Talk
Data Contracts: What They Are, Why They Matter, and How to Use Them
Jochen Christ, Co-Founder & CTO @ Entropy Data · March 12, 2026
In this talk at the TDWI Roundtable Münster, I explain what data contracts are, how they compare to API specifications in the software world, and why they have become essential for managing data across teams. We walk through a concrete example using the Open Data Contract Standard (ODCS), discuss contract-first vs. data-first approaches, explore tooling like the Data Contract CLI and Data Contract Editor, and look at how data contracts become the governance layer for AI agents accessing enterprise data.

Note: The talk was delivered in German. The transcript below is an English translation. Transcribed and summarized using AI.
Thanks to TDWI for hosting the Roundtable Münster and Bodo Hüsemann for being the host at x1F.

Introduction
Hello everyone, I am Jochen, from Ansbach near Nuremberg. Today we are talking about data contracts —a topic that has become very popular. We will look at what a data contract is, walk through some examples, explore the tools you can use, and discuss why data contracts have become such an important topic.
I am at Entropy Data, a spin-off from INNOQ. Our core business is building software for managing data products with data contracts —metadata management platform. We also maintain two open-source tools: the Data Contract Editor, a web UI for working with data contracts, and the Data Contract CLI, for testing data contracts.
My background is software engineering —Java is my mother tongue. About five years ago, we dove into the data world, asking ourselves what the next big thing in IT would be. Cloud was done, event-driven architectures were done, Domain-Driven Design was everywhere. We concluded that data and AI would have the most impact. That led us to Data Mesh and eventually to translating Zhamak Dehghani's Data Mesh book into German for O'Reilly.

Where Are Your APIs?
Coming from the software world, the first thing we always asked data people was: "Where are your APIs?" The answer was always: "Look in the data catalog." So we looked —and first we found nothing, and when we did find something, we did not understand it.
Then PayPal published the first Data Contract template. We liked the idea but felt it could be closer to OpenAPI/Swagger. We made a proposal, and eventually we joined forces to create the BITOL project under the Linux Foundation, where we now govern and evolve the Open Data Contract Standard (ODCS).
I serve on the Technical Steering Committee. So if something is missing or does not make sense —tell us, and we can make it better.
A YAML Document —Like OpenAPI, but for Data
A data contract is, surprise, a YAML document. Why YAML? Because of Kubernetes —everything in Kubernetes is YAML. And OpenAPI/Swagger is a YAML document too. It describes what makes a dataset that I want to share with others.
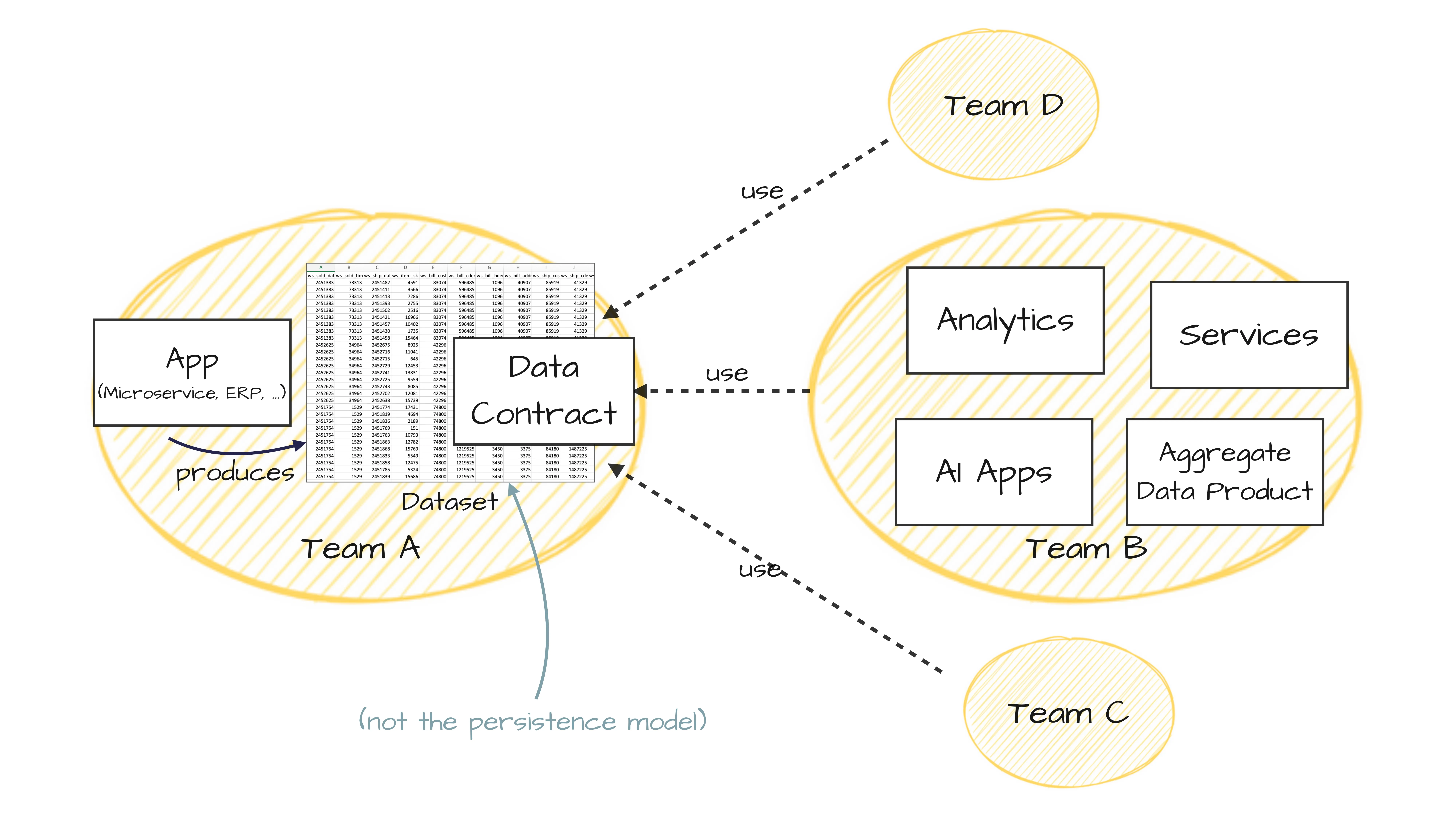
In a Data Mesh context, you have a team responsible for a dataset —the team where the data is originally created, for example in a microservice, an ERP system, or a business domain. That team takes ownership of the data product that is shared with other teams. Other teams want to access it for analytics, building services, AI applications, or creating aggregated data products.
The data contract defines the interface to consumers. It is relevant when exchanging data across teams and organizational units. Important: this is a usage relationship, not an ETL pipeline. Other teams access or consume my data. Conceptually, this is a usage dependency, which is different from classic data pipelines.
And for software developers who get nervous when they see a database table: I explicitly do not mean exposing the Oracle or Postgres database directly. There is always an anti-corruption layer, a view, that decouples the data model from the operational system.
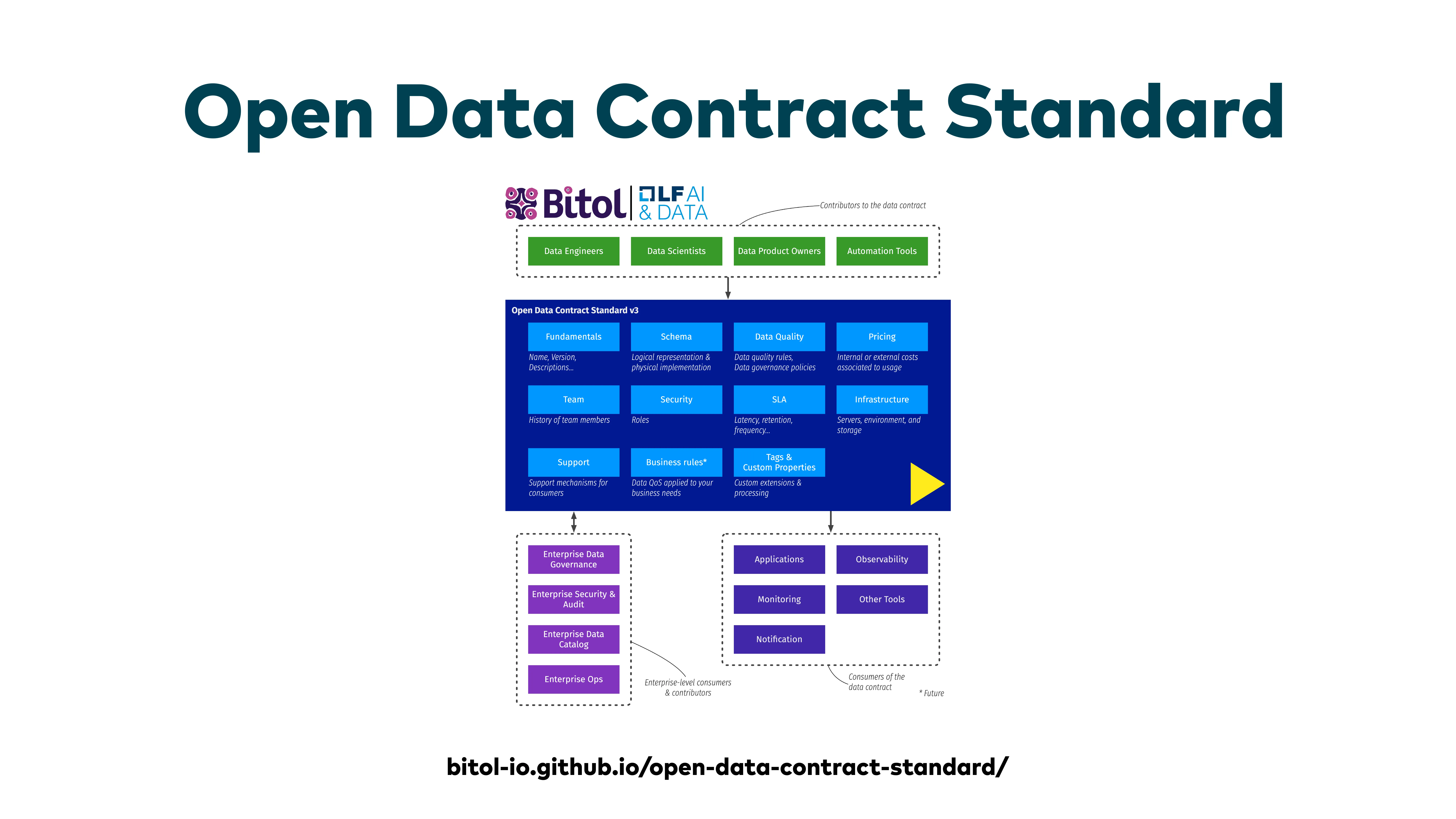
The Open Data Contract Standard (ODCS)
ODCS is now, I believe, the industry standard that everyone has converged on. Collibra, OpenMetadata, IBM —all major metadata vendors are adopting ODCS. Please, if you introduce data contracts, do not invent a proprietary format. Use ODCS so you can leverage the ecosystem and tooling, and remain interoperable with metadata layers and data catalogs.
Last year, the Open Data Product Specification (ODPS) was also created at the Linux Foundation. A data product is the system or module that produces the data —with input ports, a pipeline, tests, metadata, documentation —and at the end offers a dataset through an output port with a specific data contract. The data product is the system; the contract is the interface specification for the final dataset.

Two Approaches to Building Data Contracts
Data First is the most common approach. You already have a table or schema in your data warehouse. Now you want to add a contract: document it, describe it, specify quality attributes, so your consumers can understand what the dataset is. You put a contract on existing data.
Contract First is less common but very powerful. You start from the requirements of your business users and consumers. What data do they actually need? What should the data model look like to serve their use cases? Then you design the data product to match those requirements. This leads to smaller, more focused data products instead of tables with 10,000 columns because nobody wanted to throw anything away.
One important note: users cannot read or write YAML. We will look at tools that make this much more accessible —including Excel templates.

Walkthrough: An Orders Data Contract
Let us walk through a concrete example. In a web shop, a Checkout team manages order and customer data. A Recommendations team wants to build a machine learning model. So we do a contract-first workshop with Sophia, the data scientist:
"As a data scientist, I want all web shop orders from the last five years, so that we know which articles or categories were purchased together by a customer, enabling us to build a recommendation model for the web shop and marketing emails."
Ownership is the hardest part. Which team takes responsibility for providing the orders dataset? This ownership question is often 50% of the work. We have cancelled workshops where nobody was willing to own the data product. Without ownership, everything else —semantics, quality, service levels —is moot.

Schema, Semantics, and Examples
The heart of a data contract is the data model. You define schemas with tables and columns. But it is not just technical information —it also includes business names and descriptions that a business user would use. Do they say "Order ID", "Bestellnummer", or "Order Number"? We capture both the technical name and the business name.
This semantic description is something AI cannot generate for you. You only get it by talking to your domain experts, listening to how they talk to each other, and writing it down. That is the best source of good metadata.
Examples are crucial. We deliberately write slightly wrong examples in workshops, because people love to correct things. A domain expert will say: "Four decimal places? That cannot be right." And then you discover whether amounts are stored in dollars, euros, as integers in cents, or as doubles. The typical questions that have always caused pain.
If nobody corrects your examples, your audience has fallen asleep.

Quality Rules
Quality rules can initially be captured as plain text —a description of what consumers expect. For example: "The delivery date should not be more than 20 days in the future." Capture the business expectations first, in natural language.
Then turn them into SQL queries. AI can help with that. The essential part is capturing the business logic. Once you have the SQL, you can use it to verify data quality of your data products and datasets —similar to what tools like Great Expectations do.

The Story of John and the Consent Filter
An hour into the workshop, John, the product owner of the Checkout team, suddenly remembers: "Sorry, we cannot give you all orders. There is a consent restriction —only about 80% of orders have the cookie consent for analytical usage."
Sophia, the data scientist, says: "Fine, machine learning is fuzzy anyway, 80% is enough." But this information must go into the data contract —under limitations. This dataset is approved for analytical use but is not suitable for financial KPIs, because it only represents ~80% of revenue.
These are the kinds of limitations you simply do not see when you just look at the table in the data warehouse. You need metadata in the contract to capture them.
Terms of use are becoming increasingly important —especially for AI. Being able to tell an agent what it may and may not do with a dataset, and for which purposes it is suitable, is critical for governance. You can also link to standard policies like GDPR, data classification policies, or marketing data rules.

Service Levels and Non-Functional Guarantees
A data contract can also include non-functional aspects: availability, latency, support hours, retention, and backup guarantees. Every session, someone asks: "Can I use this dataset for my operational microservice?" The answer: define the guarantees in the contract, and let the consumer decide whether they are sufficient for their use case.
Nobody would build a web shop with a dependency on a system with only 99.8% availability. At least, they would add an anti-corruption layer or an asynchronous decoupling process. The SLA information in the contract helps consumers make that decision.

Why the Name Is Wrong —and Why It Stuck
One thing a data contract does not contain are the parties —the consumers. We have the owner, but not who consumes. In business law, a contract is a bilateral binding declaration. That bilateral character is missing here. It is really an interface specification.
In legal terms, it is more like an invitatio ad offerendum —an invitation to make an offer. Why is it called "contract" then? Because PayPal coined the term first, and the name stuck. It is catchy. It is memorable. It is just not technically correct.
The bilateral relationship is handled separately through agreements in the tooling —with start dates, end dates, and lifecycle management. That is where the 1:1 relationship between provider and consumer lives.
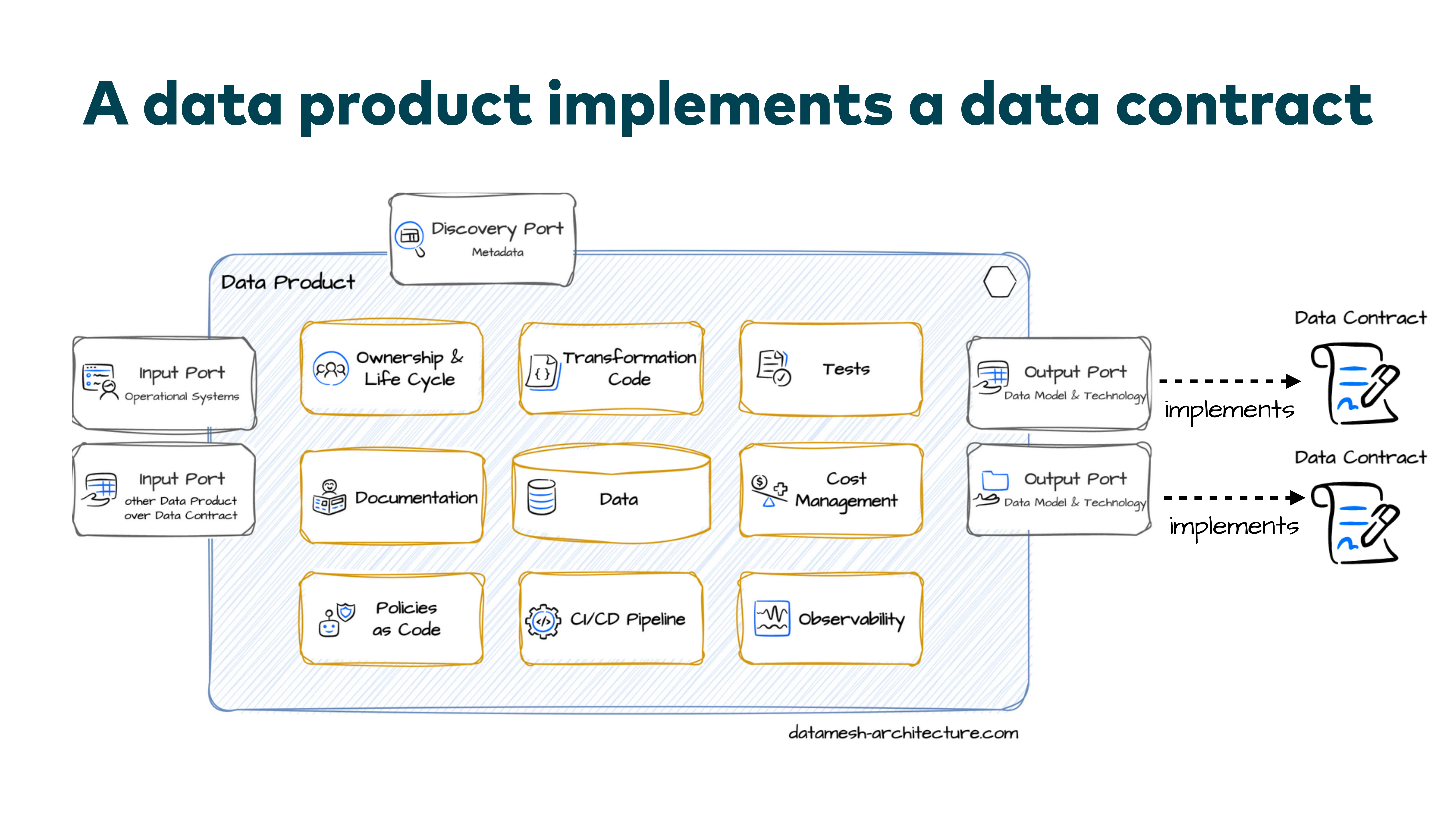
Data Products and Data Contracts
A data product has a private and a public aspect. Internally, there are pipelines, transformation code, intermediate tables, raw tables, tests. At the end, you expose a specific dataset for other teams to consume —that is the public part, the output port.
The data contract describes exactly this output port. The data product is the system on the platform; the contract is the interface that describes how the data looks and what guarantees come with it. They are tightly coupled.
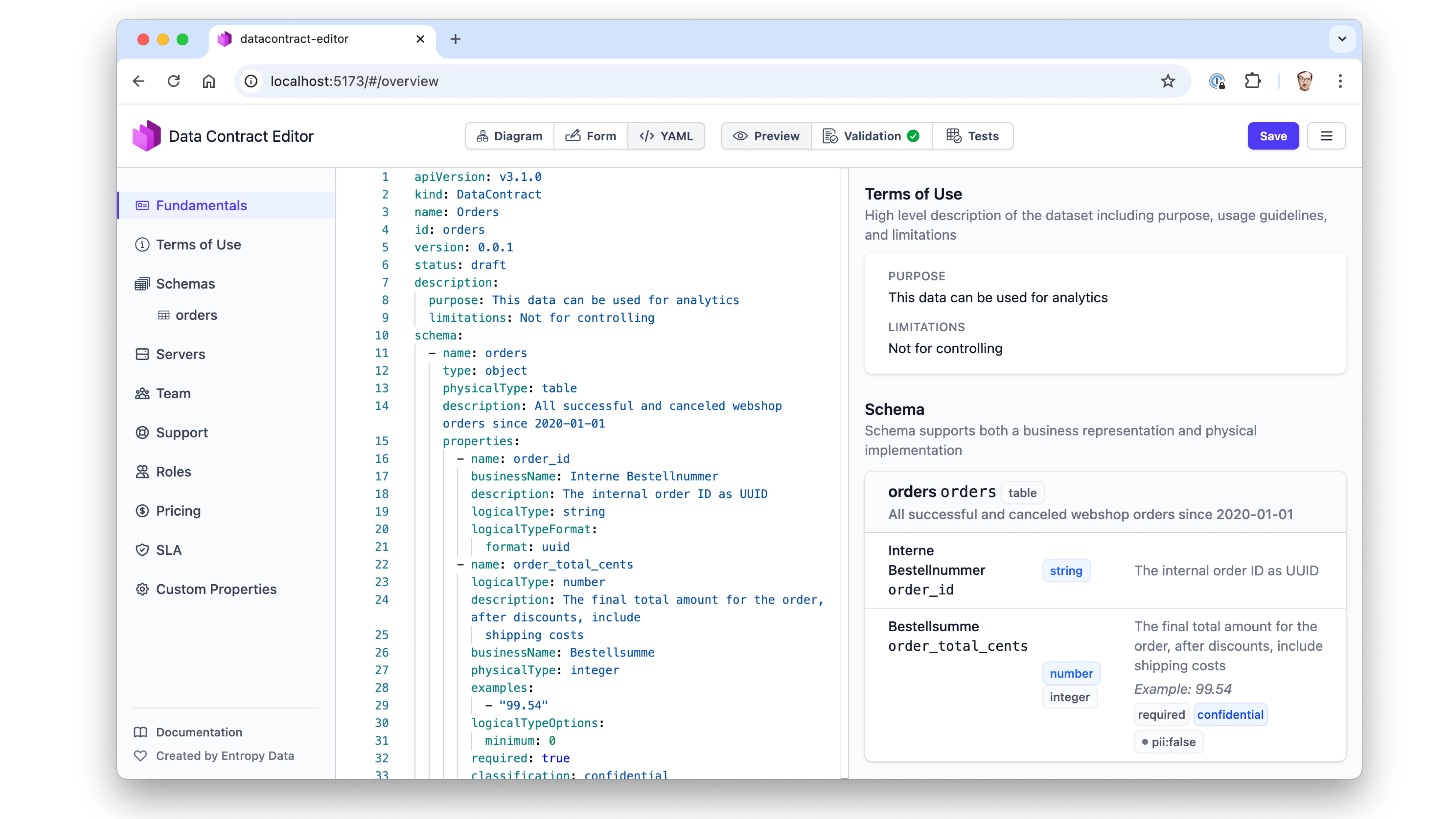
Data Contract Editor
The Data Contract Editor is an open-source web application you can deploy locally as a Docker container. You can write YAML directly, but you can also use forms to enter terms of use, server information, and schema definitions. It offers visual data modeling —like ER modeling, similar to Innovator or other tools people are used to.
At the end, it produces YAML. You can preview as HTML, validate for correctness, and run tests to verify that the actual data product behind the contract matches its definitions.
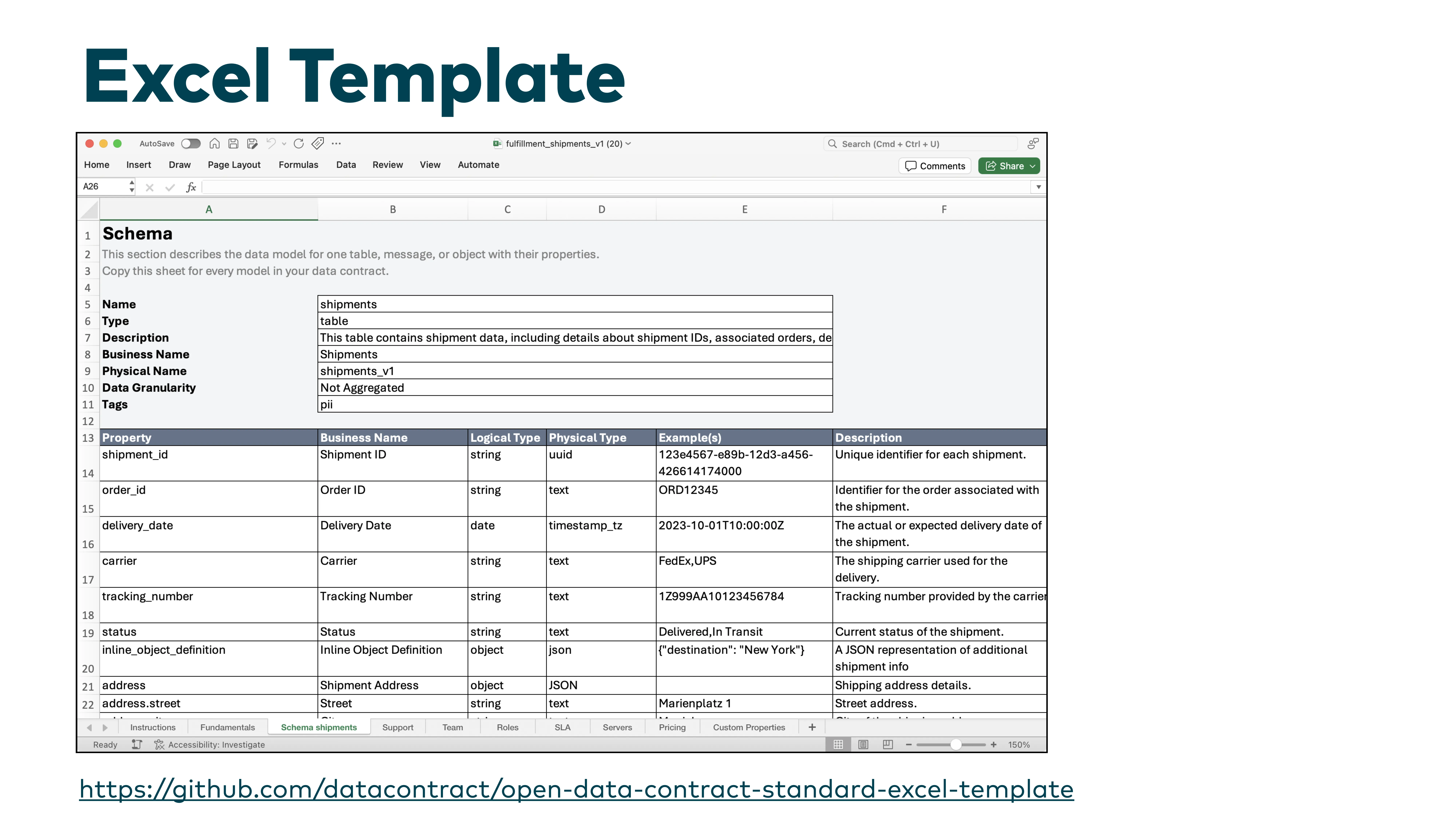
Excel Template —You Cannot Escape Excel
We created an Excel template because at least three customers said: "Everything is great, but we have introduced Excel for working with our business users." As computer scientists, it was hard to accept. But Excel still offers the best user experience for many people. You can email it around. The source data is often already in Excel.
The template is standards-compliant and converts to and from YAML in both directions. You will not get rid of Excel —so at least make it a good Excel.

Data Contract CLI and Pipeline Integration
The Data Contract CLI takes all the information from the YAML —field types, formats, quality rules (as SQL or Great Expectations) —connects to the database, and verifies that the data meets the contract's guarantees. It runs SQL statements for each aspect and reports pass/fail.
Integrating this into your deployment pipeline —for example, a GitHub Actions workflow —gives you higher confidence in your data. You can react quickly when something is red. Consumers can run the same checks on their input ports before executing their pipelines.
The CLI speaks to all major data platforms (BigQuery, Snowflake, Databricks, Postgres, and more) and can import/export from various formats.

Communication, Trust, and Discoverability
Communication: Data contracts give you a structured format to bring people together —producers and consumers —to discuss data requirements, domain knowledge, semantics. It guides conversations through the important aspects: terms of use, SLAs, quality rules. Do not underestimate this aspect of business transformation within the organization.
Trust: Data is only used when consumers feel it is correct and complete. Trust is easily lost —after the pipeline breaks for the third time, people stop believing in the data. You know the classic problem: one KPI, three different values. Which one is right? Data contracts help through clear semantics and automated quality checks.
Discoverability: When you collect data contracts and data product specifications centrally, you get a powerful overview of all available data in your organization. Unlike traditional data catalogs that scan every raw and intermediate table, a data marketplace built on data products shows only managed, curated datasets that are intended for consumption —far fewer artifacts, much higher quality.
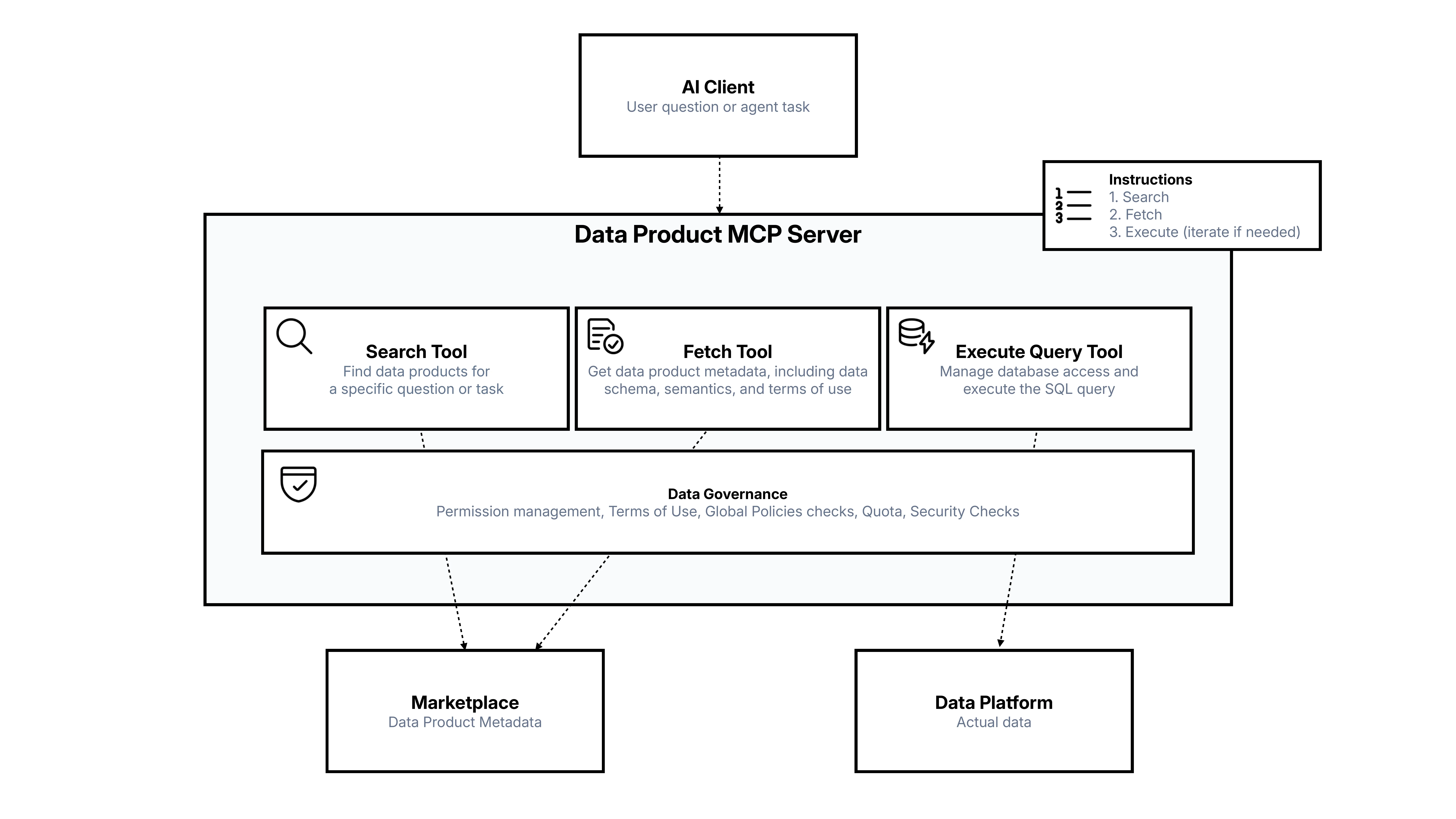
Agents Need Enterprise Data —and Governance
AI clients —ChatGPT, Claude, autonomous agent systems —can answer "What is the distance from Earth to the Moon?" without enterprise data. But for meaningful business tasks, they need access to your organization's data: customer data, orders, financials.
To enable this safely, agents need several tools:
- Search —discover what data products exist (customer data, orders, etc.).
- Evaluate —assess whether the semantics and data models match the question.
- Query —from the schema, an AI can automatically write SQL and query the data.
- Governance —control which agents have access, verify identity (user context vs. service account), enforce terms of use, apply global policies, and run security checks.
This is exactly the architecture we implement with our Entropy Data MCP Server. An agent asks a business question, the MCP server searches the data marketplace, fetches the data contract with its full metadata, evaluates the schema, requests access, and generates SQL. The data contract —with its terms of use, quality rules, and semantics —becomes the governance layer that makes this safe and controlled.

Summary
Data contracts are the missing piece for managing data across teams. They bring the rigor of API specifications to the data world: schema definitions, semantic descriptions, quality rules, terms of use, and service levels —all in a standardized, machine-readable format.
With tools like the Data Contract CLI, the Data Contract Editor, and even Excel templates, the ecosystem is mature enough for adoption today. And as AI agents increasingly need access to enterprise data, data contracts become the essential governance layer that makes this possible —safely and at scale.
If you want to continue the conversation, you can find me on LinkedIn or visit www.entropy-data.com.
Q&A
Selected questions from the audience during the talk.
Q: Can I use the same dataset in different granularities —e.g., aggregated vs. raw? How do I handle variants?
Conceptually, those are different data contracts. Each variant —different granularity, different format —gets its own contract. You can link them or tag them as related, but logically they are separate interfaces with separate guarantees.
Q: Can I use data contracts for operational data exchange between microservices, not just analytical data?
Yes, define the non-functional guarantees —availability, latency, support hours —in the contract. Then the consumer can decide whether those guarantees are sufficient for their operational use case. A web shop would never depend on a system with 99.8% availability without adding an anti-corruption layer or asynchronous decoupling.
Q: How do you formalize terms of use for AI agents? Natural language seems too vague for automated enforcement.
Our approach is to keep terms of use in natural language and have a specialized agent interpret them against the query and the prompt. An AI system can evaluate whether "this data may not be used for marketing purposes" applies to a given query. The governance layer —the MCP server implementation —enforces global policies, quotas, and security checks before letting SQL through to the data platform.
Q: When defining quality requirements, how often do you discover that you need to capture additional information in the schema?
Quite often. When you discuss data models with domain experts, things surface that were hidden. Classic example: status fields where you thought there were only three or four states, but suddenly there is a "partially delivered" state, or error states that break all your assumptions. Status fields and consent filters are particularly tricky. That is exactly why the workshop process is so valuable —it forces these discoveries.