Talk
Open Standards for Data Mesh
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · 21. April 2026
In diesem Vortrag beim Data Mesh Belgium Meetup #7 in Leuven gehe ich die drei offenen Standards durch, die prägen, wie wir Data Mesh heute bauen: den Open Data Contract Standard (ODCS), den Open Data Product Standard (ODPS) und das Open Semantic Interchange (OSI). Ich zeige, wie sie zusammenpassen, wohin sich das Tooling entwickelt und warum ein Standard in vier Jahren überall sein wird.

Live aufgezeichnet beim Data Mesh Belgium Meetup #7 in Leuven. Das Transkript unten ist eine bearbeitete Fassung des Vortrags.
Danke an Tom De Wolf (ACA) und Emma Houben (AE) für die Einladung und das Hosten des Meetups, und an die BITOL-Community für die offenen Standards, die wir gemeinsam bauen.

Einleitung
Danke für die Einladung, Tom -- ich bin zum ersten Mal in Leuven, und bisher ist es großartig. Ich heiße Simon und bin im Herzen Software-Engineer. Ich habe sieben Jahre bei einer Beratung gearbeitet und bin seit August 2025 Co-Founder und CEO von Entropy Data, wo wir einen Datenmarktplatz für Datenprodukte bauen. Wir haben Kunden in sieben Ländern weltweit -- darunter die USA, Australien und Belgien.
Nebenbei habe ich seinerzeit, in meinen Java-Tagen, "Java by Comparison" mitgeschrieben (Claude programmiert jetzt für mich), und ich habe das "Data Mesh"-Buch ins Deutsche mitübersetzt -- das Coole ist, dass die Bilder in der deutschen Ausgabe tatsächlich in Farbe gedruckt sind. Ich schreibe mit an datamesh-architecture.com und datacontract.com, betreue die Open-Source-Projekte Data Contract CLI und Data Contract Editor mit und sitze im TSC des BITOL-Projekts der Linux Foundation, das offene Standards für Data Contracts und Datenprodukte vorantreibt. Tatsächlich haben wir unser TSC-Meeting heute früher in Toms Büro abgehalten -- ein schöner Weg, den Abend persönlich zu beginnen.
Ein kurzes Data-Mesh-Recap
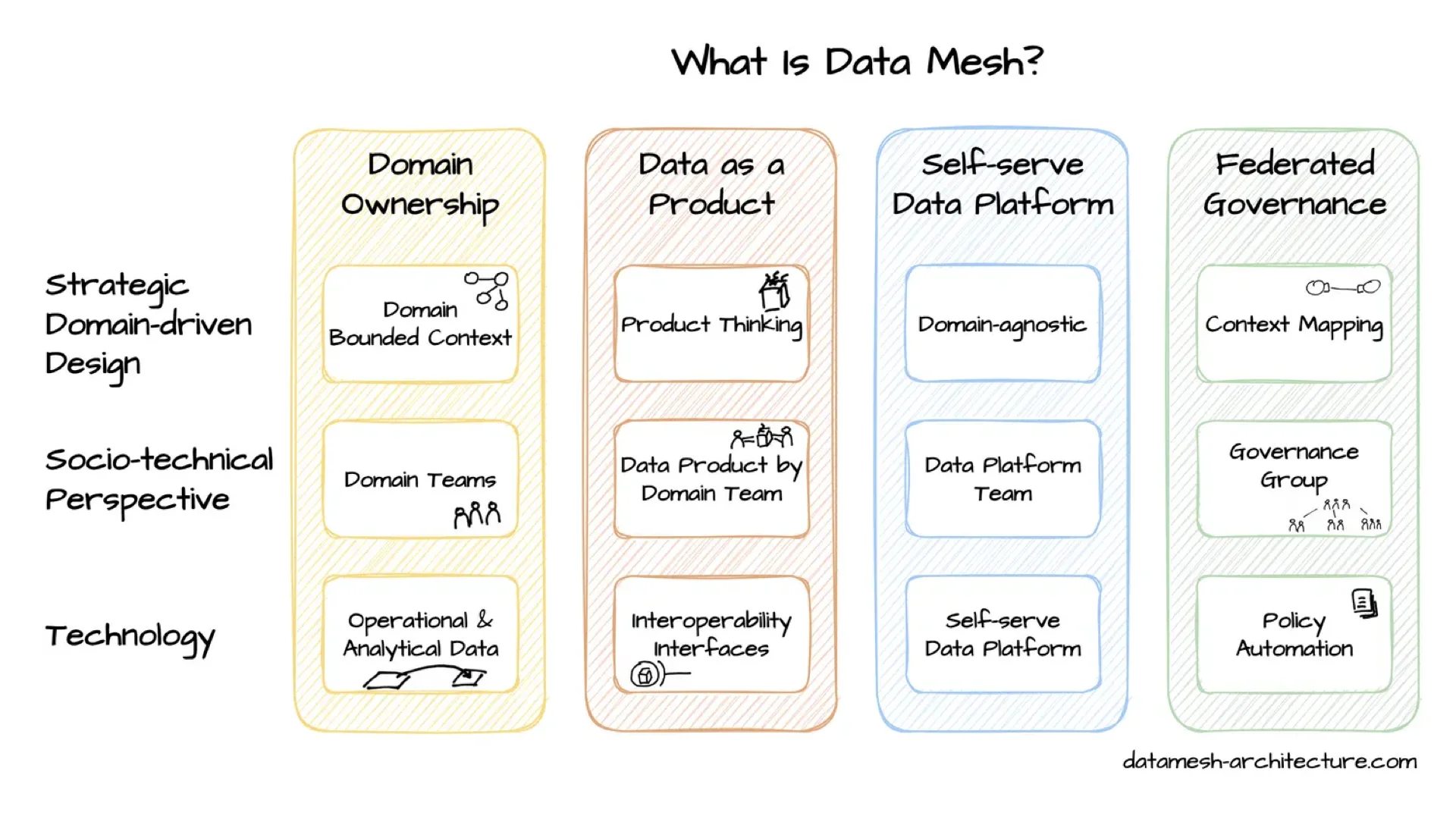
Das ist ein Data-Mesh-Meetup, also weißt du das wahrscheinlich schon -- nur ein sehr kurzes Recap, damit wir auf demselben Stand sind. Data Mesh, geprägt von Zhamak Dehghani, beruht auf vier Prinzipien: Domain Ownership, Data as a Product, Self-Serve Data Platform und Federated Governance.
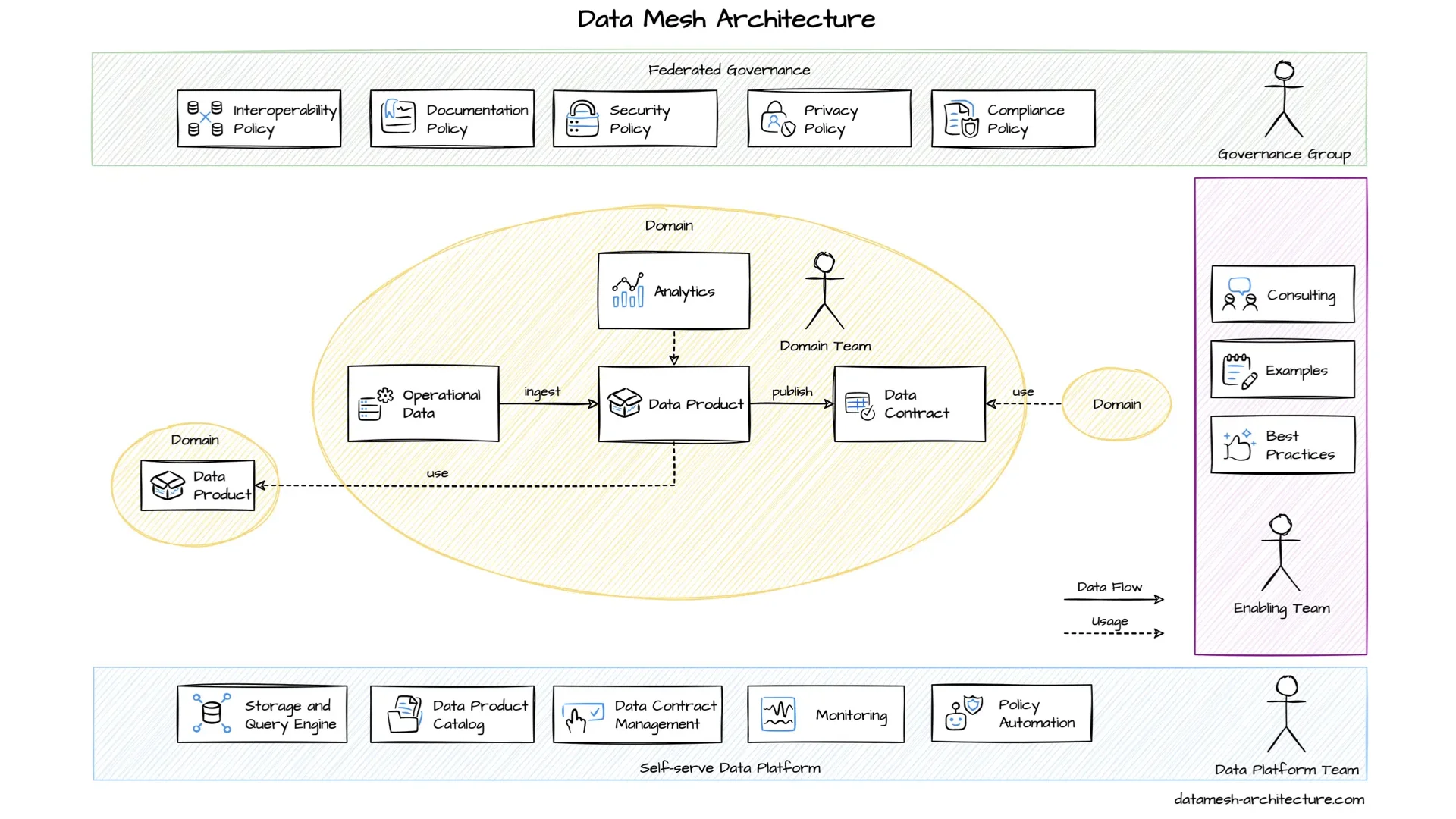
Die typische Architektur hat die Self-Serve-Plattform unten, Federated Governance oben und ein Enabling Team an der Seite, das anderen hilft. In der Mitte sind die Domänen mit ihren Domain Teams, die Datenprodukte für andere bauen.
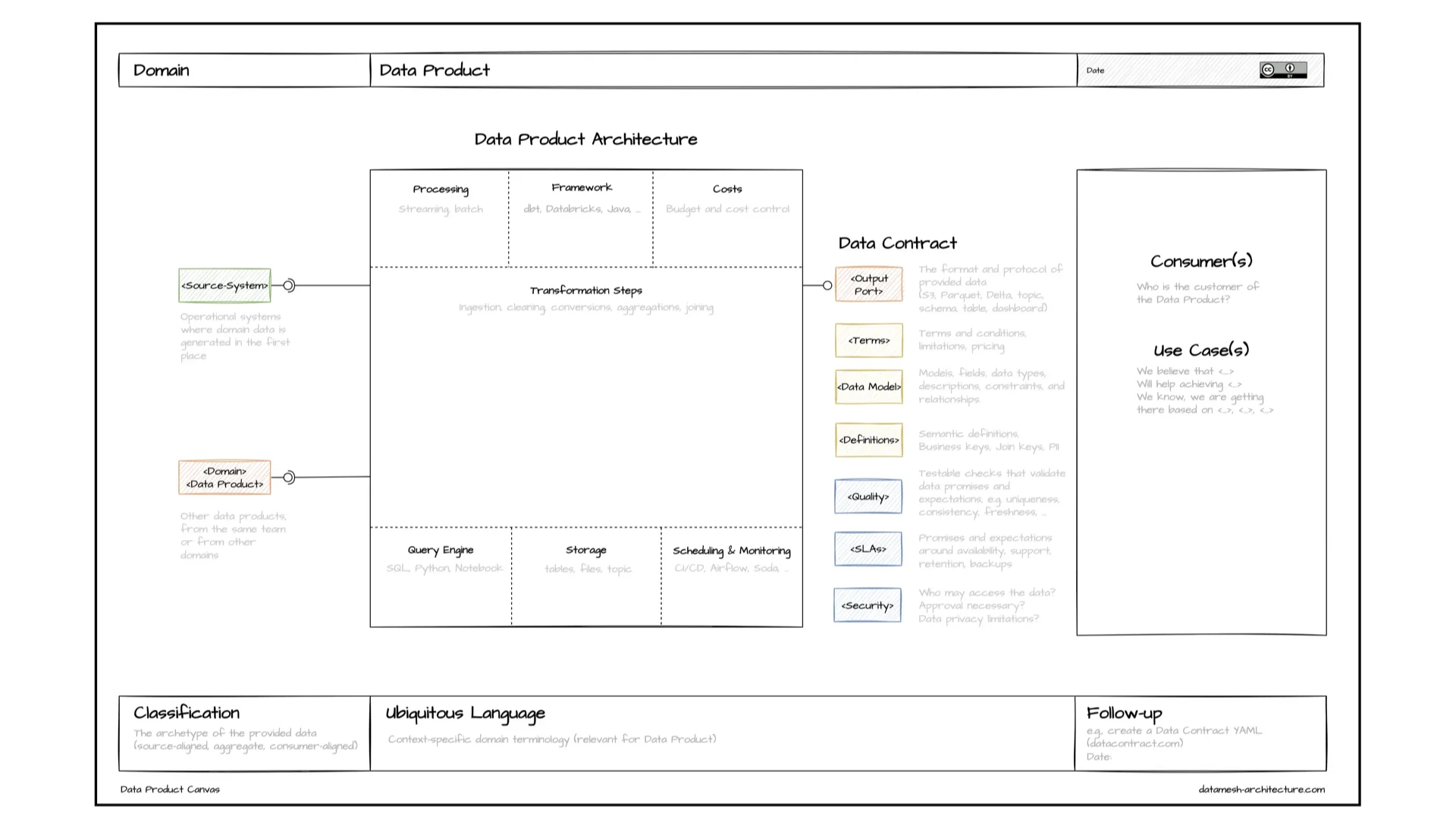
Wenn ein Team ein Datenprodukt baut, nutzen wir oft das Data Product Canvas -- Open Source, entstanden in meiner Beratungszeit als Miro-Template. Input Ports kommen von Quellsystemen oder anderen Datenprodukten. Output Ports bieten Daten über einen Data Contract für Consumers mit Use Cases an. In der Mitte sitzt die Implementierung: Processing, Framework, Query Engine, Storage, Scheduling, Kosten. Zusammen bilden viele davon den größeren Mesh-Graphen.


Was ist ein Standard? Und warum brauchen wir sie?
Statt ins Oxford-Wörterbuch schaue ich gerne in XKCD. Unterschiedliche Arten, ein Datum zu schreiben, führten zum ISO-8601-Standard: alle profitieren, wenn sie ihn nutzen (außer, wie XKCD anmerkt, die USA). Unterschiedliche Arten zu zählen -- "eins, zwei, drei, los" versus "drei, zwei, eins, los" -- erzeugen dieselbe Verwirrung und dieselben Kosten, weshalb Standards Kosten senken. Und natürlich gibt es den klassischen XKCD "How Standards Proliferate": du hast vierzehn Standards, du erstellst einen neuen universellen, der alles abdeckt, und jetzt hast du fünfzehn. Das ist das Standards-Problem an sich.
Lass mich klären, worüber ich heute spreche. Die Standards, die mir wichtig sind, sind:
- De Facto, nicht De Jure -- getrieben von tatsächlicher Nutzung in einer kritischen Masse von Unternehmen, nicht per Gesetz.
- Initiative, nicht Vendor -- im Besitz einer offenen Initiative, nicht von einem einzelnen Unternehmen kontrolliert. Wenn ein Vendor ihn diktiert, ist es kein Standard.
- Viele Contributors, nicht einer -- es geht darum, dass Macht und Kontrolle verteilt sind.
- Offen, nicht hinter einer Paywall -- frei nutzbar. (Wir sind ISO 27001 zertifiziert, und 130 Schweizer Franken für ein 10-seitiges PDF zu zahlen ist genau die Art von Reibung, die offene Standards vermeiden.)
Standardisierung könnte fast überall in einem Data Mesh stattfinden: Monitoring, Kataloge, Query, Storage, Policies, Analytics, Beziehungen. Ich konzentriere mich auf drei, die gerade am meisten zählen.
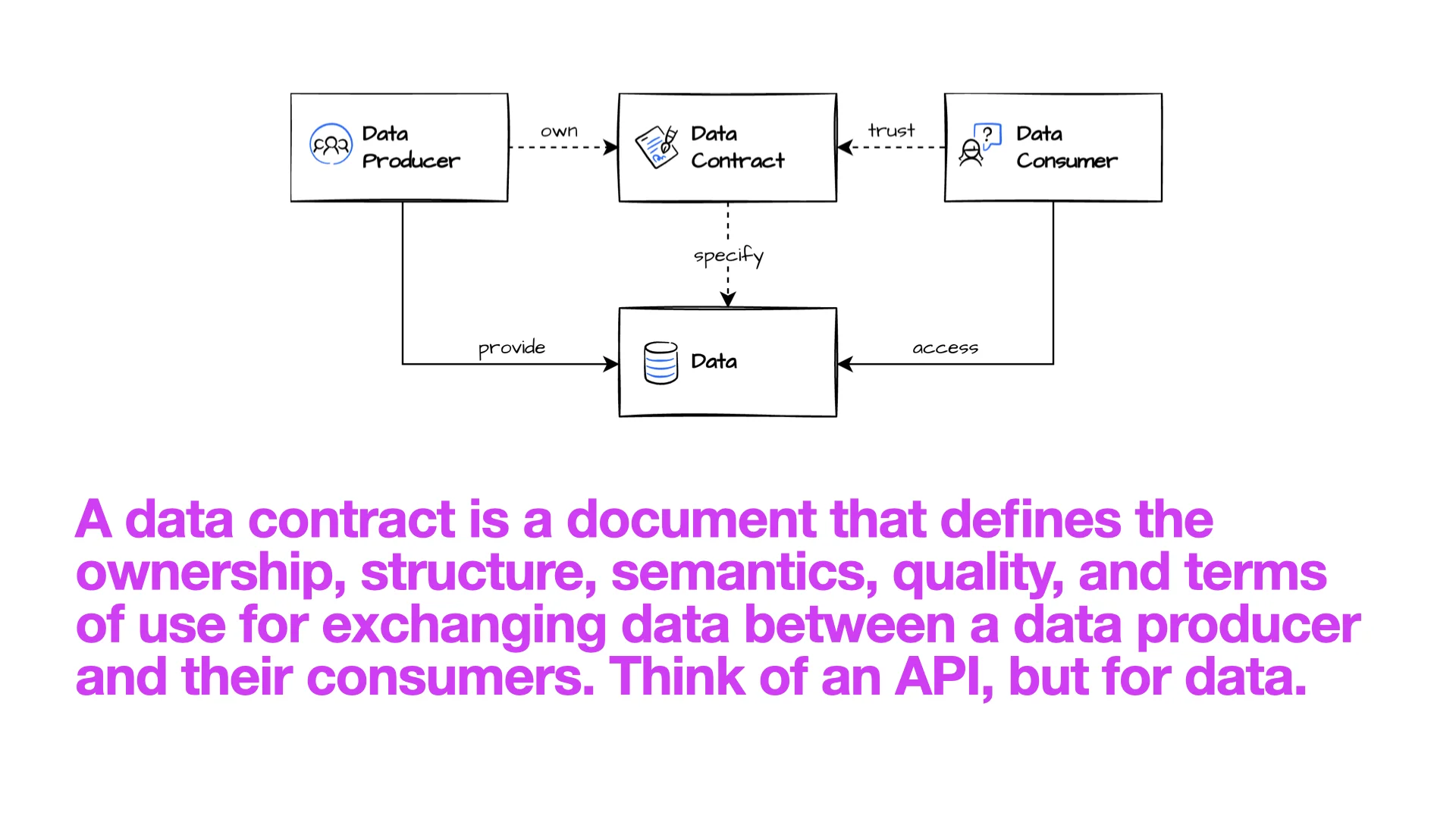
Was ist ein Data Contract?
Ein Data Contract ist ein Dokument, das Ownership, Struktur, Semantik, Qualität und Nutzungsbedingungen für den Datenaustausch zwischen einem Producer und seinen Consumers definiert. Stell dir eine API vor, aber für Daten.
Der Contract ist das, was Vertrauen schafft. Der Producer besitzt ihn; der Consumer liest ihn und vertraut ihm; gemeinsam einigen sie sich auf die Daten, die zwischen ihnen fließen werden.
"Der Contract ist per Definition korrekt. Wenn Daten und Contract sich widersprechen, sind die Daten falsch. So stark ist der Trust Layer -- konzeptionell."
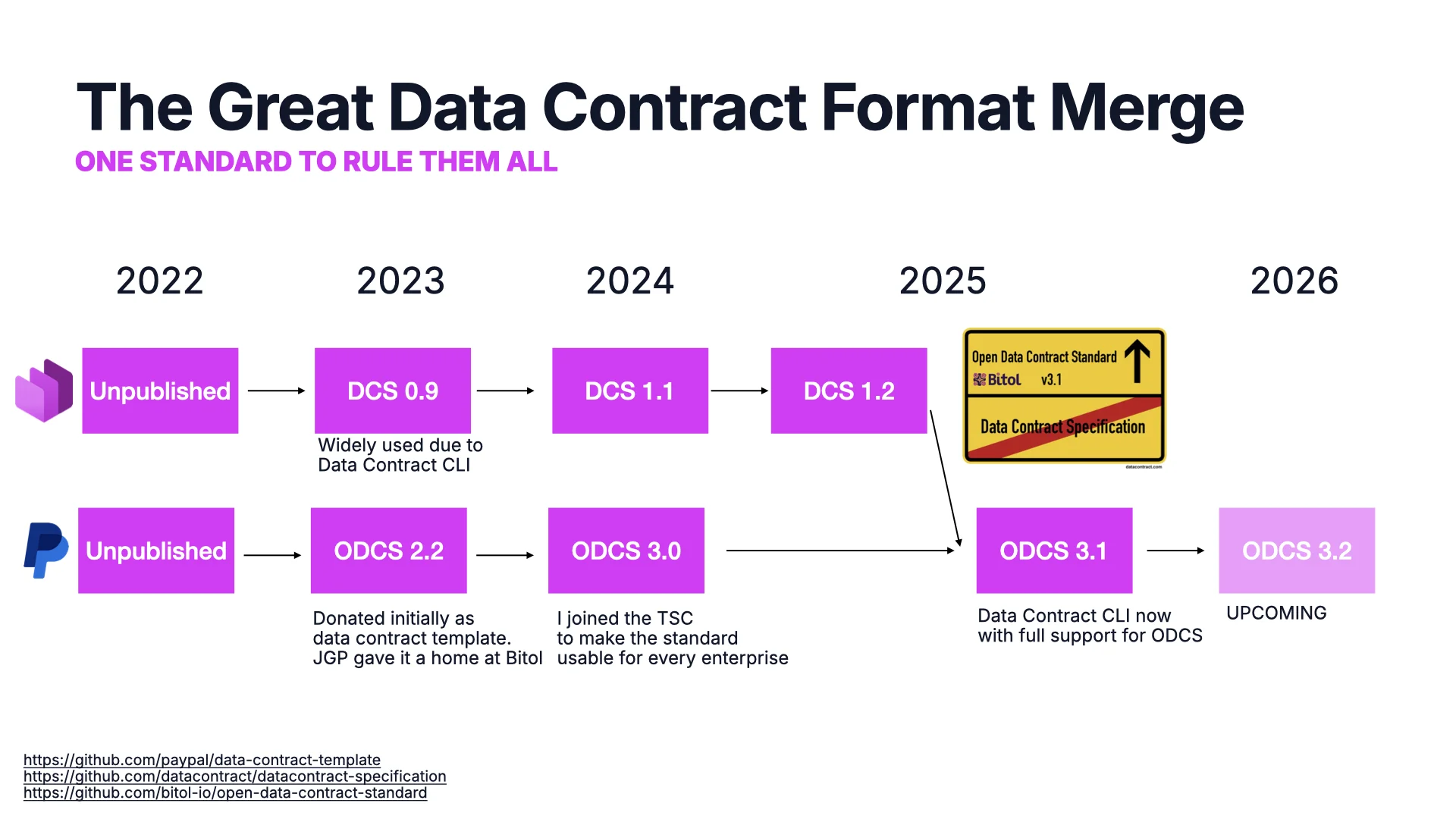
Der große Data-Contract-Format-Merge
Weil dieser Bedarf mit dem Aufstieg von Data Mesh und dezentralen Daten entstand, erfand jedes Unternehmen zunächst sein eigenes Format. PayPal erstellte sein internes Template, machte es Open Source und spendete es als ODCS 2.2 an die Linux Foundation. Parallel dazu bauten wir etwa zur selben Zeit unsere eigene Data Contract Specification (DCS), und sie wurde dank des Data Contract CLI-Toolings drumherum weit verbreitet.
Ich mag offene Sachen, also bin ich dem TSC beigetreten, und wir haben ODCS 3.0 veröffentlicht, die PayPal-Spezifika herausgenommen und es für jedes Unternehmen nutzbar gemacht -- es gibt nur ein PayPal. Letztes Jahr haben wir unsere eigene Data Contract Specification zugunsten von ODCS abgekündigt und all unsere Ressourcen dorthin verlagert. Kontrolle zählt: nur eines von vielen Mitgliedern in einem Komitee mit guter Parität zwischen Endnutzern, Beratern und Vendors zu sein, ist eine viel gesündere Balance als ein Single-Vendor-Projekt, so offen es auch sein mag. ODCS 3.2 steht bevor; wir haben gerade beim heutigen TSC-Meeting ein paar neue Ergänzungen beschlossen.
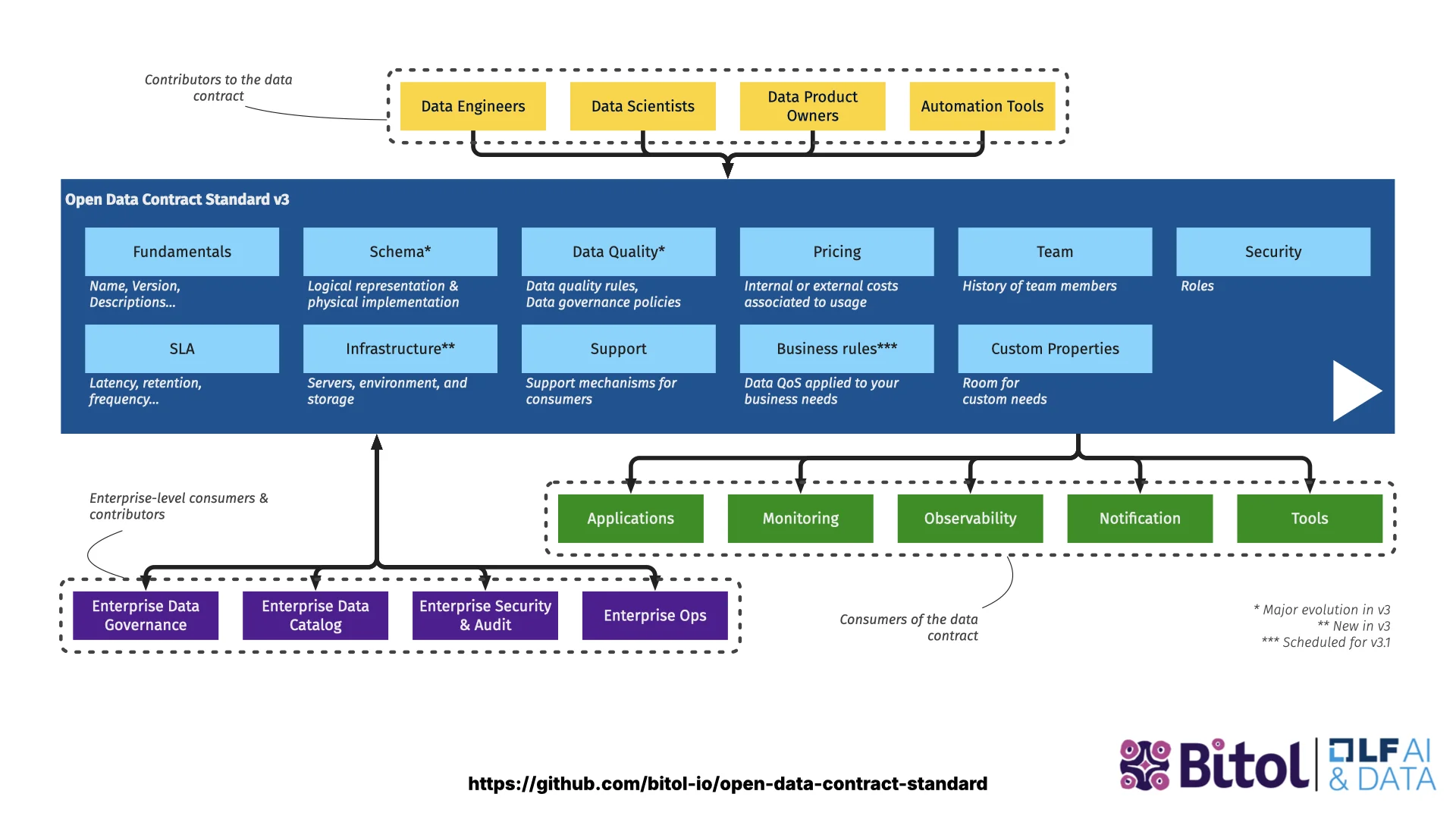
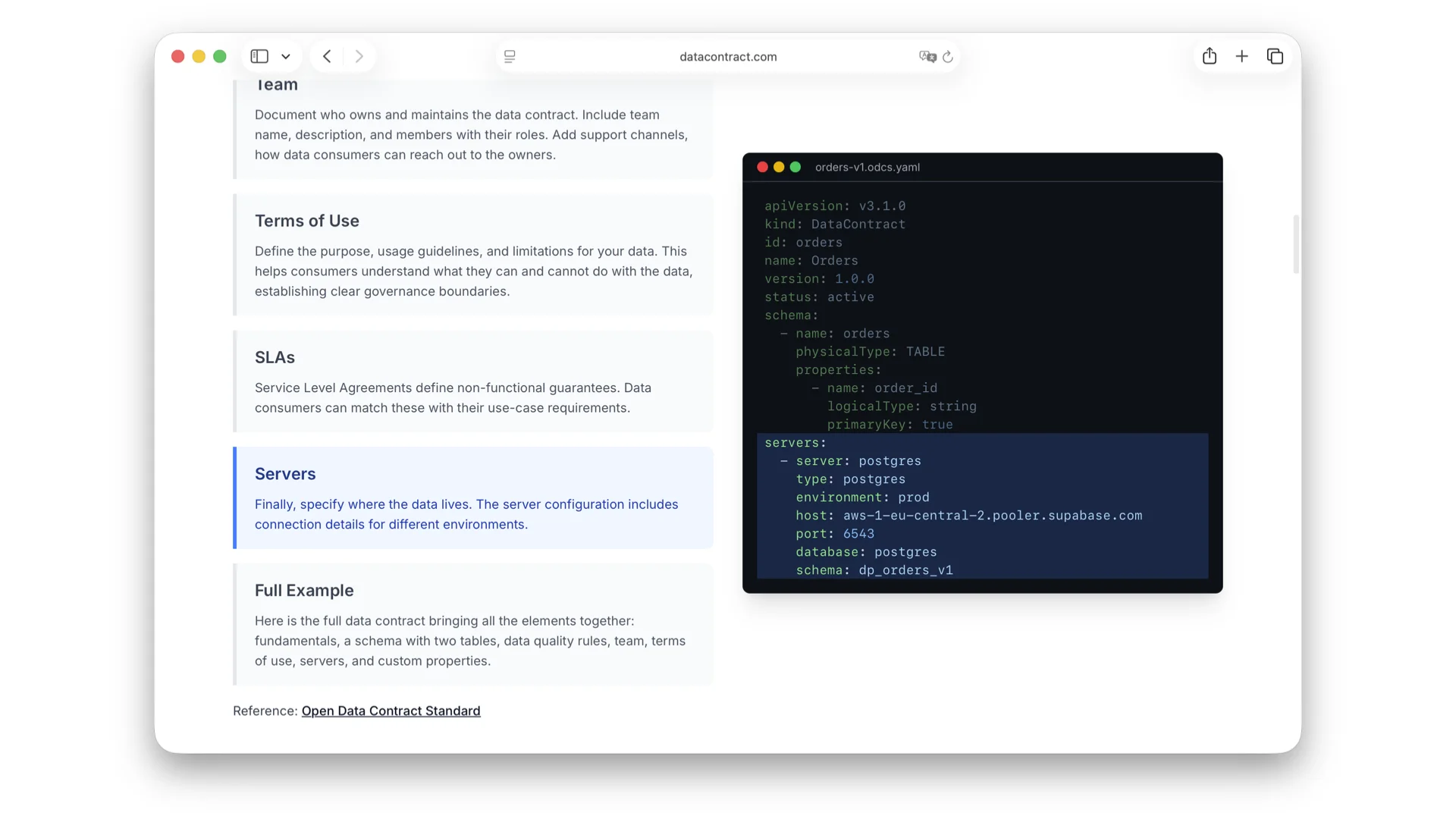
Was steckt in einem ODCS-Contract
ODCS hat viele Bausteine, mit denen ein Producer sein Angebot beschreiben kann. Eine YAML-Datei erfasst:
- Fundamentals -- ID, Name, Version, Status, um Angebote ein- oder auszuphasen.
- Schema -- Tabellen und Spalten mit Typen, Primary und Foreign Keys, Business-Namen, Klassifizierungen, PII-Tags. Selbst wenn deine Daten als JSON auf S3 oder CSV auf SFTP liegen, kannst du die Beziehungen trotzdem deklarieren -- technisch sind sie da.
- Data Quality -- Enums wie order_status ∈ {pending, shipped, cancelled}, oder beliebige SQL-Checks wie "Zeilenanzahl muss größer als 100.000 sein".
- Team & Support -- wie man die Owners erreicht, Slack-Channels, Ticketsysteme.
- Nutzungsbedingungen -- was Consumers mit den Daten tun dürfen und was nicht.
- SLAs -- Freshness, Retention, Verfügbarkeit -- von Tools trackbar.
- Servers -- wo die Daten tatsächlich liegen, damit Consumers mit Zugriff direkt dorthin gehen können.
Der Standard definiert die YAML-Struktur und was du ausdrücken kannst. Alles Nachgelagerte baut darauf auf.

Automatisiere alles
Sobald du das YAML hast, kannst du automatisieren: den Contract gegen echte Daten vergleichen, Breaking Changes in einem PR erkennen, kontinuierlich die Produktion überwachen, Java, Pydantic, dbt-Modelle, SQL DDL generieren und Metadaten in Metastores, Datenkataloge wie Collibra, Datenmarktplätze wie Entropy Data und Software-Kataloge wie LeanIX pushen. Die Data Contract CLI macht all das -- verbinde dich mit Snowflake, Databricks, BigQuery, was auch immer -- und erzeugt einen Report darüber, wie gut die Daten zu den Garantien passen. Unter der Haube nutzen wir Soda Core für die Quality-Ausführung -- ebenfalls ein Open-Source-Projekt eines belgischen Unternehmens, was hier in Leuven passend wirkt.
Und wenn du dir die GitHub-Star-History anschaust, ist die Data Contract CLI populärer als die ODCS-Spec selbst. Das ist die Lehre: Tooling zählt mehr als der Standard. Der Standard existiert, weil er dir das Tooling kostenlos liefert, weil er Vendor-Lock-in vermeiden lässt, wenn mehrere Vendors dasselbe Format unterstützen, und weil er bedeutet, dass wir einander helfen, statt dasselbe zehnmal neu zu erfinden.
Ein Contract sind auch die besten Metadaten, die du einer KI geben kannst. Wenn du KI mit dieser Art strukturierter Metadaten kombinierst -- besonders mit modernen Modellen der Opus-Klasse -- sind die Grenzen weit gesteckt.
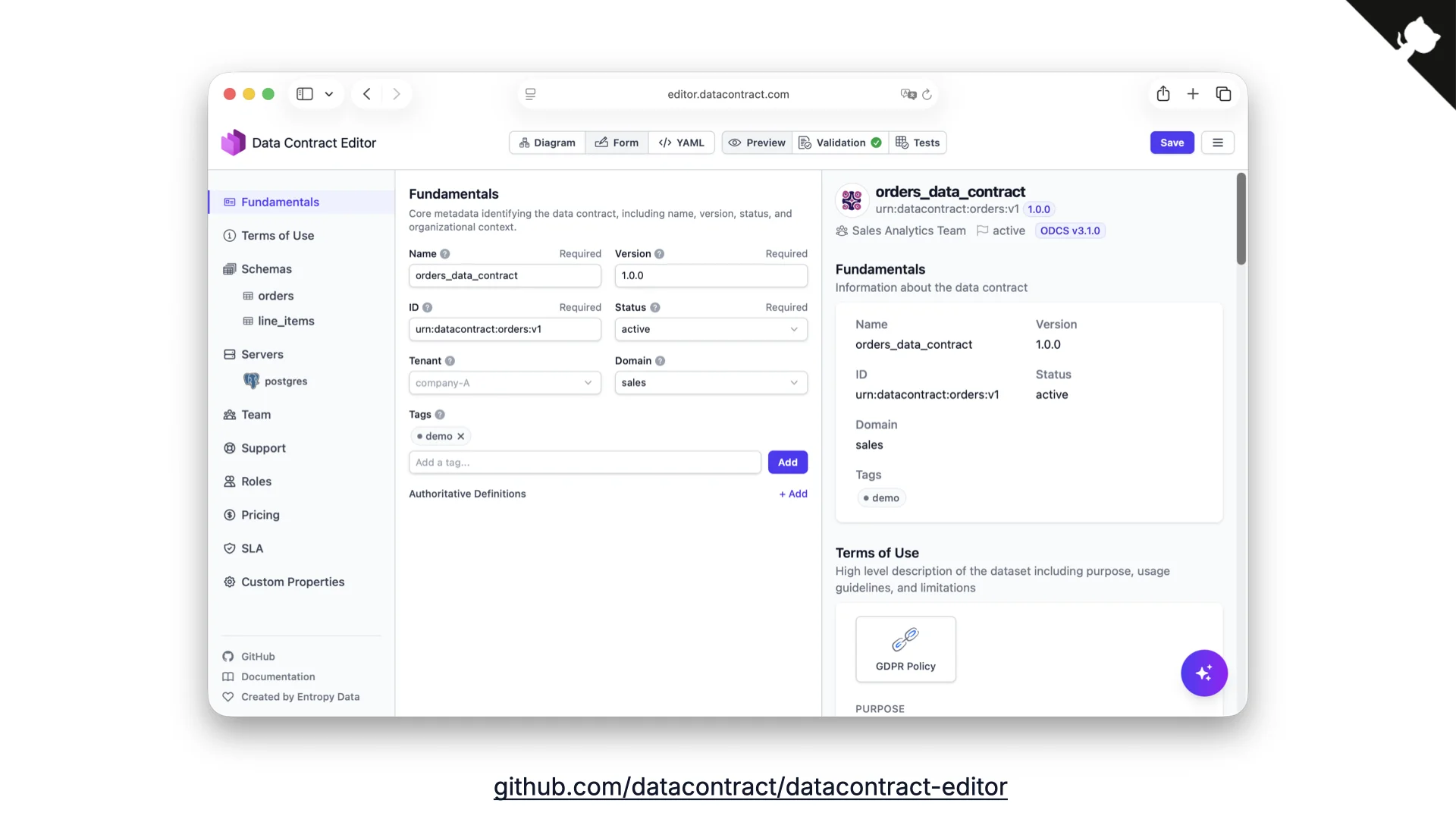
Editoren für Menschen (und Business-User)
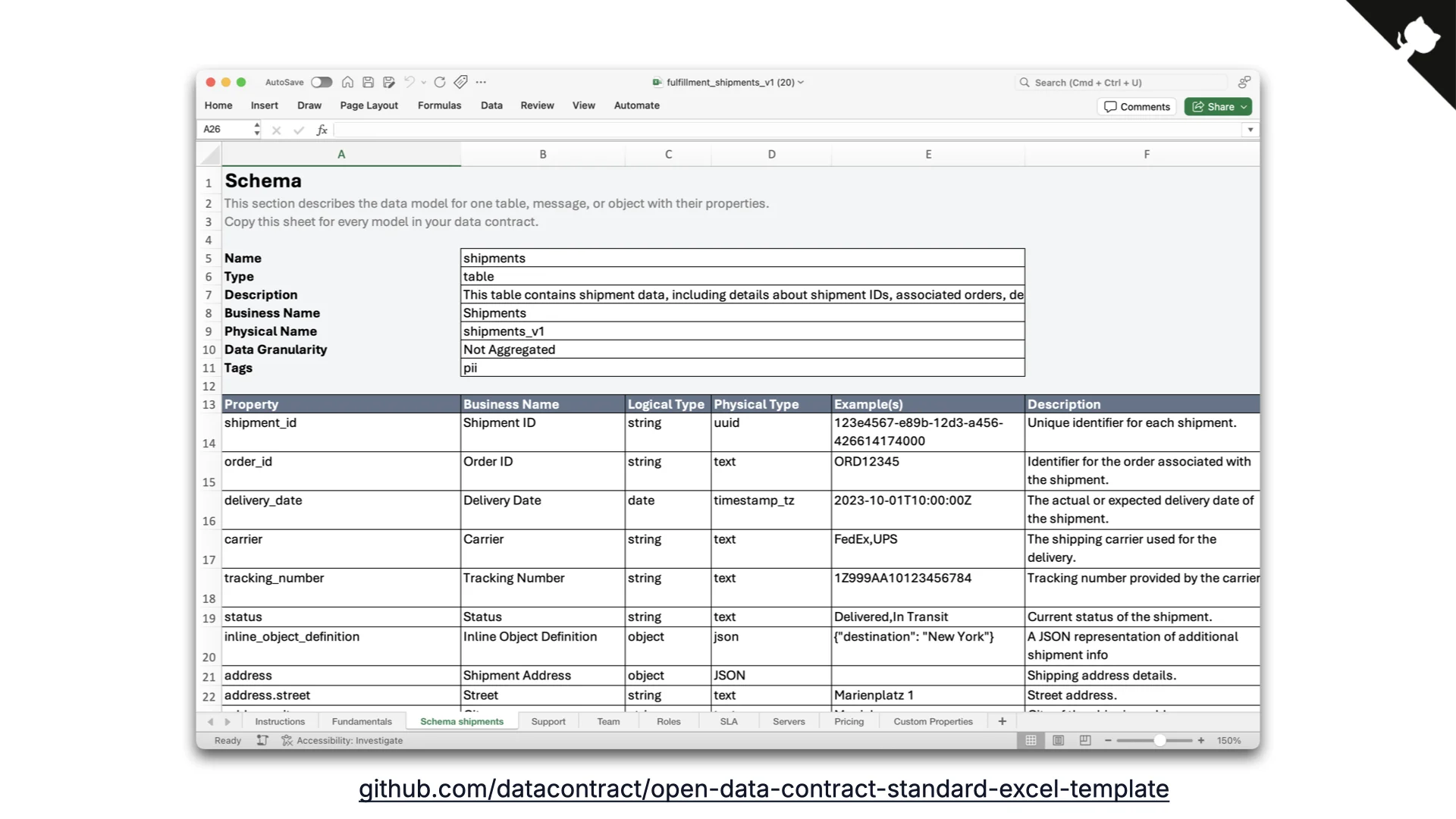
YAML manuell zu schreiben ist viel Arbeit, also haben wir den Data Contract Editor gebaut. Er erlaubt das Ausfüllen von Contracts über eine Formularansicht, eine Diagrammansicht oder das rohe YAML -- mit eingebauten Vorschauen und Validierungen. Entscheidend: Hier können Business- und Technik-Leute eine Brücke schlagen: Business denkt in Spalten und versteht die Daten, Technik füllt die fehlenden physischen Details aus. Oft fängt Business an, Technik vervollständigt.
Für die noch businessigeren Leute haben wir ein Excel-Template für ODCS erstellt. Es ist überraschend beliebt. Die CLI wandelt es in das richtige YAML um und verarbeitet es weiter.
Offener Standard + Open-Source-Editor + Automatisierungs-Tooling + ein Excel-Template -- du bekommst dieses Paket kostenlos, keine Paywall, einfach nutzen.
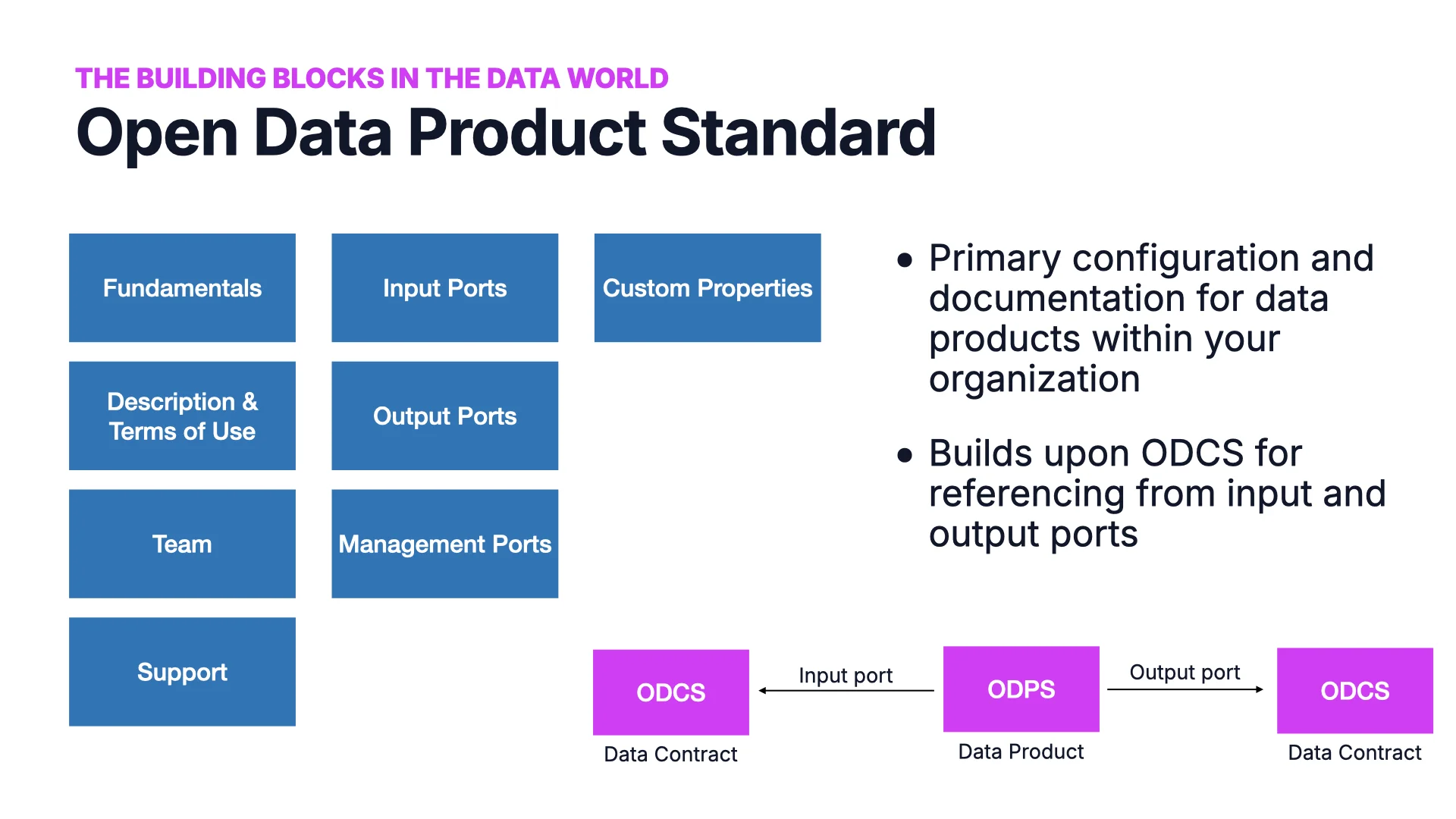

Der Open Data Product Standard (ODPS)
Contracts sind ein zentraler Aspekt. Datenprodukte sind der andere. Der Open Data Product Standard (ODPS) des BITOL-Projekts spiegelt ODCS bei Fundamentals, Nutzungsbedingungen, Team, Support und Custom Properties. Der Hauptunterschied: Input Ports, Output Ports und Management Ports. Jeder Port verweist auf einen ODCS Data Contract.
Weil ODPS auf ODCS aufbaut, ist die Datenprodukt-Datei kurz, wenn du bereits Contracts hast. Eine typische hat einen Namen, eine Beschreibung, eine Version und ein paar Ports -- z. B. einen Kafka Input Port v1 und vier Snowflake Output Ports für PII / Nicht-PII in v1 und v2. Das war's. Zusammen bilden sie den Graphen deines Data Mesh.

Vom YAML zu einem lebendigen Mesh-Graphen
Weil jedes Datenprodukt seine Input und Output Ports in ODPS deklariert und jeder Port auf einen ODCS-Contract verweist, bekommst du einen vollständigen Abhängigkeitsgraphen kostenlos. Quellanwendungen speisen Datenprodukte; Datenprodukte speisen andere Datenprodukte oder direkt Consumer-Use-Cases wie Funnel-Analytics, monatliche Zielberichte oder Echtzeit-Klassifizierung von Usern.
Das ist der ganze Sinn: Der Standard ist das, was den Graphen existieren lässt. Visualisiere ihn, und du hast deine Data-Mesh-Karte -- vollständig aus Contract- und Produkt-YAML-Dateien abgeleitet, nicht von Hand gezeichnet.

Aber sei vorsichtig, wenn du es "claudest"
In diesem Bereich gibt es echte Verwirrung. Zwei verschiedene Projekte bei der Linux Foundation teilen dasselbe Akronym: ODPS steht sowohl für "Open Data Product Standard" (den, den ich beschrieben habe, Teil von BITOL) als auch für "Open Data Product Specification" (ein separates eigenständiges Projekt). Wenn du suchst -- oder Claude fragst -- musst du wissen, welchen von beiden du gerade liest.
Die mentalen Modelle sind verschieden. Der BITOL Standard modelliert Datenprodukte mit mehreren Input Ports, mehreren Output Ports und Verknüpfungen zu vielen ODCS-Contracts -- er ist als komponierbare Familie von Standards entworfen. Die Specification kennt kein Konzept von Input Ports und erlaubt höchstens einen verknüpften Contract auf oberster Ebene; sie ist stark bei Pricing Plans und Internationalisierung, was sie zu einer besseren Wahl macht, wenn du einen externen Datenmarktplatz mit komplexen kommerziellen Konditionen betreibst.
Keiner von beiden ist falsch -- sie lösen nur unterschiedliche Probleme unter demselben Namen. Ich bin im BITOL-Lager, weil mir die Familie von Standards wichtig ist, die zusammen komponiert. Das ist mein Bias; deiner mag abweichen.
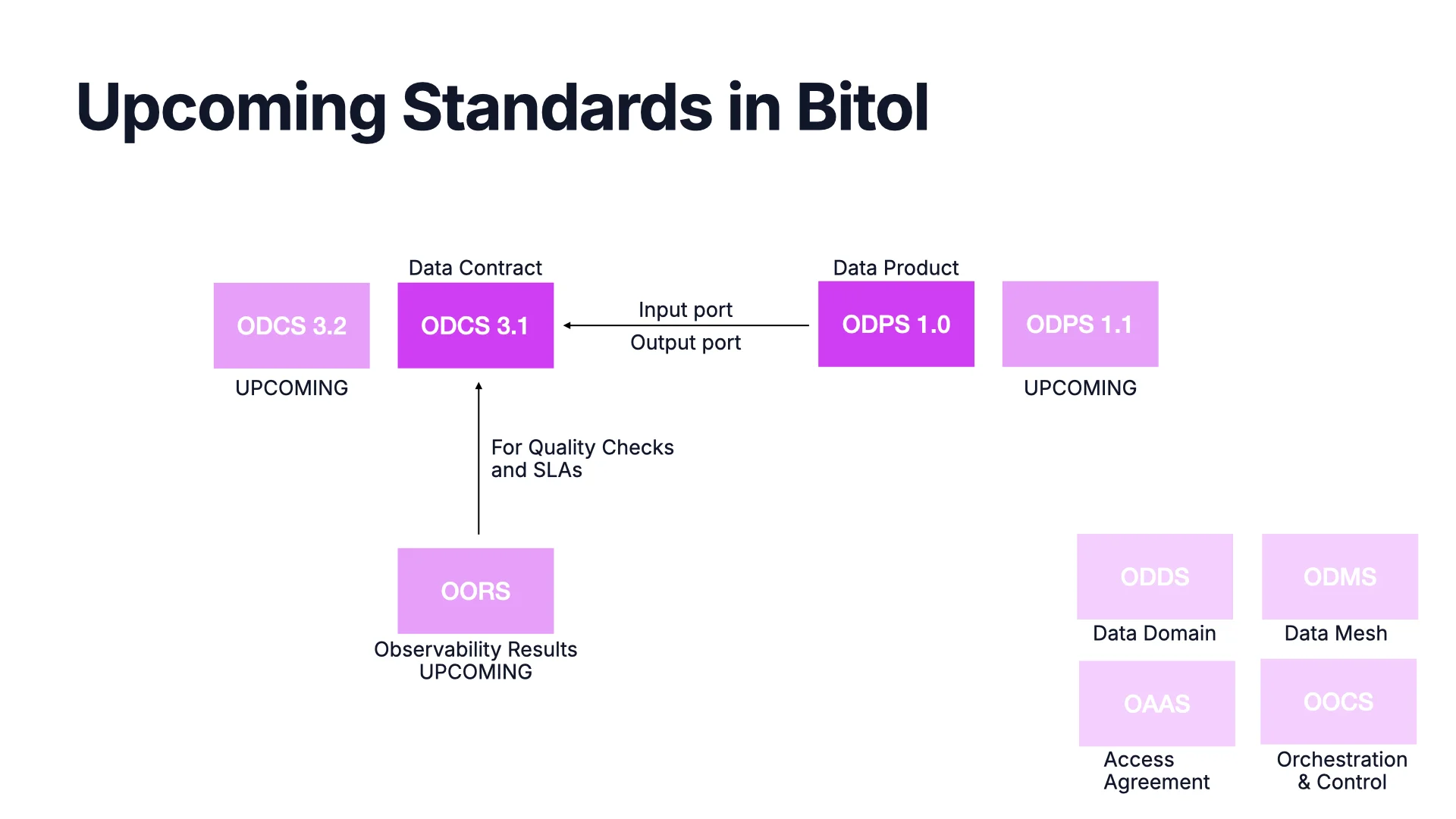
Was als Nächstes in der BITOL-Familie kommt
ODCS 3.1 und ODPS 1.0 sind heute die Kernstandards. Minor-Versionen später dieses Jahr konzentrieren sich vor allem darauf, mehr AI-Kontext hinzuzufügen -- Metadaten, die Agenten zur Datenentdeckung und Query-Generierung nutzen können.
Um den Kern herum entwerfen wir Hilfsstandards: OORS für Observability-Ergebnisse (wie sieht ein Quality-Check-Ergebnis aus?), OAAS für Access Agreements und Request-Access-Workflows, ODDS für Datendomänen, ODMS für Data Mesh und OOCS für Orchestrierung und Steuerung. Der Kern bleibt Kern; die Hilfsstandards decken die Ränder ab, die jeder Datenmarktplatz irgendwie kodieren muss.
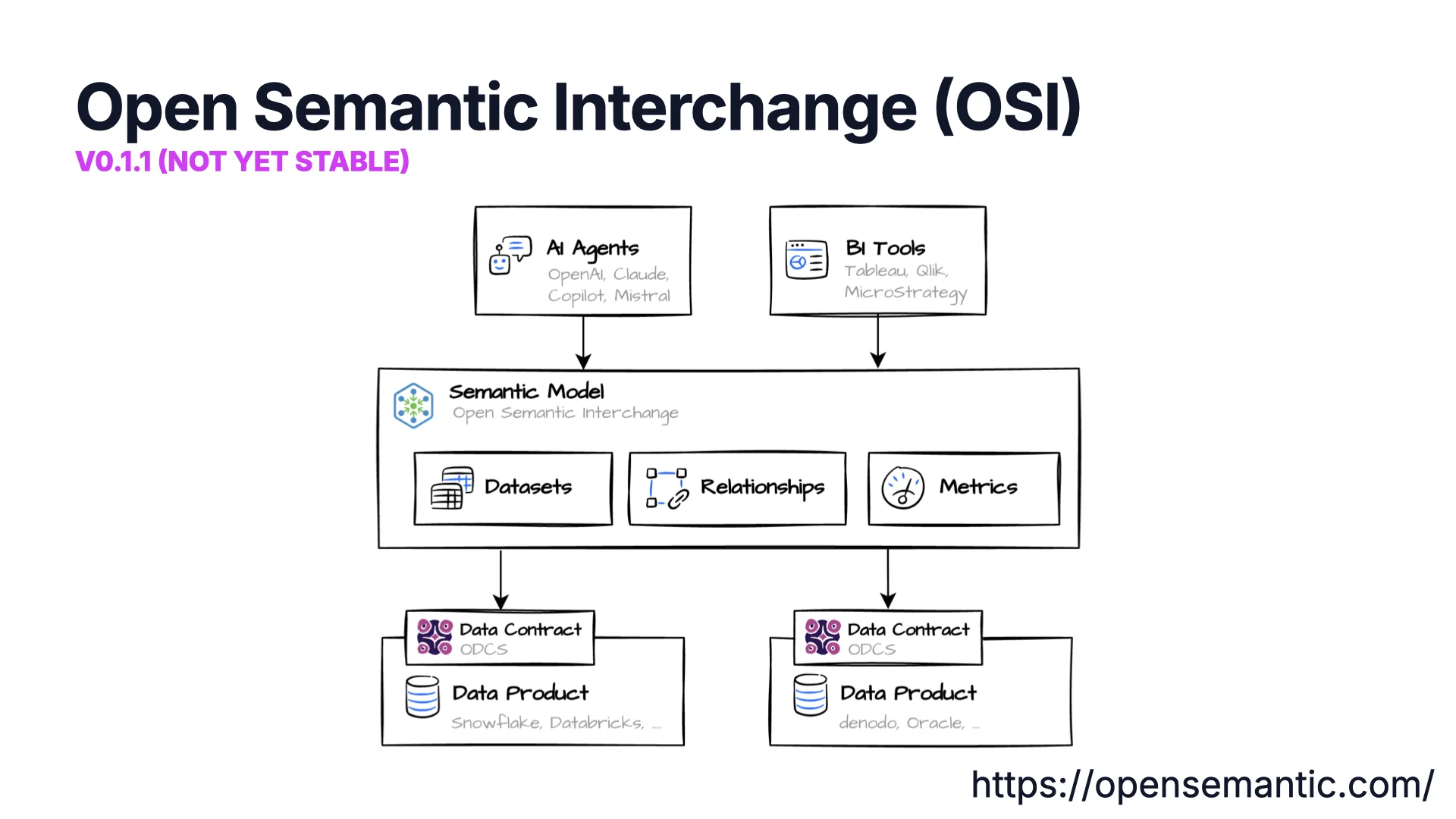

Open Semantic Interchange (OSI)
Wieder haben wir eine Akronym-Kollision -- OSI ist auch das Netzwerk-Schichtenmodell, das du in der Informatik-Vorlesung gelernt hast. Dieses hier ist das Open Semantic Interchange, eine von Snowflake mit vielen anderen Unternehmen vorangetriebene Initiative. Es ist Version 0.1.1 und explizit noch nicht stabil, aber die Working Groups sind sehr aktiv.
Die Kernidee: Auf deinen Datenprodukten und Contracts baust du ein semantisches Modell mit Datasets, Beziehungen und Metriken auf -- ähnlich dem Power-BI-Semantic-Layer. Dann fügt OSI "AI Sprinkles" hinzu: Anweisungen, Synonyme und Beispiele, damit KI-Agenten und BI-Tools korrekt mit den Daten arbeiten können.
Verglichen mit ODCS überlappen sich die beiden bei Datasets, Beziehungen und Custom Extensions. OSI fügt Metriken (z. B. total_revenue = SUM(order_total)) und dynamische Felder (z. B. full_name = first_name + " " + last_name) hinzu. ODCS hat, was OSI derzeit fehlt: Nutzungsbedingungen, Quality Checks und SLAs. AI-Kontext ist die interessante Überlappung -- alle wollen ihn, und dorthin entwickeln sich beide.
Die Working Groups zu Ontologie, Composability und Tooling sind alle aktiv. Mein Kollege und Co-Founder Jung ist dort ebenfalls stark involviert. Das ist eines, das man im Auge behalten sollte.
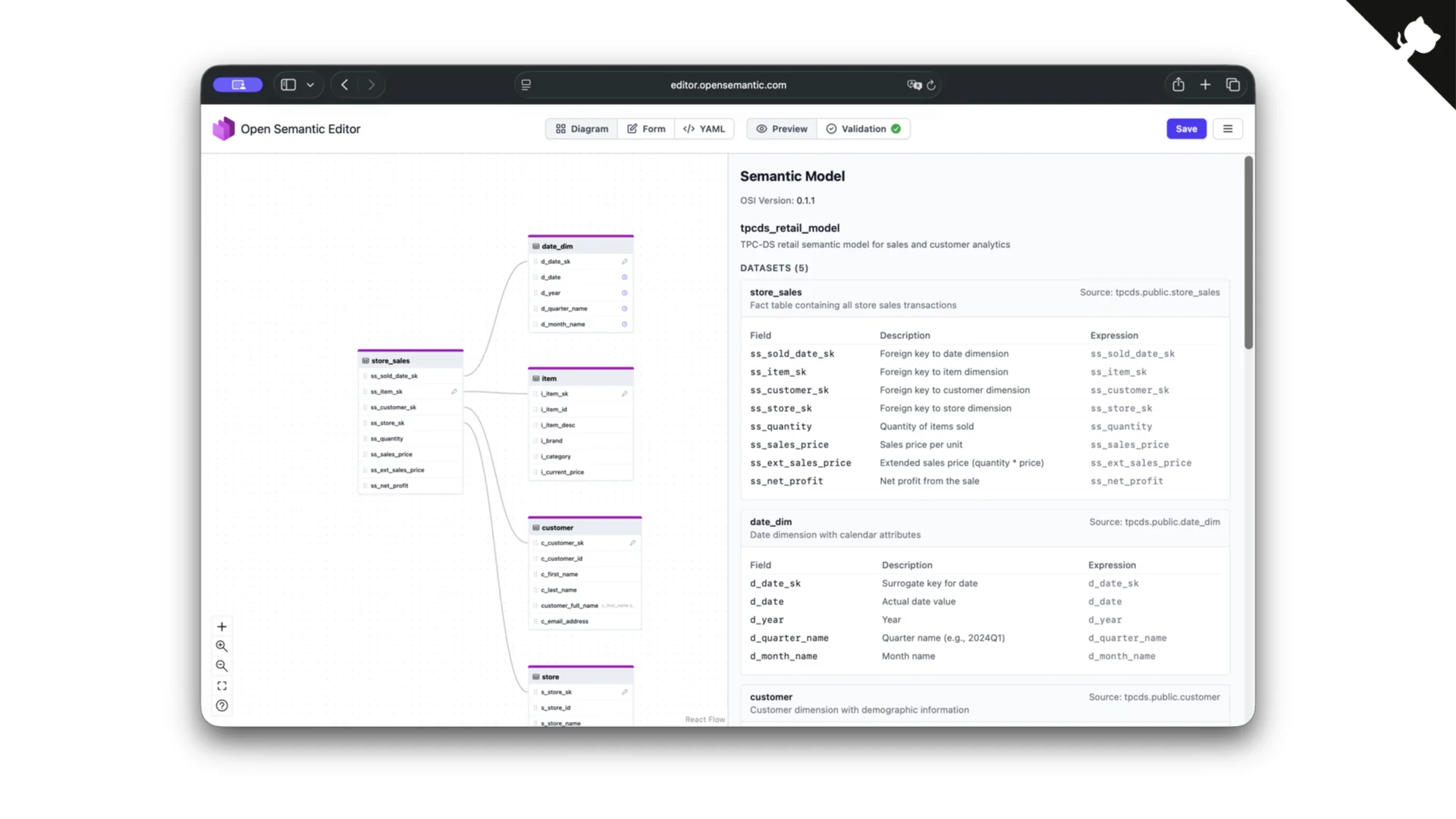
Ein Editor für semantische Modelle
Weil ein OSI-Modell immer noch viel wie ein Contract aussieht -- Tabellen, Foreign Keys, Beziehungen -- haben wir auch dafür einen kleinen Open-Source-Editor gebaut, verfügbar unter editor.opensemantic.com (Quellcode auf GitHub). Dasselbe Muster wie beim Data Contract Editor: Diagramm-, Formular- und YAML-Ansichten, mit Vorschau und Validierung.
Ehrlich gesagt hat Claude Code das meiste davon an einem Nachmittag für uns gebaut. Das ist jetzt genau deshalb möglich, weil das zugrunde liegende Format ein offener Standard ist, den das Modell bereits versteht.

Und viel Power dahinter
OSI ist noch 0.1.1, aber die Working Groups dahinter sind ernsthaft dabei:
- Advanced Metrics & Expression Language — über die Basics hinaus, die du oben gesehen hast.
- Composability — wie OSI-Modelle einander referenzieren und komponieren.
- Catalog Integration — Anbindung an die Datenkatalog-Schicht im Unternehmen.
- Ontology Representation — Konzepte und Eigenschaften als Graph. Mein Co-Founder Jochen Christ ist hier tief involviert.
- Model Converters & Developer Tools — wo die Ecosystem-Story tatsächlich gebaut wird.
Wenn du dir die Mitgliederliste anschaust -- Snowflake, Databricks, Tableau, MicroStrategy und viele andere -- steckt hier viel Power dahinter. Das lohnt sich zu beobachten.
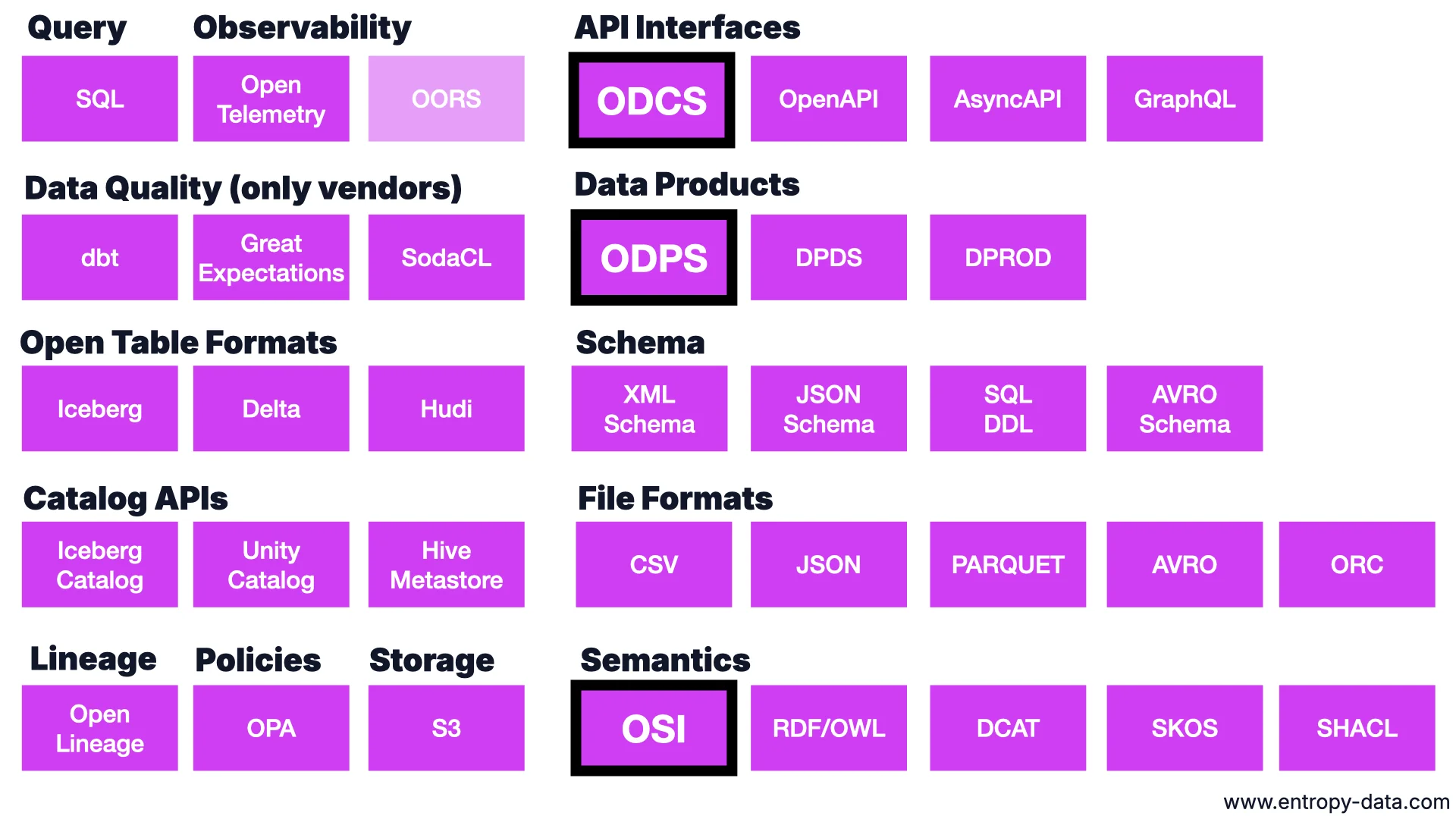
Die breitere Landschaft
Heute habe ich ODCS, ODPS und OSI behandelt, aber die Karte ist viel größer: API-Schnittstellen (OpenAPI, AsyncAPI, GraphQL), Schemas (XML, JSON, SQL DDL, Avro), Dateiformate (CSV, JSON, Parquet, Avro, ORC), offene Tabellenformate (Iceberg, Delta, Hudi), Catalog APIs (Iceberg Catalog, Unity Catalog, Hive Metastore), Lineage (OpenLineage), Policies (OPA), Observability (OpenTelemetry, OORS), Data Quality (dbt, Great Expectations, SodaCL) und Semantik (OSI plus RDF/OWL, DCAT, SKOS, SHACL).
Was die hervorgehobenen eint: Sie sind offen, nicht von einem einzelnen Unternehmen kontrolliert, von einem Komitee getragen, mit Open-Source-Tooling drumherum. Ein Data Mesh wird auf vielen Standards gebaut, und es kommen noch mehr.

Die Prognose
Swagger 1.0 wurde 2011 veröffentlicht. Heute ist OpenAPI überall -- jede REST-API, die du anfasst, hat es. 99 % Adoption, de facto.
ODCS 3.0 -- das erste Release, das nicht an PayPals Spezifika gebunden ist, die erste wirklich von jedem Unternehmen nutzbare Version -- wurde 2025 veröffentlicht. Meine Annahme ist, dass das viel schneller geht als bei OpenAPI, weil sich die Welt heute viel schneller bewegt.
Meine Prognose: ODCS wird in vier Jahren überall sein. Sei vorbereitet.
Danke
Danke für den herzlichen Empfang in Leuven, und danke an Tom De Wolf (ACA) und Emma Houben (AE) für die Einladung und das Organisieren eines tollen Abends.
Wenn du das Gespräch fortsetzen möchtest, findest du mich auf LinkedIn, unter simonharrer.com oder unter simon.harrer@entropy-data.com. Probier den Contract-basierten Datenmarktplatz für Datenprodukte unter www.entropy-data.com aus, und gib bitte datacontract-cli einen Star auf GitHub, wenn es dir hilft.
Q&A
Ausgewählte Fragen aus dem Publikum nach dem Vortrag.
F: Wenn du viele Data Contracts aus derselben Quelle hast und dieselben Quality Checks über alle hinweg pflegen und ändern musst, wie gehst du damit um?
Der beste Ansatz ist, den Quality Check upstream zu schieben -- so nah wie möglich an das Quellsystem -- damit du Fehler früh fängst und nicht dieselben teuren Checks wiederholt den Graphen hinunter ausführen musst. Falls das nicht möglich ist, ist eine Antwort KI: mit Agenten wie Claude Code ist es relativ günstig, verwandte Checks über Contracts hinweg konsistent zu halten, und das ist nicht so frech, wie es klingt. Darüber hinaus ist das Muster, das wir typischerweise nutzen, eine Verknüpfung vom Contract zu einem semantischen Modell. Du definierst order_id einmal -- Beschreibung, Typ, Format ("beginnt mit 053") -- und erbst es überall. Bonus: Weil zwei Contracts auf dasselbe order_id-Konzept zeigen, weiß die KI, dass diese Tabellen gejoint werden können. Dasselbe, nicht ähnlich.
F: Wie verhält sich OSI zu DCAT?
Heute haben sie keine Beziehung zueinander. DCAT lebt in der RDF- / Semantic-Web-Welt als Katalog-Vokabular, inspiriert von Bibliotheken und Dataset-Angeboten. Es gibt eine Working Group in OSI, um Semantik hinzuzufügen -- Konzepte und Eigenschaften, im Grunde ein in YAML kodierter Graph -- was die beiden näher zusammenbringt, aber ich glaube nicht, dass sie jemals perfekt zusammenpassen werden. DCAT komponiert in RDF natürlich mit anderen Vokabularen (DPROD von der OMG zum Beispiel). YAML-Formate wie OSI sind strikter. Die Formatwahl hat Konsequenzen.
F: Du hast erwähnt, Transformationen mit dem Data Contract zu automatisieren. Kannst du ein Beispiel geben? Mein Verständnis ist, dass der Contract keine Transformationslogik erfasst.
Richtig -- der Contract ist auf den Consumer ausgerichtet, nicht auf die Implementierung. Er erfasst ein paar Transformationshinweise (woher eine Spalte kommt, eine kurze Beschreibung), ist aber bewusst begrenzt. Du kannst immer ODCS' Custom Properties nutzen, um zu kodieren, was du brauchst. Was wir in der Praxis sehr gut funktionieren sehen: Gib Claude Code die Input- und Output-Contracts plus einen Skill wie "so bauen wir typischerweise ein Databricks-Datenprodukt" und lass es die Lücken füllen. Füge semantische Verknüpfungen hinzu, die über Contracts hinweg auf dieselben Konzepte zeigen, und die KI findet auch die Joins heraus. Für tatsächliche Runtime-Lineage-Details -- wie die Pipeline wirklich funktioniert -- nutze OpenLineage-Traces. Das ist es, was Column-Level Lineage erfasst, nicht der Contract.