Talk
Open Standards for Data Mesh
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · April 21, 2026
In this talk at Data Mesh Belgium Meetup #7 in Leuven, I walk through the three open standards shaping how we build data mesh today: the Open Data Contract Standard (ODCS), the Open Data Product Standard (ODPS), and the Open Semantic Interchange (OSI). I show how they fit together, where the tooling is going, and why one standard will be everywhere in four years.

Recorded live at Data Mesh Belgium Meetup #7 in Leuven. The transcript below is an edited version of the talk.
Thanks to Tom De Wolf (ACA) and Emma Houben (AE) for the invitation and hosting the meetup, and to the BITOL community for the open standards we build together.

Introduction
Thanks for the invite, Tom -- this is my first time in Leuven, and it has been great so far. My name is Simon and I am a software engineer at heart. I worked for seven years at a consultancy and since August 2025 I am Co-Founder and CEO of Entropy Data, where we build a data product marketplace. We have customers in seven countries worldwide -- including the US, Australia, and Belgium.
On the side, I co-authored "Java by Comparison" back in my Java days (Claude codes for me now), and I co-translated the "Data Mesh" book into German -- the cool part is that the pictures in the German edition are actually printed in color. I co-write datamesh-architecture.com and datacontract.com, co-maintain the open-source Data Contract CLI and Data Contract Editor, and serve on the TSC at the Linux Foundation's BITOL project driving open standards for data contracts and data products. In fact, we held our TSC meeting earlier today at Tom's office -- a nice way to start the evening in person.
A Quick Data Mesh Recap
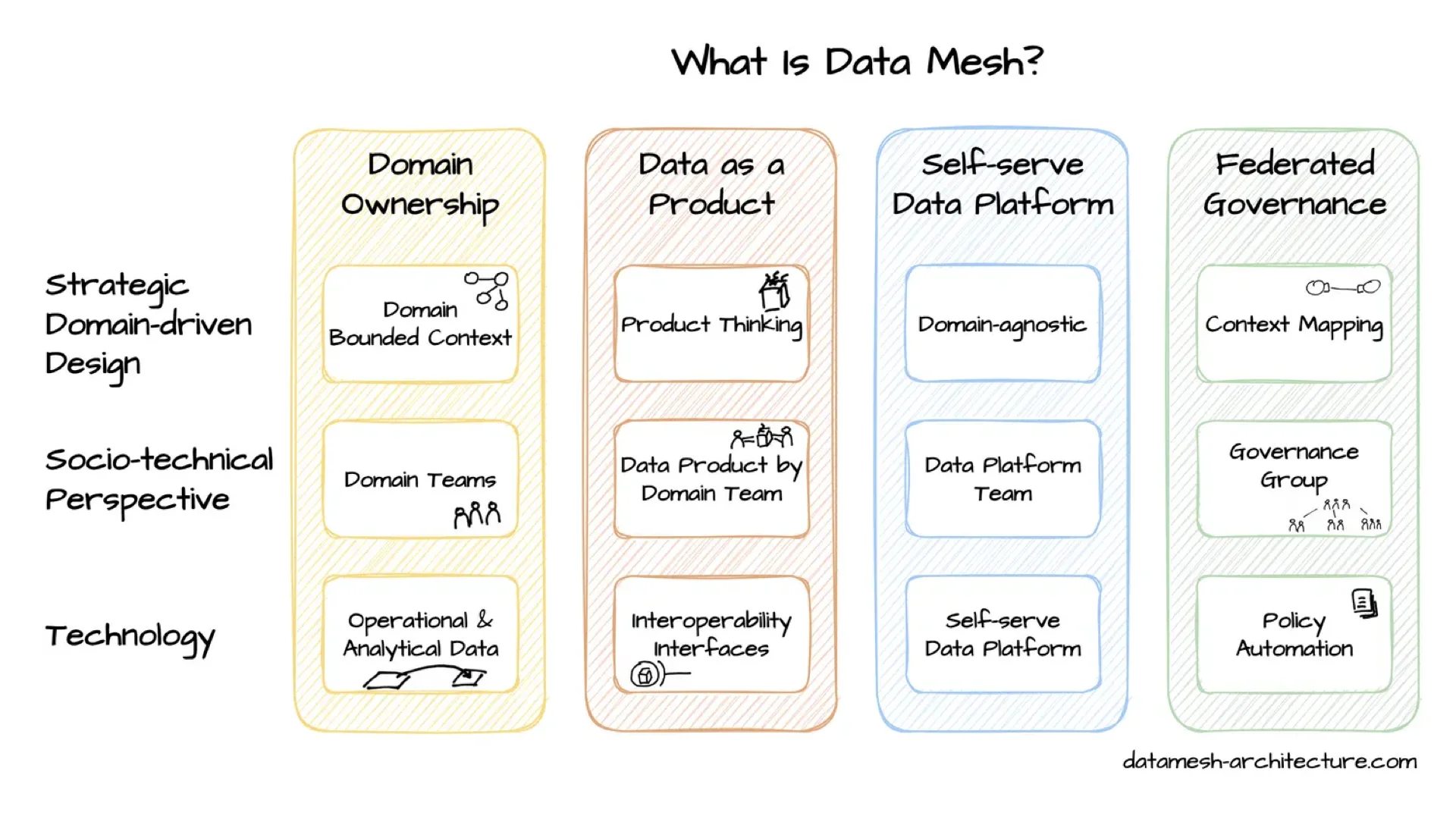
This is a data mesh meetup, so you probably know this already -- a very short recap just to be on the same page. Data mesh, coined by Zhamak Dehghani, rests on four principles: domain ownership, data as a product, self-serve data platform, and federated governance.
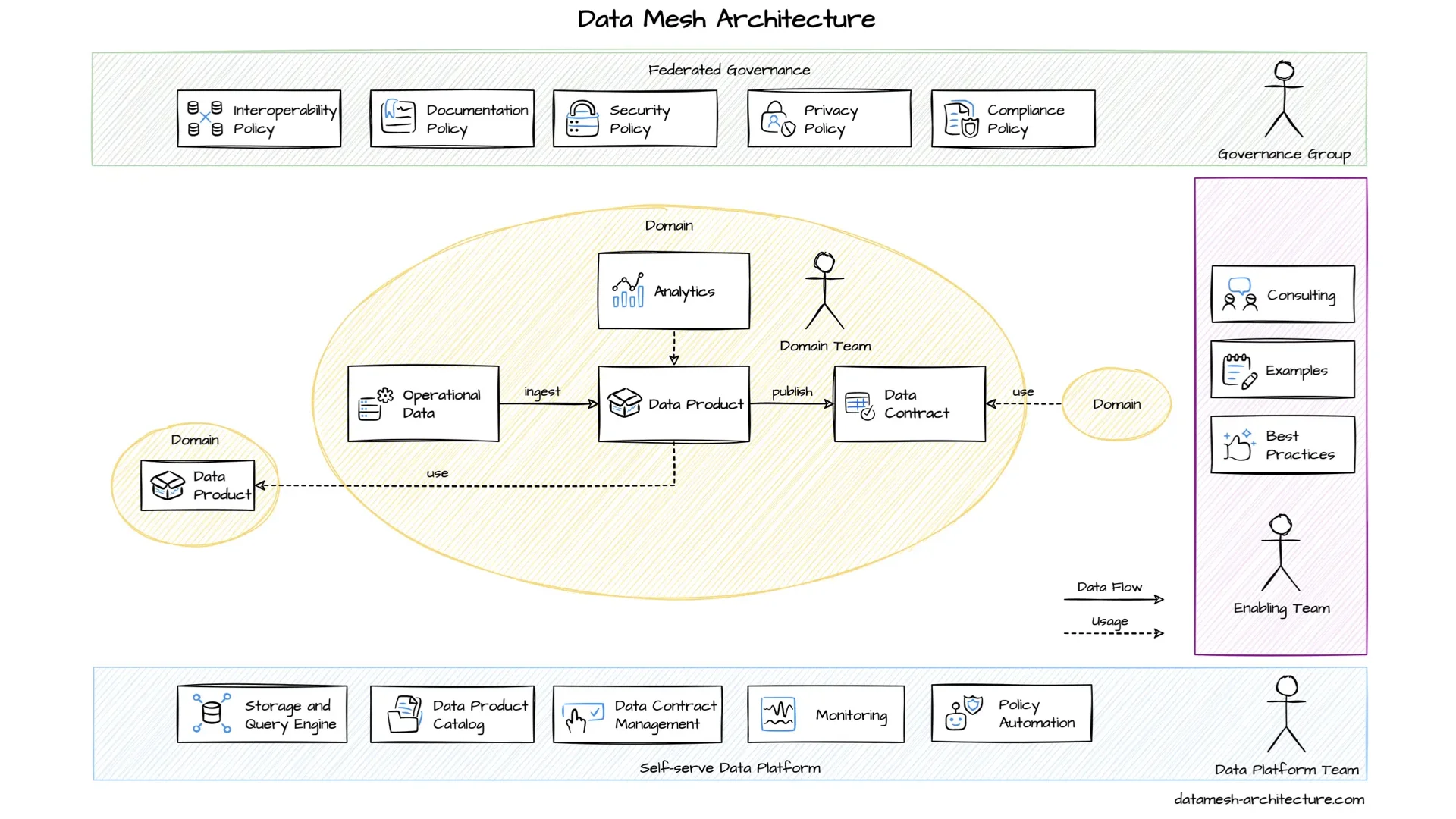
The typical architecture has the self-serve platform at the bottom, federated governance at the top, and an enabling team on the side helping others. In the center are the domains with their domain teams building data products for others to use.
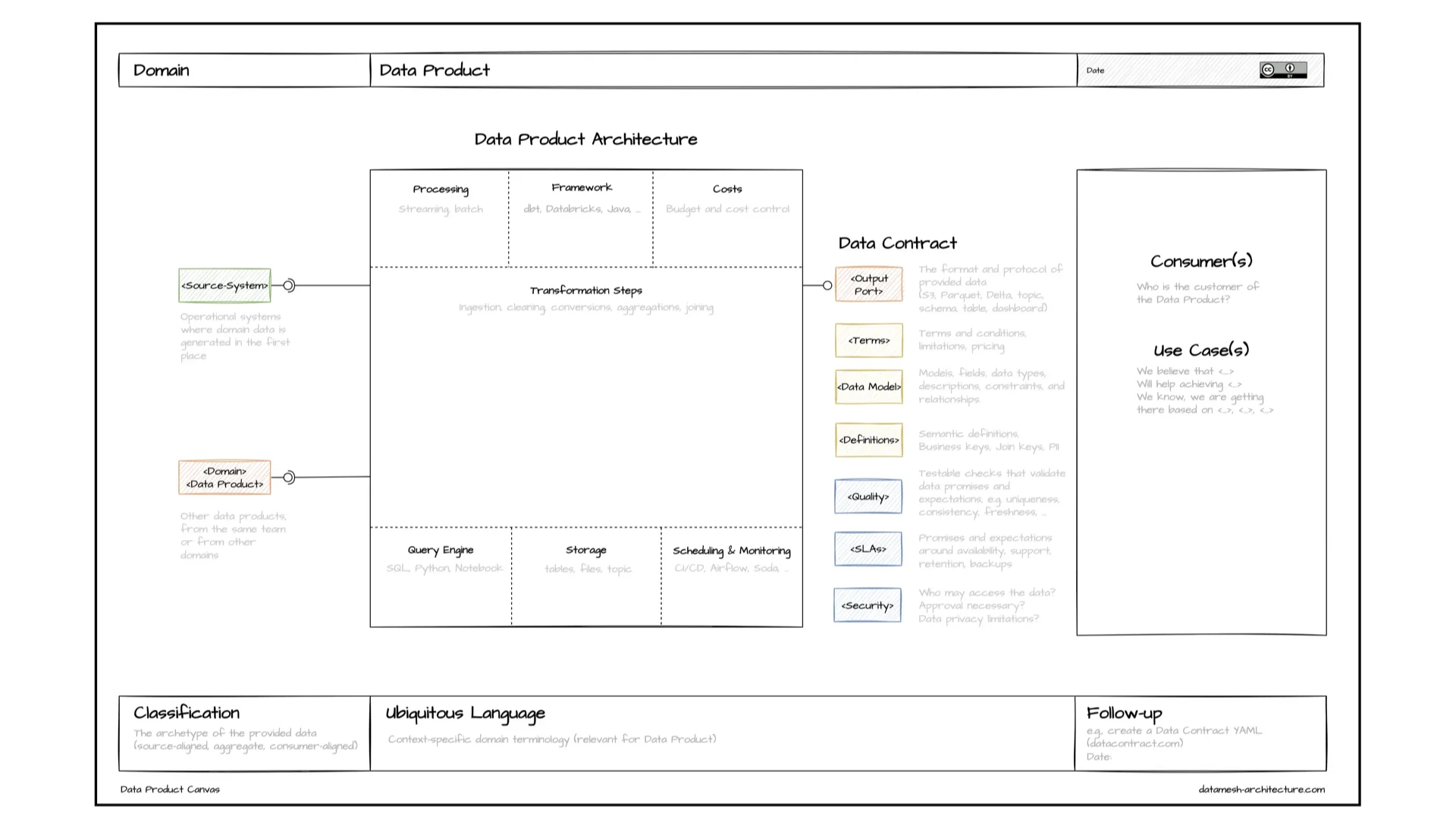
When a team builds a data product we often use the Data Product Canvas -- open-source, created during my consultancy days as a Miro template. Input ports come from source systems or other data products. Output ports offer data via a data contract to consumers with use cases. In the middle sits the implementation: processing, framework, query engine, storage, scheduling, cost. Together, many of these form the larger mesh graph.


What Is a Standard? And Why Do We Need Them?
Instead of the Oxford dictionary, I like to look at XKCD. Different ways of writing a date led to the ISO 8601 standard: everybody benefits when they use it (except, as XKCD notes, the US). Different ways of counting -- "one, two, three, go" versus "three, two, one, go" -- create the same confusion and cost, which is why standards bring cost down. And of course there is the classic XKCD "How Standards Proliferate": you have fourteen standards, you create a new universal one to cover everything, and now you have fifteen. That is the standards problem itself.
Let me clarify what I am talking about today. The standards I care about are:
- De Facto, not De Jure -- driven by actual usage in a critical mass of companies, not by law.
- Initiative, not Vendor -- owned by an open initiative, not controlled by a single company. If one vendor dictates it, it is not a standard.
- Many contributors, not One -- it is about power and control being distributed.
- Open, not behind a Paywall -- freely usable. (We are ISO 27001 certified and paying 130 Swiss Francs for a 10-page PDF is exactly the kind of friction open standards avoid.)
Standardization could happen almost everywhere in a data mesh: monitoring, catalogs, query, storage, policies, analytics, relationships. I will focus on three that matter most right now.
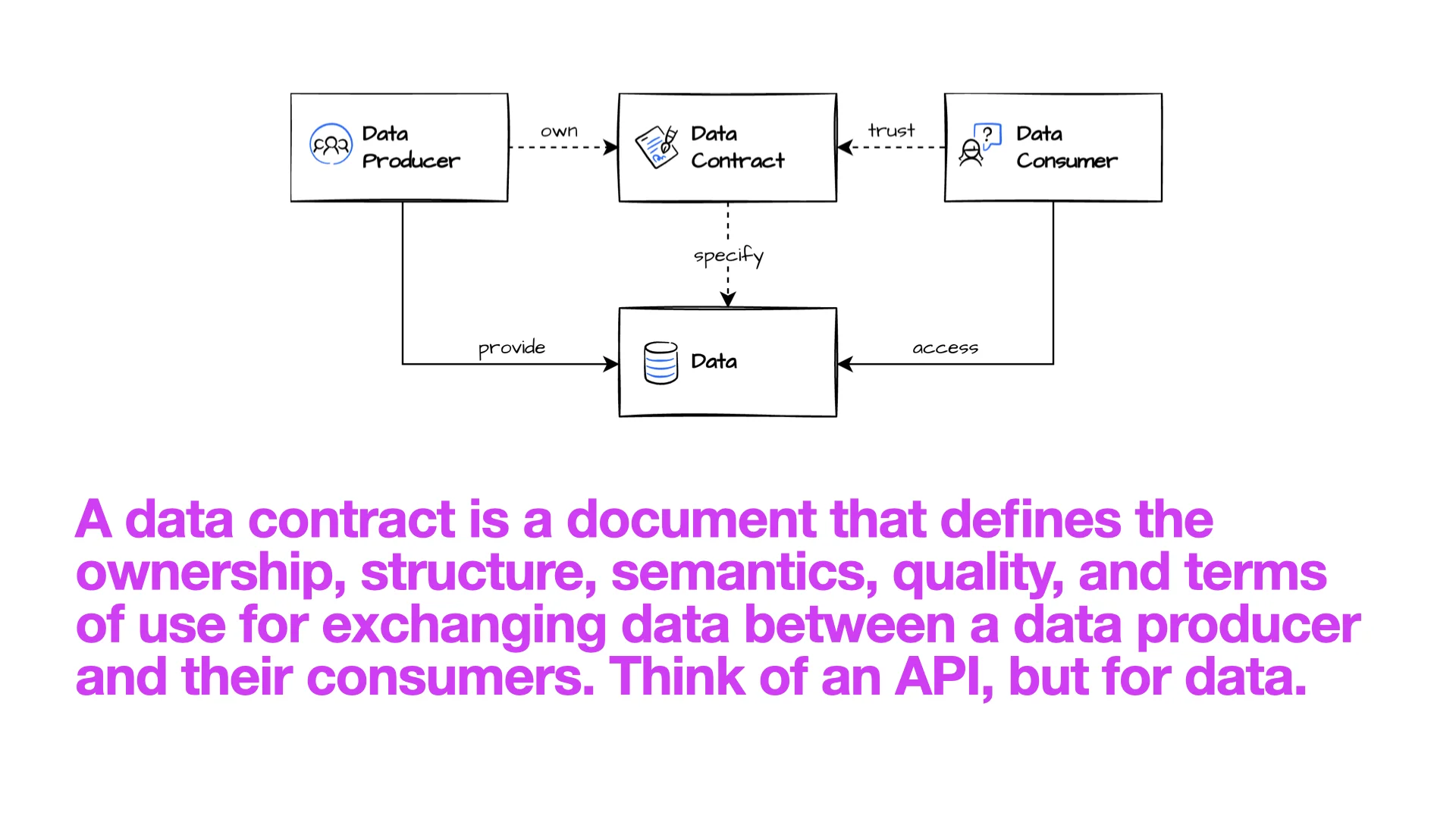
What Is a Data Contract?
A data contract is a document that defines the ownership, structure, semantics, quality, and terms of use for exchanging data between a producer and its consumers. Think of an API, but for data.
The contract is what creates trust. The producer owns it; the consumer reads it and trusts it; together they agree on the data that will flow between them.
"The contract is by definition correct. When the data and the contract disagree, the data is wrong. That is how strong the trust layer is -- conceptually."
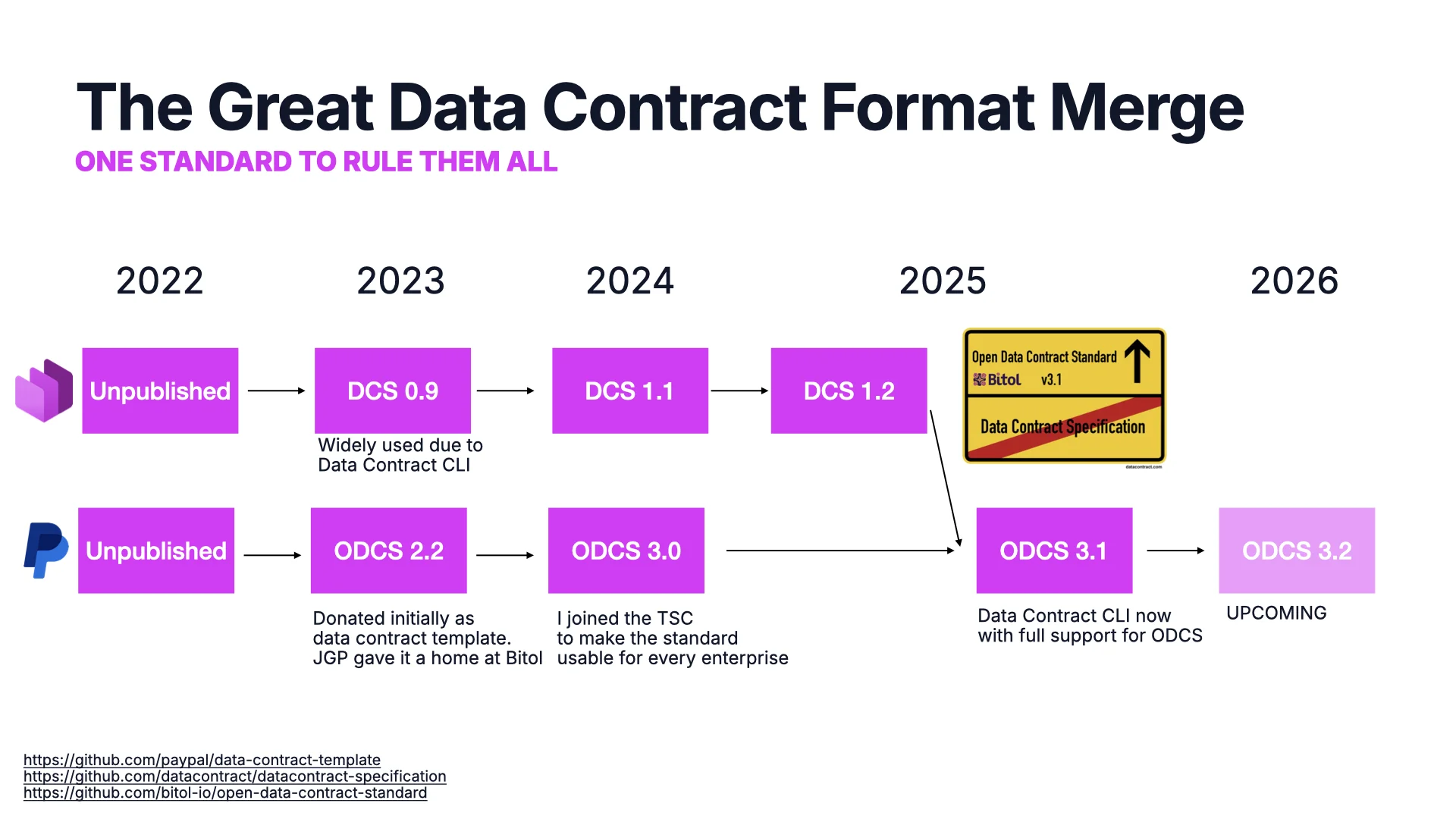
The Great Data Contract Format Merge
Because this need emerged with the rise of data mesh and decentralized data, every company initially invented their own format. PayPal created their internal template, open-sourced it, and donated it to the Linux Foundation as ODCS 2.2. In parallel, we built our own Data Contract Specification (DCS) around the same time, and it became widely used thanks to the Data Contract CLI tooling around it.
I like open stuff, so I joined the TSC and we released ODCS 3.0, stripping out the PayPal specifics and making it usable for any enterprise -- there is only one PayPal. Last year we deprecated our own Data Contract Specification in favor of ODCS and moved all our resources there. Control matters: being just one of many members on a committee with great parity between end users, consultants, and vendors is a much healthier balance than a single-vendor project, however open. ODCS 3.2 is upcoming; we just approved a few new additions at today's TSC meeting.
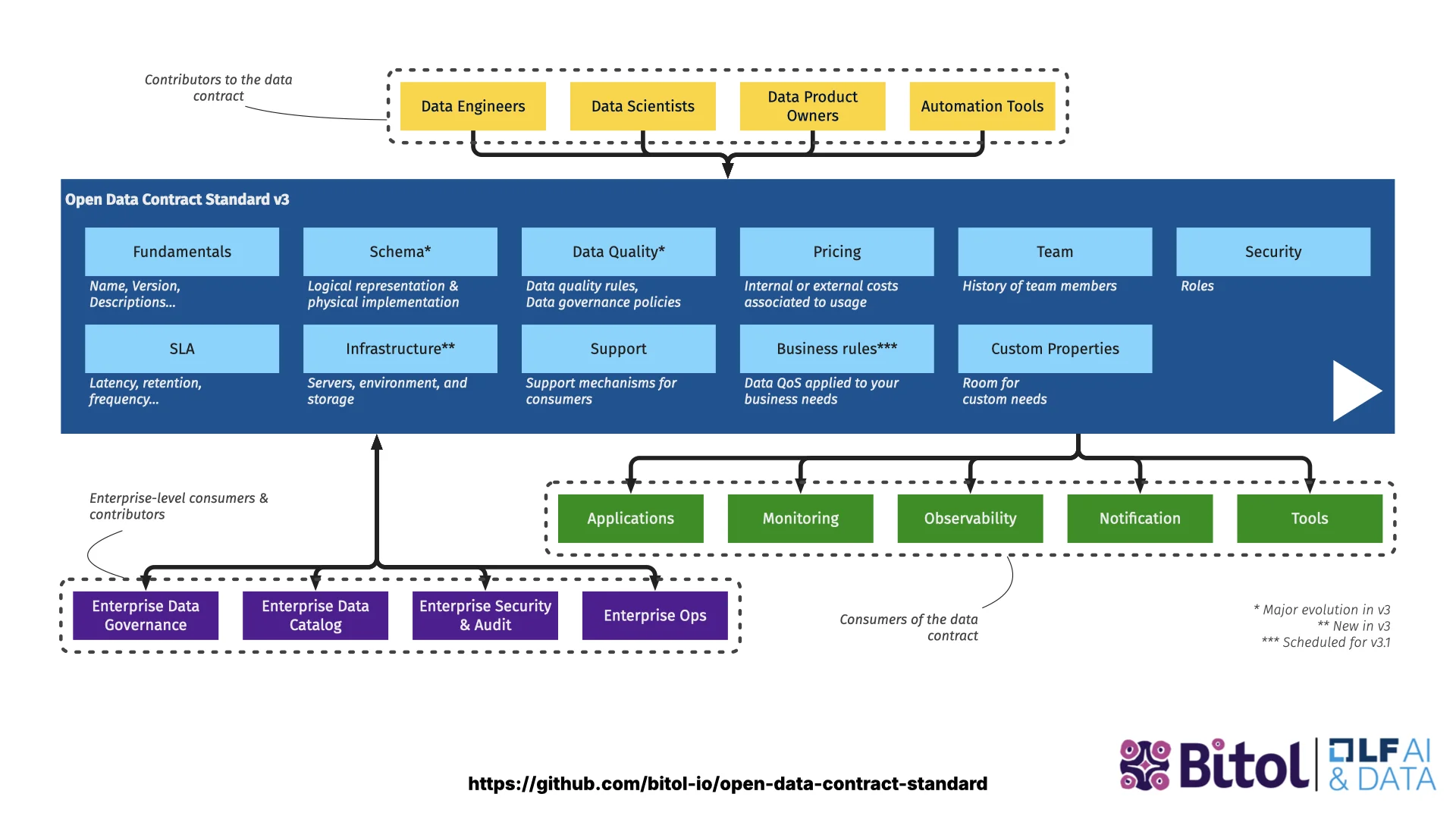
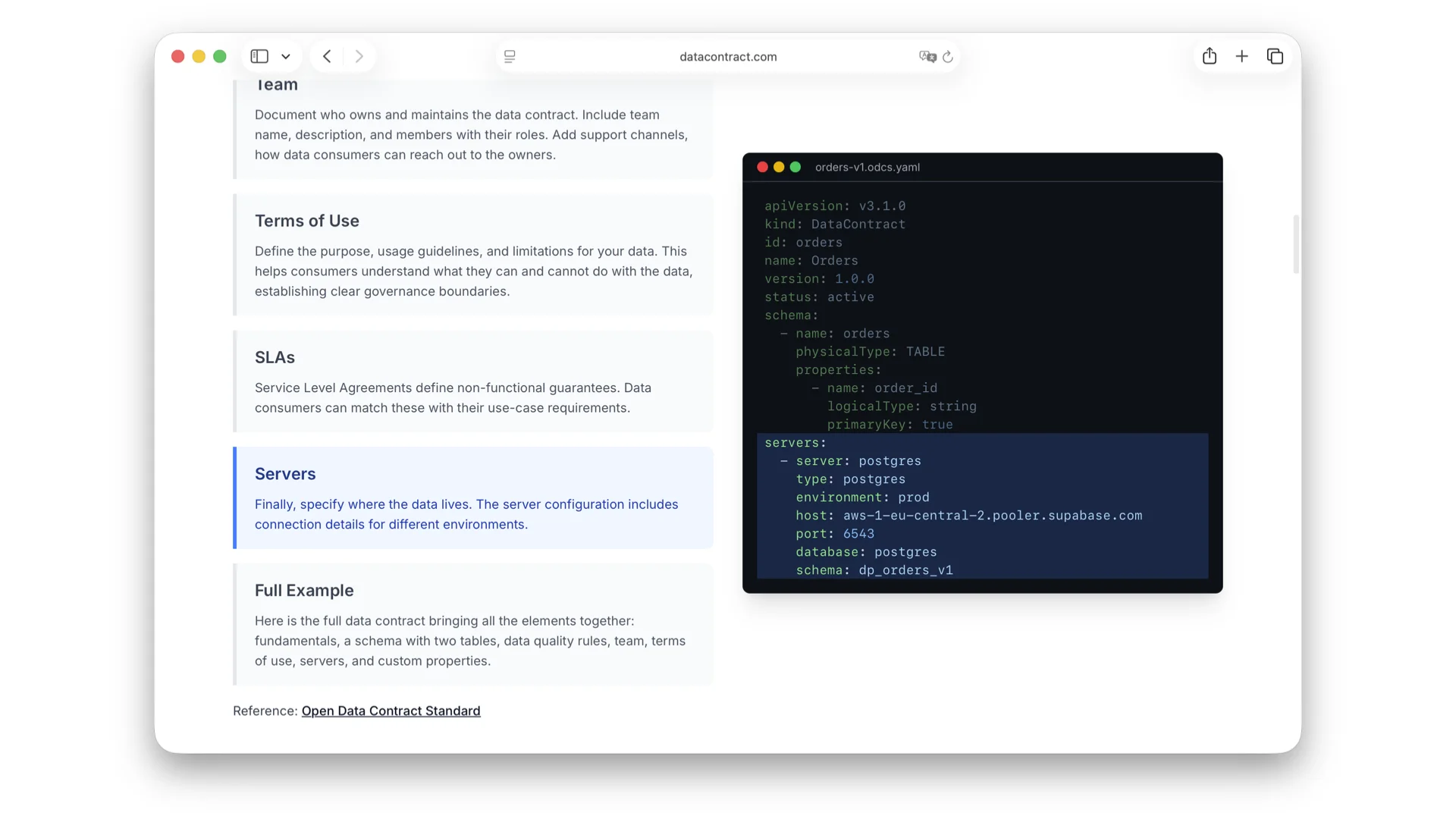
What's Inside an ODCS Contract
ODCS has a lot of building blocks where a producer can describe their offering. One YAML file captures:
- Fundamentals -- ID, name, version, status to phase offerings in or out.
- Schema -- tables and columns with types, primary and foreign keys, business names, classifications, PII tags. Even if your data lives as JSON on S3 or CSV on SFTP, you can still declare the relationships -- they are technically there.
- Data Quality -- enums like order_status ∈ {pending, shipped, cancelled}, or arbitrary SQL checks like "row count must be greater than 100,000".
- Team & Support -- how to reach the owners, Slack channels, ticket systems.
- Terms of Use -- what consumers can and cannot do with the data.
- SLAs -- freshness, retention, availability -- trackable by tools.
- Servers -- where the data actually lives, so consumers with access can go straight there.
The standard defines the YAML structure and what you can express. Everything downstream builds on top of that.

Automate All the Things
Once you have the YAML, you can automate: compare the contract against real data, detect breaking changes in a PR, continuously monitor production, generate Java, Pydantic, dbt models, SQL DDL, and push metadata into metastores, catalogs like Collibra, marketplaces like Entropy Data, and software catalogs like LeanIX. The Data Contract CLI does all of this -- connect to Snowflake, Databricks, BigQuery, whatever -- and produces a report on how well the data matches the guarantees. Under the hood we use Soda Core for the quality execution -- also an open-source project from a Belgian company, which feels appropriate here in Leuven.
And if you look at the GitHub star history, the Data Contract CLI is more popular than the ODCS spec itself. That is the lesson: tooling matters more than the standard. The standard exists because it gives you the tooling for free, it lets you avoid vendor lock-in when multiple vendors support the same format, and it means we help each other instead of reinventing the same thing ten times.
A contract is also the best metadata you can give an AI. If you combine AI with this kind of structured metadata -- especially with modern Opus-class models -- the sky is the limit.
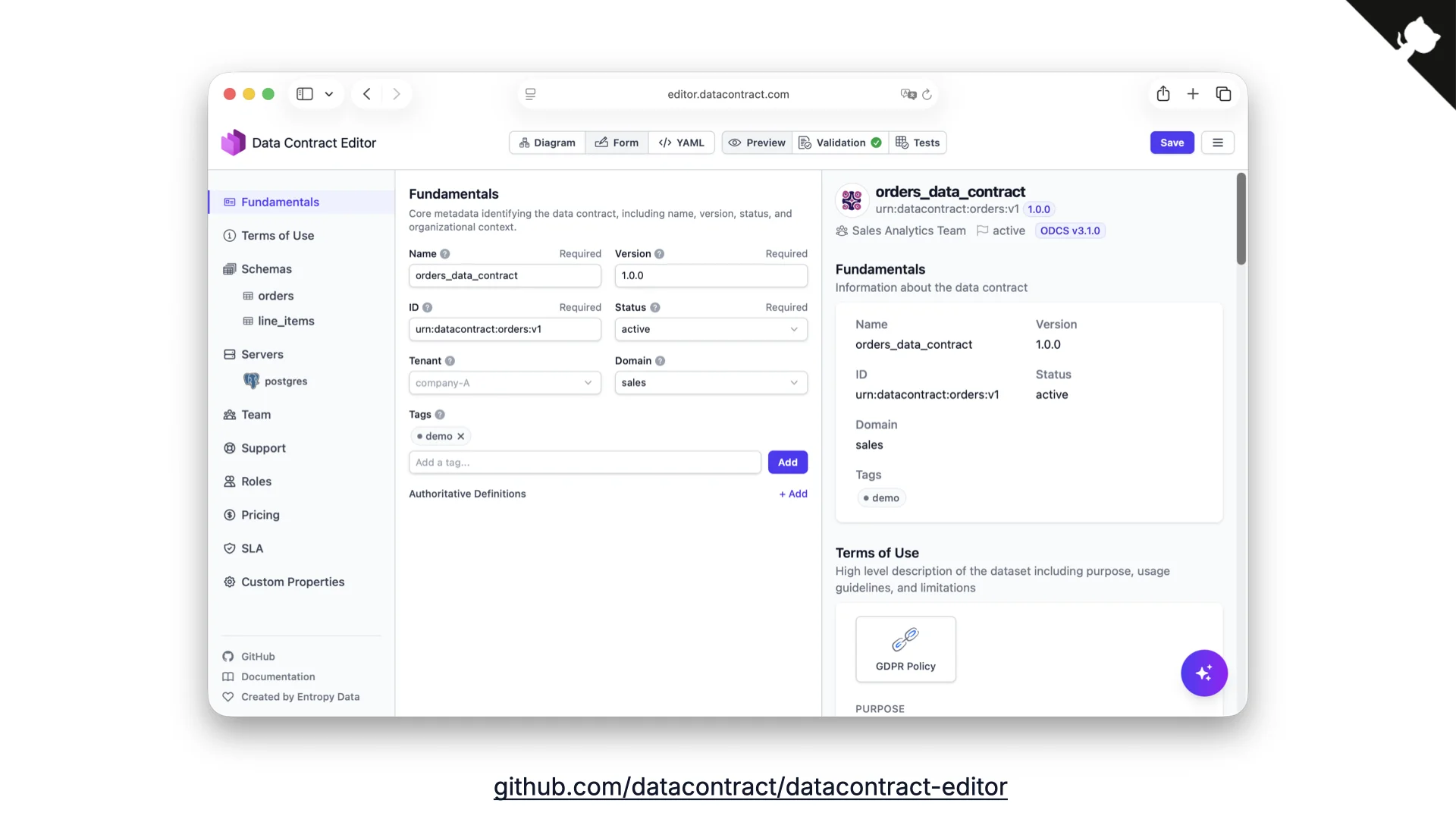
Editors for Humans (and Business People)
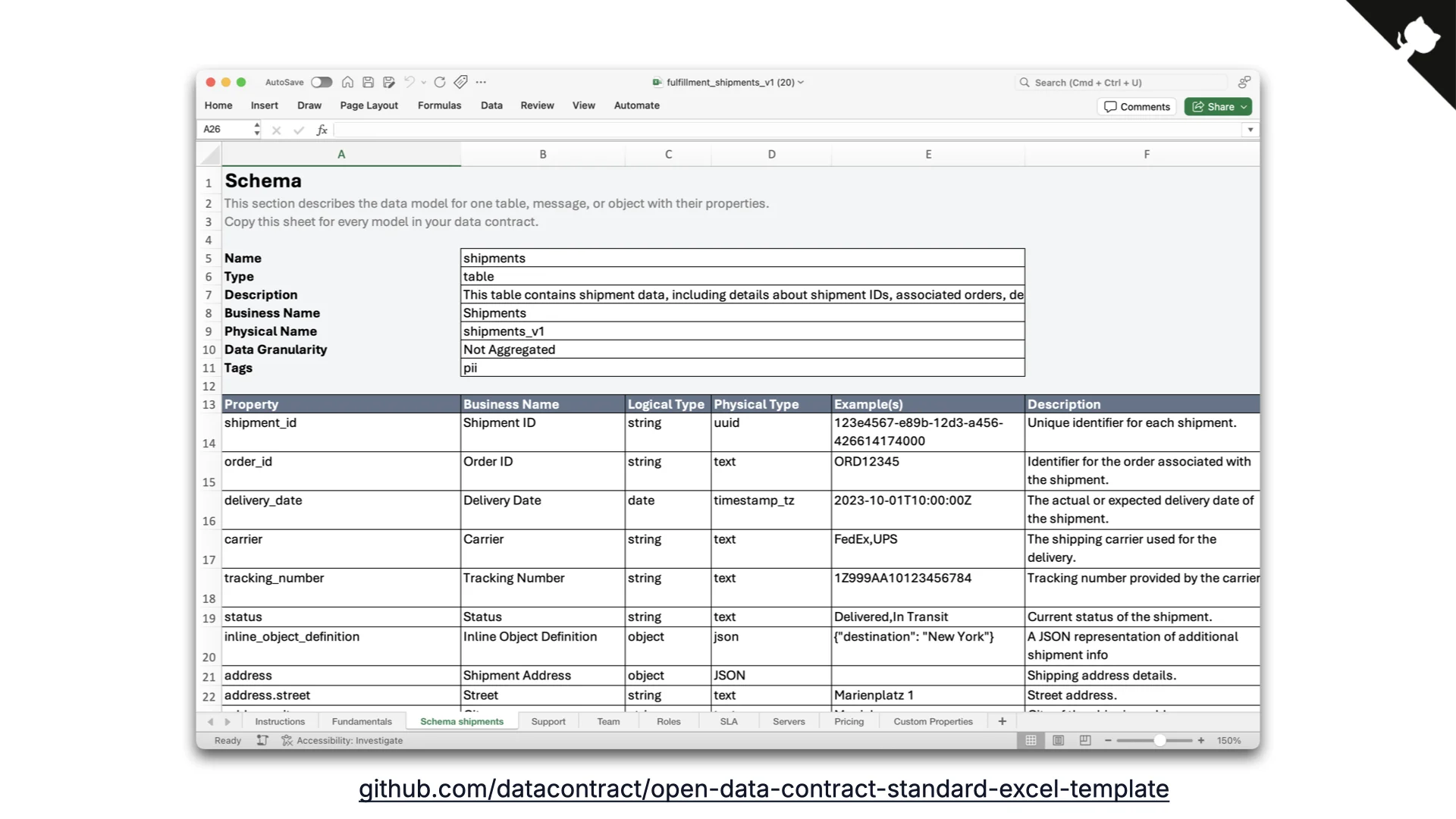
Writing YAML manually is a lot of work, so we built the Data Contract Editor. It allows filling in contracts through a form view, a diagram view, or the raw YAML -- with previews and validations built in. Crucially, this is where business and technical people can bridge: business thinks in columns and understands the data, tech fills in the missing physical details. Often business starts, tech completes.
For the even-more-business-people, we created an Excel template for ODCS. It is surprisingly popular. The CLI converts it into the proper YAML and processes it further.
Open standard + open-source editor + automation tooling + an Excel template -- you get that package for free, no pay wall, just use it.
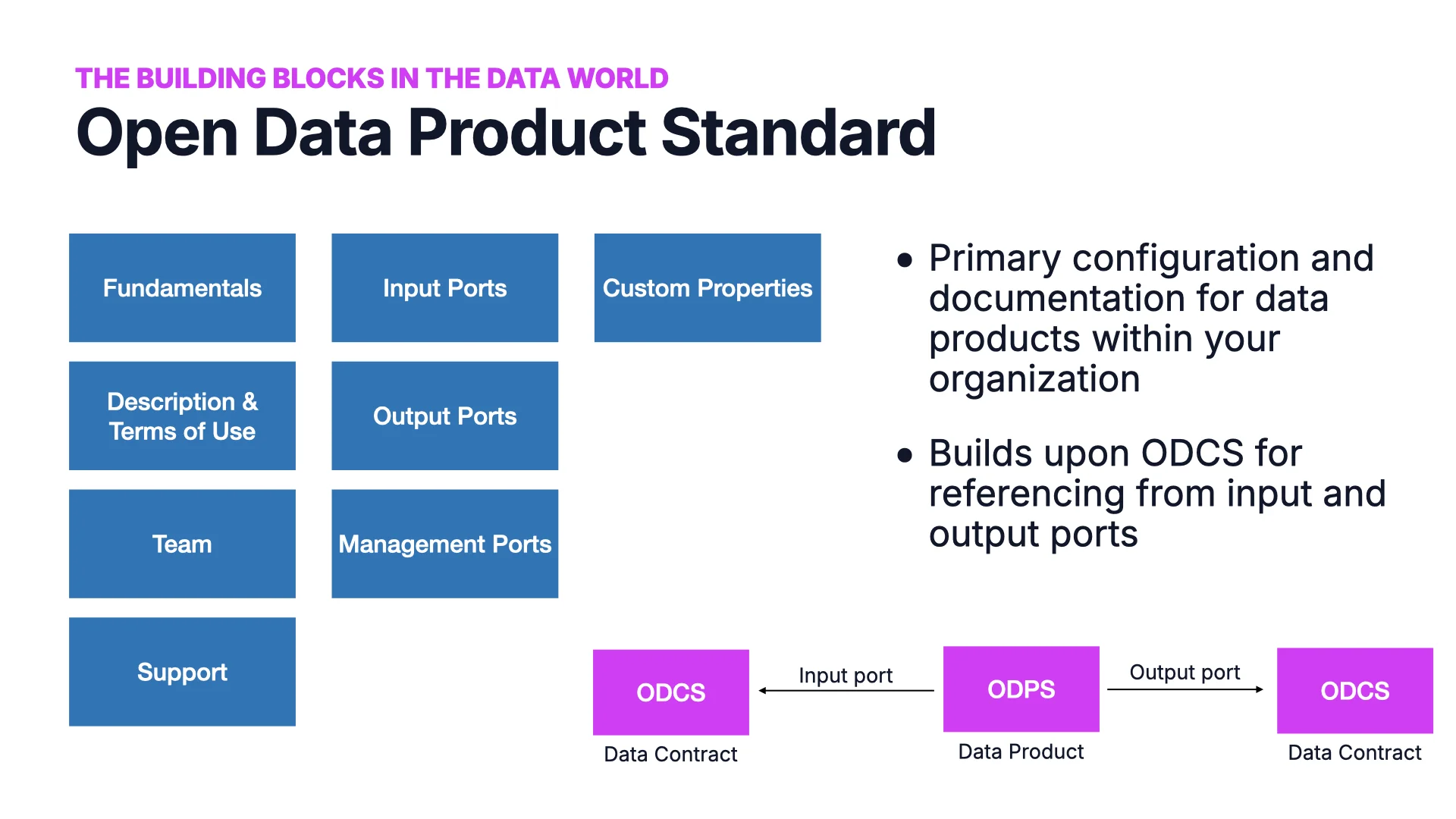

The Open Data Product Standard (ODPS)
Contracts are one key aspect. Data products are the other. The BITOL project's Open Data Product Standard (ODPS) mirrors ODCS on fundamentals, terms of use, team, support, and custom properties. The key difference: input ports, output ports, and management ports. Each port links to an ODCS data contract.
Because ODPS builds on ODCS, if you already have contracts the data product file is short. A typical one has a name, description, version, and a few ports -- e.g., one Kafka input port v1 and four Snowflake output ports for PII / non-PII in v1 and v2. That is it. Together they form the graph of your data mesh.

From YAML to a Living Mesh Graph
Because every data product declares its input and output ports in ODPS, and every port references an ODCS contract, you get a complete dependency graph for free. Source applications feed into data products; data products feed into other data products or straight into consumer use cases like funnel analytics, monthly target reports, or realtime user classification.
That is the whole point: the standard is what lets the graph exist. Visualise it and you have your data mesh map -- derived entirely from contract and product YAML files, not drawn by hand.

But Be Aware When You Claude It
There is real confusion in this space. Two different projects at the Linux Foundation share the same acronym: ODPS stands for both "Open Data Product Standard" (the one I have been describing, part of BITOL) and "Open Data Product Specification" (a separate standalone project). When you search -- or ask Claude -- you have to know which one you are reading.
The mental models are different. The BITOL Standard models data products with multiple input ports, multiple output ports, and links to many ODCS contracts -- it is designed as a composable family of standards. The Specification has no concept of input ports and allows at most one linked contract at the top level; it is strong on pricing plans and internationalisation, which makes it a better fit if you run an external marketplace with complex commercial terms.
Neither one is wrong -- they just solve different problems with the same name. I am in the BITOL camp because I care about the family of standards composing together. That is my bias; yours may differ.
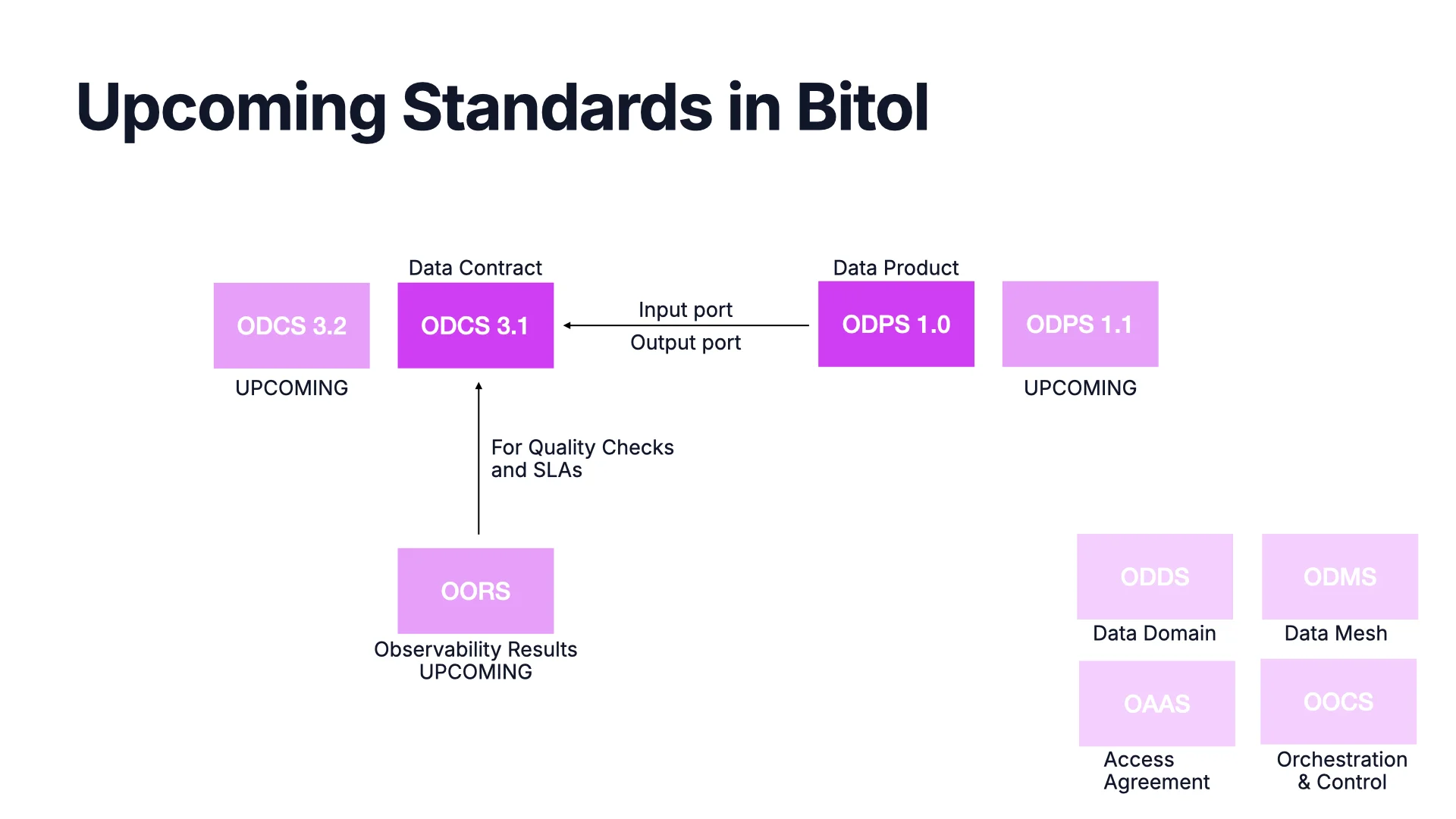
What's Next in the BITOL Family
ODCS 3.1 and ODPS 1.0 are the core standards today. Minor versions later this year focus mostly on adding more AI context -- metadata that agents can use for data discovery and query generation.
Around the core we are drafting auxiliary standards: OORS for observability results (what does a quality-check result look like?), OAAS for access agreements and request-access workflows, ODDS for data domains, ODMS for data mesh, and OOCS for orchestration and control. The core stays core; the auxiliaries cover the edges every marketplace has to encode somehow.
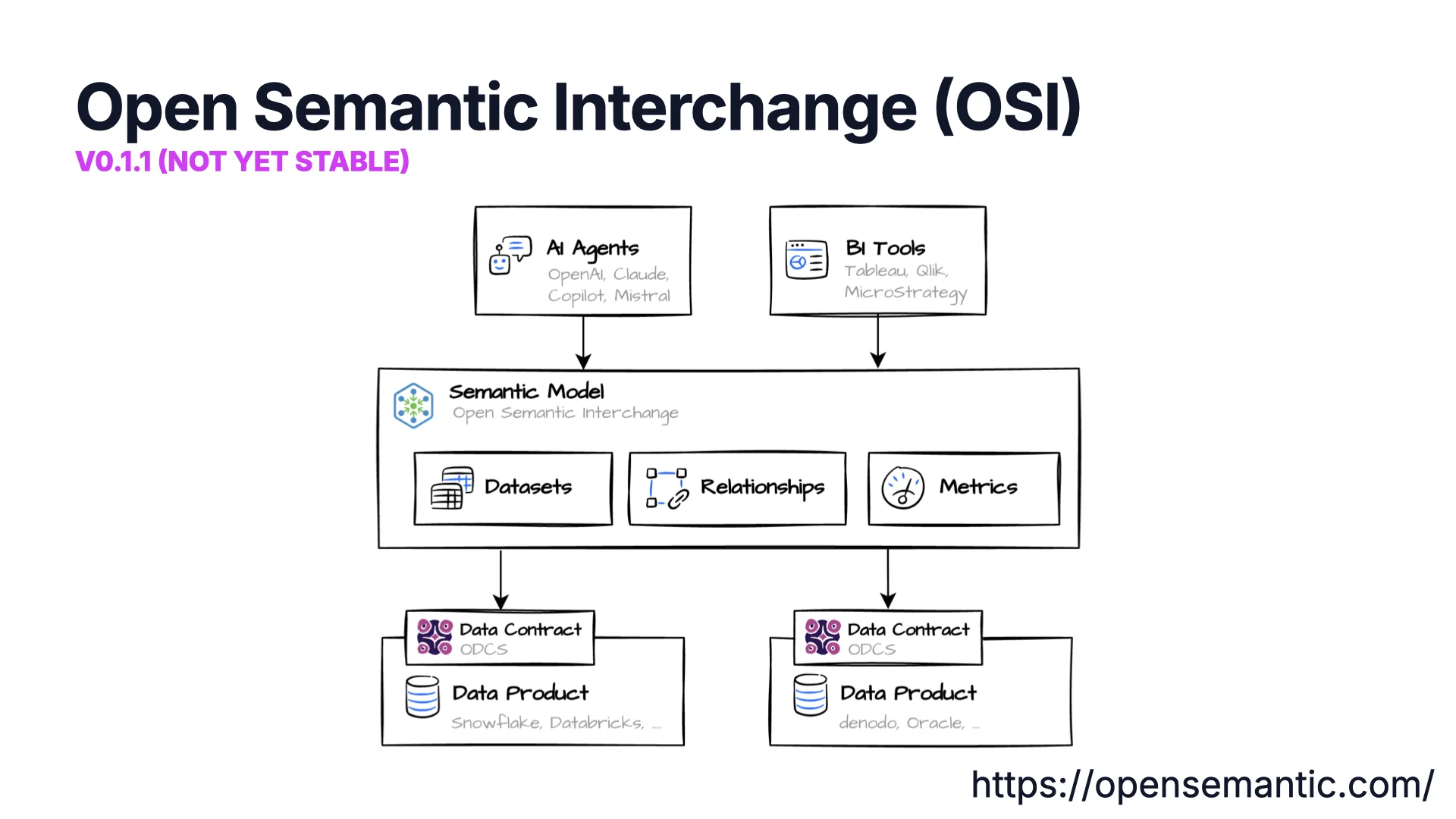

Open Semantic Interchange (OSI)
Again we have an acronym collision -- OSI is also the networking layer model you learned in CS class. This one is the Open Semantic Interchange, an initiative pushed by Snowflake with many other companies. It is version 0.1.1 and explicitly not yet stable, but the working groups are very active.
The core idea: on top of your data products and contracts, you build a semantic model with datasets, relationships, and metrics -- similar to the Power BI semantic model. Then OSI adds "AI sprinkles": instructions, synonyms, and examples so AI agents and BI tools can work with the data correctly.
Compared to ODCS, the two overlap on datasets, relationships, and custom extensions. OSI adds metrics (e.g., total_revenue = SUM(order_total)) and dynamic fields (e.g., full_name = first_name + " " + last_name). ODCS has what OSI currently lacks: terms of use, quality checks, and SLAs. AI context is the interesting overlap -- everyone wants it, and that is where both are evolving.
Ontology, composability, and tooling working groups are all active. My colleague and co-founder Jung is heavily involved there too. This is one to watch.
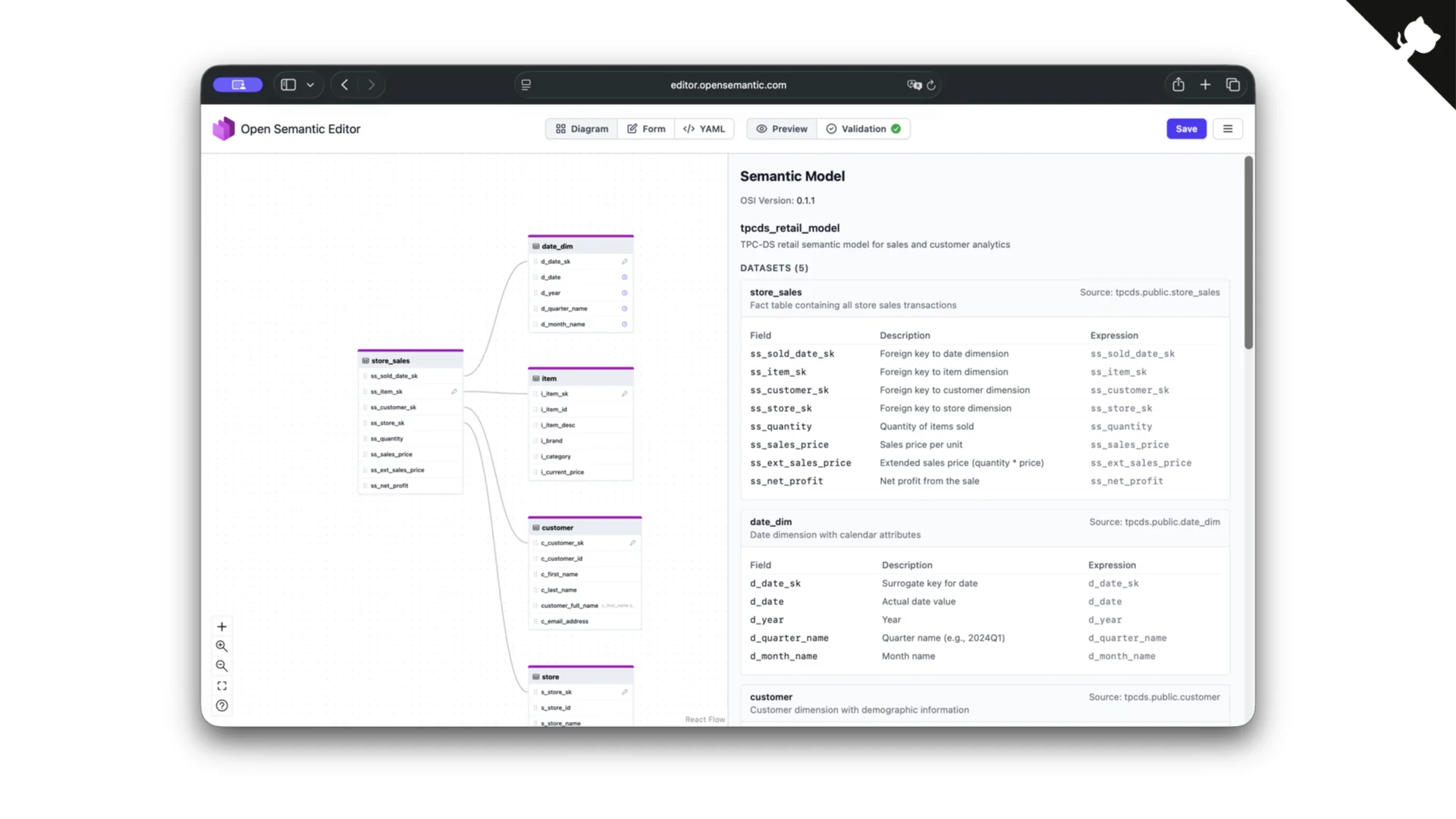
An Editor for Semantic Models
Because an OSI model still looks a lot like a contract -- tables, foreign keys, relationships -- we built a small open-source editor for it too, available at editor.opensemantic.com (source on GitHub). Same pattern as the Data Contract Editor: diagram, form, and YAML views, with a preview and validation.
To be honest, Claude Code built most of it for us in an afternoon. That is possible now precisely because the underlying format is an open standard the model already understands.

And a Lot of Power Behind It
OSI is still 0.1.1, but the working groups behind it are serious:
- Advanced Metrics & Expression Language — beyond the basics you saw above.
- Composability — how OSI models reference and compose each other.
- Catalog Integration — hooking into the enterprise data catalog layer.
- Ontology Representation — concepts and properties as a graph. My co-founder Jochen Christ is deeply involved here.
- Model converters & developer tools — where the ecosystem story actually gets built.
When you look at the membership list -- Snowflake, Databricks, Tableau, MicroStrategy, and many others -- there is a lot of power behind this one. It is worth watching.
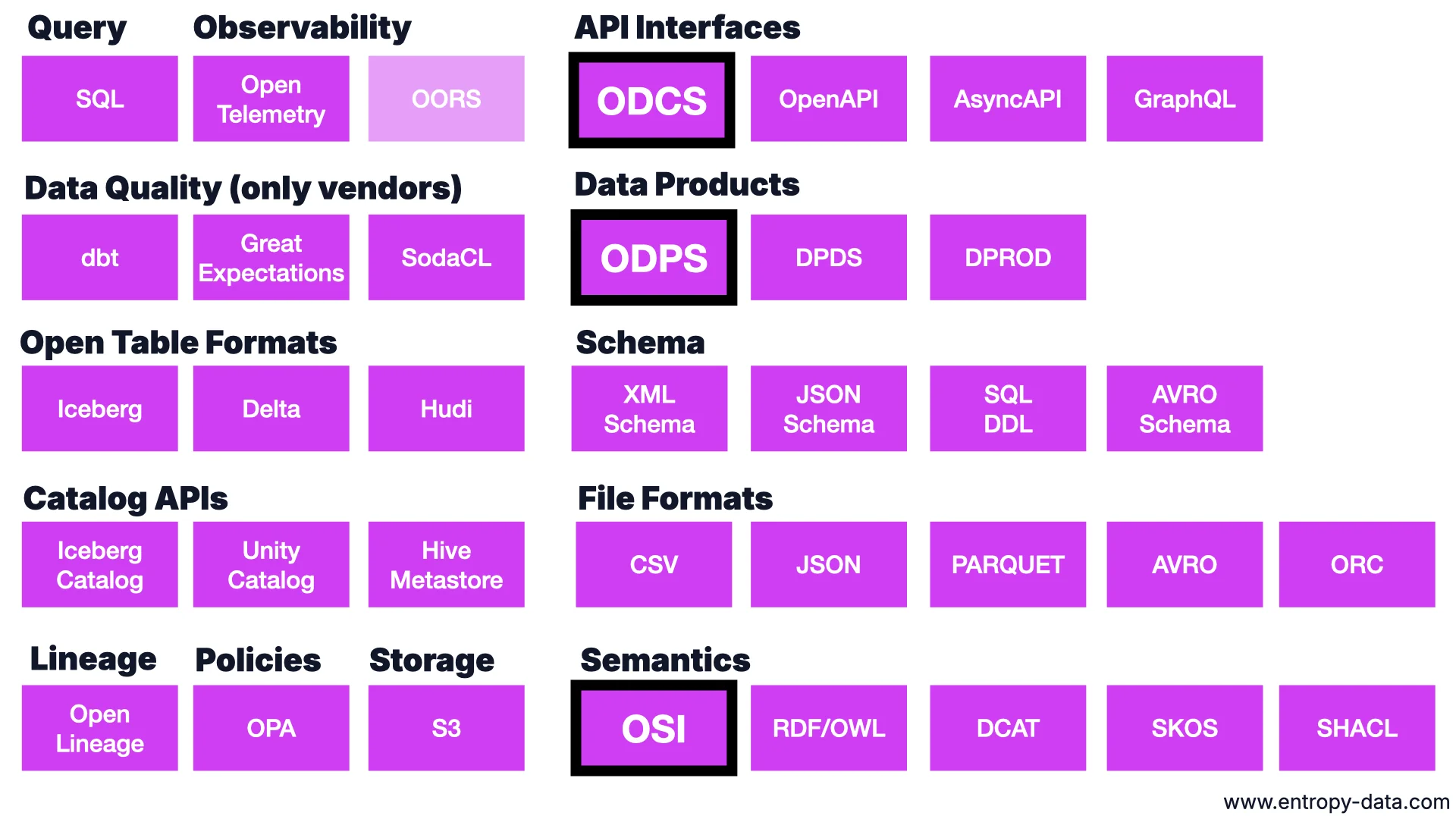
The Broader Landscape
Today I covered ODCS, ODPS, and OSI, but the map is much larger: API interfaces (OpenAPI, AsyncAPI, GraphQL), schemas (XML, JSON, SQL DDL, Avro), file formats (CSV, JSON, Parquet, Avro, ORC), open table formats (Iceberg, Delta, Hudi), catalog APIs (Iceberg Catalog, Unity Catalog, Hive Metastore), lineage (OpenLineage), policies (OPA), observability (OpenTelemetry, OORS), data quality (dbt, Great Expectations, SodaCL), and semantics (OSI plus RDF/OWL, DCAT, SKOS, SHACL).
What unites the ones I highlighted: they are open, not controlled by a single company, backed by a committee, with open-source tooling around them. A data mesh is built on many standards, and more are coming.

The Prediction
Swagger 1.0 was released in 2011. Today OpenAPI is everywhere -- every REST API you touch has it. 99% adoption, de facto.
ODCS 3.0 -- the first release not tied to PayPal's specifics, the first truly usable-by-any-enterprise version -- was released in 2025. My assumption is that this goes much faster than OpenAPI did, because the world moves much faster now.
My prediction: ODCS will be everywhere in four years. Be prepared.
Thank You
Thanks for the warm welcome in Leuven, and thanks to Tom De Wolf (ACA) and Emma Houben (AE) for inviting me and organizing a great evening.
If you want to continue the conversation, find me on LinkedIn, at simonharrer.com, or at simon.harrer@entropy-data.com. Try the contract-based data product marketplace at www.entropy-data.com, and please give datacontract-cli a star on GitHub if it helps you.
Q&A
Selected questions from the audience after the talk.
Q: If you have many data contracts coming from the same source, and you have to maintain and modify the same quality checks across all of them, how do you handle that?
The best approach is to push the quality check upstream -- as close to the source system as possible -- so you catch errors early and do not have to run the same expensive checks repeatedly down the graph. If that is not possible, one answer is AI: with agents like Claude Code it is relatively cheap to keep related checks consistent across contracts, and that is not as cheeky as it sounds. Beyond that, the pattern we typically use is linking from the contract to a semantic model. You define order_id once -- description, type, format ("starts with 053") -- and inherit it everywhere. Bonus: because two contracts point to the same order_id concept, the AI knows those tables can be joined. Same thing, not similar.
Q: How does OSI relate to DCAT?
Today they are not related. DCAT lives in the RDF / semantic-web world as a catalog vocabulary, inspired by libraries and dataset offerings. There is a working group in OSI to add semantics -- concepts and properties, essentially a graph encoded in YAML -- which will bring the two closer, but I don't think they will ever fit perfectly. DCAT composes naturally in RDF with other vocabularies (DPROD from OMG, for example). YAML formats like OSI are more strict. The format choice has consequences.
Q: You mentioned automating transformations using the data contract. Can you give an example? My understanding is that the contract does not capture transformation logic.
Correct -- the contract is targeted at the consumer, not the implementation. It captures a few transformation hints (where a column comes from, a short description), but it is deliberately limited. You can always use ODCS's custom properties to encode what you need. What we see working very well in practice: hand Claude Code the input and output contracts plus a skill like "this is how we typically build a Databricks data product" and let it fill in the blanks. Add semantic links pointing to the same concepts across contracts and AI figures out the joins too. For actual runtime lineage details -- how the pipeline really works -- use OpenLineage traces. That is what captures column-level lineage, not the contract.