Talk
Let's Talk About Data Contracts: Standards, Tooling & Best Practices
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · March 19, 2026
In this talk at the INFOMOTION Data & AI Meetup Cologne, I cover everything you need to know about data contracts: what they are, why they matter, the Open Data Contract Standard (ODCS), open source tooling, best practices for versioning and lifecycle management, and why agentic AI will make data contracts as ubiquitous as OpenAPI.

Note: The talk was delivered in German. The transcript below is an English translation.
Thanks to Prof. Dr. Ana Moya, Peter Baumann, and INFOMOTION for organizing the meetup and the invitation to speak, and Jochen Christ for helping shape the talk.

Introduction
Hi, my name is Simon. I am a software engineer at heart who wandered into the world of data about four years ago. I come from the Java ecosystem -- I co-authored a book on clean code in Java called "Java by Comparison". Fun fact: that book was written before AI, and there is currently a lawsuit because Anthropic's models illegally processed it for training.
I worked at INNOQ for a long time as a consultant, and in 2025, we spun out a startup from INNOQ. I am co-founder and CEO at Entropy Data, where we build a data product marketplace based on data contracts.
Together with colleagues, I co-translated the "Data Mesh" book into German, launched datamesh-architecture.com and datacontract.com, co-maintain open source tools like the Data Contract CLI and Data Contract Editor, and serve on the Technical Steering Committee at the Linux Foundation's BITOL project for data contract standards. So I think I can speak quite competently about data contracts today.
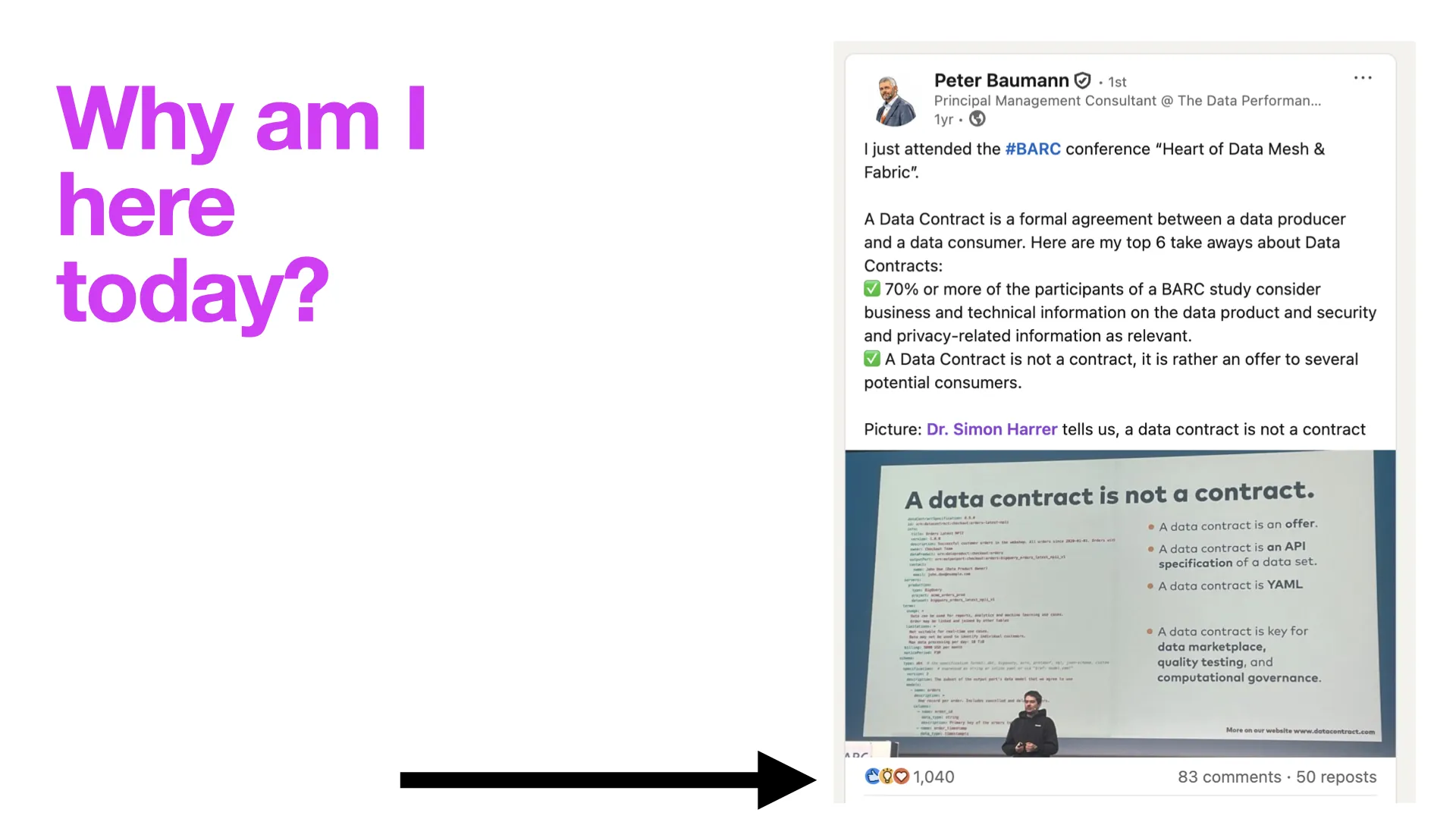
Why Am I Here Today?
A quick anecdote. About a year and a half ago, I gave a talk at the BARC "Heart of Data Mesh & Fabric" conference, and Peter Baumann from INFOMOTION posted it on LinkedIn. It got over 1,000 likes -- went quite viral -- with the title "A Data Contract Is Not a Contract." That was a bit provocative, of course, but people clicked on it.
So let us talk about data contracts. And when we talk about data, we are really talking about trust. Trust in data. That is the essential thing.
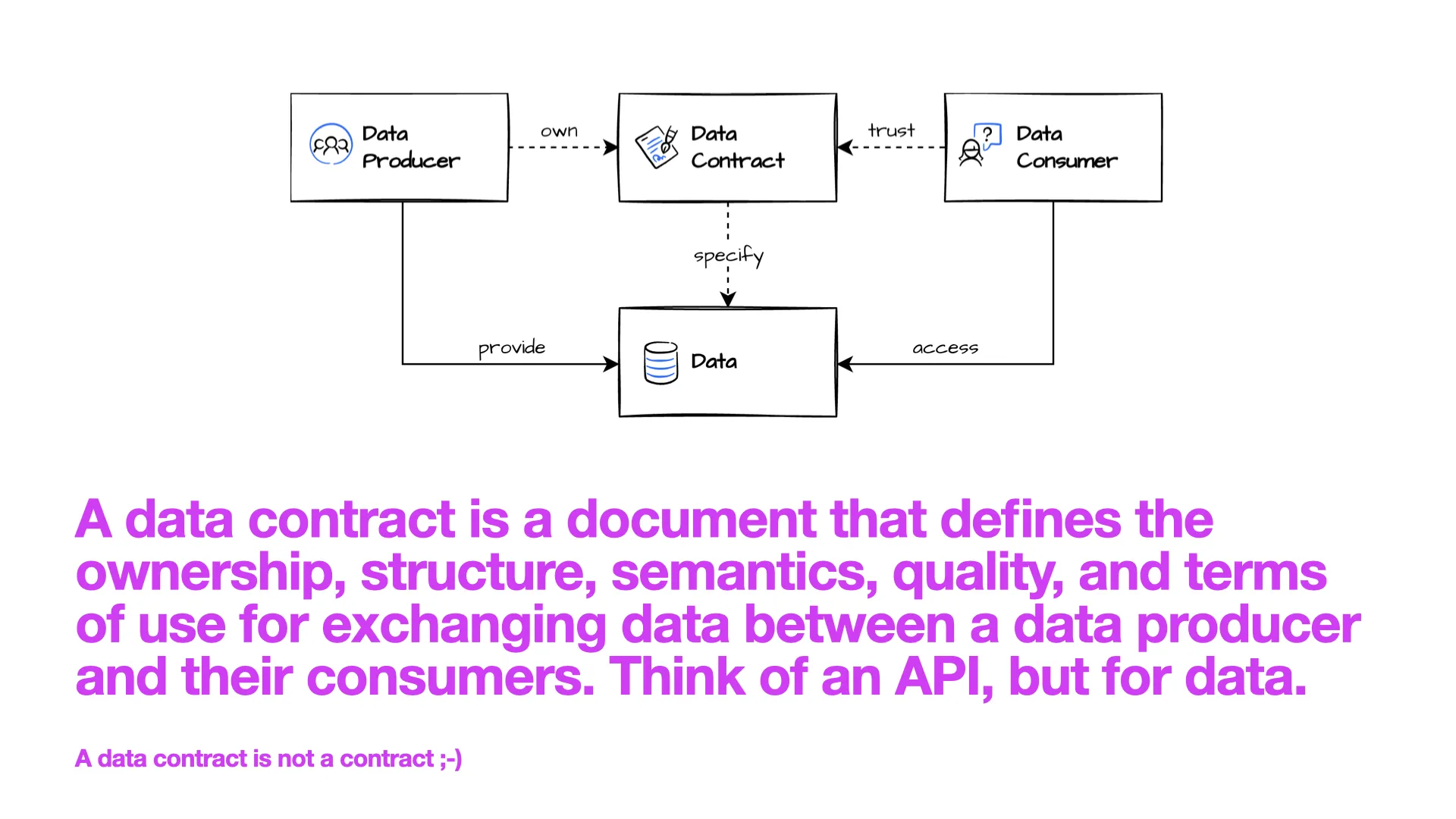
What Is a Data Contract?
A data contract is a document that defines ownership, structure, semantics, data quality, and terms of use for exchanging data between a data producer and their consumers -- like an API specification, but for the data world.
In the diagram you can see: the consumer cares about using the data, but above all about trust. The data contract plays a crucial role because the data producer offers data and specifies their promises in the contract. If those promises match the actual data, the consumer can use the data and trust the contract.
A data contract has many elements. We will go through them in detail, but first I want to share the origin story of how we ended up with standards.

The Gap: No Specification for Data APIs
A few years ago, in the world of software and data, there was a very clear answer for REST APIs: OpenAPI (the successor to Swagger). For asynchronous interfaces like Kafka, there was AsyncAPI. But for data -- if I wanted to share a large dataset -- there was no good answer. There were a few isolated solutions, but nothing standardized.
And yet we had plenty of data APIs: CSV on SFTP (yes, I see the first chuckle), JSON on S3, SQL tables on BigQuery, Iceberg files, Snowflake views, Delta Live Tables. These are all interfaces. Someone built something critically important on top of them, and if that interface breaks, everything downstream breaks too.
We needed a way to trust that when I consume a CSV from an SFTP server, it stays stable and the data has the quality that was agreed upon.

Everyone Built Their Own Format
As data became more decentralized, more and more teams started sharing data with more and more consumers. It was no longer just one data team with one Oracle server and one data warehouse.
Many companies saw the need for data contracts -- and every single one built their own format. They all had the same problem and all built their own solutions. The only thing they had in common? Almost everyone chose YAML. Well, some used JSON, and some even used Word and Excel. But then a standard emerged.
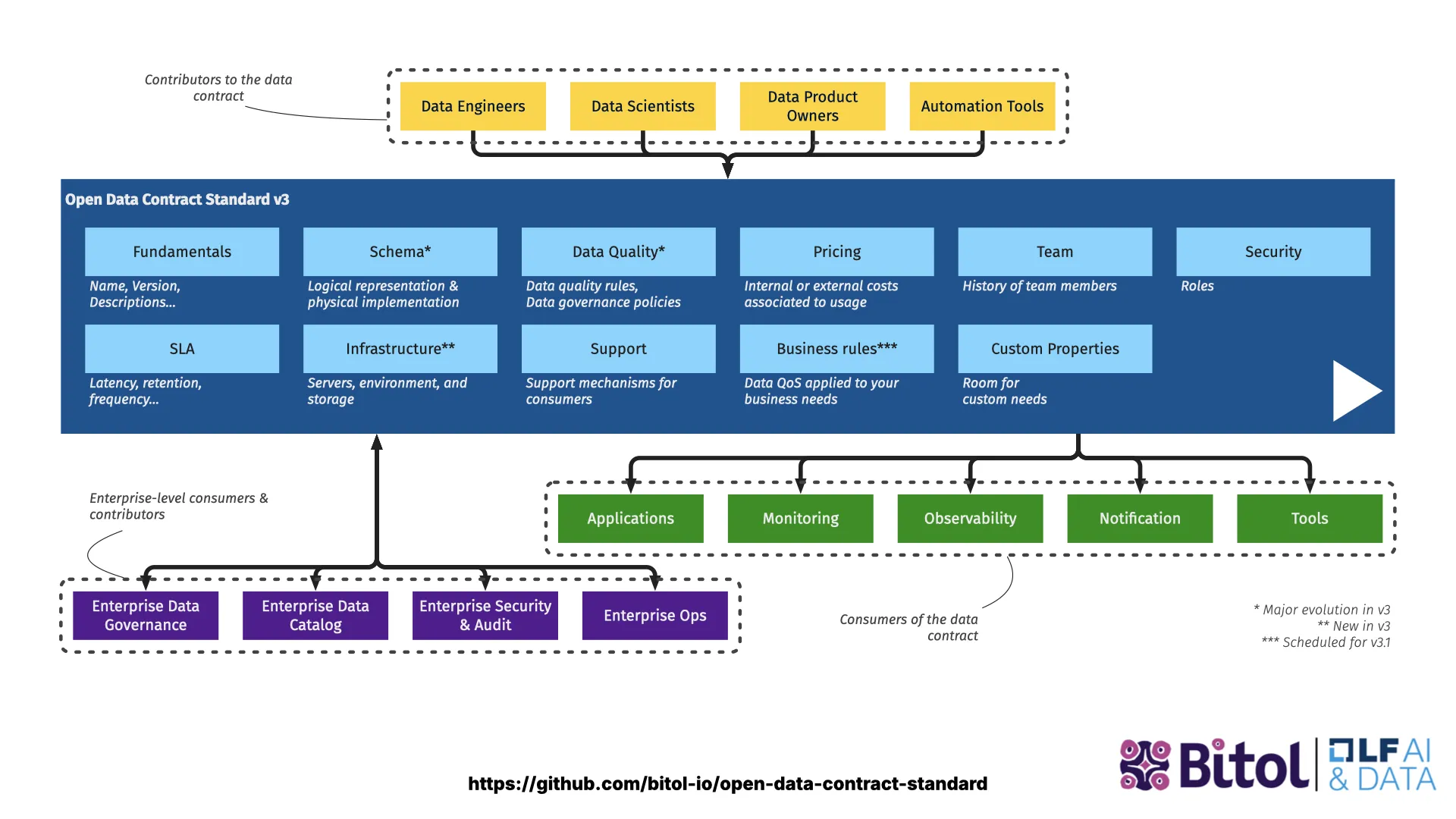
The Open Data Contract Standard (ODCS)
The standard that emerged is the Open Data Contract Standard. It originally came from PayPal -- they were one of those companies that had developed their own data contract format. They open sourced it under the Apache License and later donated it to the Linux Foundation.
I joined the standardization committee. We removed the PayPal-specific elements and expanded it so that companies other than PayPal could use it. Since 2025, it is in version 3 (now 3.1), and you can really use it well. We are seeing strong adoption this year -- Collibra has committed, OpenMetadata has committed and already built features for it.
It covers fundamentals, schema, data quality, pricing, team, security, SLAs, infrastructure, support, business rules, and custom properties.
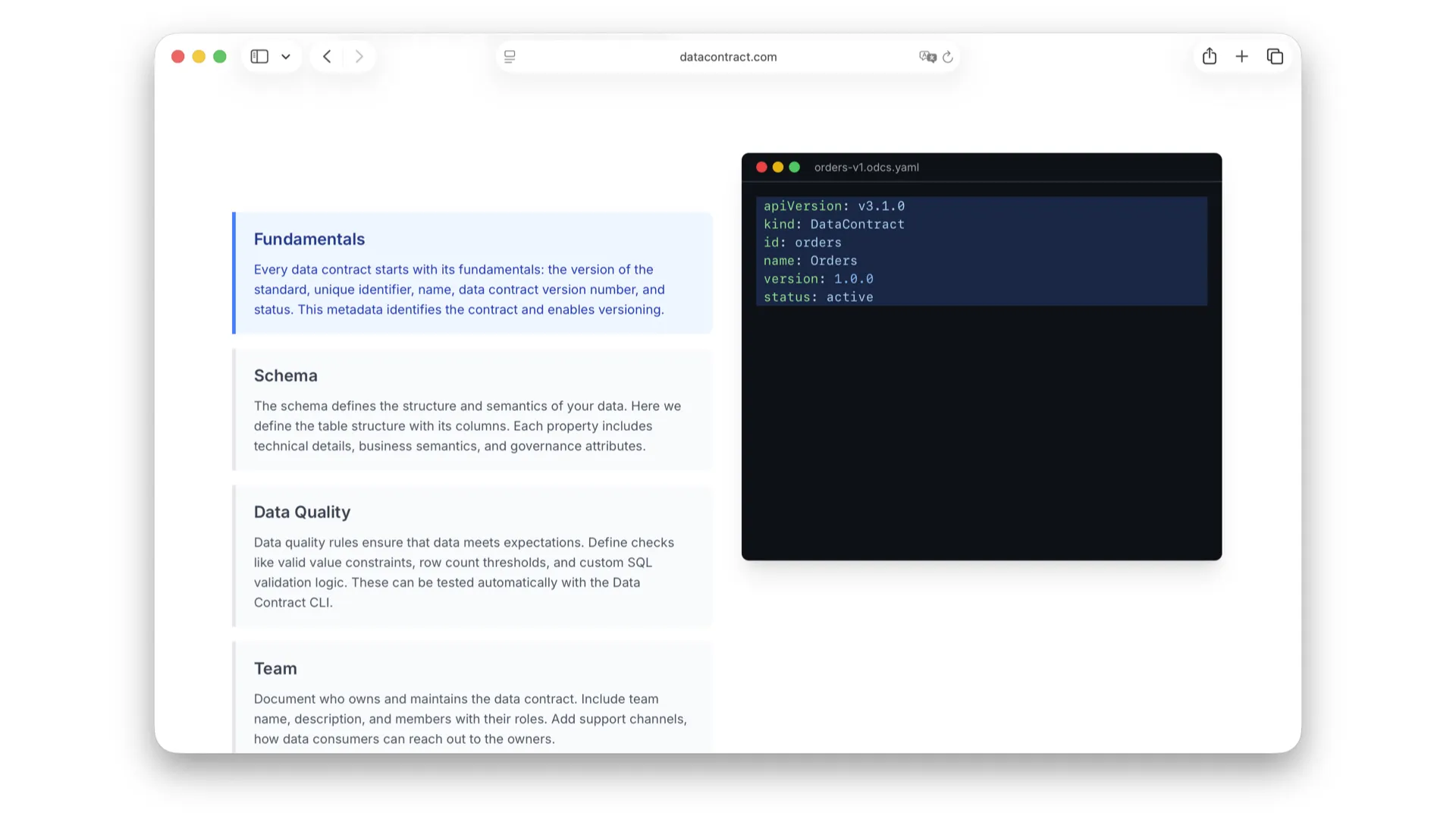
Fundamentals
In the fundamentals block, we define the ID, name, version, and a status for phasing contracts in and out. How do I version data contracts? I will get to that later in the best practices section. All of these details can be explored at datacontract.com.
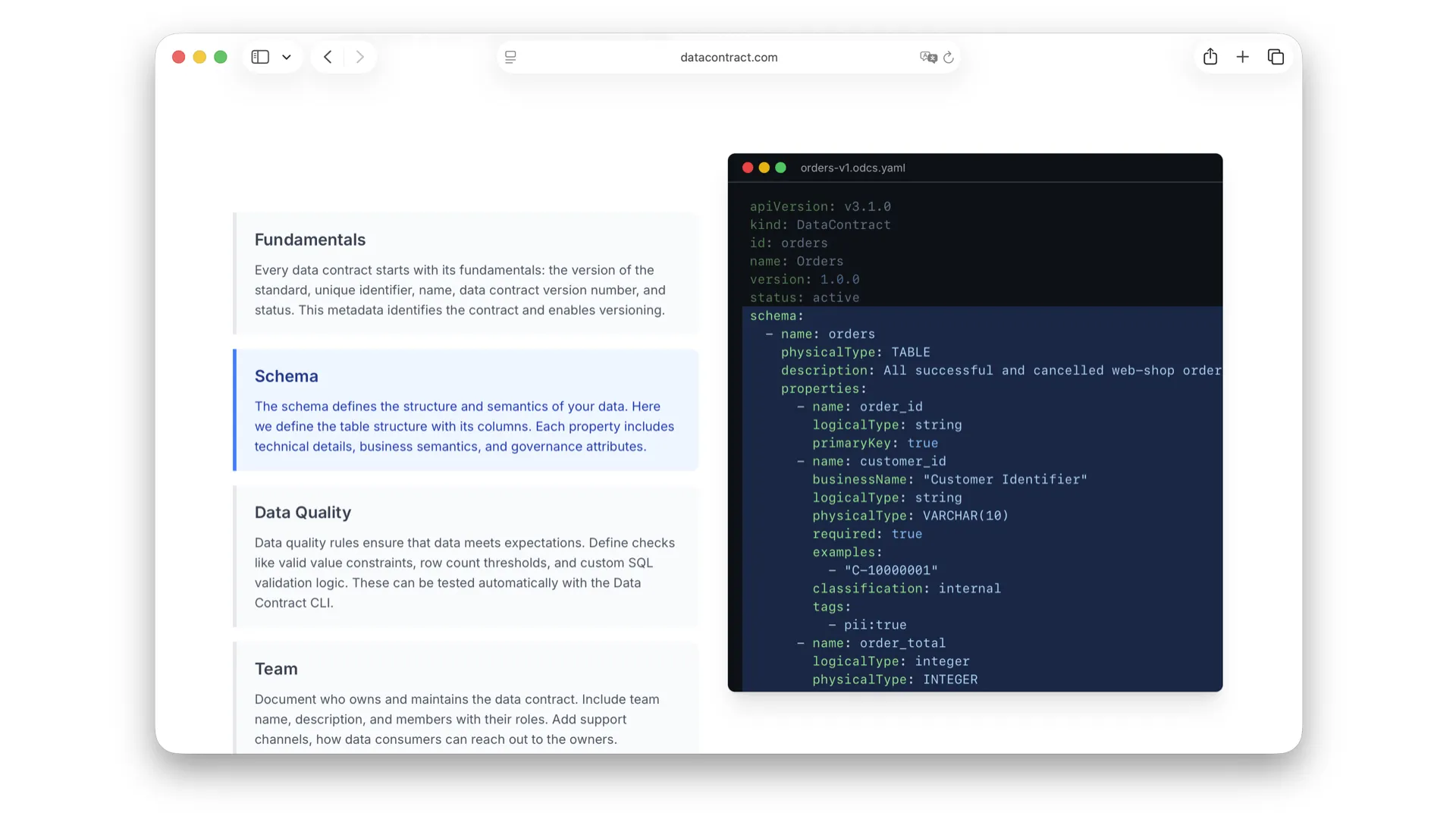
Schema
The schema description is essential -- it defines how the data is structured. You define tables and their columns. What is interesting: we have both physical types and logical types. We also include examples, data classification, and business names -- it is already moving in the direction of semantics. You can describe the schema in great detail.
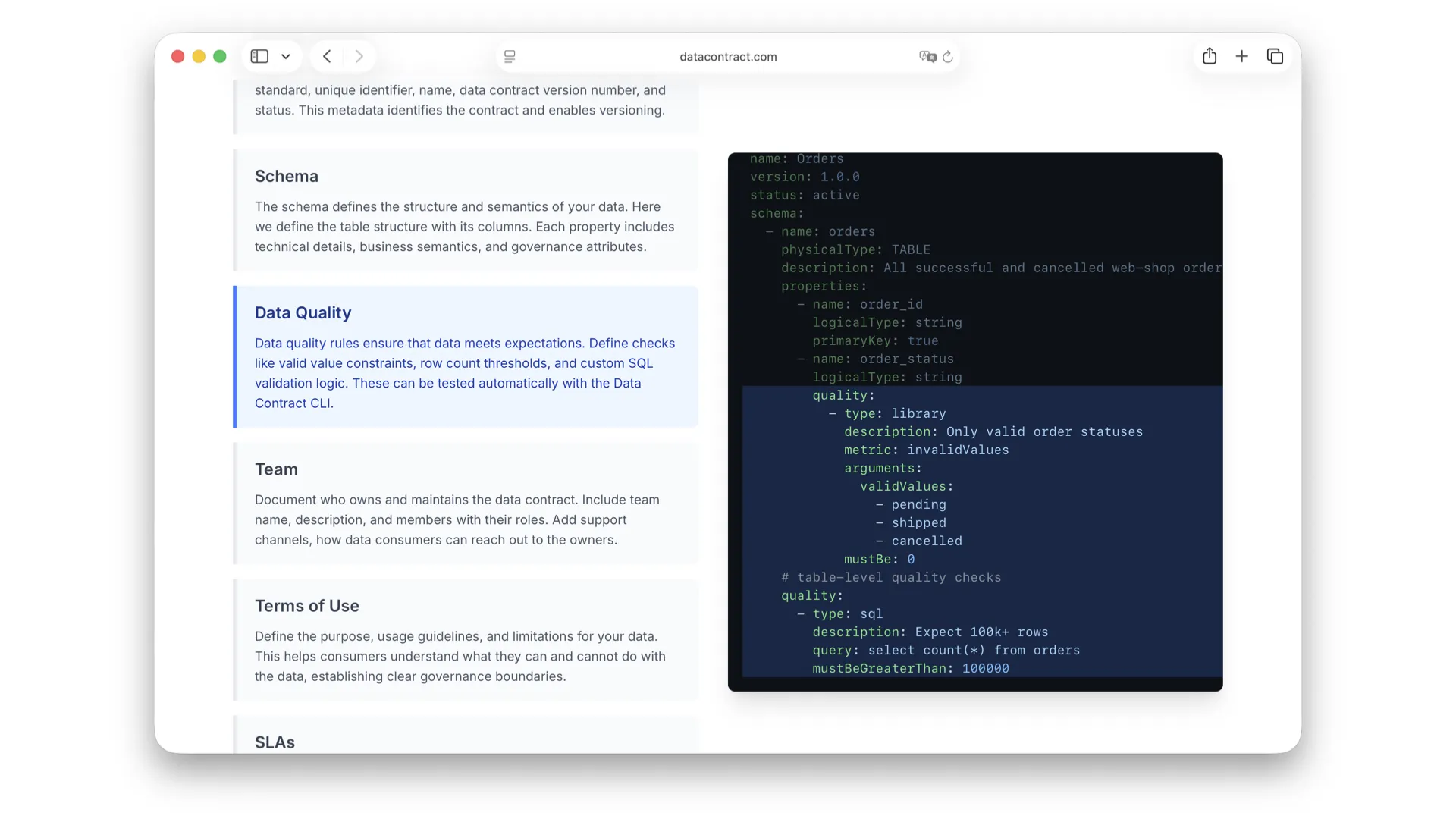
Data Quality
Data quality is part of the contract because it is part of my promises as a data provider to my consumers. Here we have a data quality check for invalid values using a library like Soda or Great Expectations, and SQL-based quality checks that are executable. With the right tooling, you can automatically verify whether the contract is upheld by the actual data.
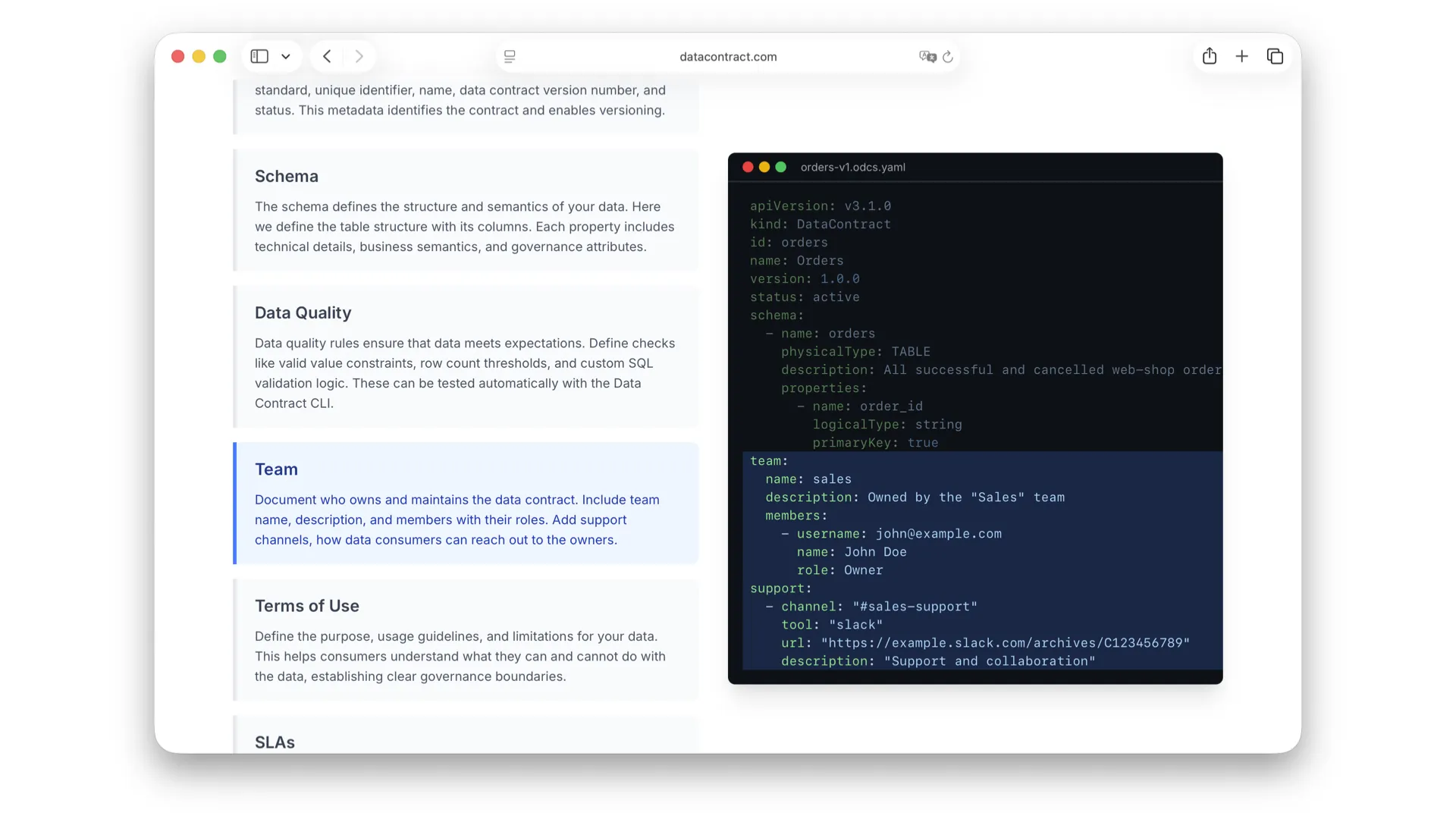
Team
The team section tells you who provides these data and how to contact them. What is the Slack channel? What is the preferred support channel? Do they actually respond? This is crucial -- when something goes wrong with the data, you need to know who to reach out to.
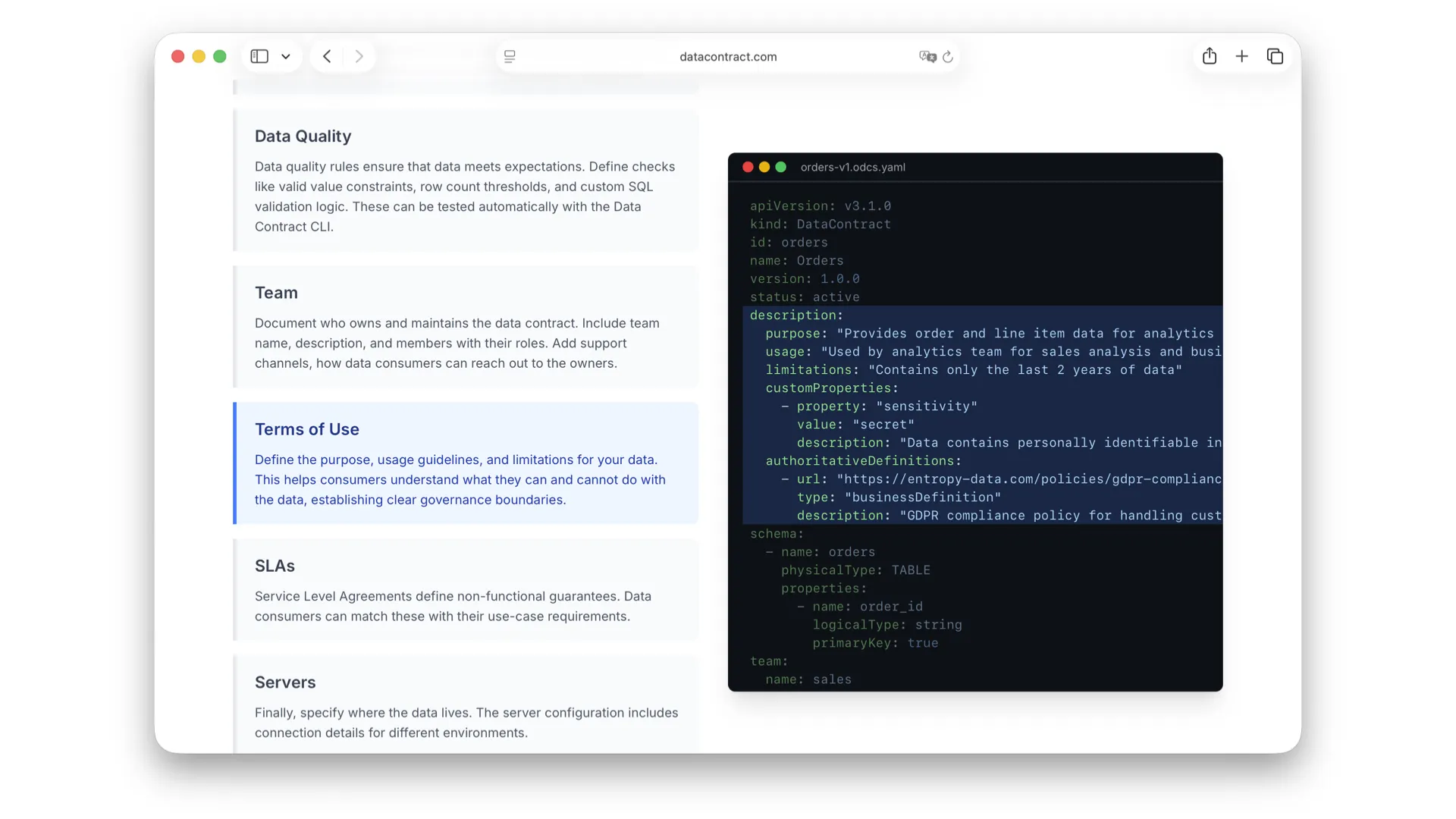
Terms of Use
The terms of use define what I am allowed to do as a consumer with the data, and what not. Are there license conditions? Does GDPR apply? Are there internal data protection policies I have imposed on myself? What may I do with the data and what may I not? This also builds trust.
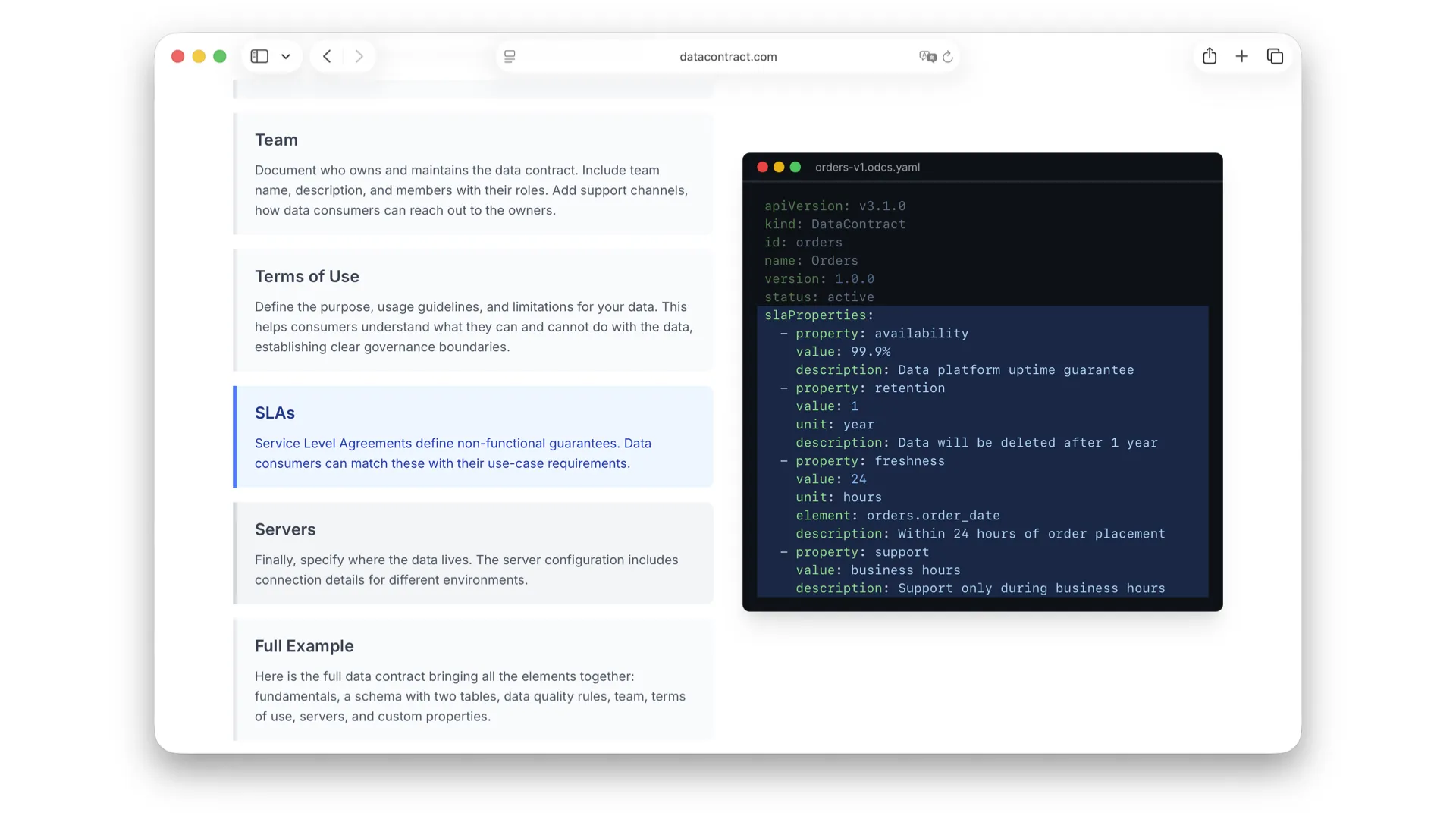
Service Level Agreements
Service Level Agreements are classic: data retention, freshness, latency. These are essential and can also be automatically verified. Here I have them guaranteed in writing by the provider -- black on white.
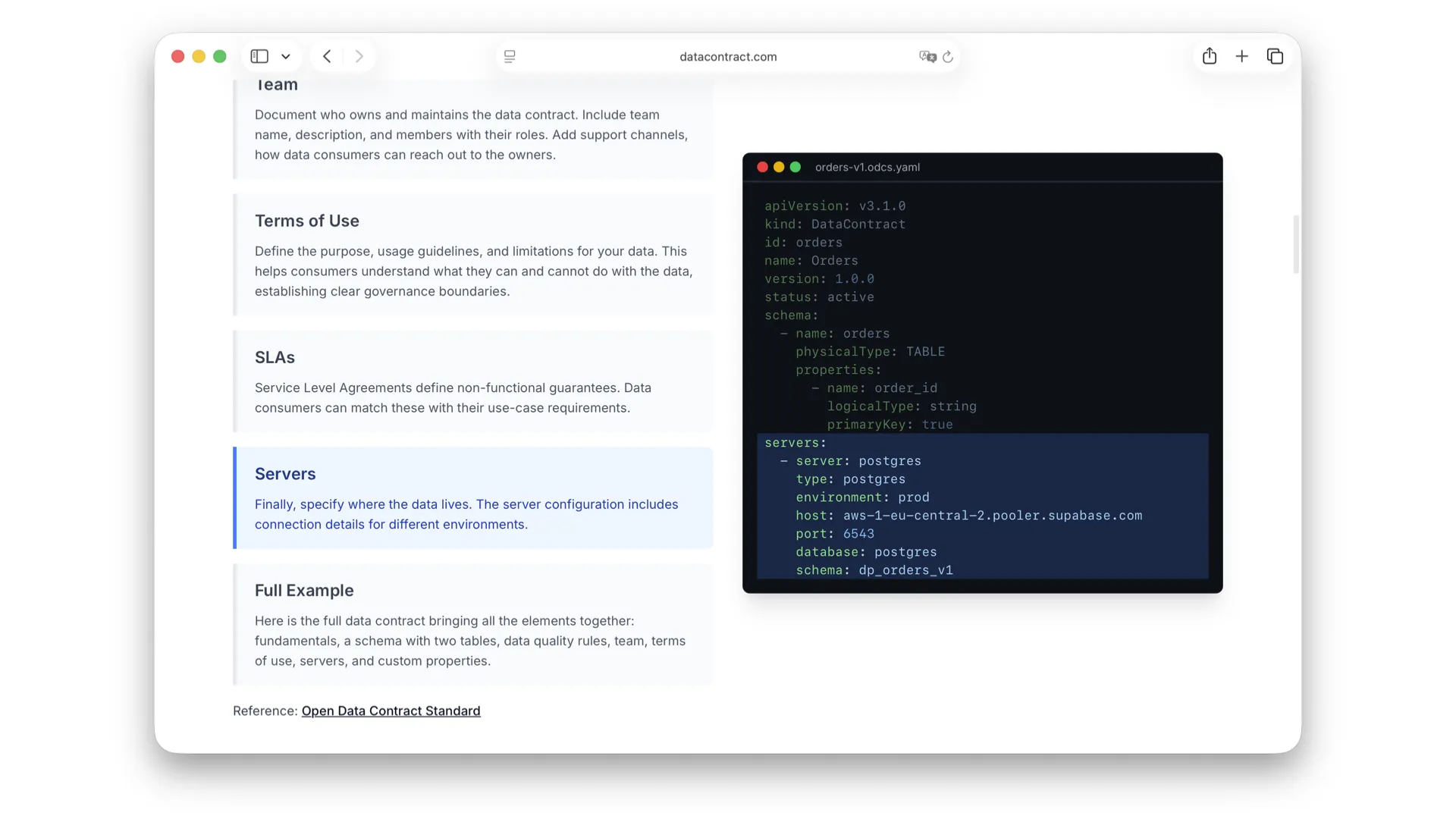
Servers and Infrastructure
And finally: where does the data actually live? Here I have an example with Postgres on Supabase. But it can be anything -- Databricks, Snowflake, a CSV on S3, or any other data platform.
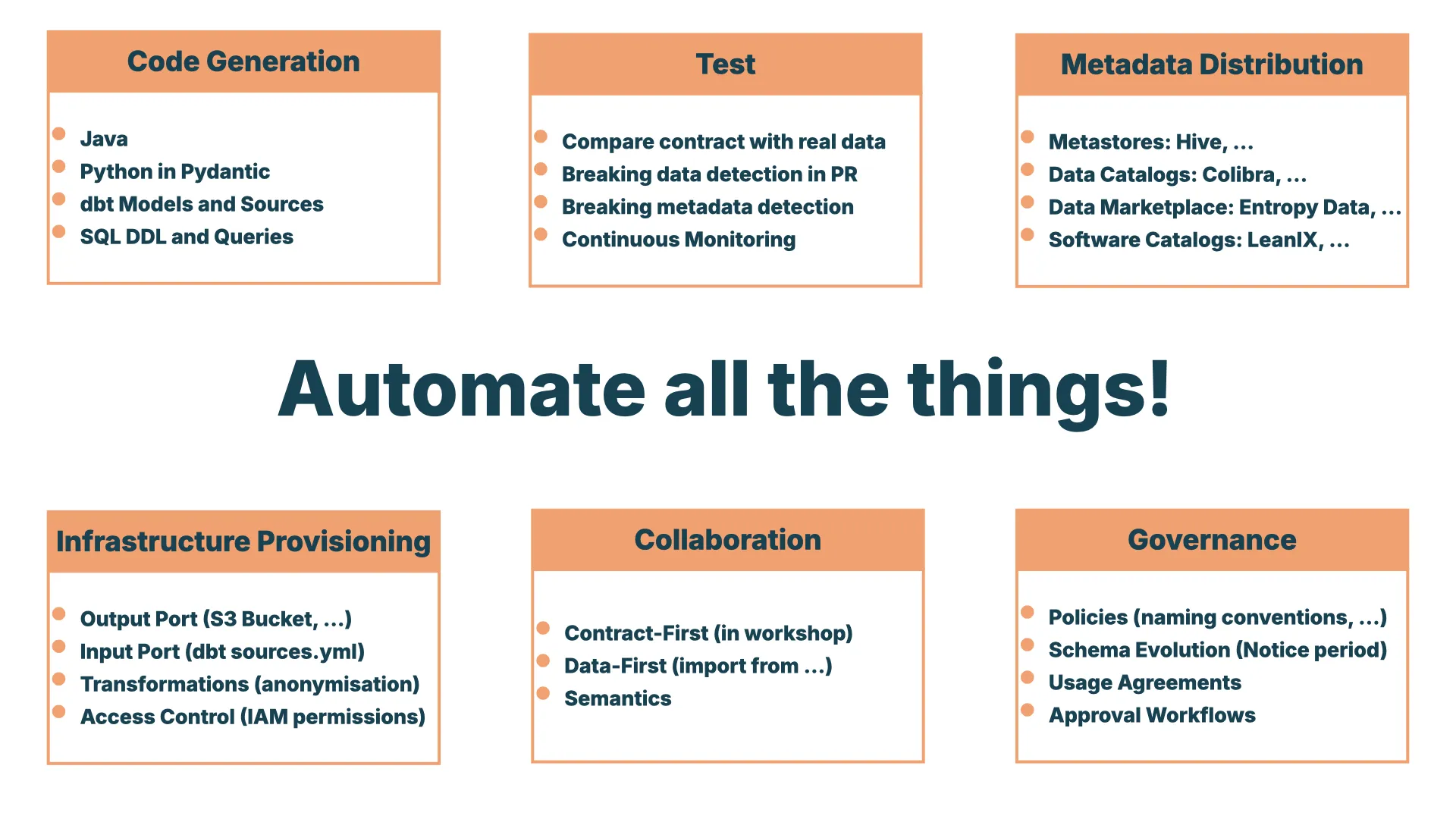
Automate All the Things
Once I have a contract with all this information, I can do a thousand things with it:
- Test -- lay the data and the contract side by side and check if they match. If they do not, raise an alert and escalate.
- Generate code -- produce SQL DDL, a dbt model, or even have AI build the entire dbt project. When input and output are clear, AI can fill in the gap.
- Continuous monitoring -- constantly check whether the contract still matches the data as it keeps being enriched.
- Distribute metadata -- push the contract (the source of truth) into catalogs and metastores, and use it as documentation.
- Provision infrastructure -- create S3 buckets, set up IAM roles for a data marketplace, so others can easily access the data protected by the contract.
Extremely powerful for automation.
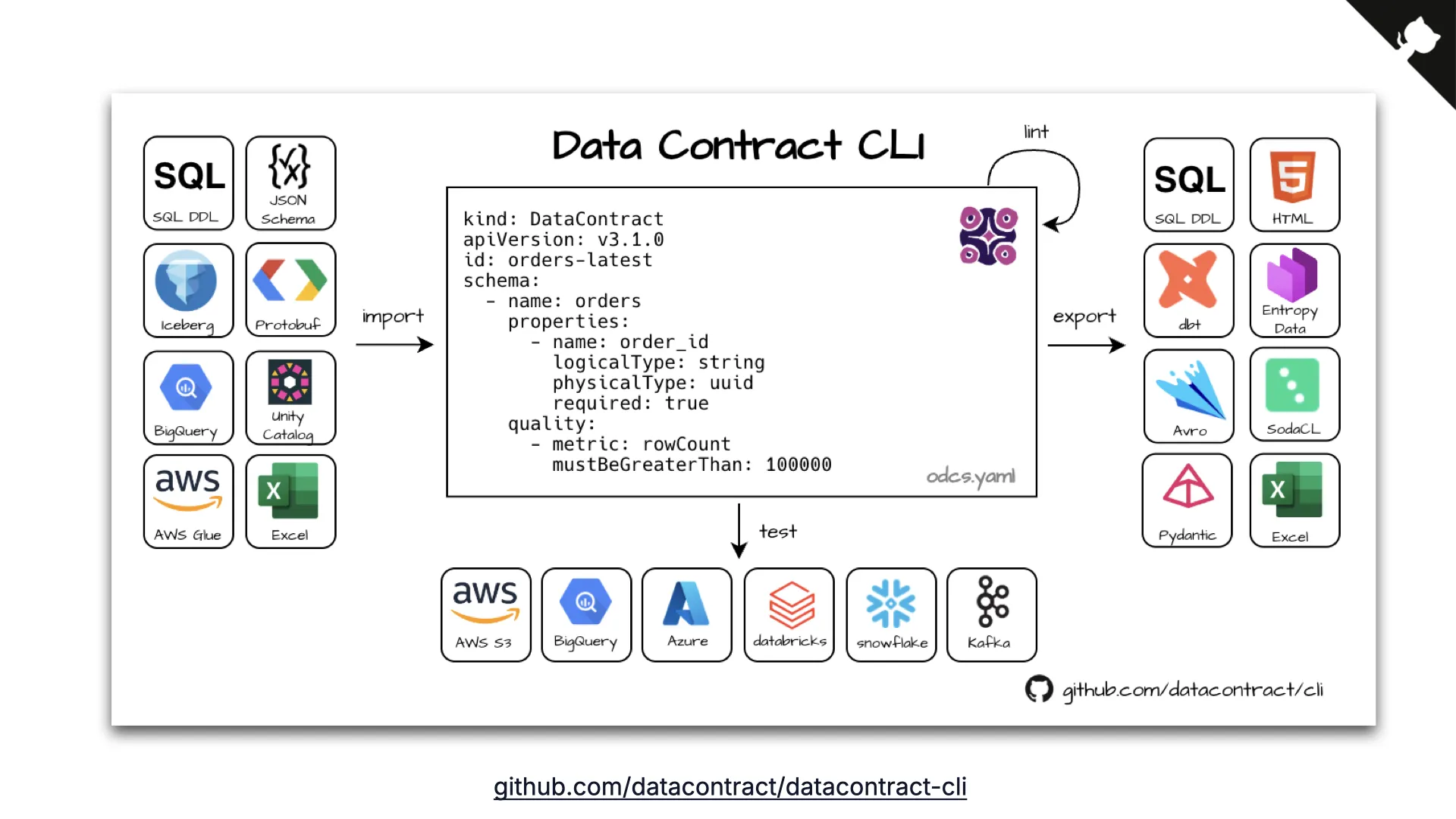
Data Contract CLI
The essential tool is the Data Contract CLI, an open source project with about 800 GitHub stars. It reads a contract, connects to any data platform you know, and automatically checks whether what is specified in the contract matches the actual data on the platform. You get a report.
You can run this in a pipeline, in Airflow, track results over time. It can export to many different formats and import from existing data sources to quickly generate your initial contract.
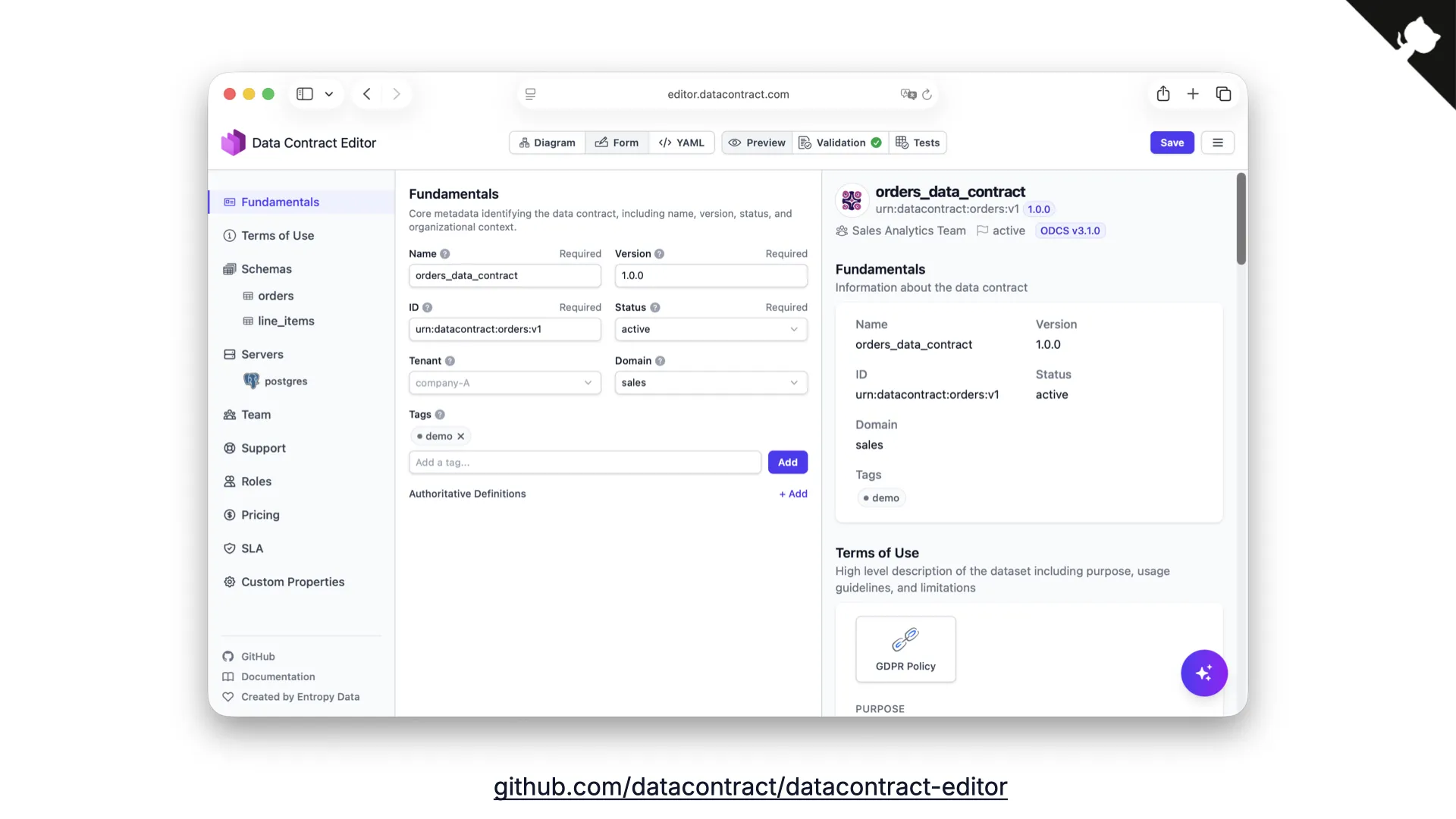
Data Contract Editor
Because sometimes you want to edit manually, we built the Data Contract Editor -- an open source web component where you can visually edit your contracts. The CLI is integrated directly, so from the test tab you can run your contract checks with a single click.
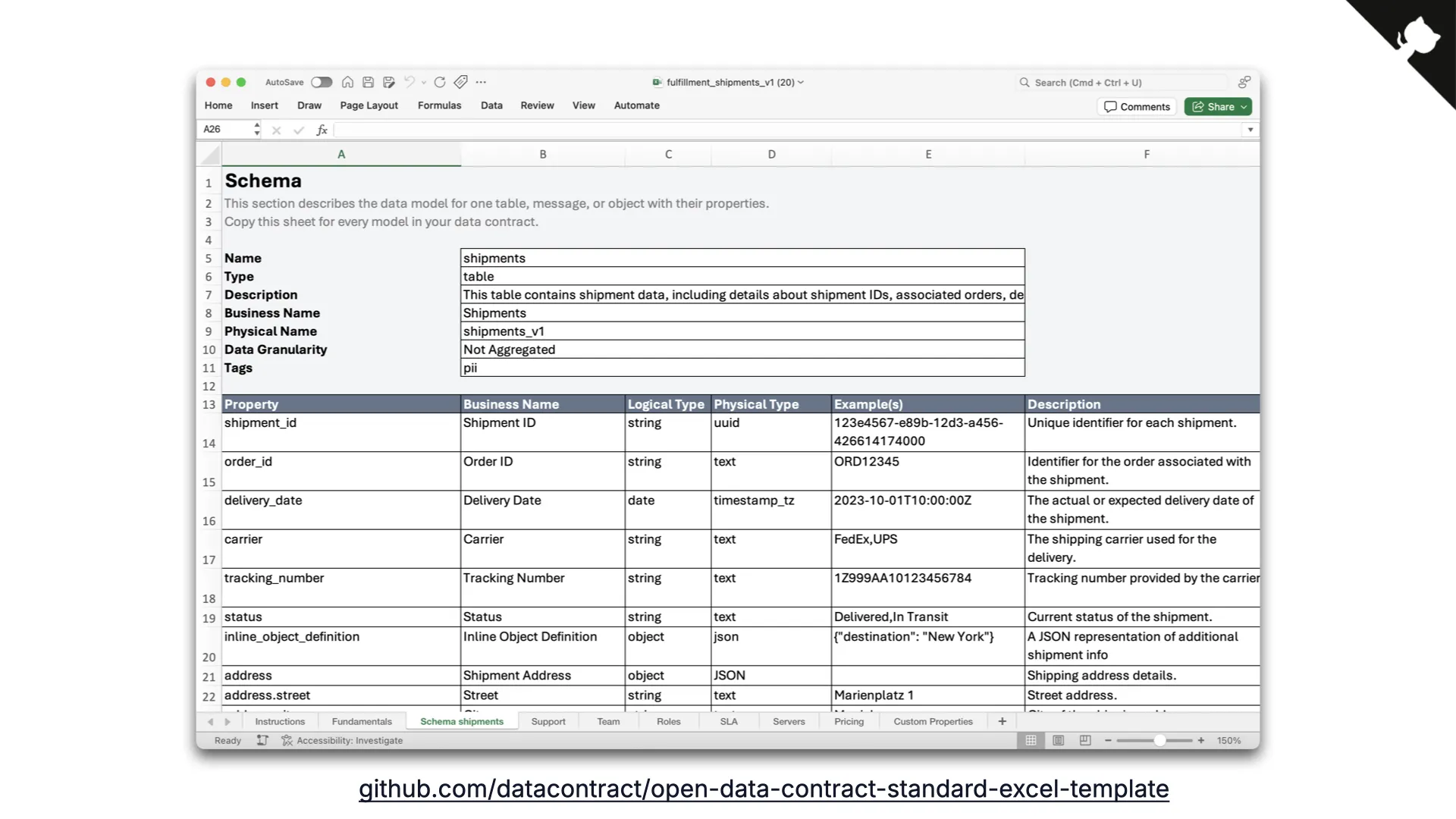
Excel Template
And experience shows: everything is nice and shiny, but people keep coming back to our good old Excel template that maps exactly to the ODCS standard. For many people, Excel is simply the easiest user interface. You would not think it, but Excel is not dying in this case. And of course, the Excel file can be read by the CLI for testing in CI too.
Live Demo: Testing Contracts Against Real Data
In the demo, I opened the Data Contract Editor showing a contract for two tables connected via a foreign key relationship. On the right, we see a preview with descriptions, examples, partitioning info, primary keys, required fields, the responsible team, where the data lives (Postgres), and the service level agreements.
The exciting part: I can run a live check from the editor, comparing the contract against the actual data. The report shows which checks passed. We used Soda Core internally to implement this.
This test result can be published alongside the contract in a marketplace. That builds trust -- because I know that seconds ago, a computer verified everything is green, and I can confidently build my use case or analysis on top of this data.
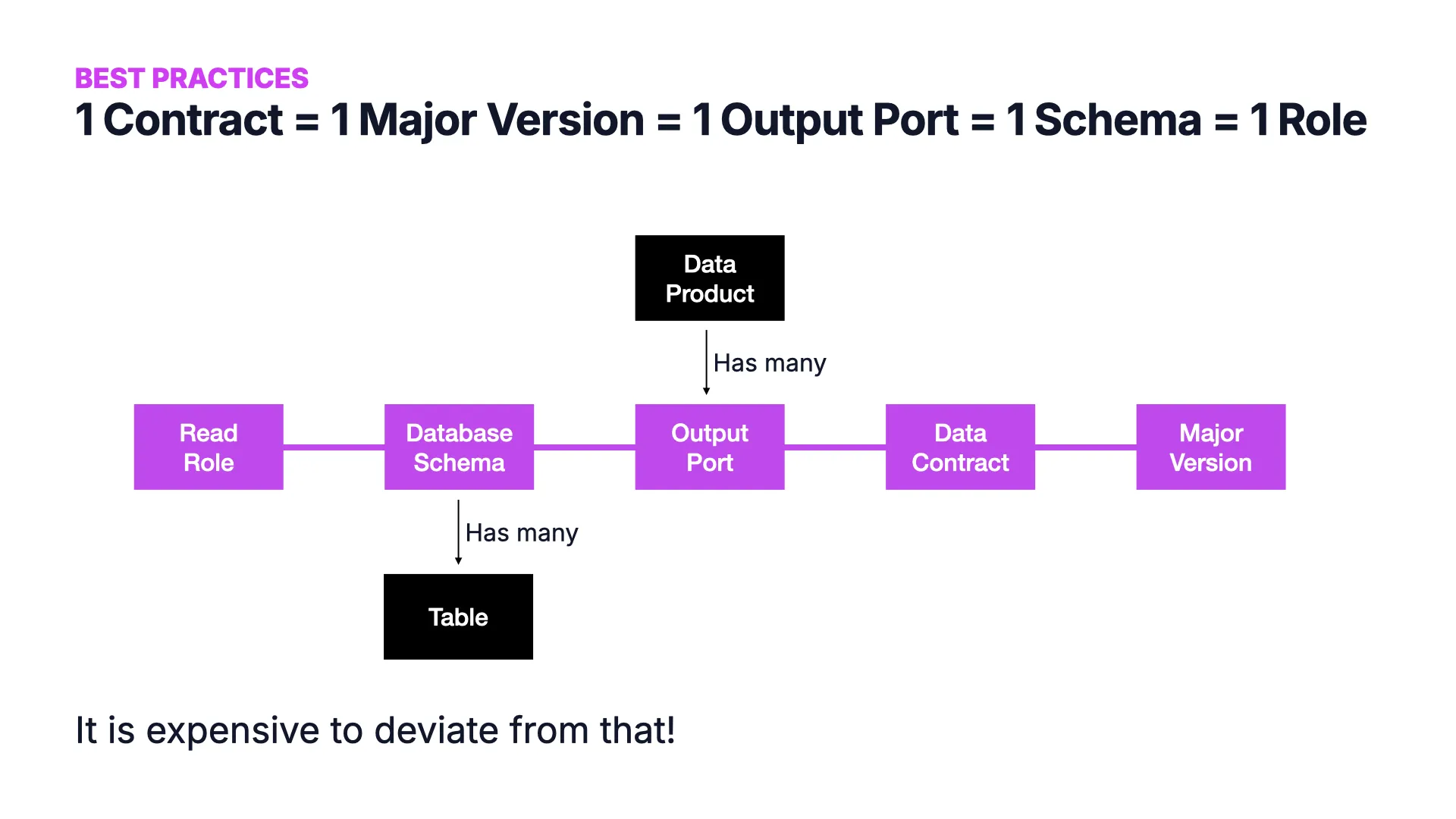
Best Practice: The 1:1:1:1:1 Mapping
One data contract in a major version maps to one output port of a data product, which maps to one database schema (that can contain multiple tables), and one read role that I can purchase.
If you can maintain this mapping, things stay simple. The more you deviate from it -- a contract per individual table (suddenly too many contracts) or multiple roles per contract (suddenly too complex) -- the more complicated it gets. It is expensive to deviate.

Best Practice: Natural Habitat
Data contracts live in the data product's git repository. You have a YAML file for the data product description and a datacontracts/ directory where the contracts sit as YAML files.
You can define contracts for output ports (what I offer) and optionally also for input ports (what I consume). For example: "I use only the first three columns of your table. Everything else I ignore." You can even add your own quality checks on top of what the provider offers.

Best Practice: Lifecycle and Evolution
Classic change management based on major versions. Breaking changes require a new major version. Non-breaking changes (like adding a new column) can be handled with minor and patch versions, so V1 stays active for a long time.
When a breaking change is truly needed, I introduce V2 alongside V1. There is a grace period where both versions run in parallel -- V1 is deprecated and V2 is active -- giving consumers time to migrate. It is a bit of effort, but it keeps things clean.

Data-First or Contract-First?
Data-first is the more natural approach: you already have data on Snowflake or Databricks and you put it "under contract." You can use the CLI import to quickly generate an initial contract version.
But from the moment you activate a contract, it becomes the source of truth. If the data deviates, the data is wrong -- the contract is by definition always right. This means you naturally switch to contract-first: all changes go into the contract first, then into the implementation.
We have our first US customer now, and they are totally contract-first. They always create the contract first, then build the data product. The advantage: you can precisely discuss what the interface looks like, and then it is easy to build. With AI, the transformations practically write themselves when the interface is clearly defined.

Best Practice: Automation
You can automate at three stages:
- Daily by data platform -- run
datacontract testto continuously verify contracts against production data. - On commit in PRs -- run
datacontract lint(including company rules) anddatacontract test --server=stagingto find issues before merge. Companies can enforce rules like "every field must have a data classification" -- if not, the PR does not go through. - On commit to main -- run
datacontract publishto push the contract to your data marketplace where people can see and trust the data.
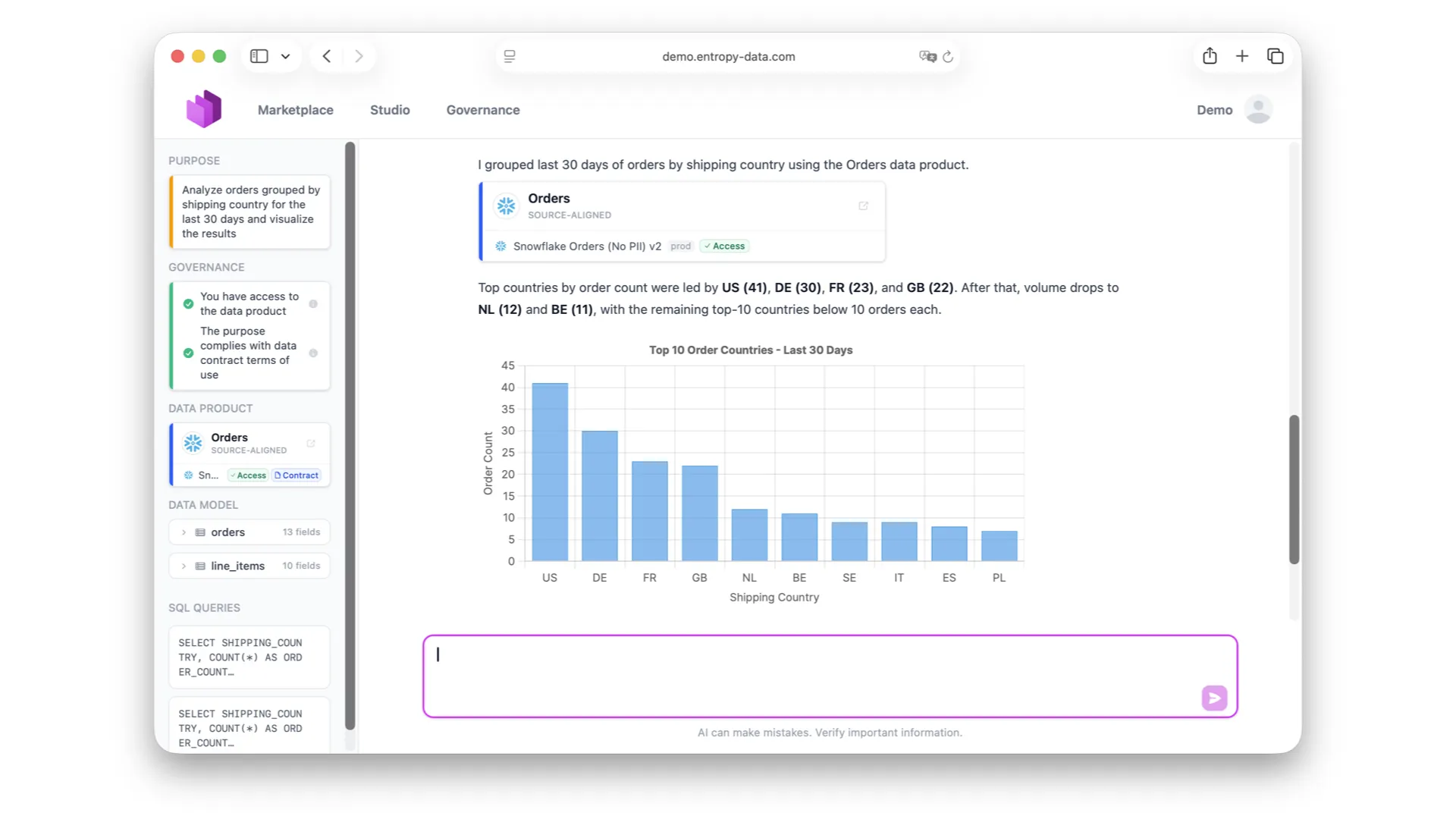
Why AI Agents Need Data Contracts
A data contract is by definition the source of truth for metadata about an offered dataset. What could be better for an agentic AI than to look at the contract, check if it is useful for the task at hand, compare multiple contracts, and then use the data protected by the best-fitting contract?
In the demo, I asked the AI agent: "Who are my top customers?" In the background, it searched for data products with contracts, found the right one, examined the contract to verify it could fulfill the task, generated a SQL query, executed it, and returned the answer.
That is the future. Regardless of which AI client you use -- agents with data hunger are coming. They want to access Snowflake, Databricks, wherever the data lives. The data contract and the governance layer between agents and data act as a defense line.
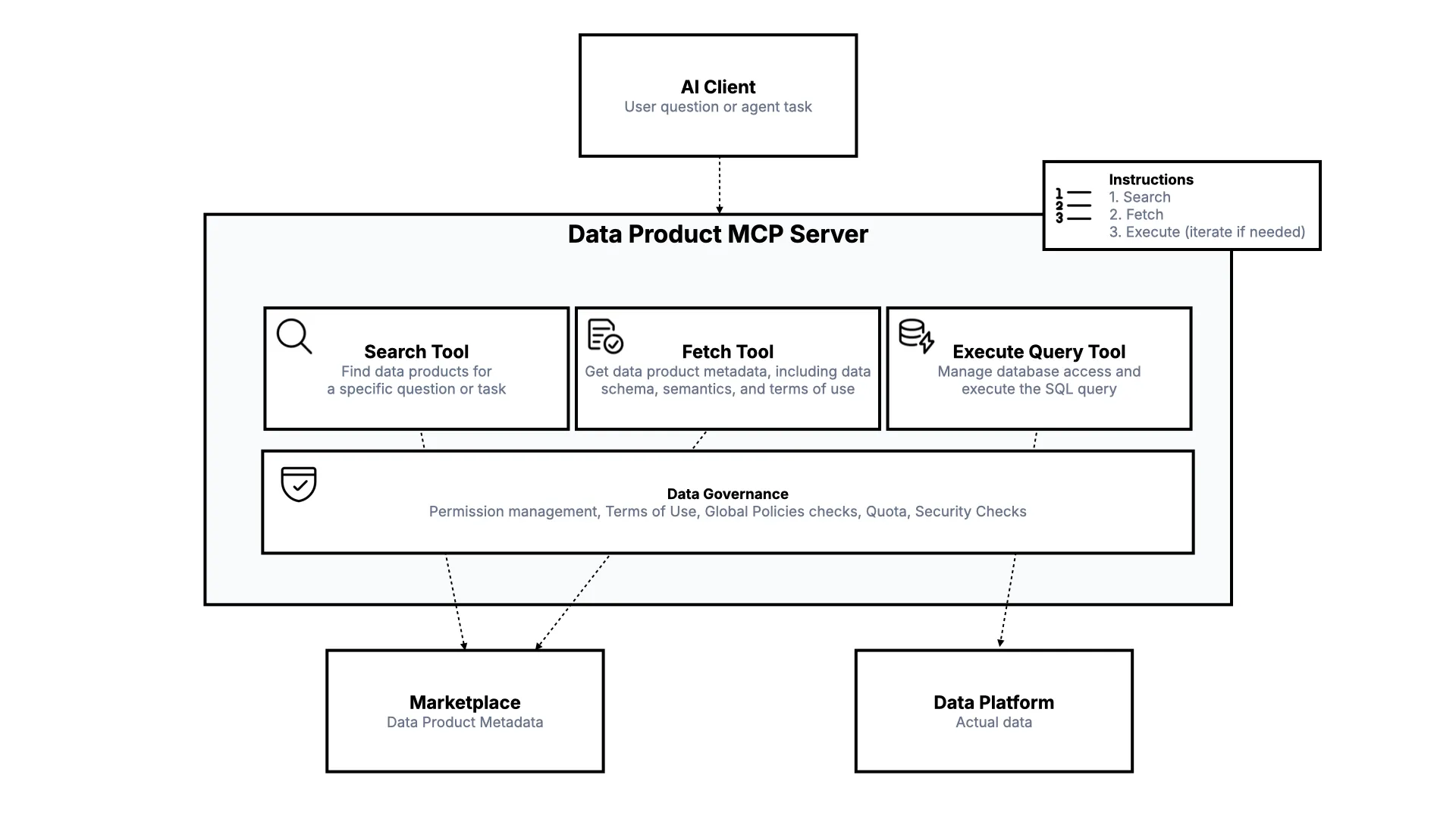
The Architecture: Data Product MCP Server
From an architecture perspective: the AI client sits on top, the data platform where the data lives is at the bottom, and a marketplace holds the metadata. The AI agent interacts with a Data Product MCP Server that can search, fetch metadata with the contract, and execute queries.
The crucial layer in between is governance: permission management, terms of use checks, global policies, quotas, and security checks. This will happen because it is simply too natural not to.

ODCS Will Be Everywhere
Swagger 1.0 was released in 2011, and OpenAPI is everywhere today.
ODCS 3.0 was released in 2025. I believe that in five years, data contracts will be just as omnipresent as OpenAPI is in the API world today.
Thank You
Thank you for listening. If you want to continue the conversation, you can find me on LinkedIn, reach me at simon.harrer@entropy-data.com, or visit www.entropy-data.com. And if you like open source, give datacontract-cli a star on GitHub.
Q&A
Selected questions from the audience after the talk.
Q: How do we get the business side on board? This all still feels very technical. Even your agent demo returned customer IDs, not names like "Zalando" or "H&M."
Two answers. First, the reason the demo looked cryptic was that the agent only had access to the IDs -- it did not have permission to resolve them to plain-text names. With the right permissions, it would do that. Second, the data contracts are specifically designed to carry business language. We have business names for all columns and tables. You can define a data dictionary or glossary -- say, "this is what an order number means" -- once, and all contracts reference that definition. Additionally, you can now attach example questions, answers, synonyms, and supplementary knowledge to a contract so the AI can answer even better. That is all optimized for business users.
Q: I come from the production/manufacturing side. Can I model relations between data points -- like flow through a pipe, where it goes, and how much should arrive?
Not directly, because contracts operate at the schema level, not the instance level. We look at which columns exist and make assertions about columns, but not about individual rows. If each data point is essentially its own table, you are getting into Digital Twin and Asset Administration Shell territory, which is a different world. You could theoretically create a contract for each table, but you need to be careful that the contract does not end up bigger than the data itself.