Talk
Data Contracts: What They Are, Why They Matter, and How to Use Them
Jochen Christ, Co-Founder & CTO @ Entropy Data · 12. März 2026
In diesem Vortrag beim TDWI Roundtable Münster erkläre ich, was Data Contracts sind, wie sie sich mit API-Spezifikationen in der Softwarewelt vergleichen lassen und warum sie für das Management von Daten über Teams hinweg unverzichtbar geworden sind. Wir gehen ein konkretes Beispiel mit dem Open Data Contract Standard (ODCS) durch, diskutieren Contract-First- vs. Data-First-Ansätze, erkunden Tools wie die Data Contract CLI und den Data Contract Editor und schauen uns an, wie Data Contracts zur Governance-Ebene für KI-Agenten werden, die auf Unternehmensdaten zugreifen.

Hinweis: Der Vortrag wurde auf Deutsch gehalten. Das Transkript unten basiert auf der Originalaufnahme. Transkribiert und zusammengefasst mit KI.
Danke an TDWI für die Ausrichtung des Roundtable Münster und an Bodo Hüsemann für die Gastgeberrolle bei x1F.

Einführung
Hallo zusammen, ich bin Jochen, aus Ansbach bei Nürnberg. Heute sprechen wir über Data Contracts —ein Thema, das sehr beliebt geworden ist. Wir schauen uns an, was ein Data Contract ist, gehen ein paar Beispiele durch, erkunden die Tools, die du verwenden kannst, und diskutieren, warum Data Contracts zu einem so wichtigen Thema geworden sind.
Ich bin bei Entropy Data, einem Spin-off von INNOQ. Unser Kerngeschäft ist die Entwicklung von Software für das Management von Datenprodukten mit Data Contracts —eine Plattform für Metadaten-Management. Wir pflegen außerdem zwei Open-Source-Tools: den Data Contract Editor, eine Web-UI für die Arbeit mit Data Contracts, und die Data Contract CLI, zum Testen von Data Contracts.
Mein Hintergrund ist Software Engineering —Java ist meine Muttersprache. Vor etwa fünf Jahren sind wir in die Datenwelt eingetaucht und haben uns gefragt, was das nächste große Ding in der IT sein würde. Cloud war durch, ereignisgesteuerte Architekturen waren durch, Domain-Driven Design war überall. Wir kamen zu dem Schluss, dass Daten und KI den größten Einfluss haben würden. Das führte uns zu Data Mesh und schließlich dazu, Zhamak Dehghanis Data-Mesh-Buch für O'Reilly ins Deutsche zu übersetzen.

Wo sind eure APIs?
Aus der Softwarewelt kommend war das Erste, was wir Datenleute immer gefragt haben: „Wo sind eure APIs?" Die Antwort war immer: „Schau in den Datenkatalog." Also haben wir nachgeschaut —und zuerst nichts gefunden, und als wir etwas fanden, haben wir es nicht verstanden.
Dann veröffentlichte PayPal das erste Data-Contract-Template. Uns gefiel die Idee, aber wir fanden, sie könnte näher an OpenAPI/Swagger sein. Wir machten einen Vorschlag, und schließlich taten wir uns zusammen, um das BITOL-Projekt unter der Linux Foundation zu gründen, wo wir nun den Open Data Contract Standard (ODCS) verwalten und weiterentwickeln.
Ich bin Mitglied im Technical Steering Committee. Wenn also etwas fehlt oder keinen Sinn ergibt —sagt es uns, und wir können es besser machen.
Ein YAML-Dokument —wie OpenAPI, aber für Daten
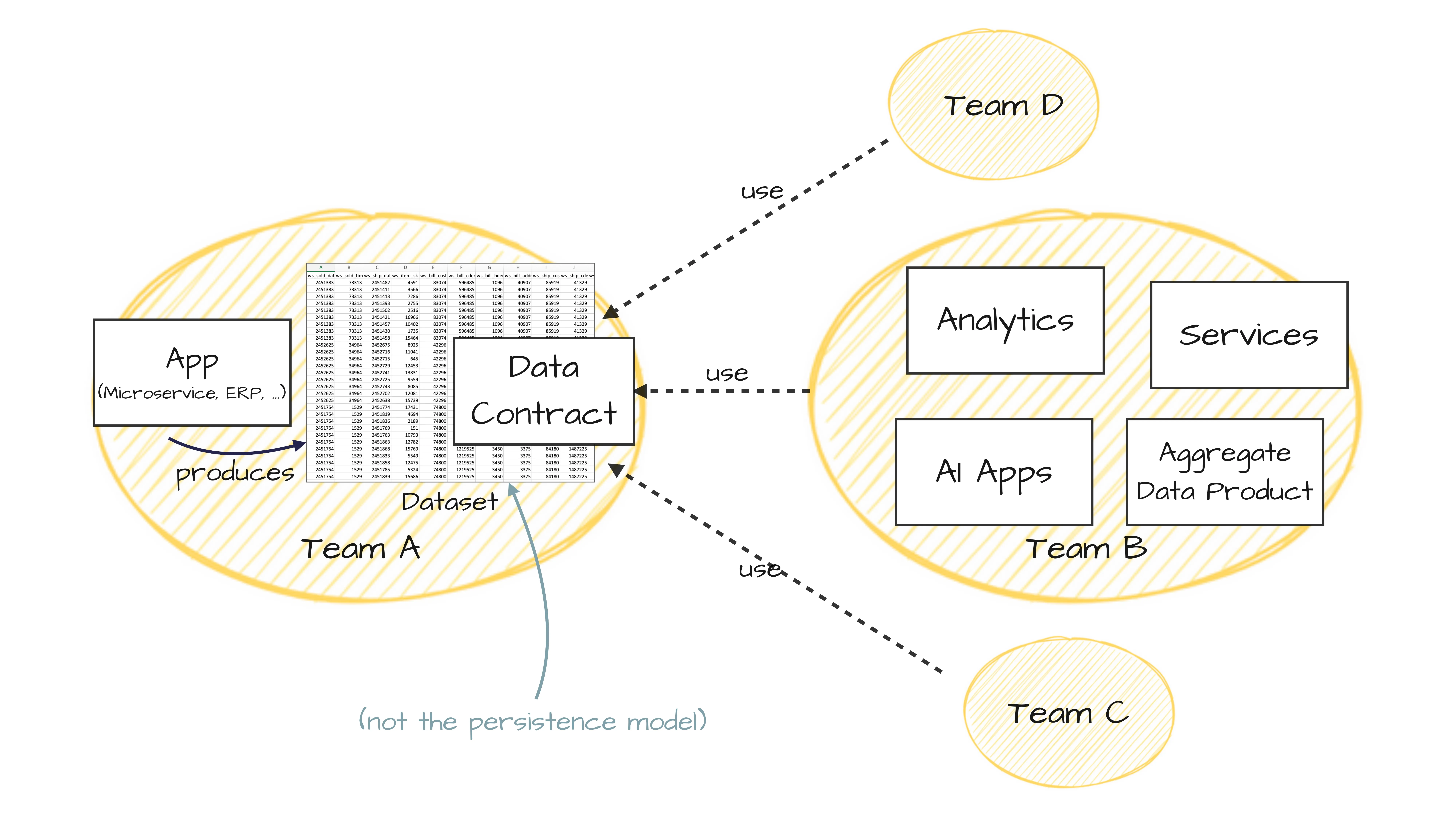
Ein Data Contract ist, Überraschung, ein YAML-Dokument. Warum YAML? Wegen Kubernetes —in Kubernetes ist alles YAML. Und OpenAPI/Swagger ist auch ein YAML-Dokument. Es beschreibt, was einen Datensatz ausmacht, den ich mit anderen teilen möchte.
In einem Data-Mesh-Kontext hast du ein Team, das für einen Datensatz verantwortlich ist —das Team, in dem die Daten ursprünglich entstehen, zum Beispiel in einem Microservice, einem ERP-System oder einer Fachlichkeit. Dieses Team übernimmt die Ownership für das Datenprodukt, das mit anderen Teams geteilt wird. Andere Teams wollen darauf zugreifen, für Analytics, zum Bauen von Services, für KI-Anwendungen oder zum Erstellen aggregierter Datenprodukte.
Der Data Contract definiert die Schnittstelle zu den Consumers. Er ist relevant, wenn Daten über Teams und Organisationseinheiten hinweg ausgetauscht werden. Wichtig: Das ist eine Nutzungsbeziehung, keine ETL-Pipeline. Andere Teams greifen auf meine Daten zu oder konsumieren sie. Konzeptionell ist das eine Nutzungsabhängigkeit, die sich von klassischen Datenpipelines unterscheidet.
Und für Software Developers, die nervös werden, wenn sie eine Datenbanktabelle sehen: Ich meine ausdrücklich nicht, die Oracle- oder Postgres-Datenbank direkt freizugeben. Es gibt immer einen Anti-Corruption-Layer, eine View, die das Datenmodell vom operativen System entkoppelt.
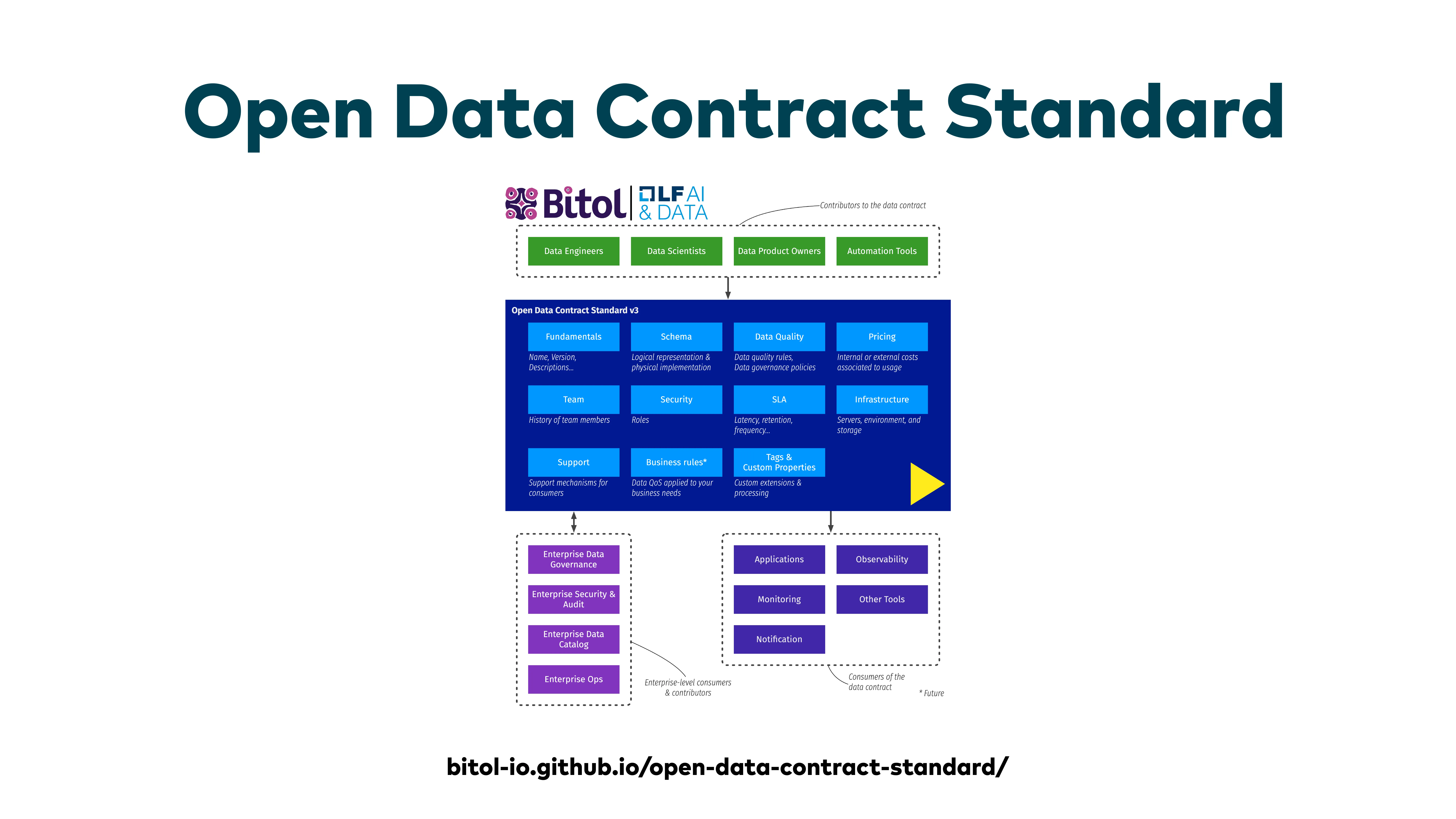
Der Open Data Contract Standard (ODCS)
ODCS ist mittlerweile, glaube ich, der Industriestandard, auf den sich alle geeinigt haben. Collibra, OpenMetadata, IBM —alle großen Metadaten-Anbieter setzen auf ODCS. Bitte: Wenn ihr Data Contracts einführt, erfindet kein proprietäres Format. Nutzt ODCS, damit ihr das Ökosystem und die Tools nutzen könnt und interoperabel mit Metadaten-Ebenen und Datenkatalogen bleibt.
Letztes Jahr wurde außerdem die Open Data Product Specification (ODPS) bei der Linux Foundation geschaffen. Ein Datenprodukt ist das System oder Modul, das die Daten erzeugt —mit Input Ports, einer Pipeline, Tests, Metadaten, Dokumentation —und am Ende über einen Output Port einen Datensatz mit einem bestimmten Data Contract anbietet. Das Datenprodukt ist das System; der Contract ist die Schnittstellenspezifikation für den finalen Datensatz.

Zwei Ansätze, um Data Contracts zu bauen
Data First ist der häufigste Ansatz. Du hast bereits eine Tabelle oder ein Schema in deinem Data Warehouse. Jetzt willst du einen Contract hinzufügen: ihn dokumentieren, beschreiben, Qualitätsattribute festlegen, damit deine Consumers verstehen, was der Datensatz ist. Du legst einen Contract über bestehende Daten.
Contract First ist seltener, aber sehr mächtig. Du startest von den Anforderungen deiner Business-User und Consumers. Welche Daten brauchen sie wirklich? Wie sollte das Datenmodell aussehen, um ihre Use Cases zu bedienen? Dann designst du das Datenprodukt passend zu diesen Anforderungen. Das führt zu kleineren, fokussierteren Datenprodukten statt zu Tabellen mit 10.000 Spalten, weil niemand etwas wegwerfen wollte.
Ein wichtiger Hinweis: User können kein YAML lesen oder schreiben. Wir schauen uns Tools an, die das viel zugänglicher machen —inklusive Excel-Templates.

Walkthrough: Ein Orders-Data-Contract
Gehen wir ein konkretes Beispiel durch. In einem Webshop verwaltet ein Checkout-Team Bestell- und Kundendaten. Ein Recommendations-Team will ein Machine-Learning-Modell bauen. Also machen wir einen Contract-First-Workshop mit Sophia, der Data Scientist:
„Als Data Scientist will ich alle Webshop-Bestellungen der letzten fünf Jahre, damit wir wissen, welche Artikel oder Kategorien von einem Kunden zusammen gekauft wurden, sodass wir ein Empfehlungsmodell für den Webshop und Marketing-E-Mails bauen können."
Ownership ist der schwierigste Teil. Welches Team übernimmt die Verantwortung, den Bestelldatensatz bereitzustellen? Diese Ownership-Frage ist oft 50% der Arbeit. Wir haben Workshops abgesagt, in denen niemand bereit war, das Datenprodukt zu besitzen. Ohne Ownership ist alles andere —Semantik, Qualität, Service Levels —hinfällig.

Schema, Semantik und Beispiele
Das Herzstück eines Data Contracts ist das Datenmodell. Du definierst Schemas mit Tabellen und Spalten. Aber es sind nicht nur technische Informationen —es gehören auch Business-Namen und Beschreibungen dazu, die ein Business-User verwenden würde. Sagen sie „Order ID", „Bestellnummer" oder „Order Number"? Wir erfassen sowohl den technischen Namen als auch den Business-Namen.
Diese semantische Beschreibung kann KI nicht für dich generieren. Du bekommst sie nur, indem du mit deinen Domänenexperten sprichst, zuhörst, wie sie miteinander reden, und es aufschreibst. Das ist die beste Quelle für gute Metadaten.
Beispiele sind entscheidend. Wir schreiben in Workshops absichtlich leicht falsche Beispiele, weil Menschen es lieben, Dinge zu korrigieren. Ein Domänenexperte wird sagen: „Vier Nachkommastellen? Das kann nicht stimmen." Und dann findest du heraus, ob Beträge in Dollar, Euro, als Integer in Cent oder als Double gespeichert werden. Die typischen Fragen, die schon immer Schmerzen bereitet haben.
Wenn niemand deine Beispiele korrigiert, ist dein Publikum eingeschlafen.

Qualitätsregeln
Qualitätsregeln können zunächst als reiner Text erfasst werden —eine Beschreibung dessen, was Consumers erwarten. Zum Beispiel: „Das Lieferdatum sollte nicht mehr als 20 Tage in der Zukunft liegen." Erfasse zuerst die Business-Erwartungen, in natürlicher Sprache.
Dann wandle sie in SQL-Queries um. KI kann dabei helfen. Der wesentliche Teil ist das Erfassen der Business-Logik. Sobald du das SQL hast, kannst du damit die Datenqualität deiner Datenprodukte und Datensätze prüfen —ähnlich wie es Tools wie Great Expectations tun.

Die Geschichte von John und dem Consent-Filter
Eine Stunde im Workshop fällt John, dem Product Owner des Checkout-Teams, plötzlich ein: „Sorry, wir können euch nicht alle Bestellungen geben. Es gibt eine Consent-Einschränkung —nur etwa 80% der Bestellungen haben das Cookie-Consent für die analytische Nutzung."
Sophia, die Data Scientist, sagt: „Passt, Machine Learning ist sowieso unscharf, 80% reichen." Aber diese Information muss in den Data Contract —unter Einschränkungen. Dieser Datensatz ist für die analytische Nutzung freigegeben, aber nicht für Finanz-KPIs geeignet, weil er nur ~80% des Umsatzes abbildet.
Das sind genau die Einschränkungen, die du einfach nicht siehst, wenn du nur auf die Tabelle im Data Warehouse schaust. Du brauchst Metadaten im Contract, um sie zu erfassen.
Nutzungsbedingungen werden immer wichtiger —besonders für KI. Einem Agenten sagen zu können, was er mit einem Datensatz tun darf und was nicht und für welche Zwecke er geeignet ist, ist entscheidend für die Governance. Du kannst auch auf Standard-Policies wie die DSGVO, Datenklassifizierungs-Policies oder Marketing-Datenregeln verlinken.

Service Levels und nicht-funktionale Garantien
Ein Data Contract kann auch nicht-funktionale Aspekte enthalten: Verfügbarkeit, Latenz, Support-Zeiten, Aufbewahrung und Backup-Garantien. In jeder Session fragt jemand: „Kann ich diesen Datensatz für meinen operativen Microservice nutzen?" Die Antwort: Definiere die Garantien im Contract und lass den Consumer entscheiden, ob sie für seinen Use Case ausreichen.
Niemand würde einen Webshop mit einer Abhängigkeit von einem System mit nur 99,8% Verfügbarkeit bauen. Zumindest würde man einen Anti-Corruption-Layer oder eine asynchrone Entkopplung hinzufügen. Die SLA-Informationen im Contract helfen Consumers, diese Entscheidung zu treffen.

Warum der Name falsch ist —und warum er sich durchgesetzt hat
Eine Sache, die ein Data Contract nicht enthält, sind die Parteien —die Consumers. Wir haben den Owner, aber nicht, wer konsumiert. Im Wirtschaftsrecht ist ein Vertrag eine zweiseitige bindende Erklärung. Dieser zweiseitige Charakter fehlt hier. Es ist eigentlich eine Schnittstellenspezifikation.
Rechtlich gesehen ist es eher eine invitatio ad offerendum —eine Aufforderung zur Abgabe eines Angebots. Warum heißt es dann „Contract"? Weil PayPal den Begriff zuerst geprägt hat und der Name sich durchgesetzt hat. Er ist eingängig. Er ist einprägsam. Er ist nur technisch nicht korrekt.
Die zweiseitige Beziehung wird separat über Agreements in den Tools abgebildet —mit Startdaten, Enddaten und Lifecycle-Management. Dort lebt die 1:1-Beziehung zwischen Provider und Consumer.
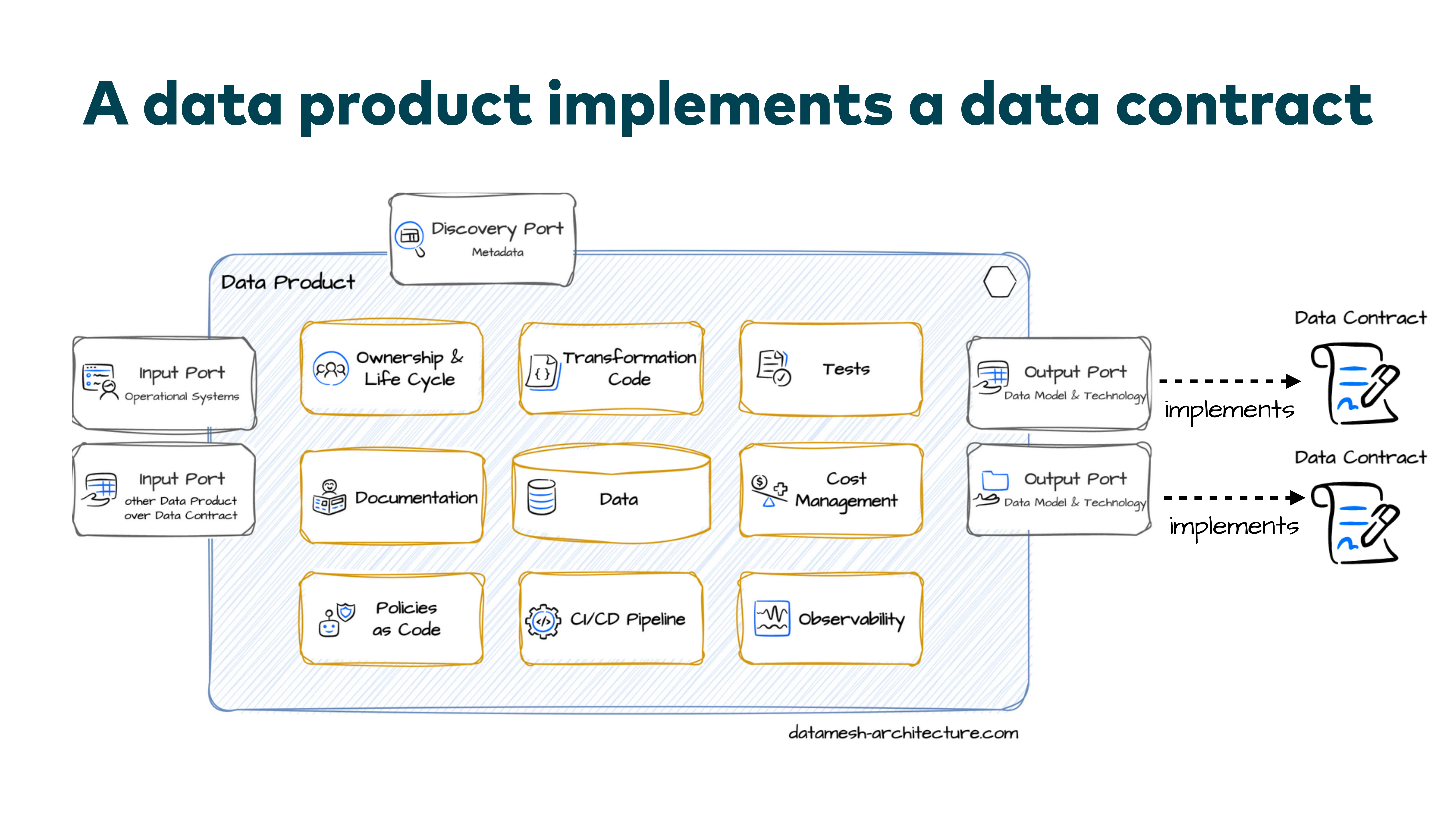
Datenprodukte und Data Contracts
Ein Datenprodukt hat einen privaten und einen öffentlichen Aspekt. Intern gibt es Pipelines, Transformationscode, Zwischentabellen, Rohtabellen, Tests. Am Ende stellst du einen bestimmten Datensatz bereit, den andere Teams konsumieren können —das ist der öffentliche Teil, der Output Port.
Der Data Contract beschreibt genau diesen Output Port. Das Datenprodukt ist das System auf der Plattform; der Contract ist die Schnittstelle, die beschreibt, wie die Daten aussehen und welche Garantien mit ihnen einhergehen. Sie sind eng gekoppelt.
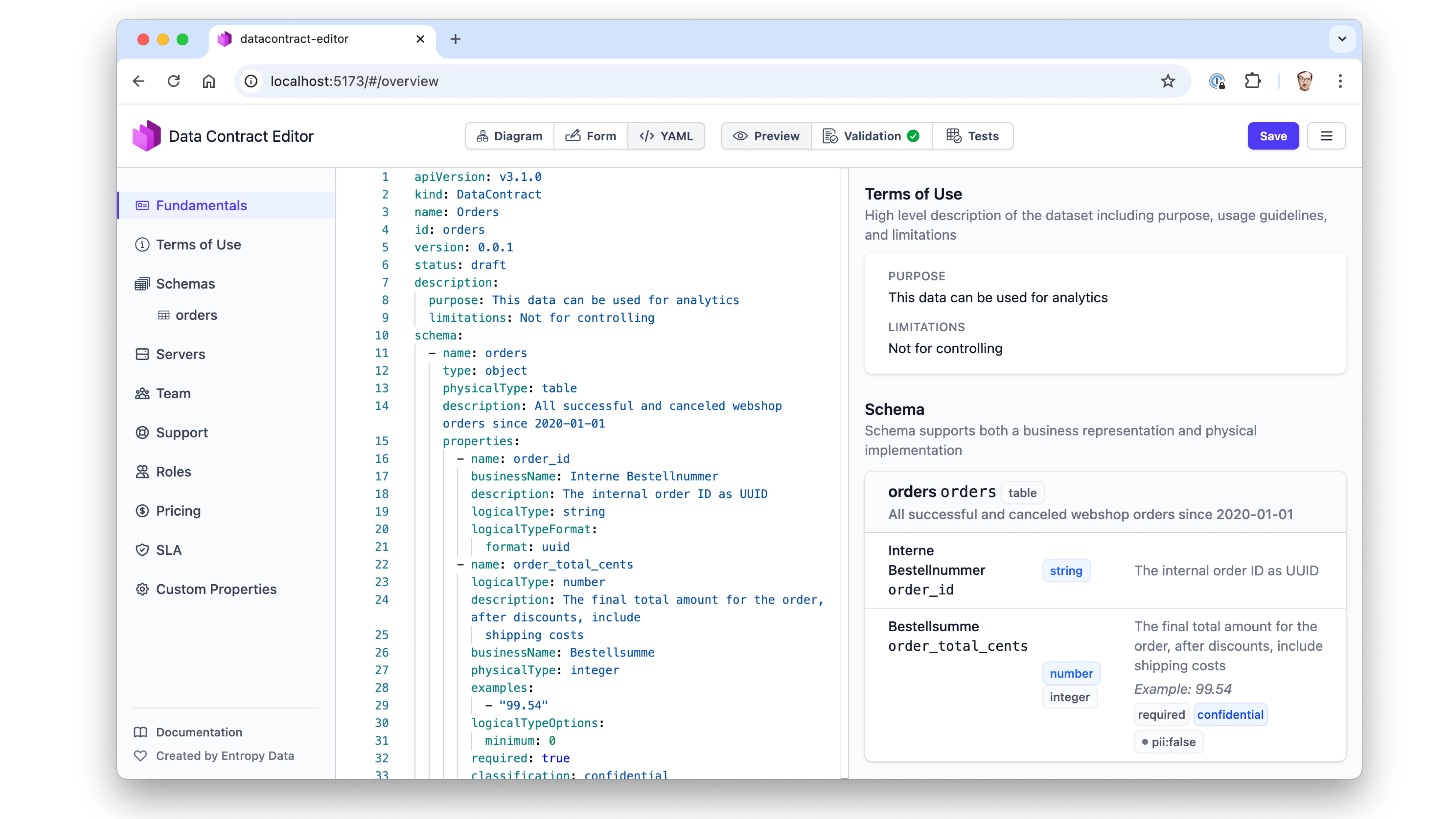
Data Contract Editor
Der Data Contract Editor ist eine Open-Source-Webanwendung, die du lokal als Docker-Container deployen kannst. Du kannst YAML direkt schreiben, aber du kannst auch Formulare nutzen, um Nutzungsbedingungen, Serverinformationen und Schema-Definitionen einzugeben. Er bietet visuelle Datenmodellierung —wie ER-Modellierung, ähnlich wie Innovator oder andere Tools, die man gewohnt ist.
Am Ende erzeugt er YAML. Du kannst als HTML vorschauen, auf Korrektheit validieren und Tests ausführen, um zu prüfen, ob das tatsächliche Datenprodukt hinter dem Contract zu seinen Definitionen passt.
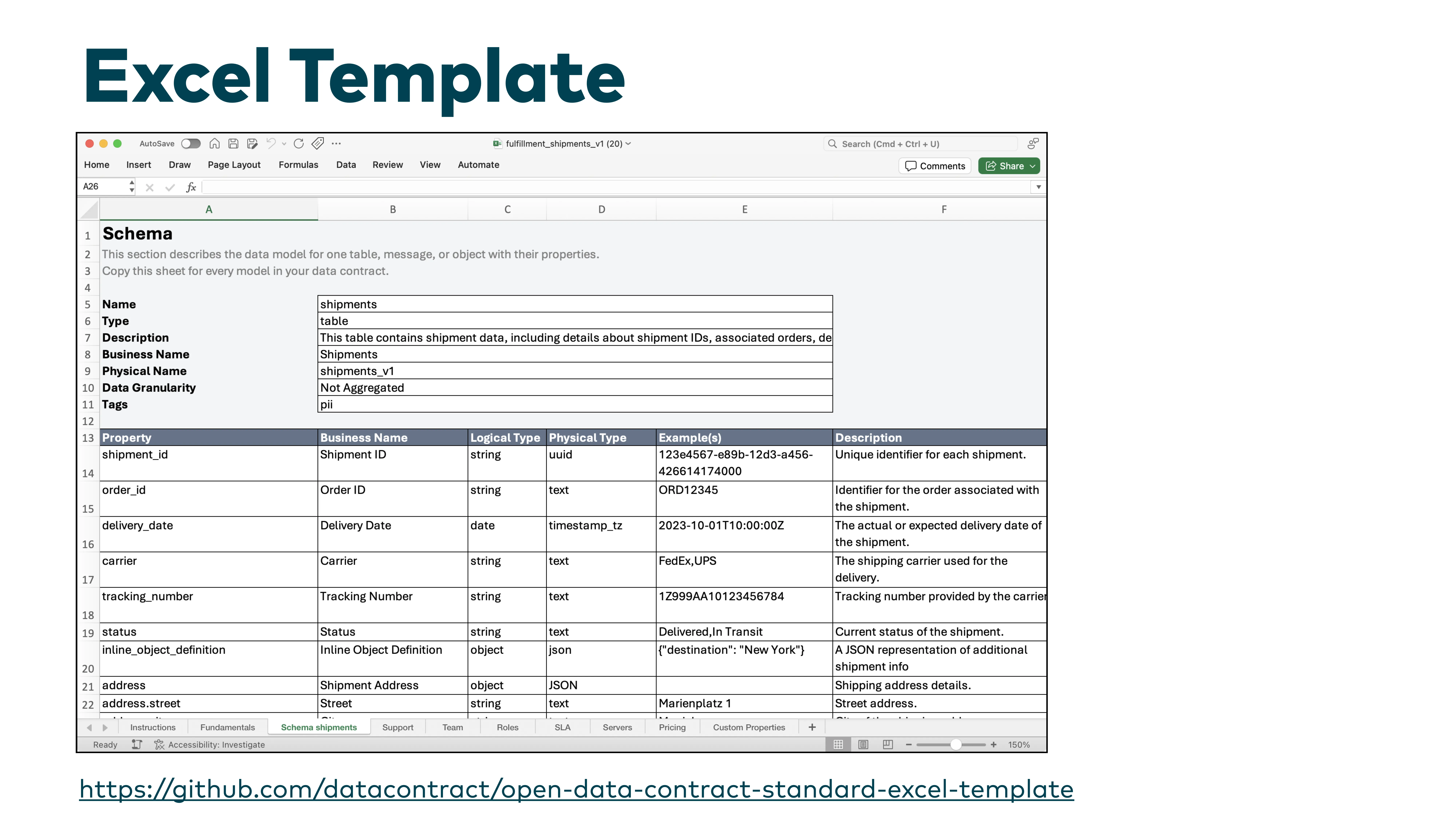
Excel-Template —Excel entkommst du nicht
Wir haben ein Excel-Template erstellt, weil mindestens drei Kunden sagten: „Alles super, aber wir haben Excel für die Arbeit mit unseren Business-Usern eingeführt." Als Informatiker fiel es schwer, das zu akzeptieren. Aber Excel bietet für viele Menschen immer noch die beste User Experience. Du kannst es per E-Mail herumschicken. Die Quelldaten liegen oft schon in Excel vor.
Das Template ist standardkonform und konvertiert in beide Richtungen von und zu YAML. Du wirst Excel nicht los —also mach wenigstens ein gutes Excel daraus.

Data Contract CLI und Pipeline-Integration
Die Data Contract CLI nimmt alle Informationen aus dem YAML —Feldtypen, Formate, Qualitätsregeln (als SQL oder Great Expectations) —verbindet sich mit der Datenbank und prüft, ob die Daten die Garantien des Contracts erfüllen. Sie führt für jeden Aspekt SQL-Statements aus und meldet pass/fail.
Wenn du das in deine Deployment-Pipeline integrierst —zum Beispiel in einen GitHub-Actions-Workflow —bekommst du mehr Vertrauen in deine Daten. Du kannst schnell reagieren, wenn etwas rot ist. Consumers können dieselben Checks auf ihren Input Ports ausführen, bevor sie ihre Pipelines starten.
Die CLI spricht mit allen großen Datenplattformen (BigQuery, Snowflake, Databricks, Postgres und mehr) und kann aus verschiedenen Formaten importieren/exportieren.

Kommunikation, Vertrauen und Auffindbarkeit
Kommunikation: Data Contracts geben dir ein strukturiertes Format, um Menschen zusammenzubringen —Data Producers und Data Consumers —um Datenanforderungen, Domänenwissen und Semantik zu diskutieren. Es leitet Gespräche durch die wichtigen Aspekte: Nutzungsbedingungen, SLAs, Qualitätsregeln. Unterschätze diesen Aspekt der Business-Transformation innerhalb der Organisation nicht.
Vertrauen: Daten werden nur genutzt, wenn Consumers das Gefühl haben, dass sie korrekt und vollständig sind. Vertrauen ist leicht verloren —nachdem die Pipeline zum dritten Mal kaputtgeht, glauben die Leute nicht mehr an die Daten. Du kennst das klassische Problem: ein KPI, drei verschiedene Werte. Welcher stimmt? Data Contracts helfen durch klare Semantik und automatisierte Qualitäts-Checks.
Auffindbarkeit: Wenn du Data Contracts und Data-Product-Spezifikationen zentral sammelst, bekommst du einen mächtigen Überblick über alle verfügbaren Daten in deiner Organisation. Anders als traditionelle Datenkataloge, die jede Roh- und Zwischentabelle scannen, zeigt ein Datenmarktplatz auf Basis von Datenprodukten nur verwaltete, kuratierte Datensätze, die zur Nutzung gedacht sind —weit weniger Artefakte, deutlich höhere Qualität.
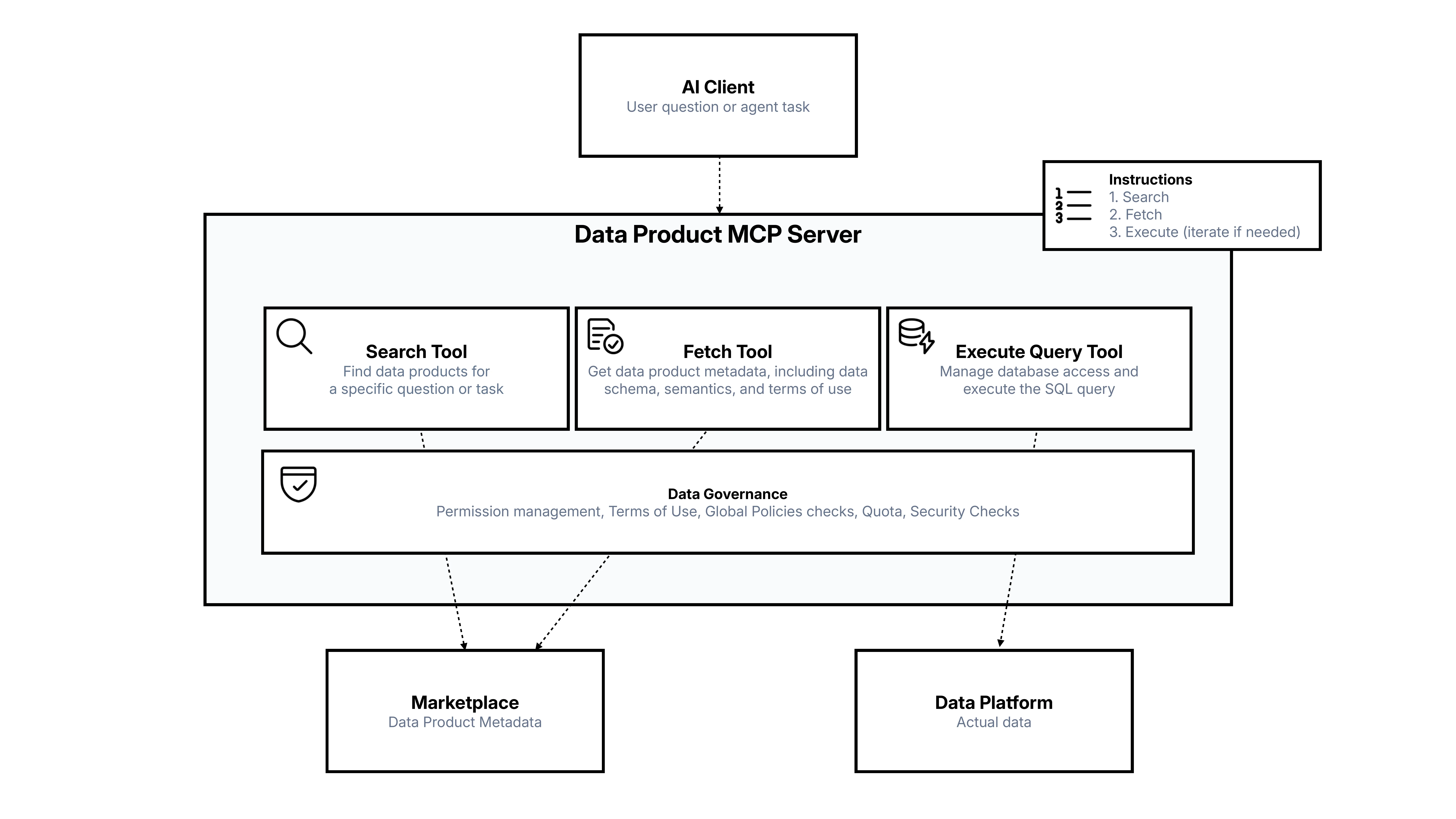
Agenten brauchen Unternehmensdaten —und Governance
KI-Clients —ChatGPT, Claude, autonome Agentensysteme —können „Wie weit ist die Erde vom Mond entfernt?" ohne Unternehmensdaten beantworten. Aber für sinnvolle Business-Aufgaben brauchen sie Zugriff auf die Daten deiner Organisation: Kundendaten, Bestellungen, Finanzen.
Um das sicher zu ermöglichen, brauchen Agenten mehrere Tools:
- Search —entdecken, welche Datenprodukte existieren (Kundendaten, Bestellungen usw.).
- Evaluate —bewerten, ob Semantik und Datenmodelle zur Frage passen.
- Query —aus dem Schema kann eine KI automatisch SQL schreiben und die Daten abfragen.
- Governance —steuern, welche Agenten Zugriff haben, Identität verifizieren (User-Kontext vs. Service Account), Nutzungsbedingungen durchsetzen, globale Policies anwenden und Sicherheits-Checks ausführen.
Genau diese Architektur setzen wir mit unserem Entropy Data MCP Server um. Ein Agent stellt eine Business-Frage, der MCP-Server durchsucht den Datenmarktplatz, holt den Data Contract mit seinen vollständigen Metadaten, evaluiert das Schema, fordert Zugriff an und generiert SQL. Der Data Contract —mit seinen Nutzungsbedingungen, Qualitätsregeln und Semantik —wird zur Governance-Ebene, die das sicher und kontrolliert macht.

Zusammenfassung
Data Contracts sind das fehlende Teil für das Management von Daten über Teams hinweg. Sie bringen die Strenge von API-Spezifikationen in die Datenwelt: Schema-Definitionen, semantische Beschreibungen, Qualitätsregeln, Nutzungsbedingungen und Service Levels —alles in einem standardisierten, maschinenlesbaren Format.
Mit Tools wie der Data Contract CLI, dem Data Contract Editor und sogar Excel-Templates ist das Ökosystem reif genug für die Adoption heute. Und während KI-Agenten zunehmend Zugriff auf Unternehmensdaten brauchen, werden Data Contracts zur unverzichtbaren Governance-Ebene, die das möglich macht —sicher und in großem Maßstab.
Wenn du das Gespräch fortsetzen möchtest, findest du mich auf LinkedIn oder besuche www.entropy-data.com.
Q&A
Ausgewählte Fragen aus dem Publikum während des Vortrags.
F: Kann ich denselben Datensatz in verschiedenen Granularitäten verwenden —z. B. aggregiert vs. roh? Wie gehe ich mit Varianten um?
Konzeptionell sind das unterschiedliche Data Contracts. Jede Variante —andere Granularität, anderes Format —bekommt ihren eigenen Contract. Du kannst sie verlinken oder als verwandt taggen, aber logisch sind es separate Schnittstellen mit separaten Garantien.
F: Kann ich Data Contracts für den operativen Datenaustausch zwischen Microservices nutzen, nicht nur für analytische Daten?
Ja, definiere die nicht-funktionalen Garantien —Verfügbarkeit, Latenz, Support-Zeiten —im Contract. Dann kann der Consumer entscheiden, ob diese Garantien für seinen operativen Use Case ausreichen. Ein Webshop würde niemals von einem System mit 99,8% Verfügbarkeit abhängen, ohne einen Anti-Corruption-Layer oder eine asynchrone Entkopplung hinzuzufügen.
F: Wie formalisiert ihr Nutzungsbedingungen für KI-Agenten? Natürliche Sprache scheint für eine automatisierte Durchsetzung zu vage.
Unser Ansatz ist, die Nutzungsbedingungen in natürlicher Sprache zu halten und einen spezialisierten Agenten sie gegen die Query und den Prompt interpretieren zu lassen. Ein KI-System kann bewerten, ob „diese Daten dürfen nicht für Marketingzwecke genutzt werden" auf eine gegebene Query zutrifft. Die Governance-Ebene —die MCP-Server-Implementierung —setzt globale Policies, Quotas und Sicherheits-Checks durch, bevor SQL zur Datenplattform durchgelassen wird.
F: Wie oft stellst du beim Definieren von Qualitätsanforderungen fest, dass du zusätzliche Informationen im Schema erfassen musst?
Ziemlich oft. Wenn du Datenmodelle mit Domänenexperten diskutierst, kommen Dinge zum Vorschein, die verborgen waren. Klassisches Beispiel: Statusfelder, bei denen du dachtest, es gäbe nur drei oder vier Zustände, aber plötzlich gibt es einen „teilweise geliefert"-Zustand oder Fehlerzustände, die all deine Annahmen über den Haufen werfen. Statusfelder und Consent-Filter sind besonders heikel. Genau deshalb ist der Workshop-Prozess so wertvoll —er erzwingt diese Entdeckungen.