Talk
Let's Talk About Data Contracts: Standards, Tooling & Best Practices
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · 19. März 2026
In diesem Vortrag beim INFOMOTION Data & AI Meetup Cologne erkläre ich alles, was du über Data Contracts wissen musst: was sie sind, warum sie wichtig sind, den Open Data Contract Standard (ODCS), Open-Source-Tooling, Best Practices für Versionierung und Lifecycle-Management und warum agentische KI Data Contracts so allgegenwärtig machen wird wie OpenAPI.

Hinweis: Der Vortrag wurde auf Deutsch gehalten. Das untenstehende Transkript ist eine bearbeitete Fassung.
Danke an Prof. Dr. Ana Moya, Peter Baumann und INFOMOTION für die Organisation des Meetups und die Einladung zum Vortrag, und an Jochen Christ dafür, den Vortrag mitgestaltet zu haben.

Vorstellung
Hallo, mein Name ist Simon. Im Herzen bin ich Software Engineer, der vor etwa vier Jahren in die Welt der Daten geraten ist. Ich komme aus dem Java-Ökosystem -- ich habe ein Buch über Clean Code in Java mitgeschrieben, "Java by Comparison". Fun Fact: Das Buch entstand vor KI, und aktuell läuft eine Klage, weil Anthropics Modelle es illegal fürs Training verarbeitet haben.
Ich habe lange bei INNOQ als Berater gearbeitet, und 2025 haben wir aus INNOQ ein Startup ausgegründet. Ich bin Co-Founder und CEO bei Entropy Data, wo wir einen Marktplatz für Datenprodukte auf Basis von Data Contracts bauen.
Gemeinsam mit Kolleginnen und Kollegen habe ich das "Data Mesh"-Buch ins Deutsche mitübersetzt, datamesh-architecture.com und datacontract.com ins Leben gerufen, betreue Open-Source-Tools wie die Data Contract CLI und den Data Contract Editor mit und sitze im Technical Steering Committee des BITOL-Projekts der Linux Foundation für Data-Contract-Standards. Ich denke also, ich kann heute einigermaßen kompetent über Data Contracts reden.
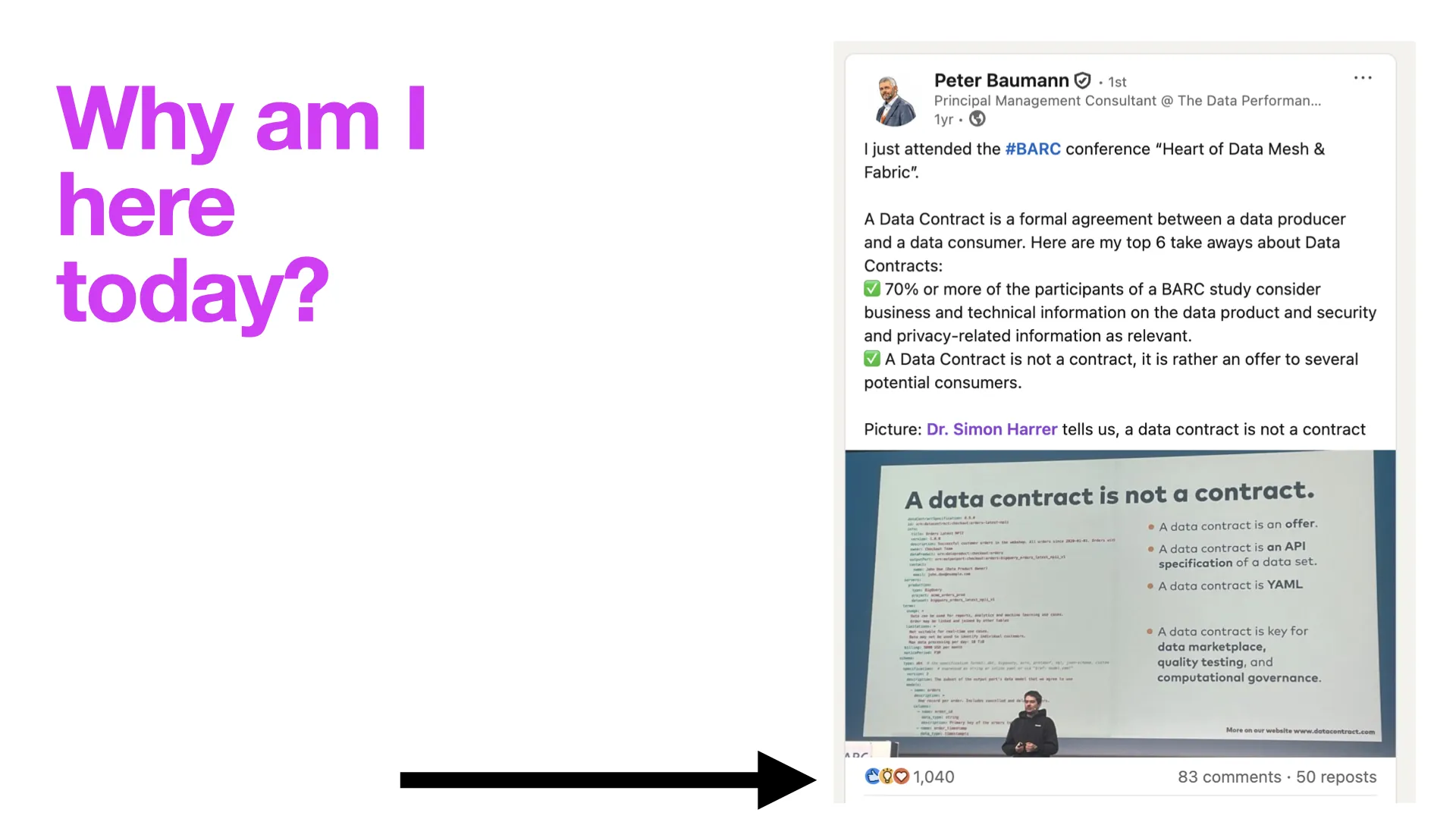
Warum bin ich heute hier?
Eine kurze Anekdote. Vor etwa anderthalb Jahren habe ich einen Vortrag auf der Konferenz BARC "Heart of Data Mesh & Fabric" gehalten, und Peter Baumann von INFOMOTION hat ihn auf LinkedIn gepostet. Er bekam über 1.000 Likes -- ging ziemlich viral -- mit dem Titel "A Data Contract Is Not a Contract." Das war natürlich etwas provokant, aber die Leute haben draufgeklickt.
Also lass uns über Data Contracts reden. Und wenn wir über Daten reden, reden wir eigentlich über Vertrauen. Vertrauen in Daten. Das ist das Wesentliche.
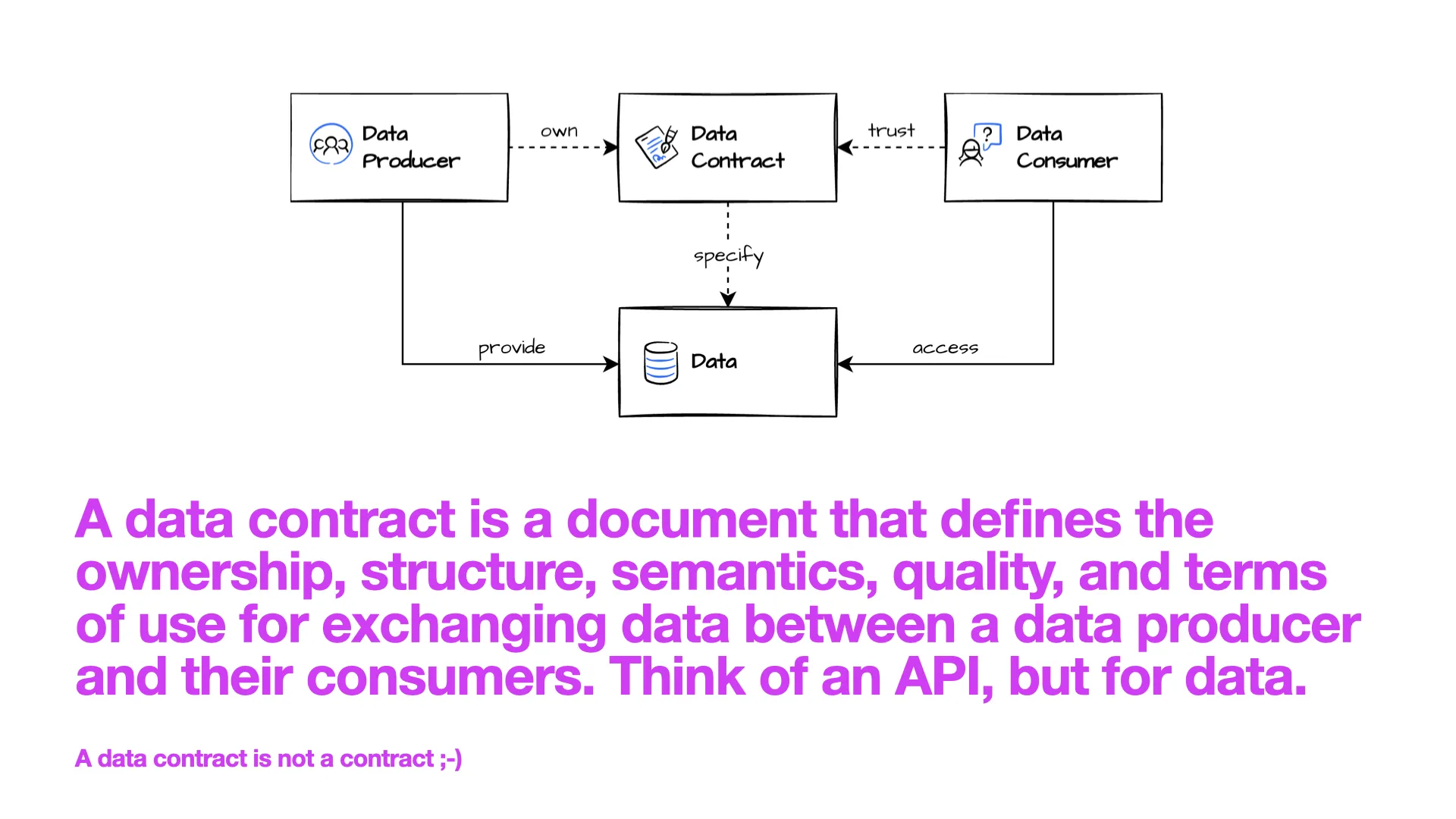
Was ist ein Data Contract?
Ein Data Contract ist ein Dokument, das Ownership, Struktur, Semantik, Datenqualität und Nutzungsbedingungen für den Austausch von Daten zwischen einem Data Producer und seinen Consumers definiert -- wie eine API-Spezifikation, aber für die Datenwelt.
Im Diagramm siehst du: Dem Consumer geht es darum, die Daten zu nutzen, vor allem aber um Vertrauen. Der Data Contract spielt eine entscheidende Rolle, weil der Data Producer Daten anbietet und seine Zusagen im Contract festhält. Wenn diese Zusagen zu den tatsächlichen Daten passen, kann der Consumer die Daten nutzen und dem Contract vertrauen.
Ein Data Contract hat viele Elemente. Wir gehen sie gleich im Detail durch, aber zuerst möchte ich die Entstehungsgeschichte erzählen, wie wir zu Standards gekommen sind.

Die Lücke: Keine Spezifikation für Data APIs
Vor ein paar Jahren gab es in der Welt von Software und Daten eine sehr klare Antwort für REST APIs: OpenAPI (der Nachfolger von Swagger). Für asynchrone Schnittstellen wie Kafka gab es AsyncAPI. Aber für Daten -- wenn ich einen großen Datensatz teilen wollte -- gab es keine gute Antwort. Es gab ein paar Insellösungen, aber nichts Standardisiertes.
Und dabei hatten wir jede Menge Data APIs: CSV auf SFTP (ja, ich sehe das erste Schmunzeln), JSON auf S3, SQL-Tabellen auf BigQuery, Iceberg-Dateien, Snowflake-Views, Delta Live Tables. Das sind alles Schnittstellen. Jemand hat etwas geschäftskritisch Wichtiges darauf aufgebaut, und wenn diese Schnittstelle bricht, bricht auch alles dahinter.
Wir brauchten eine Möglichkeit, darauf zu vertrauen, dass eine CSV, die ich von einem SFTP-Server konsumiere, stabil bleibt und die Daten die Qualität haben, die vereinbart wurde.

Jeder hat sein eigenes Format gebaut
Als Daten dezentraler wurden, fingen mehr und mehr Teams an, Daten mit mehr und mehr Consumers zu teilen. Es war nicht mehr nur ein Datenteam mit einem Oracle-Server und einem Data Warehouse.
Viele Unternehmen sahen den Bedarf für Data Contracts -- und jedes einzelne baute sein eigenes Format. Sie alle hatten dasselbe Problem und bauten alle ihre eigenen Lösungen. Das Einzige, was sie gemeinsam hatten? Fast alle wählten YAML. Na ja, manche nutzten JSON, und manche sogar Word und Excel. Aber dann entstand ein Standard.
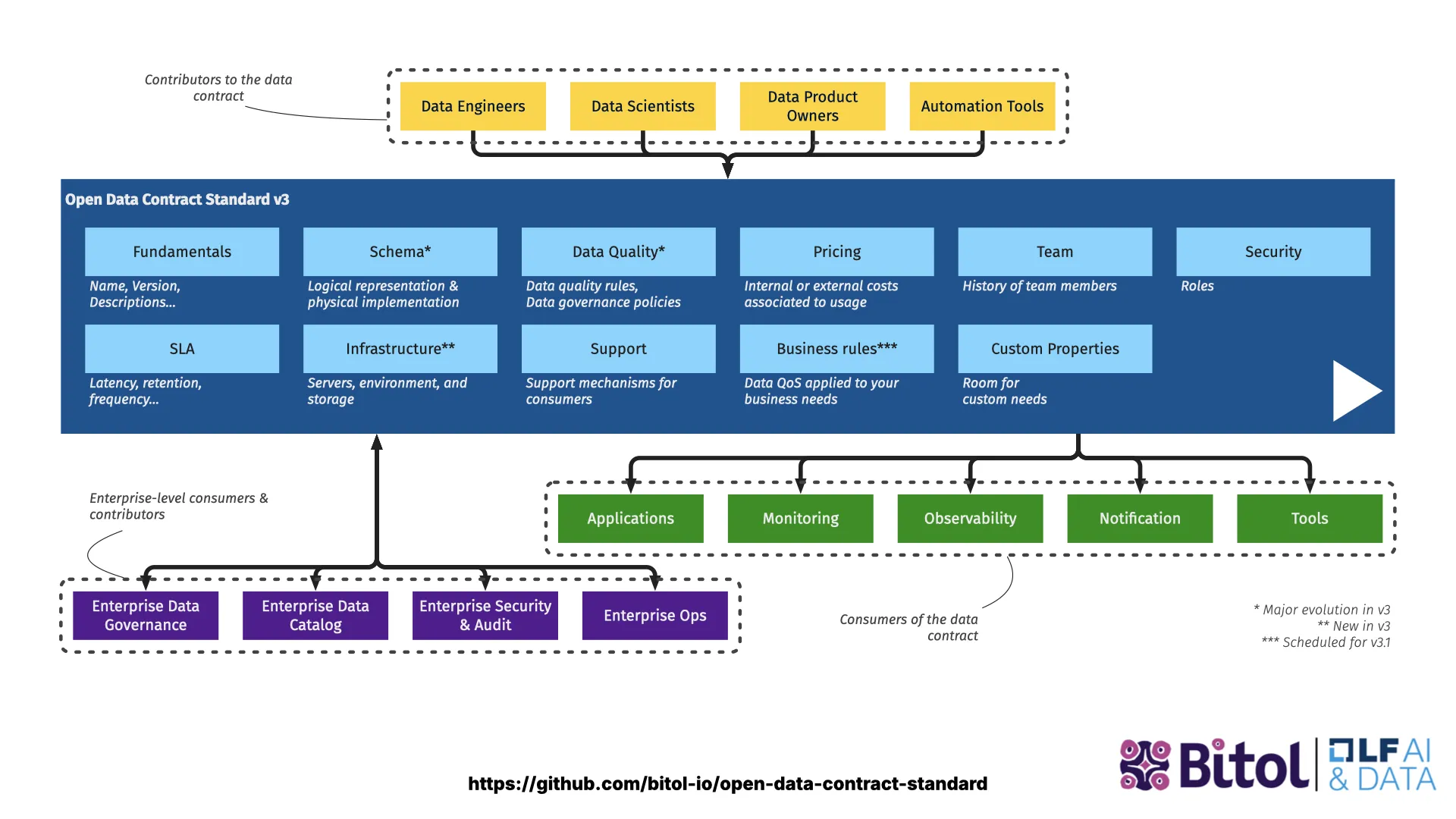
Der Open Data Contract Standard (ODCS)
Der Standard, der entstand, ist der Open Data Contract Standard. Ursprünglich kam er von PayPal -- sie waren eines dieser Unternehmen, die ihr eigenes Data-Contract-Format entwickelt hatten. Sie haben es unter der Apache License als Open Source veröffentlicht und später an die Linux Foundation gespendet.
Ich bin dem Standardisierungs-Committee beigetreten. Wir haben die PayPal-spezifischen Elemente entfernt und es so erweitert, dass auch andere Unternehmen als PayPal es nutzen können. Seit 2025 liegt es in Version 3 vor (mittlerweile 3.1), und man kann es wirklich gut einsetzen. Wir sehen dieses Jahr eine starke Adoption -- Collibra hat sich committet, OpenMetadata hat sich committet und schon Features dafür gebaut.
Es deckt Grundlagen, Schema, Datenqualität, Pricing, Team, Security, SLAs, Infrastruktur, Support, Business-Regeln und Custom Properties ab.
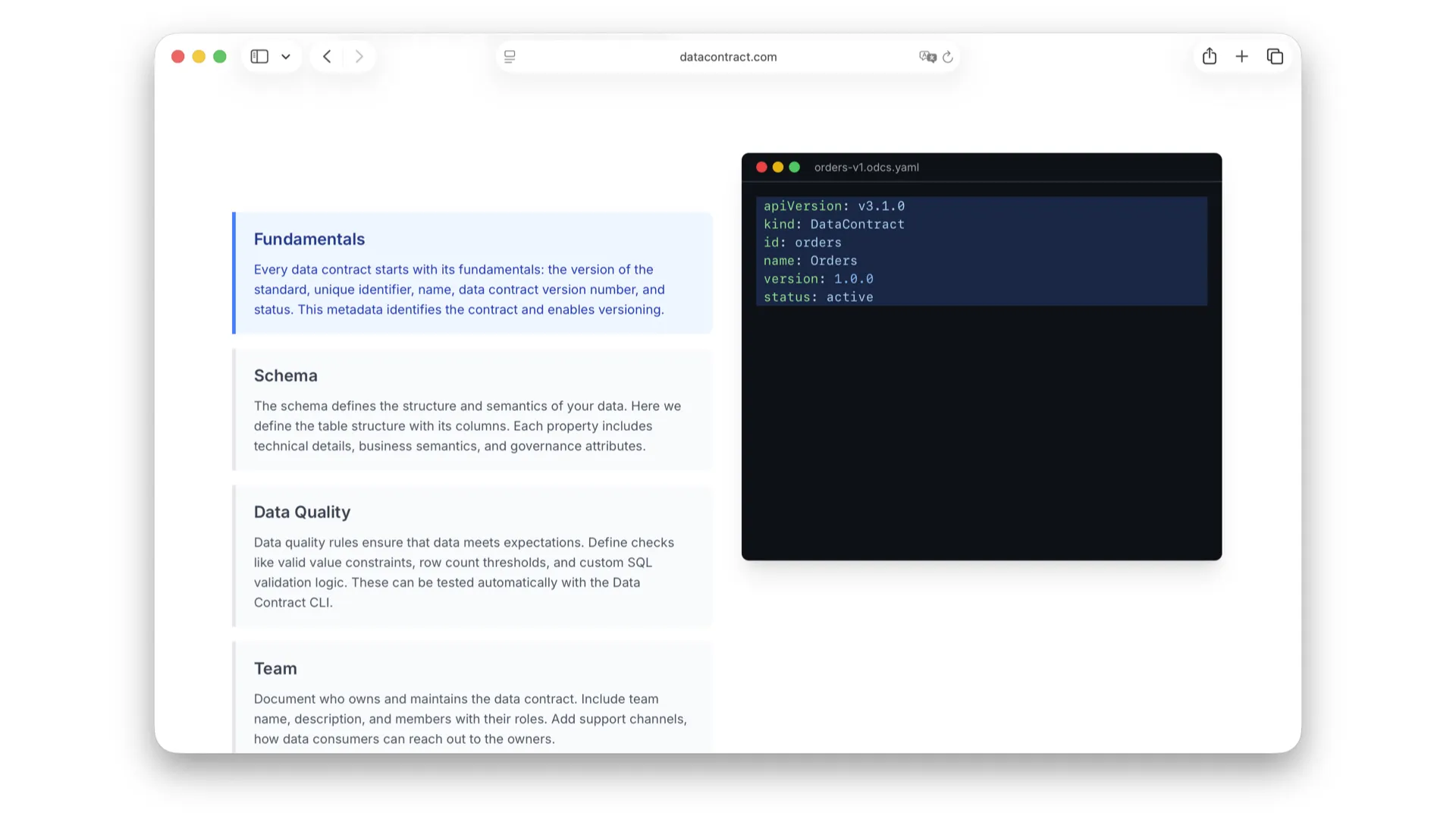
Grundlagen
Im Grundlagen-Block definieren wir die ID, den Namen, die Version und einen Status, um Contracts ein- und auszuphasen. Wie versioniere ich Data Contracts? Dazu komme ich später im Best-Practices-Teil. All diese Details kannst du auf datacontract.com erkunden.
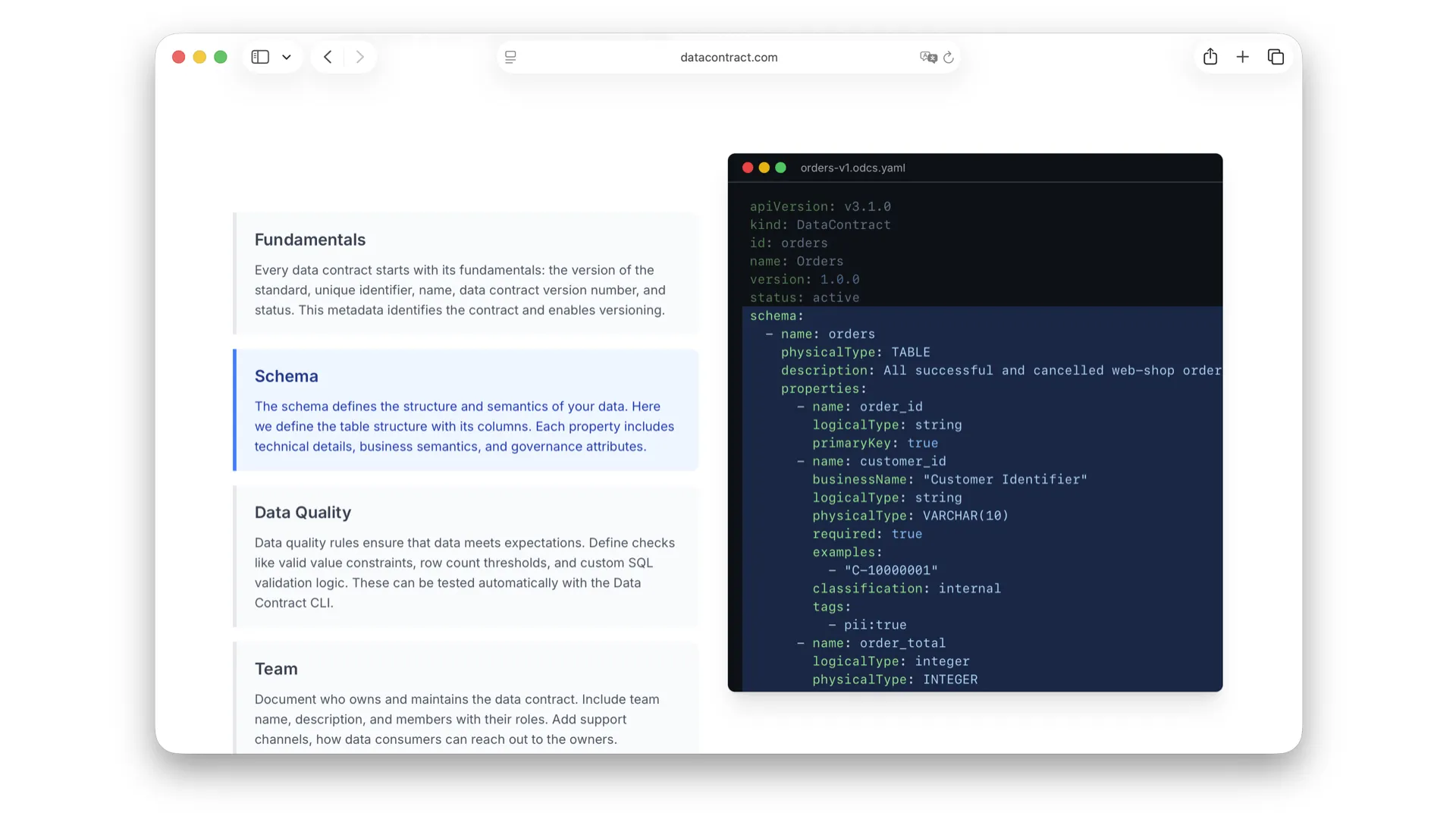
Schema
Die Schema-Beschreibung ist essenziell -- sie definiert, wie die Daten strukturiert sind. Du definierst Tabellen und ihre Spalten. Interessant ist: Wir haben sowohl physische Typen als auch logische Typen. Wir nehmen außerdem Beispiele, Datenklassifizierung und Business-Namen mit auf -- es geht schon in Richtung Semantik. Du kannst das Schema sehr detailliert beschreiben.
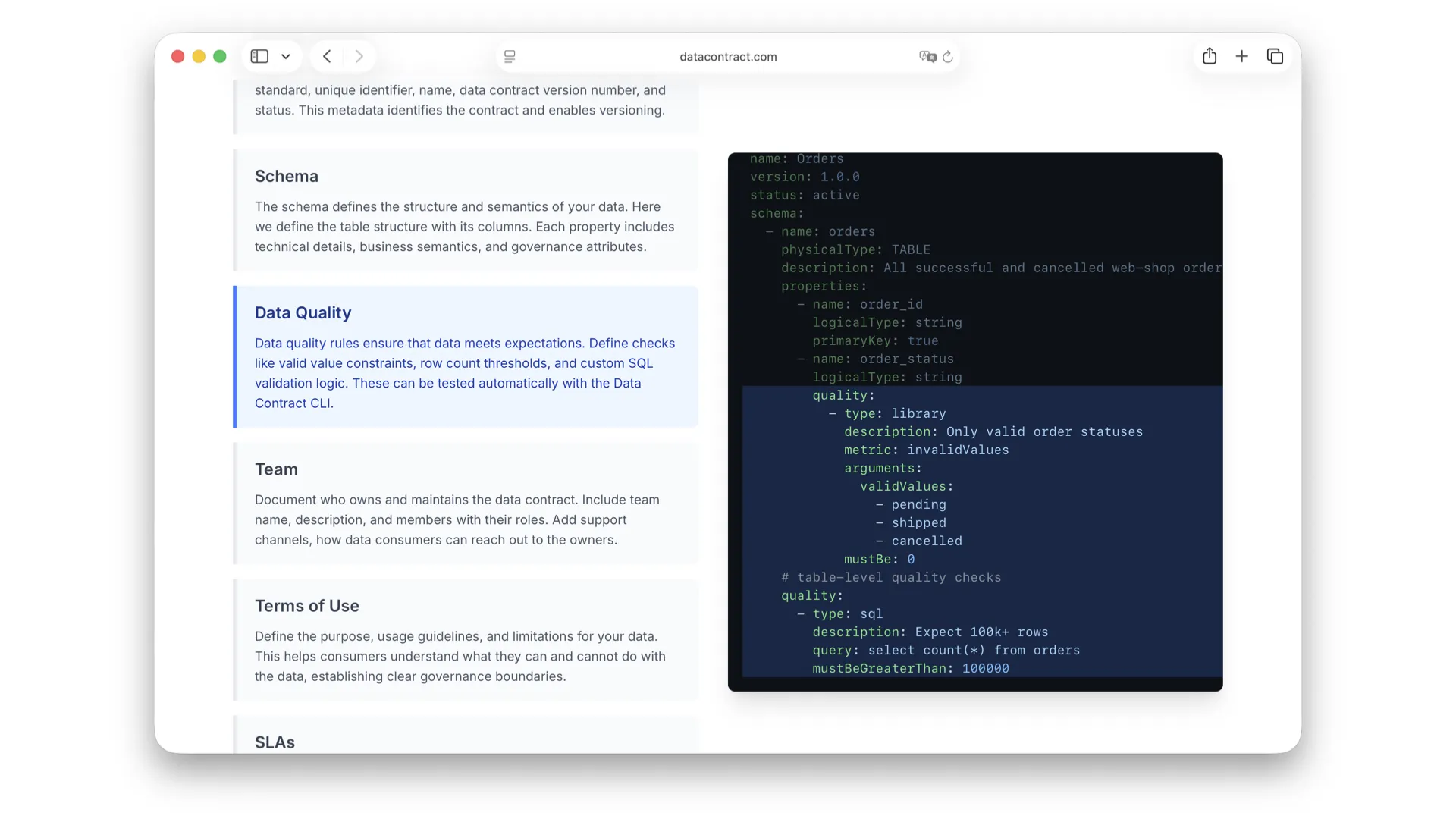
Datenqualität
Datenqualität ist Teil des Contracts, weil sie Teil meiner Zusagen als Datenanbieter an meine Consumers ist. Hier haben wir einen Datenqualitäts-Check für ungültige Werte mithilfe einer Library wie Soda oder Great Expectations und SQL-basierte Qualitätsprüfungen, die ausführbar sind. Mit dem richtigen Tooling kannst du automatisch verifizieren, ob der Contract von den tatsächlichen Daten eingehalten wird.
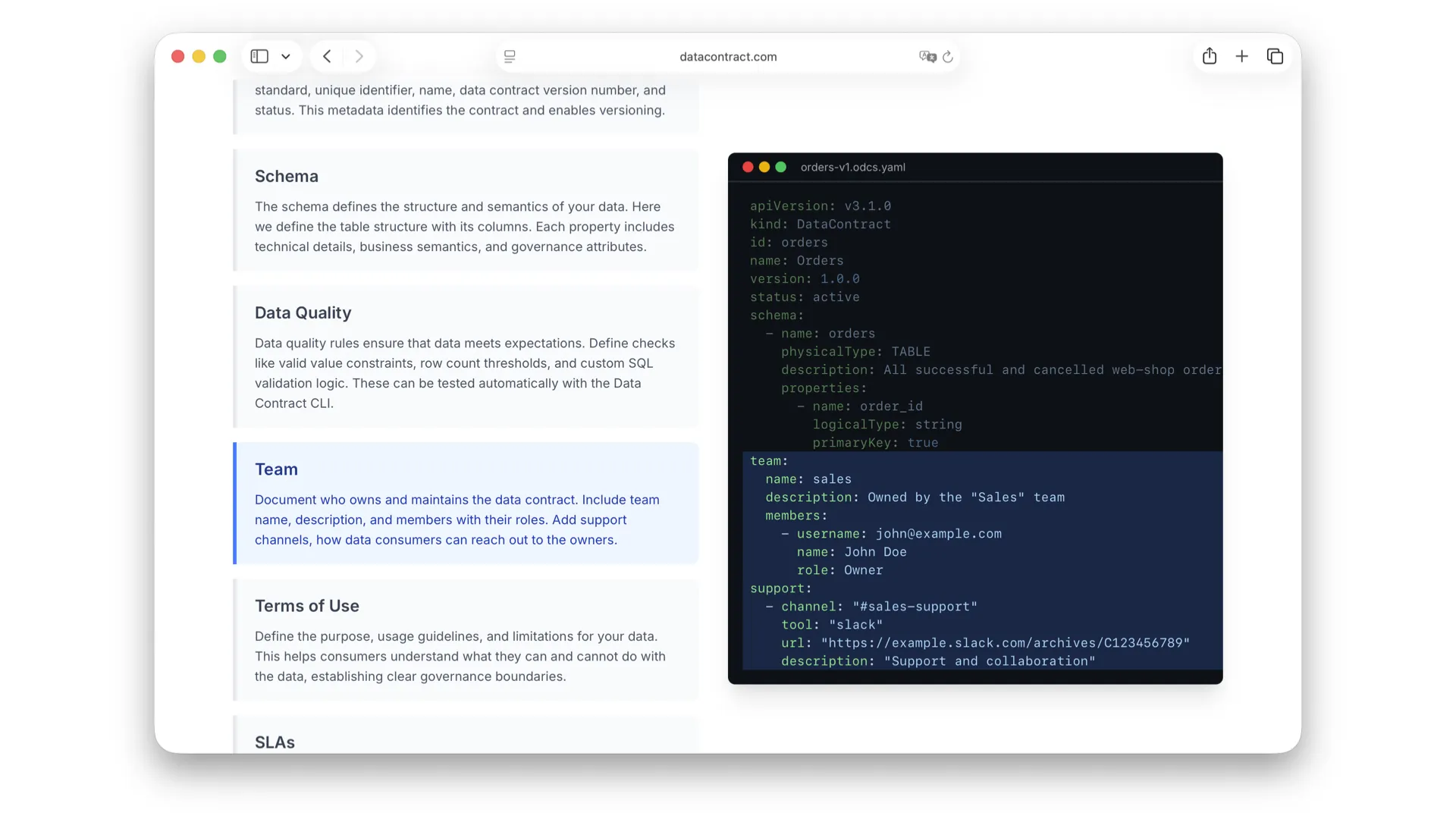
Team
Der Team-Abschnitt sagt dir, wer diese Daten bereitstellt und wie du sie erreichst. Was ist der Slack-Channel? Was ist der bevorzugte Support-Kanal? Antworten sie überhaupt? Das ist entscheidend -- wenn etwas mit den Daten schiefgeht, musst du wissen, an wen du dich wenden kannst.
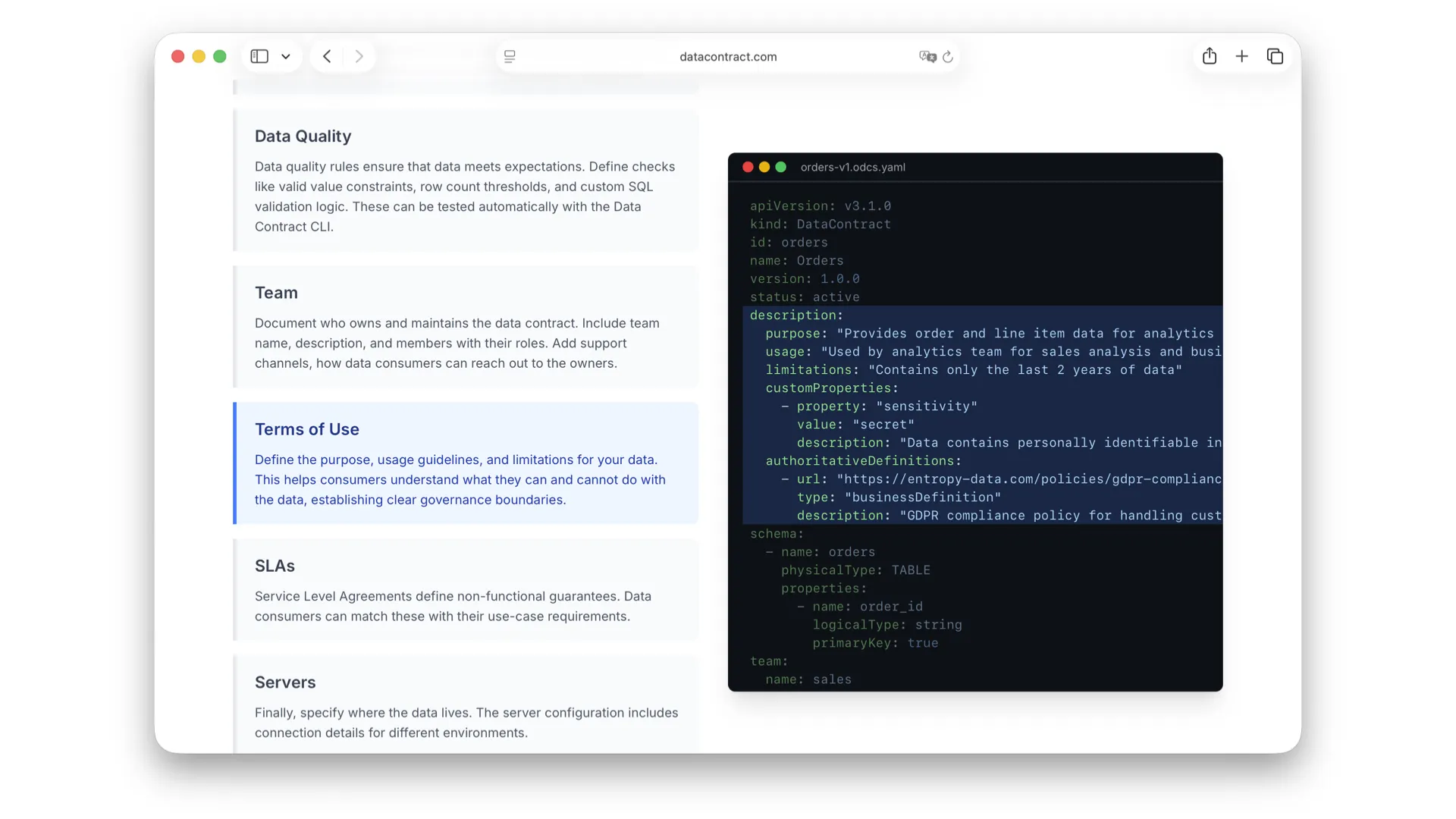
Nutzungsbedingungen
Die Nutzungsbedingungen definieren, was ich als Consumer mit den Daten tun darf und was nicht. Gibt es Lizenzbedingungen? Greift die DSGVO? Gibt es interne Datenschutzrichtlinien, die ich mir selbst auferlegt habe? Was darf ich mit den Daten tun und was nicht? Auch das schafft Vertrauen.
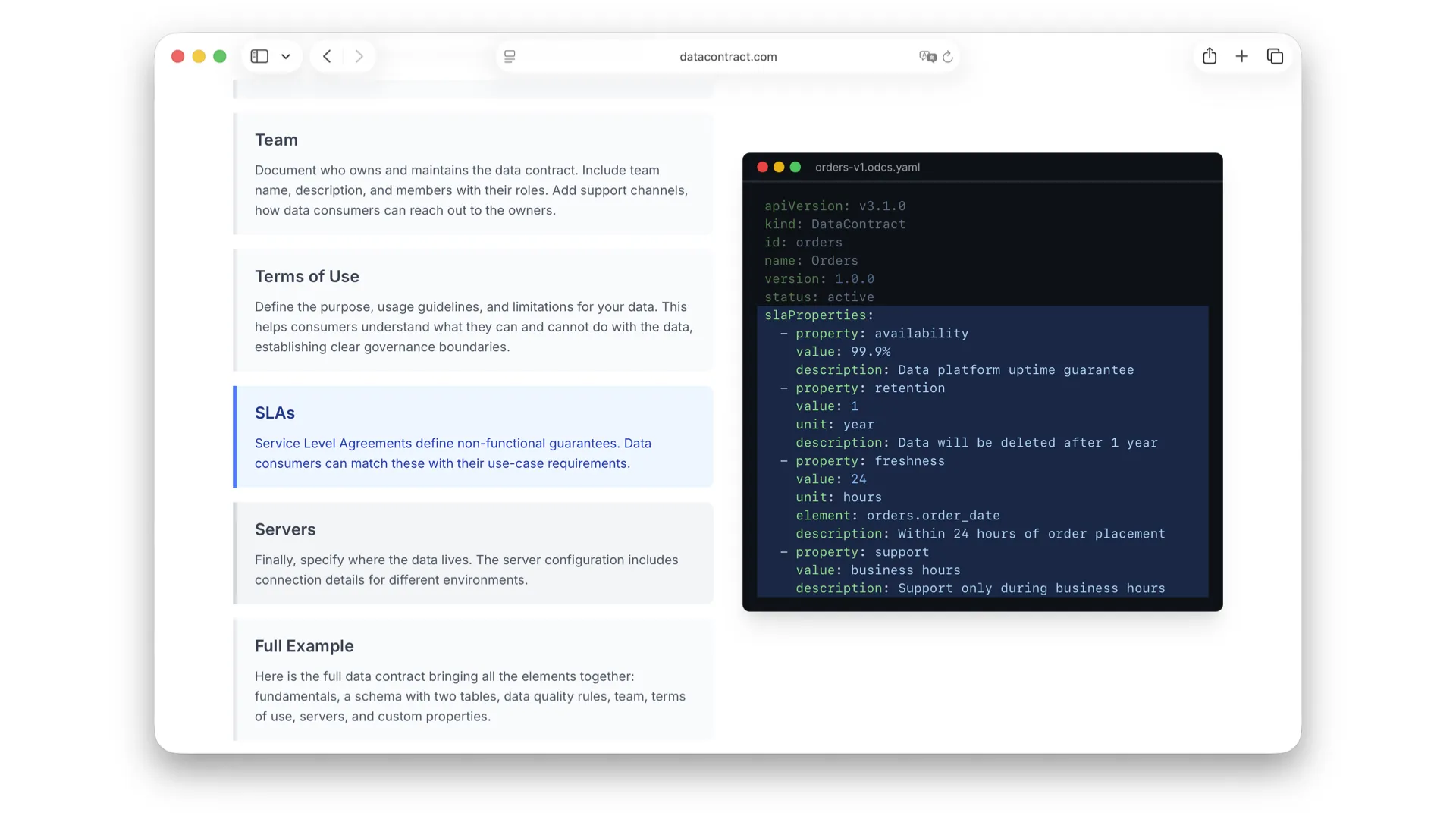
Service Level Agreements
Service Level Agreements sind Klassiker: Data Retention, Aktualität, Latenz. Die sind essenziell und lassen sich ebenfalls automatisch verifizieren. Hier habe ich sie schriftlich vom Anbieter garantiert -- schwarz auf weiß.
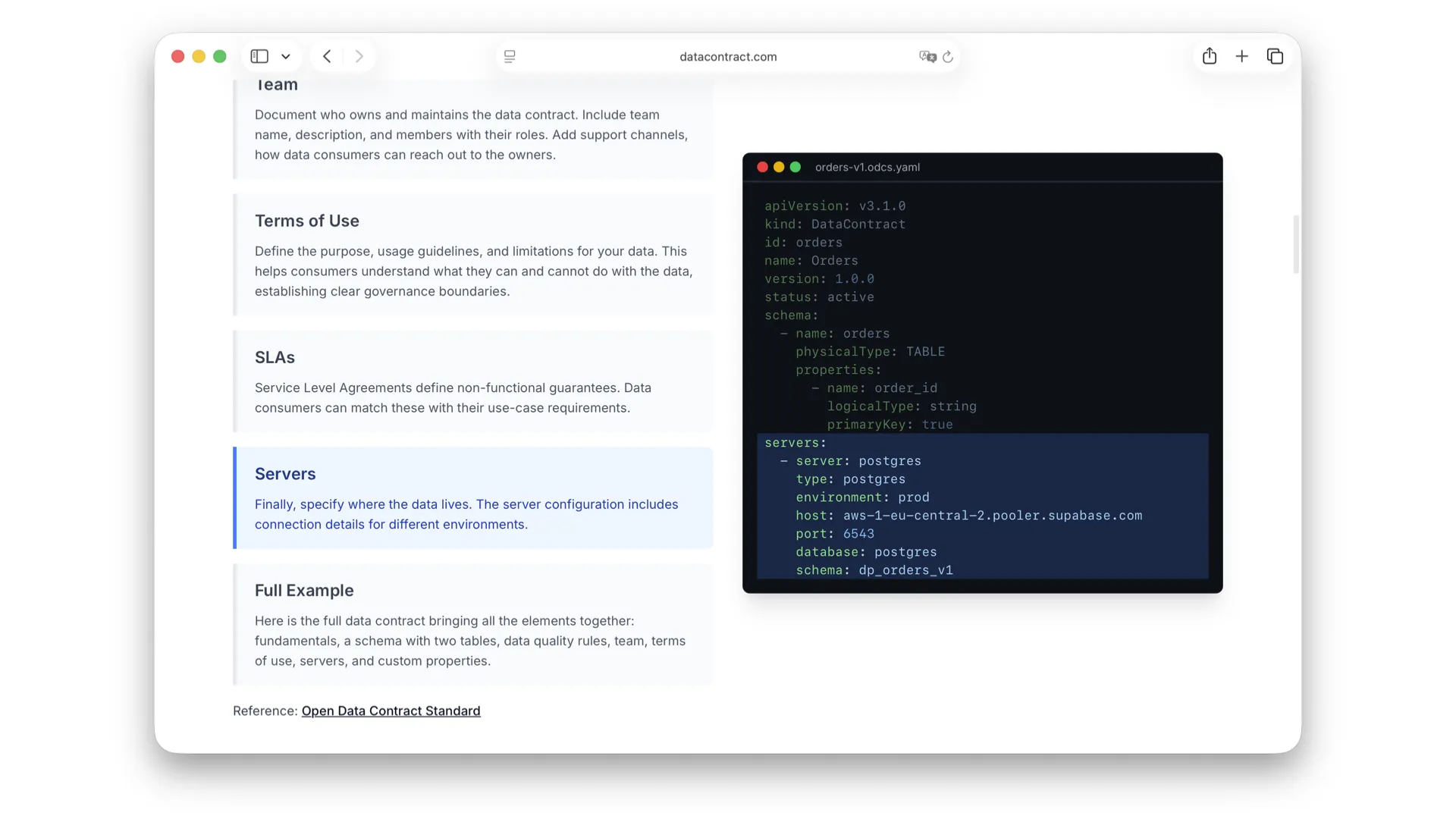
Server und Infrastruktur
Und schließlich: Wo leben die Daten eigentlich? Hier habe ich ein Beispiel mit Postgres auf Supabase. Aber es kann alles sein -- Databricks, Snowflake, eine CSV auf S3 oder jede andere Datenplattform.
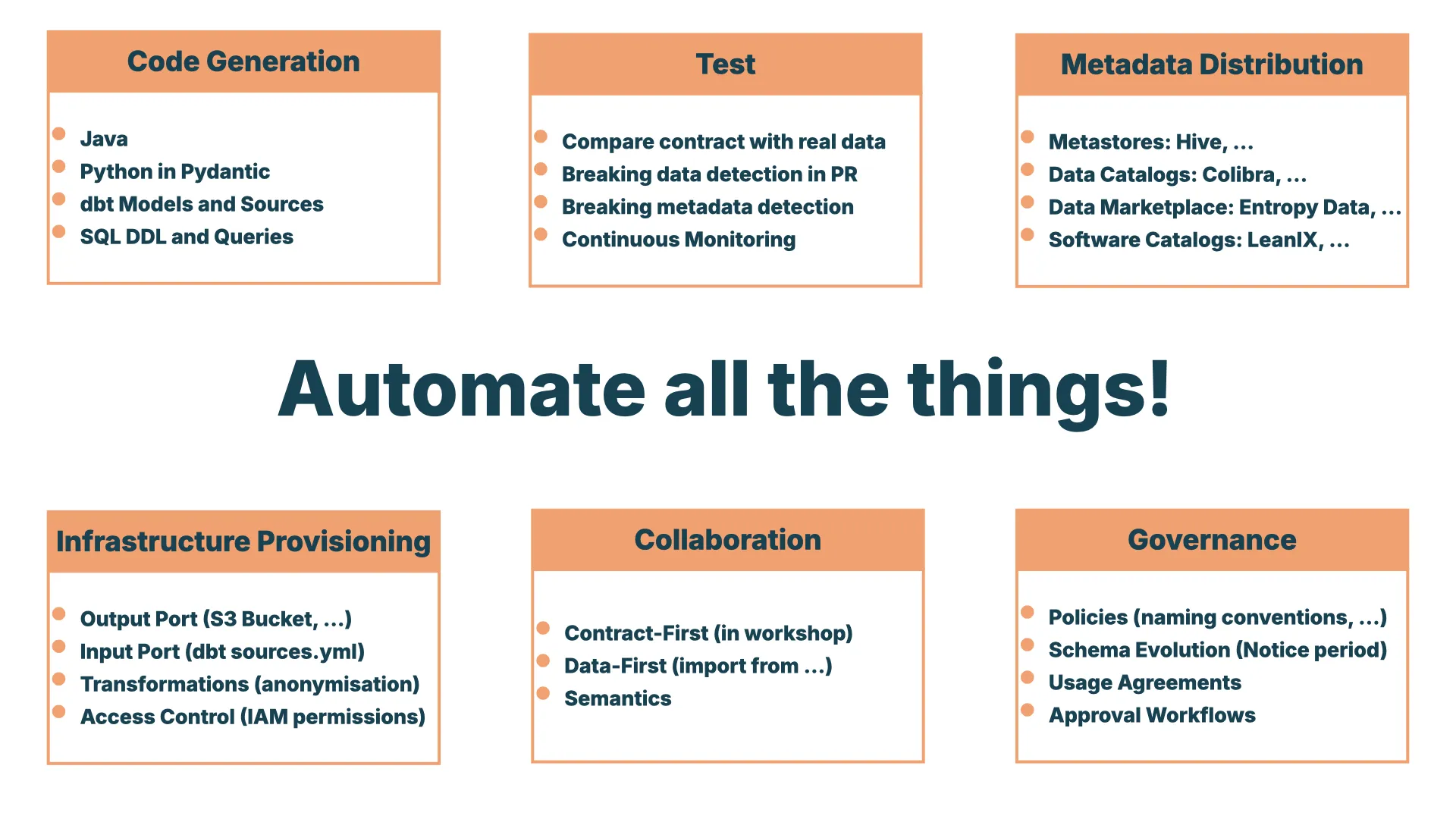
Automate All the Things
Sobald ich einen Contract mit all diesen Informationen habe, kann ich tausend Dinge damit machen:
- Testen -- die Daten und den Contract nebeneinanderlegen und prüfen, ob sie zusammenpassen. Falls nicht, einen Alert auslösen und eskalieren.
- Code generieren -- SQL DDL, ein dbt-Modell erzeugen oder sogar die KI das ganze dbt-Projekt bauen lassen. Wenn Input und Output klar sind, kann die KI die Lücke füllen.
- Continuous Monitoring -- laufend prüfen, ob der Contract noch zu den Daten passt, während sie immer weiter angereichert werden.
- Metadaten verteilen -- den Contract (die Source of Truth) in Kataloge und Metastores pushen und als Dokumentation nutzen.
- Infrastruktur provisionieren -- S3-Buckets anlegen, IAM-Rollen für einen Datenmarktplatz einrichten, damit andere einfach auf die durch den Contract geschützten Daten zugreifen können.
Extrem mächtig für die Automatisierung.
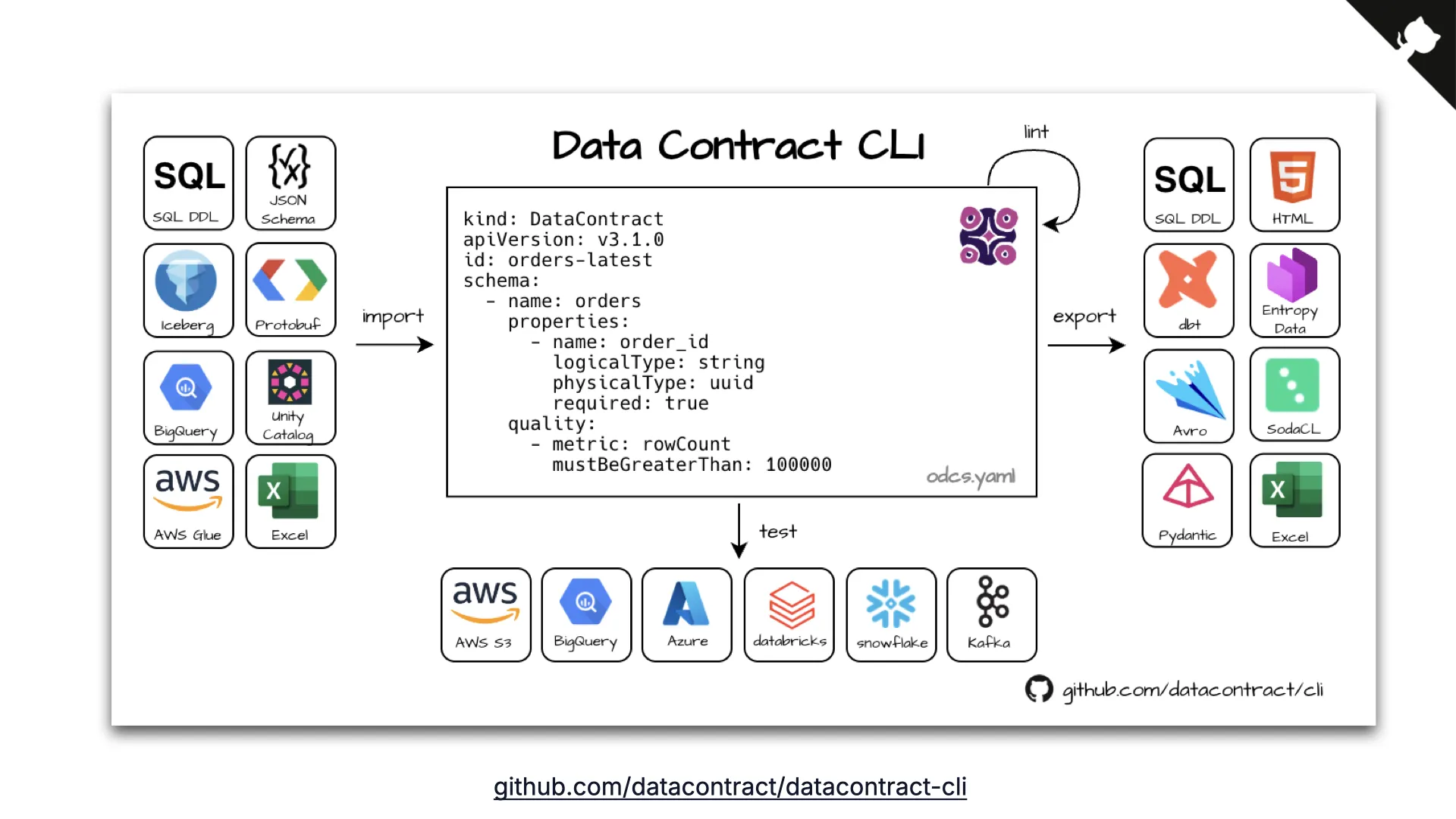
Data Contract CLI
Das wichtigste Tool ist die Data Contract CLI, ein Open-Source-Projekt mit rund 800 GitHub-Stars. Sie liest einen Contract, verbindet sich mit jeder Datenplattform, die du kennst, und prüft automatisch, ob das, was im Contract spezifiziert ist, zu den tatsächlichen Daten auf der Plattform passt. Du bekommst einen Report.
Das kannst du in einer Pipeline laufen lassen, in Airflow, Ergebnisse über die Zeit tracken. Sie kann in viele verschiedene Formate exportieren und aus bestehenden Datenquellen importieren, um schnell deine erste Contract-Version zu generieren.
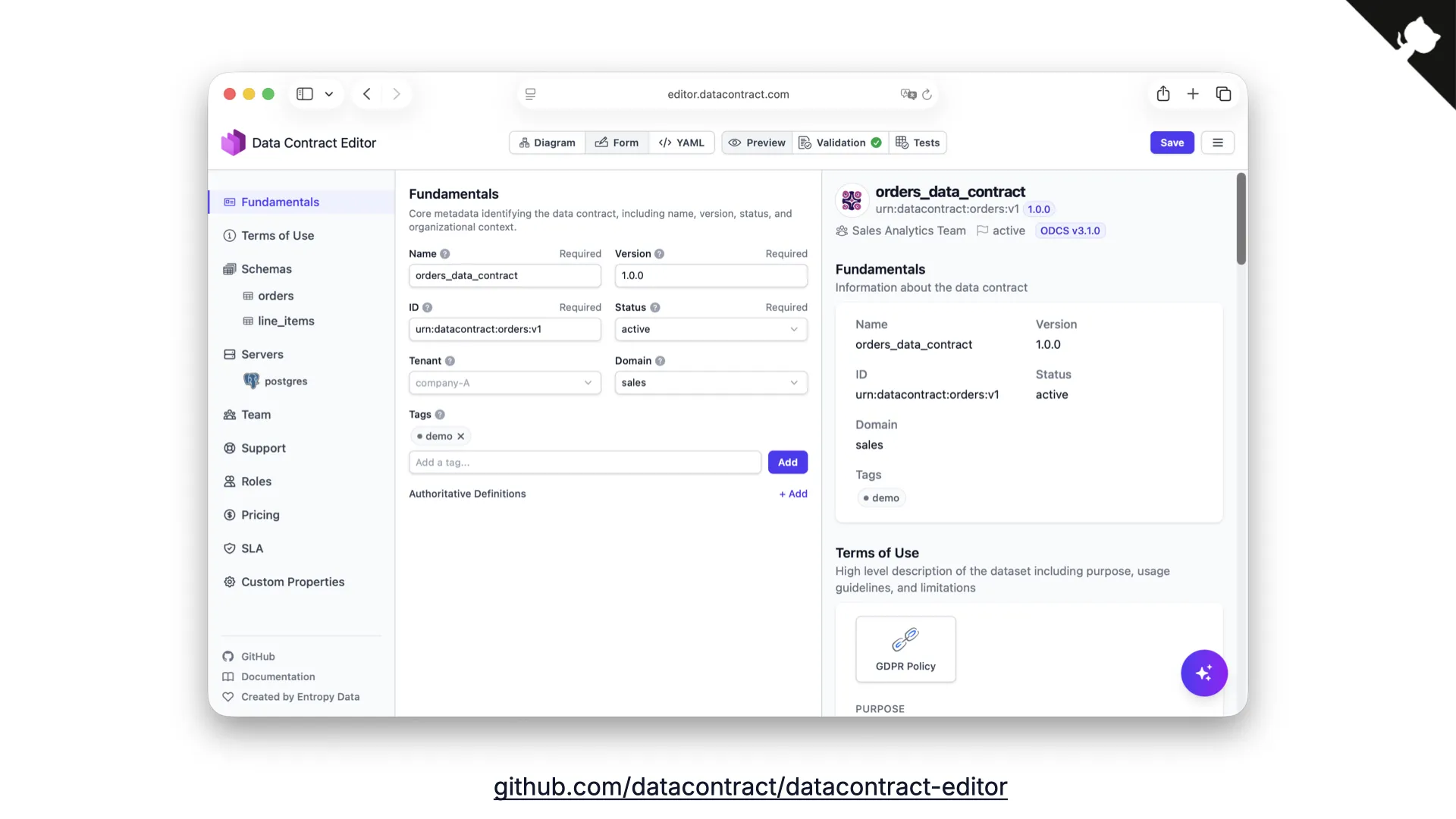
Data Contract Editor
Weil man manchmal manuell editieren möchte, haben wir den Data Contract Editor gebaut -- eine Open-Source-Web-Komponente, in der du deine Contracts visuell bearbeiten kannst. Die CLI ist direkt integriert, sodass du im Test-Tab deine Contract-Prüfungen mit einem einzigen Klick ausführen kannst.
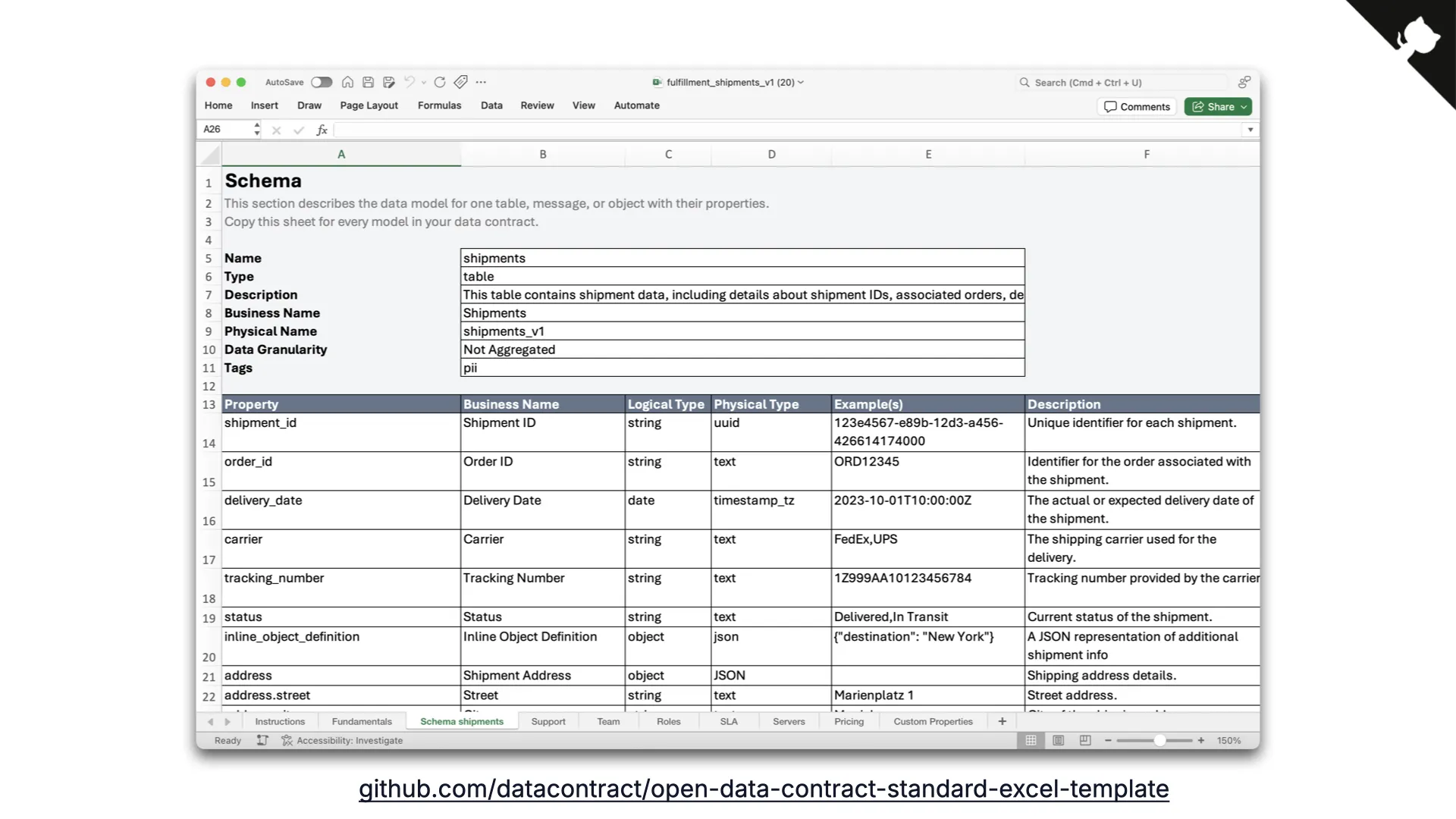
Excel-Template
Und die Erfahrung zeigt: Alles ist schön und glänzend, aber die Leute kommen immer wieder zu unserem guten alten Excel-Template zurück, das exakt auf den ODCS-Standard mappt. Für viele Leute ist Excel einfach das einfachste User Interface. Man würde es nicht denken, aber Excel stirbt in diesem Fall nicht aus. Und natürlich kann die Excel-Datei zum Testen in CI ebenfalls von der CLI gelesen werden.
Live-Demo: Contracts gegen echte Daten testen
In der Demo habe ich den Data Contract Editor geöffnet und einen Contract für zwei Tabellen gezeigt, die über eine Foreign-Key-Beziehung verbunden sind. Rechts sehen wir eine Vorschau mit Beschreibungen, Beispielen, Partitionierungsinfos, Primary Keys, Pflichtfeldern, dem verantwortlichen Team, dem Ort, an dem die Daten leben (Postgres), und den Service Level Agreements.
Das Spannende: Ich kann aus dem Editor heraus einen Live-Check ausführen und den Contract gegen die tatsächlichen Daten vergleichen. Der Report zeigt, welche Checks bestanden wurden. Intern haben wir dafür Soda Core eingesetzt.
Dieses Testergebnis kann zusammen mit dem Contract in einem Marktplatz veröffentlicht werden. Das schafft Vertrauen -- denn ich weiß, dass vor Sekunden ein Computer verifiziert hat, dass alles grün ist, und ich kann meinen Use Case oder meine Analyse bedenkenlos auf diesen Daten aufbauen.
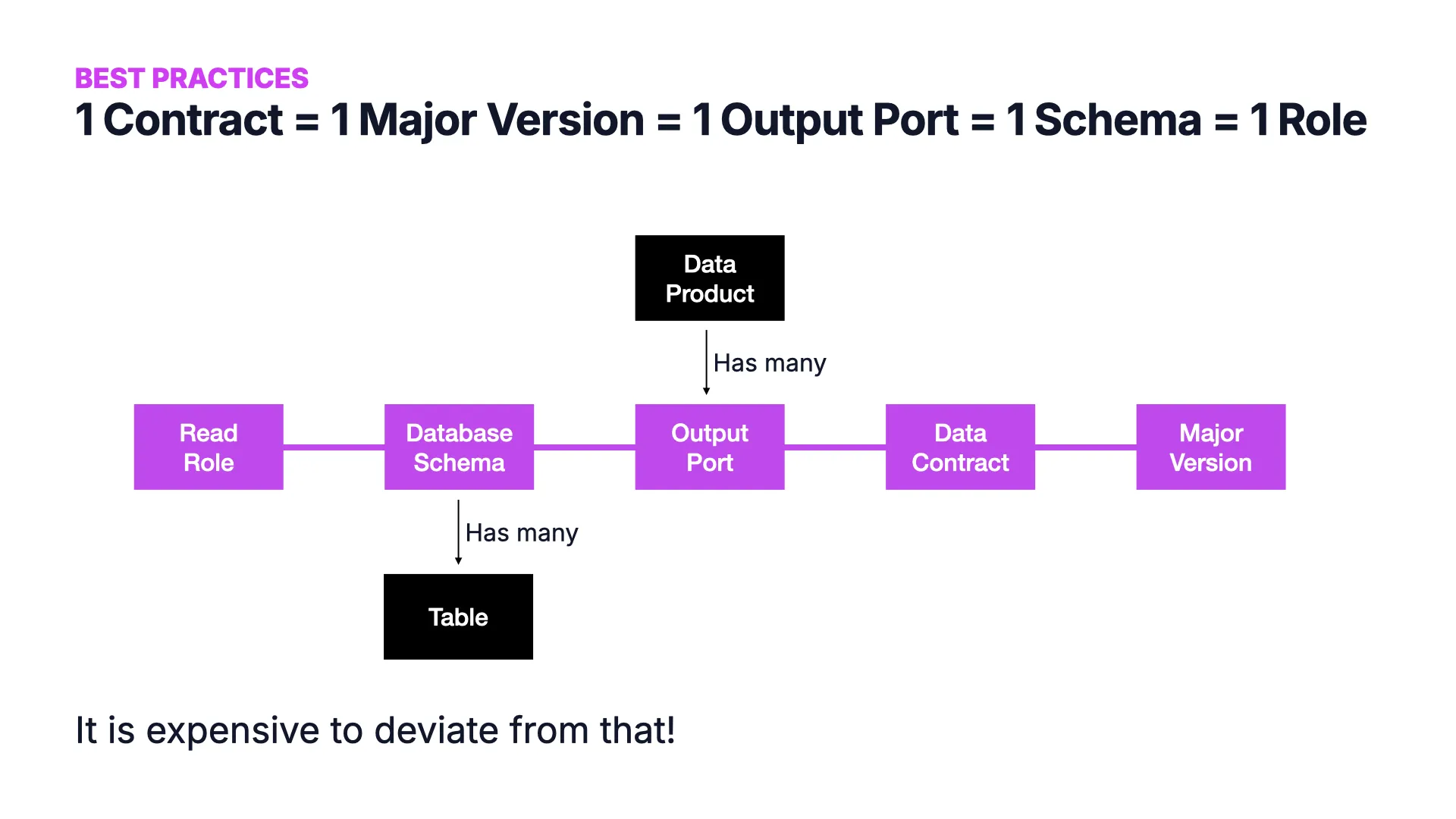
Best Practice: Das 1:1:1:1:1-Mapping
Ein Data Contract in einer Major Version mappt auf einen Output Port eines Datenprodukts, das auf ein Datenbankschema mappt (das mehrere Tabellen enthalten kann), und auf eine Lese-Rolle, die ich kaufen kann.
Wenn du dieses Mapping einhalten kannst, bleiben die Dinge einfach. Je mehr du davon abweichst -- ein Contract pro einzelner Tabelle (plötzlich zu viele Contracts) oder mehrere Rollen pro Contract (plötzlich zu komplex) -- desto komplizierter wird es. Es ist teuer, davon abzuweichen.

Best Practice: Natural Habitat
Data Contracts leben im Git-Repository des Datenprodukts. Du hast eine YAML-Datei für die Beschreibung des Datenprodukts und ein datacontracts/-Verzeichnis, in dem die Contracts als YAML-Dateien liegen.
Du kannst Contracts für Output Ports definieren (was ich anbiete) und optional auch für Input Ports (was ich konsumiere). Zum Beispiel: "Ich nutze nur die ersten drei Spalten deiner Tabelle. Alles andere ignoriere ich." Du kannst sogar deine eigenen Qualitätsprüfungen zusätzlich zu dem, was der Anbieter bietet, ergänzen.

Best Practice: Lifecycle und Evolution
Klassisches Change Management auf Basis von Major Versions. Breaking Changes erfordern eine neue Major Version. Non-Breaking Changes (wie das Hinzufügen einer neuen Spalte) lassen sich mit Minor- und Patch-Versionen abbilden, sodass V1 lange aktiv bleibt.
Wenn ein Breaking Change wirklich nötig ist, führe ich V2 neben V1 ein. Es gibt eine Übergangsfrist, in der beide Versionen parallel laufen -- V1 ist deprecated und V2 ist aktiv -- und die Consumers Zeit zum Migrieren bekommen. Es ist etwas Aufwand, aber es hält die Dinge sauber.

Data-First oder Contract-First?
Data-First ist der natürlichere Ansatz: Du hast bereits Daten auf Snowflake oder Databricks und stellst sie "unter Vertrag". Mit dem CLI-Import kannst du schnell eine erste Contract-Version generieren.
Aber ab dem Moment, in dem du einen Contract aktivierst, wird er zur Source of Truth. Wenn die Daten abweichen, sind die Daten falsch -- der Contract hat per Definition immer recht. Das bedeutet, du wechselst ganz natürlich zu Contract-First: Alle Änderungen gehen zuerst in den Contract, dann in die Implementierung.
Wir haben jetzt unseren ersten US-Kunden, und sie sind komplett Contract-First. Sie erstellen immer zuerst den Contract, dann bauen sie das Datenprodukt. Der Vorteil: Du kannst präzise diskutieren, wie die Schnittstelle aussieht, und danach ist es einfach zu bauen. Mit KI schreiben sich die Transformationen praktisch von selbst, wenn die Schnittstelle klar definiert ist.

Best Practice: Automatisierung
Du kannst an drei Stellen automatisieren:
- Täglich pro Datenplattform --
datacontract testausführen, um Contracts laufend gegen Produktionsdaten zu verifizieren. - Bei Commit in PRs --
datacontract lint(inklusive Unternehmensregeln) unddatacontract test --server=stagingausführen, um Probleme vor dem Merge zu finden. Unternehmen können Regeln durchsetzen wie "jedes Feld muss eine Datenklassifizierung haben" -- wenn nicht, geht der PR nicht durch. - Bei Commit auf main --
datacontract publishausführen, um den Contract auf deinen Datenmarktplatz zu pushen, wo die Leute die Daten sehen und ihnen vertrauen können.
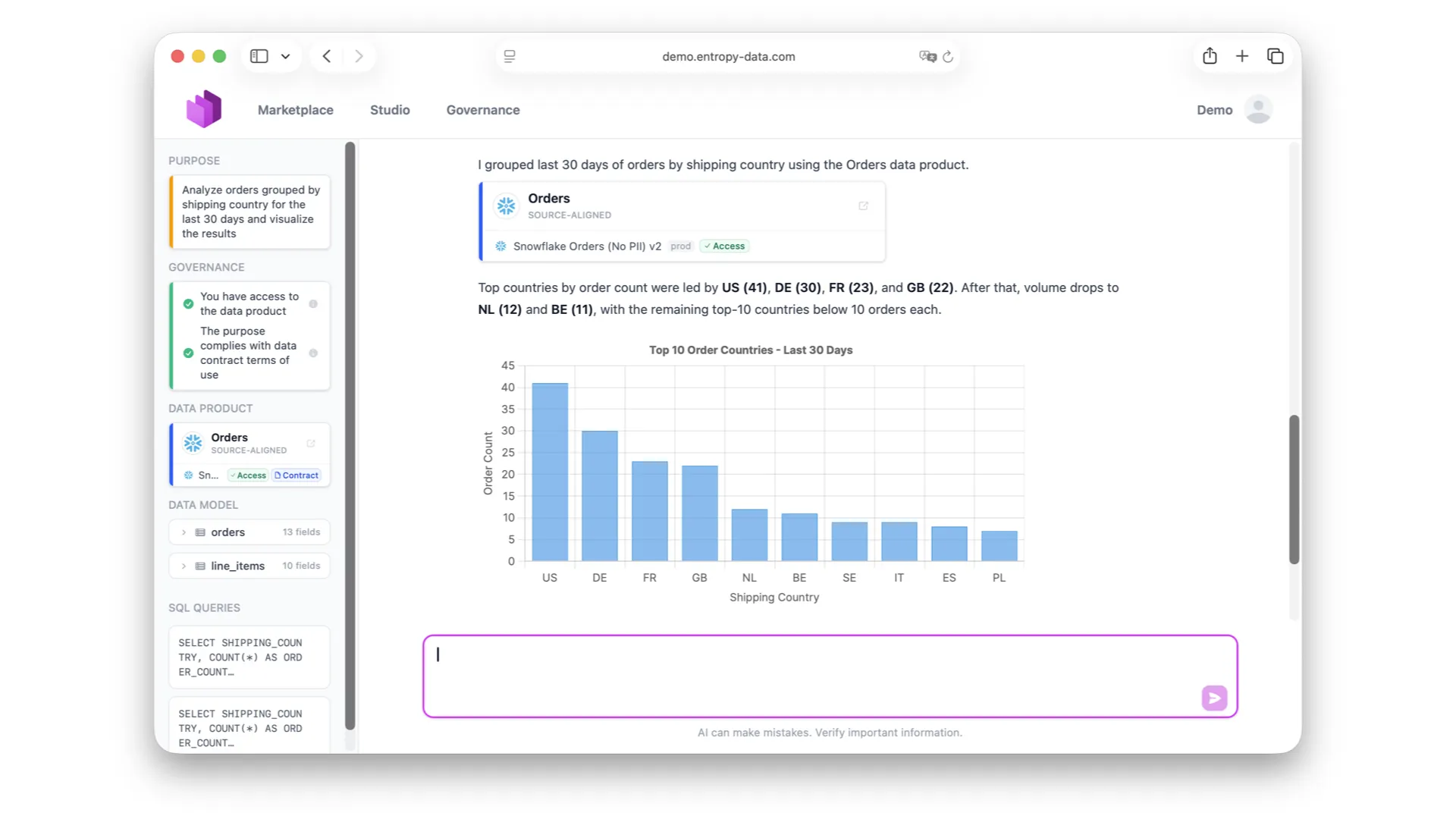
Warum KI-Agenten Data Contracts brauchen
Ein Data Contract ist per Definition die Source of Truth für Metadaten über einen angebotenen Datensatz. Was könnte für eine agentische KI besser sein, als sich den Contract anzuschauen, zu prüfen, ob er für die anstehende Aufgabe nützlich ist, mehrere Contracts zu vergleichen und dann die durch den am besten passenden Contract geschützten Daten zu nutzen?
In der Demo habe ich den KI-Agenten gefragt: "Wer sind meine Top-Kunden?" Im Hintergrund suchte er nach Datenprodukten mit Contracts, fand das richtige, prüfte den Contract, um zu verifizieren, dass er die Aufgabe erfüllen kann, generierte eine SQL-Query, führte sie aus und lieferte die Antwort.
Das ist die Zukunft. Egal, welchen KI-Client du nutzt -- Agenten mit Datenhunger kommen. Sie wollen auf Snowflake, Databricks zugreifen, wo auch immer die Daten leben. Der Data Contract und die Governance-Schicht zwischen Agenten und Daten wirken als Verteidigungslinie.
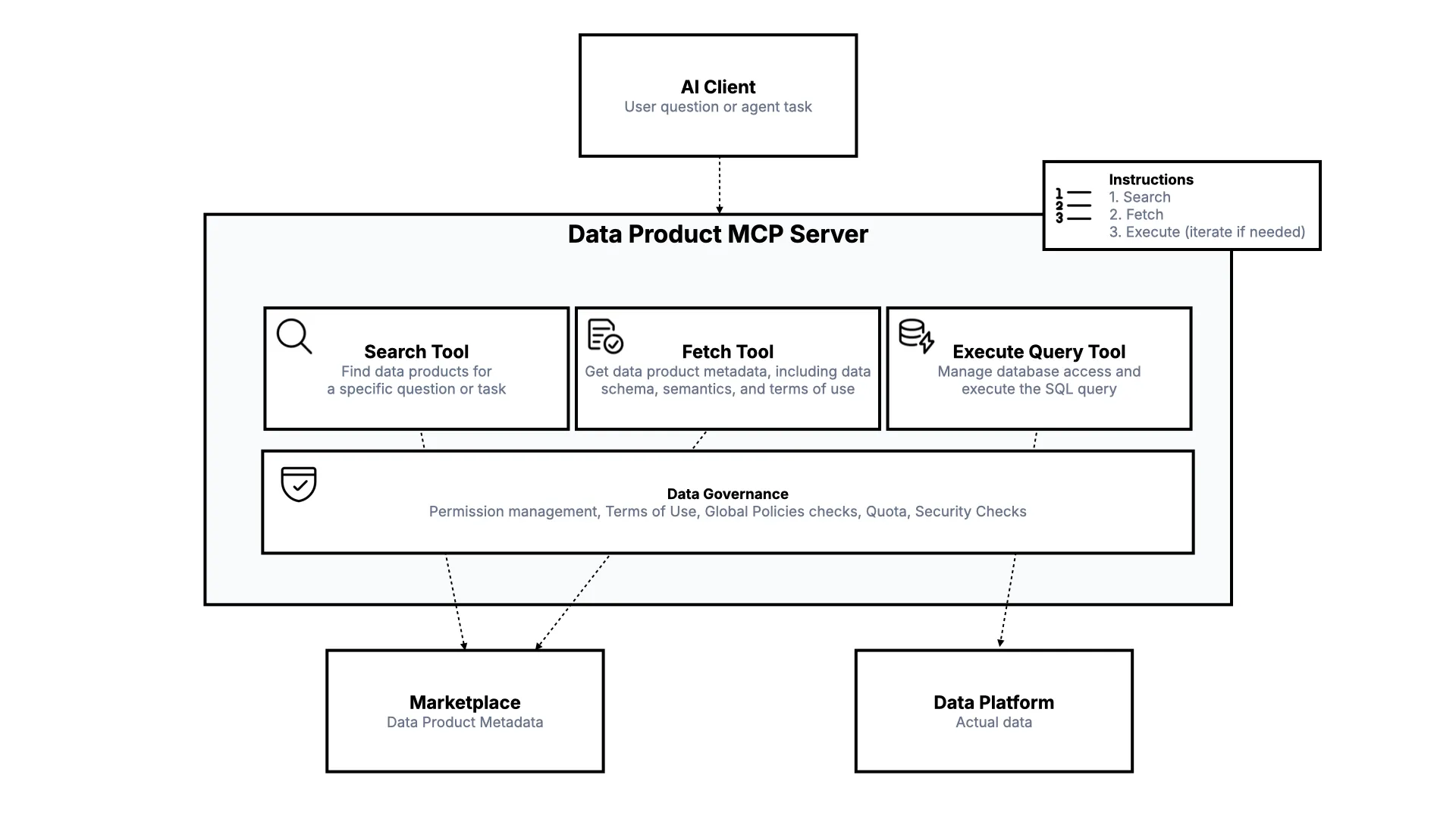
Die Architektur: Data Product MCP Server
Aus Architektursicht: Der KI-Client sitzt oben, die Datenplattform, auf der die Daten leben, ist unten, und ein Marktplatz hält die Metadaten. Der KI-Agent interagiert mit einem Data Product MCP Server, der suchen, Metadaten mit dem Contract abrufen und Queries ausführen kann.
Die entscheidende Schicht dazwischen ist Governance: Berechtigungsmanagement, Prüfung der Nutzungsbedingungen, globale Policies, Quotas und Security-Checks. Das wird passieren, weil es einfach zu naheliegend ist, es nicht zu tun.

ODCS wird überall sein
Swagger 1.0 wurde 2011 veröffentlicht, und OpenAPI ist heute überall.
ODCS 3.0 wurde 2025 veröffentlicht. Ich glaube, dass Data Contracts in fünf Jahren genauso allgegenwärtig sein werden, wie es OpenAPI heute in der API-Welt ist.
Danke
Danke fürs Zuhören. Wenn du das Gespräch fortsetzen möchtest, findest du mich auf LinkedIn, erreichst mich unter simon.harrer@entropy-data.com oder besuchst www.entropy-data.com. Und wenn du Open Source magst, gib datacontract-cli einen Star auf GitHub.
Q&A
Ausgewählte Fragen aus dem Publikum nach dem Vortrag.
F: Wie holen wir die Business-Seite ins Boot? Das fühlt sich alles noch sehr technisch an. Selbst deine Agenten-Demo hat Kunden-IDs zurückgegeben, keine Namen wie "Zalando" oder "H&M".
Zwei Antworten. Erstens: Der Grund, warum die Demo kryptisch aussah, war, dass der Agent nur Zugriff auf die IDs hatte -- er hatte keine Berechtigung, sie zu Klartextnamen aufzulösen. Mit den richtigen Berechtigungen würde er das tun. Zweitens: Die Data Contracts sind gezielt darauf ausgelegt, Business-Sprache zu transportieren. Wir haben Business-Namen für alle Spalten und Tabellen. Du kannst ein Data Dictionary oder Glossar definieren -- etwa "das bedeutet eine Bestellnummer" -- einmal, und alle Contracts referenzieren diese Definition. Außerdem kannst du jetzt Beispielfragen, Antworten, Synonyme und ergänzendes Wissen an einen Contract anhängen, damit die KI noch besser antworten kann. Das ist alles für Business-User optimiert.
F: Ich komme aus der Produktion/Fertigung. Kann ich Beziehungen zwischen Datenpunkten modellieren -- etwa den Durchfluss durch ein Rohr, wohin er geht und wie viel ankommen soll?
Nicht direkt, weil Contracts auf Schema-Ebene arbeiten, nicht auf Instanz-Ebene. Wir betrachten, welche Spalten existieren, und treffen Aussagen über Spalten, aber nicht über einzelne Zeilen. Wenn jeder Datenpunkt im Grunde seine eigene Tabelle ist, kommst du in den Bereich von Digital Twin und Asset Administration Shell, und das ist eine andere Welt. Du könntest theoretisch für jede Tabelle einen Contract anlegen, aber du musst aufpassen, dass der Contract am Ende nicht größer wird als die Daten selbst.