet wird, oder ein Template dafür mitführen, wie ein dbt-Projekt in deiner Organisation aussieht, das der Agent dann respektiert. Du installierst ihn über den Plugin-Marktplatz deines Agenten und verbindest ihn mit deinen Metadaten und deinem dbt-Projekt.
"Testing ist günstig, also kannst du mehr und mehr Skills hinzufügen, und Skills können andere Skills referenzieren."
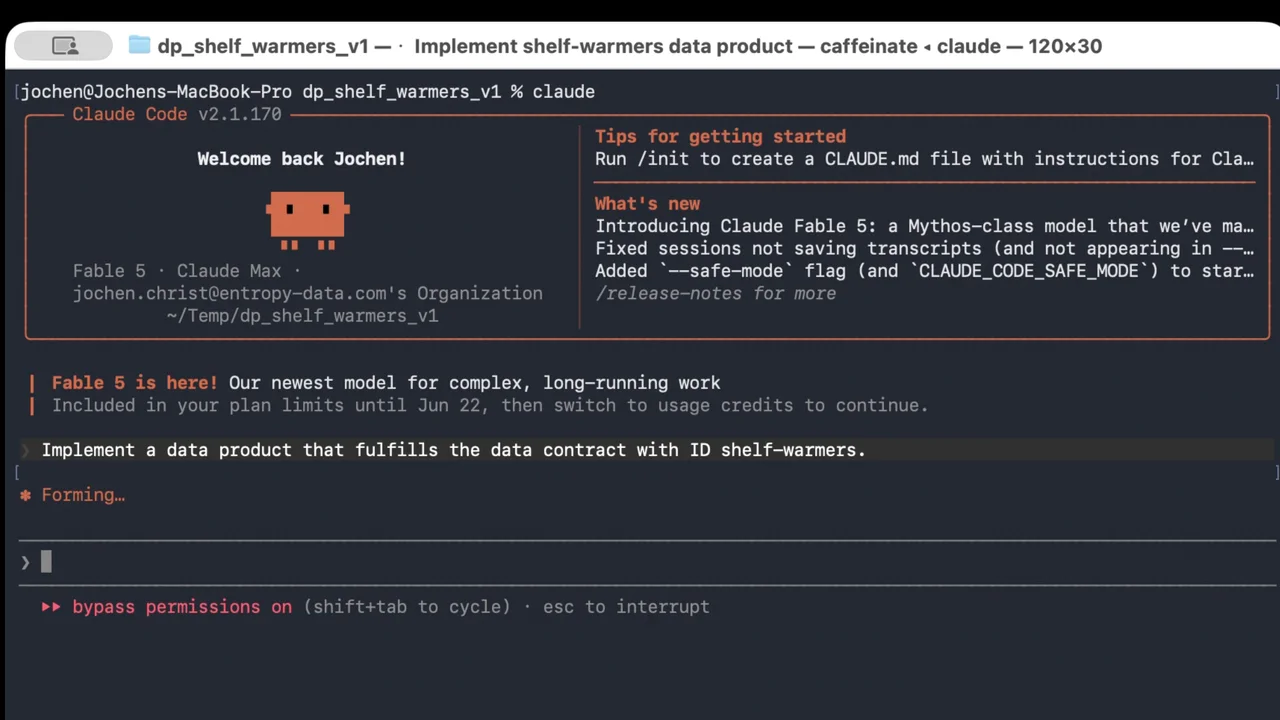
Der Build
Die ganze Anweisung ist eine Zeile: implementiere das Datenprodukt für den Contract. Der Agent liest den Contract, erkennt, dass dies ein neues Produkt ist, lädt den bootstrap-Skill mit seinem dbt-Template und legt im YOLO-Modus los, indem er die dbt-Modelle und die OpenLineage-Verdrahtung aufsetzt, die die Skills vorgeben. Im Talk als Bildschirmaufnahme gezeigt; der Live-Build dauert etwa elf Minuten.
Entscheidend: Er nutzt auch den Marktplatz, um seine vorgelagerten Quellen zu finden. Um den Contract zu erfüllen, sucht er nach Stock-Update-Events und Artikel-Stammdaten, findet diese vorhandenen Datenprodukte und fragt Zugriff an, als Teil des generierten Codes.
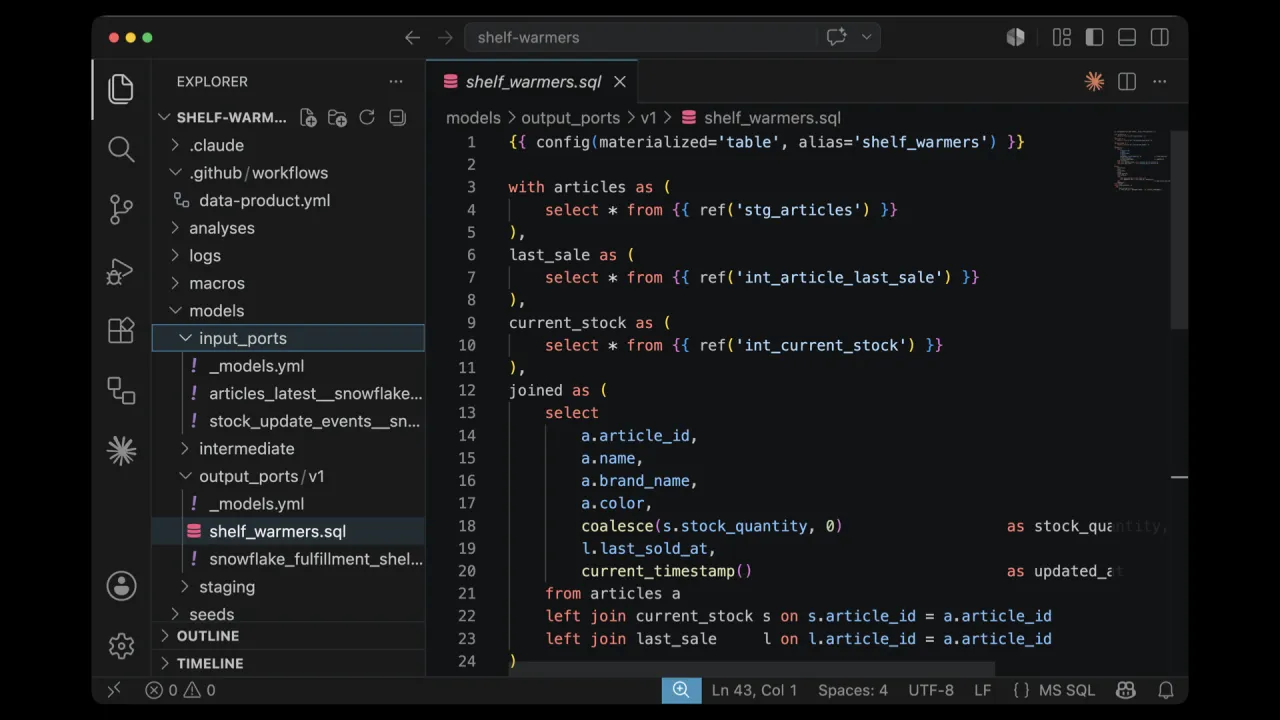
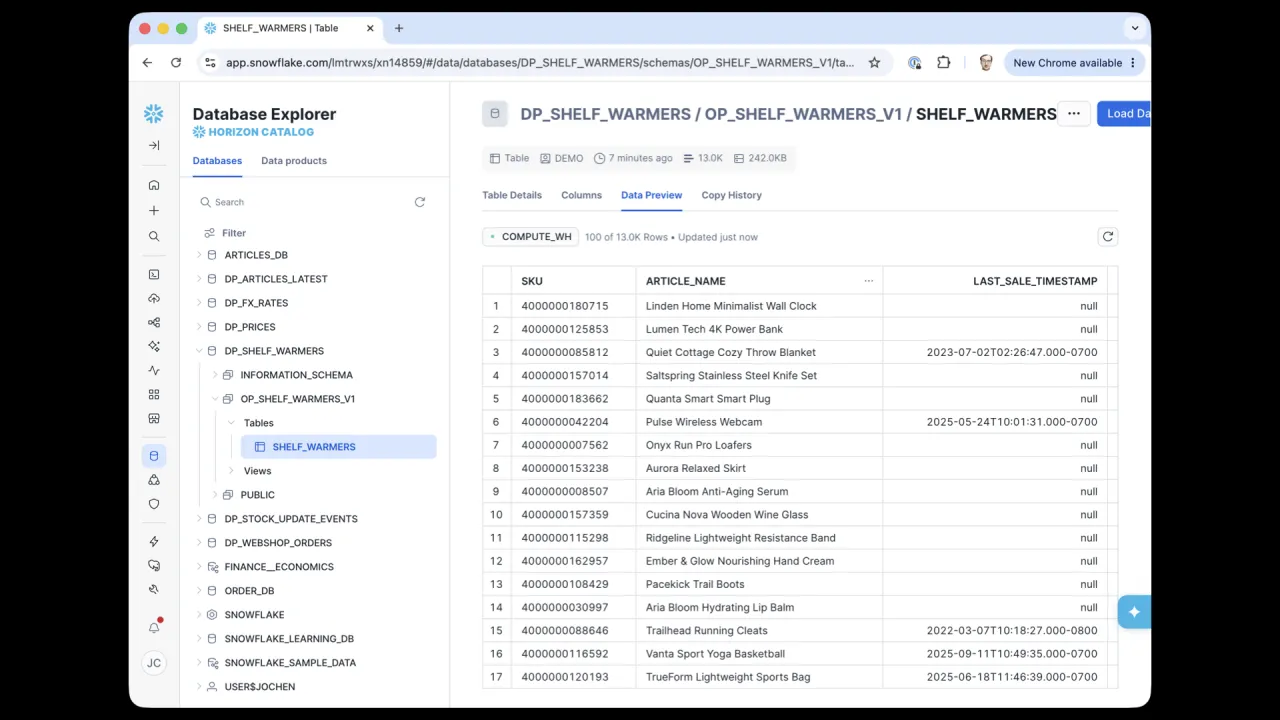
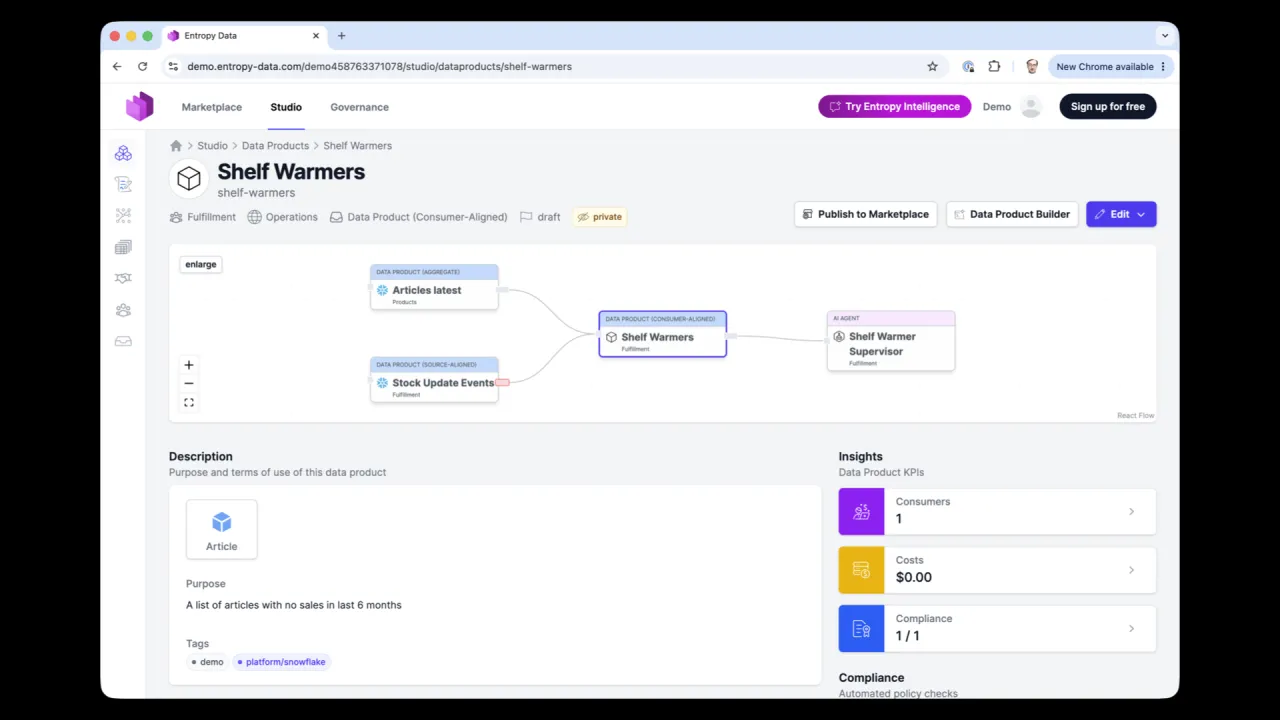
Das Ergebnis
Etwa elf Minuten später ist das Produkt gebaut: ein komplettes dbt-Projekt mit Input und Output Ports, die SHELF_WARMERS-Tabelle gefüllt in Snowflake und das Datenprodukt im Private-Modus in den Marktplatz veröffentlicht, bereit für seinen Owner, es öffentlich zu machen.
Die Contract-Tests, ebenfalls Teil der Skills, laufen als Schritt in CI oder deiner Datenpipeline. Ist der Contract grün, shippst du. Die Implementierung übernimmt ein Coding-Agent, aber die Anforderungen, die Semantik und die Garantien sind alle deine.

Shippe, wenn die Tests grün sind
Contract-first läuft Understand, Specify, Build, Test. Du investierst die Zeit vorab, um die Anforderungen zu verstehen und als Contract zu spezifizieren, der Coding-Agent implementiert ihn, die Contract-Tests laufen in deiner Pipeline, und wenn sie grün sind, shippst du.

Es gibt keinen falschen Weg
Beide Wege erreichen dasselbe Ziel: ein Produkt in Produktion, das Wert liefert. Was ist also die Antwort? Drei Takeaways:
- Ein Contract ist, was Daten vertrauenswürdig macht. Er erfasst Anforderungen und Semantik und automatisiert Testing, sodass etwas, das die Erwartungen eines Consumers brechen würde, rot wird und du benachrichtigt wirst.
- Sprich mit deinen Data Stakeholdern. Es gibt keine Abkürzung. Wenn du den Business-Wert eines Datenprodukts nicht verstehst, lohnt es sich wahrscheinlich nicht, es zu bauen. Nimm Product Ownership ernst.
- Coding-Agenten implementieren, was du spezifizierst. Je besser deine Spezifikation und deine Beschreibungen, desto besser baut der Agent, und desto besser kann er kennzeichnen, was fehlt oder schief ist.
"Data Contracts sind, was den Unterschied machen. Sie sind, was dein Datenprodukt vertrauenswürdig macht."
Q&A
Ausgewählte Fragen aus dem Publikum nach dem Talk.
F: Wenn der Agent die dbt-Modelle generiert, wer pflegt sie danach? Editiere ich den dbt-Code, oder gehe ich zurück zum Contract und generiere neu?
Das hängt von deiner Kultur und der Reife deiner Engineering-Organisation ab, aber persönlich würde ich nicht mehr zu viel in den dbt-Code schauen. Ich würde die Anforderungen im Contract ändern, und wenn das Ergebnis nicht stimmt, die Skills verbessern. Bau eine Feedback-Schleife in dein Skill-Repository ein und optimiere von dort, statt generierten Code von Hand zu patchen.
F: Unterscheidet ihr einen Marktplatz von einem Datenkatalog, oder behandelt ihr sie als dasselbe?
Wir unterscheiden sie. Ein Katalog ist ein technischer Index jedes existierenden Datensatzes, oft Millionen von Assets. Ein Marktplatz enthält nur Datenprodukte, die zum Teilen und Konsumieren durch andere Teams gedacht sind, meist ein paar Hundert. Der Marktplatz ist, wo die kontextuelle Information auf Contract-Ebene lebt.
F: Data-first fördert oft Erkenntnisse zutage, nach denen niemand gefragt hat. Heißt immer Contract-first nicht, dass du nur beantwortest, was Leute schon zu fragen wissen?
Ein fairer Punkt, und du willst explorative Fähigkeiten behalten. Der Schlüssel ist die Grenze: innerhalb deiner eigenen Domäne, wo du schon verstehst, was die Daten bedeuten, behalte einfachen explorativen, data-first Zugriff. Data Contracts zählen, wenn du eine Organisationsgrenze überschreitest, denn dort beginnt ein neuer Bounded Context, und geteilte Daten brauchen ein vereinbartes, dokumentiertes Interface.
F: Sollte der Contract das physische Schema vorab spezifizieren, oder nur Zweck und konzeptionelles Modell, und den Agenten das physische Schema herausfinden lassen?
Im Contract würde ich das konzeptionelle und logische Modell definieren und die physische, technische Implementierung dem Skill oder der Ziel-Datenplattform überlassen. Das Business-Wissen geht ins Modell; das plattformspezifische Detail geht in die Skills.
F: Wir sehen Data Contracts an den Rändern des Datenflusses, an den Quellen und vor dem Konsum. Siehst du sie auch in der Mitte, auf jedem Schritt der Lineage?
Meine Sicht ist, dass ein Data Contract eine neue Vertrauensgrenze bildet. Du brauchst wahrscheinlich keinen Contract auf jedem Sprung zurück bis zur allerersten Quelle; du brauchst Lineage zurück bis zum letzten Data Contract, auf den du dich verlässt. Zwischen Contracts kannst du technische Lineage nutzen, also die interne Verdrahtung der Pipeline eines Datenprodukts. Vertrauen wird am Quell-Contract verankert.