Talk · JAX 2026
Data Architecture: The New Backbone of Modern Software
Dr. Gernot Starke (INNOQ Fellow) & Dr. Simon Harrer (CEO, Entropy Data) · 7. Mai 2026
Ein gemeinsamer Talk auf der JAX 2026 in Mainz. Gernot eröffnet mit der großen Linie -- der Geschichte der Datenspeicherung und der These, dass Software Engineering zwischen 1995 und 2020 die Daten weitgehend vergessen hat. Simon liefert die Lösung nach: Data Contracts als die API-Spezifikationsschicht für Daten, den Open Data Contract Standard (ODCS) und eine Live-Demo eines KI-Agenten, der Business-Fragen auf Basis von Contract-gestützten Datenprodukten beantwortet.

Live aufgenommen auf der JAX 2026 in Mainz. Die Annotation unten ist eine redigierte Zusammenfassung des Talks.


Zwei Speaker
Gernot Starke ist INNOQ Fellow, Mitbegründer und Maintainer von arc42, Mitbegründer von aim42 und dem iSAQB, und macht seit sehr langer Zeit Softwarearchitektur. Daten waren immer Teil davon, selbst als der Rest der Branche aufhörte, darüber zu reden.
Simon Harrer ist im Herzen Product Engineer, Co-Autor von "Java by Comparison" und "Remote Mob Programming" sowie Co-Übersetzer von Zhamak Dehghanis "Data Mesh" ins Deutsche. Er verbrachte Jahre bei INNOQ, bevor er Entropy Data 2025 als Spin-off mitgründete. Er ist Co-Maintainer der Data Contract CLI und des Data Contract Editor und sitzt im TSC des BITOL-Projekts der Linux Foundation für offene Data-Contract- und Data-Product-Standards.


Daten vs. Information
Jeder in der IT kennt den Unterschied, aber es lohnt sich, ihn noch einmal zu nennen. Daten sind der ungeordnete Haufen Legosteine in der Schublade -- isolierte Symbole ohne eigene Bedeutung. 42 oder 07.05.2026 ist einfach nur ein Wert.
Information sind Daten im Kontext, mit Semantik. "Temperatur ist 42 °C" oder "Talk am 2026-05-07" ist etwas, mit dem du arbeiten kannst. Die ganze Geschichte der Datenarchitektur handelt davon, das Erste in das Zweite zu verwandeln.




Vom Kernspeicher zur Diskette
Die IT-Seite beginnt in den 1950ern mit dem Kernspeicher: winzige Eisenringe, auf Drähte gefädelt, die du in die eine oder andere Richtung magnetisiert hast, um ein Bit zu speichern. Hat nichts mit Kernenergie zu tun -- "Kern" meint einfach den Kern -- und fast niemand im Raum hatte je einen in der Hand.
1956 lieferte IBM die erste Festplatte aus: ein Stapel magnetischer Platten, der 5 Megabyte fasste und etwa eine Tonne wog. In den 1970ern wurde die Compact Cassette als Datenmedium in Dienst gestellt -- 300-400 Kilobyte pro Seite, was dir heute etwa ein halbes App-Icon kauft.
Dann kamen 8-Zoll-, 5,25-Zoll- und 3,5-Zoll-Disketten -- biegsam, staubempfindlich und mit fast nichts drauf. 80 kB bei den frühen, bis zu 2880 kB bei den allerletzten. Datenträger, im wörtlichsten Sinne.



Von Gigabyte zu Ångström
In den 2000ern wurden Consumer-Laufwerke in zweistelligen Gigabyte gemessen, dann schoben SSDs ab 2010 dieselben Bauformen in den Terabyte-Bereich. Heutige Rechenzentrums-Laufwerke liegen bei 24 TB und mehr -- und sind ironischerweise auch schwer zu bekommen, weil jedes davon in einem Hyperscaler verschwindet.
Das Faszinierende ist, was die Speicherindustrie still und leise geworden ist: ein Seagate-Erklärvideo, das Gernot zeigte, spricht von Schreib-Lese-Köpfen, die in Ångström-Toleranzen über die Platte fliegen -- molekulare Größenordnungen. Festplattenhersteller bewegen sich im selben Präzisionsbereich wie die Chip-Fab-Maschinen von ASML. Vier Minuten, die sich lohnen.


Handel als Daten-Use-Case
Dinge festzuhalten war schon immer ein Grundbedürfnis von Zivilisationen. Handel ist ein sauberes Beispiel. Ägyptische Pyramidenbauer führten bereits Transaktionslisten. Mittelalterliche Kaufleute hielten mit vergoldeten Federn fest, was sie kauften und verkauften.
Dann erfand jemand die doppelte Buchführung -- die Datenmenge, die ein Kaufmann führen musste, absichtlich verdoppelt, um Fehler zu reduzieren. Im Grunde ein System für Datenqualität. (Spoiler: Diese Idee kommt zurück.)
Heute sind in einer modernen Handelsgruppe die Daten das Gold. Sie sind es, mit denen du bessere Einkaufskonditionen aushandelst, Bestände über Filialen verteilst und Angebote personalisierst. Du kannst brillante Algorithmen, polierte Dashboards und die weltbesten ML-Modelle haben -- wenn die Daten, die sie füttern, mittelmäßig sind, ist auch das, was der Manager am anderen Ende herauszieht, mittelmäßig.


Herausforderung #1: Software Engineering hat Daten vergessen
Die These ist bewusst provokant: Zwischen 1995 und 2020 hat Software Engineering die Daten weitgehend vergessen. Wir waren mit anderen Dingen beschäftigt.
Um 1995 wurde C++ Mainstream, Java kam, und alle lernten Objektorientierung -- Vererbung, Methoden, Kopplung und Kohäsion. Die funktionale Seite der Software. In den 1980ern war der Begriff "Datenmodell" noch üblich; Ende der 1990er war er fast ein Schimpfwort. Dann SOA. Dann Agile und Scrum (Daten sind kein Wort, das irgendwo im Scrum Guide vorkommt). Dann Microservices. Alles auf Verhalten fokussiert, nichts auf die Form der Daten, die herumflossen.
Gernot gibt gerne zu, dass er mittendrin war. "Mit schuld" -- mit verantwortlich. Es geht nicht darum, sich zu entschuldigen; es geht darum, zu erkennen, woraus wir uns jetzt wieder herausarbeiten.

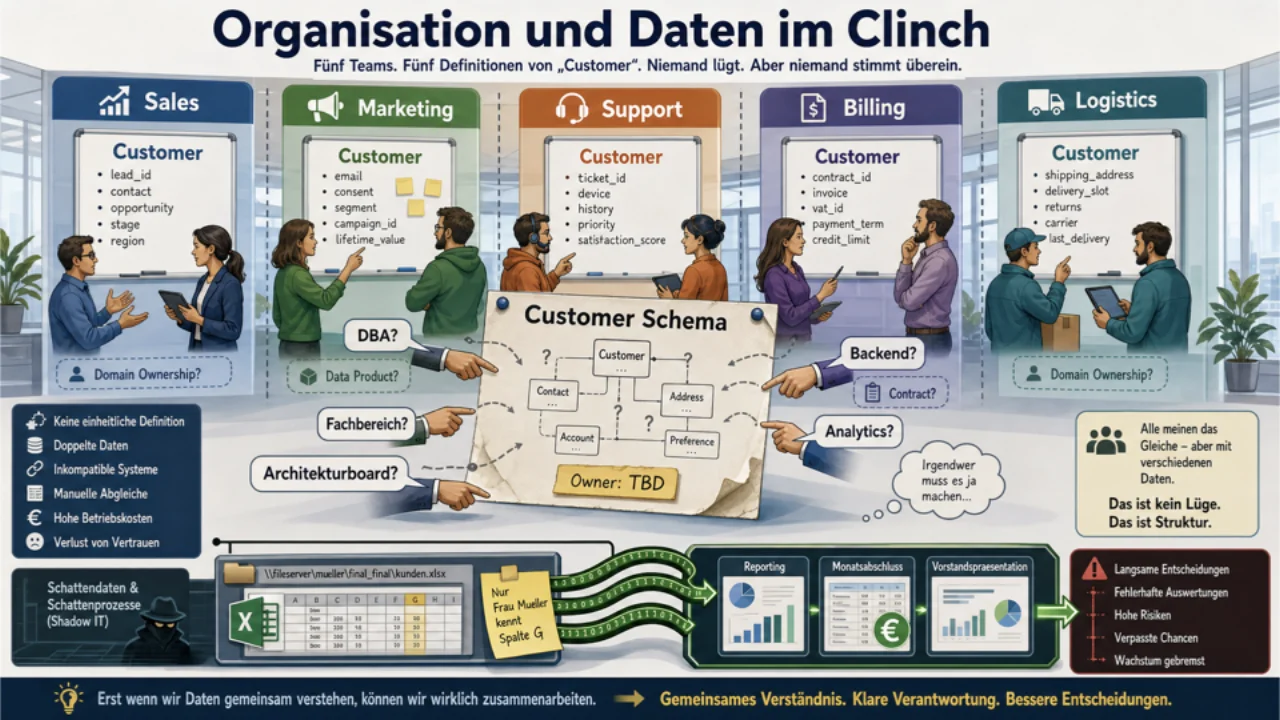
Herausforderung #2: Daten, das einzige Asset ohne Owner
Jedes andere Asset in einem Unternehmen hat einen Owner. Daten traditionell nicht. Oder genauer: Jeder denkt, er besitze sie, was dasselbe Problem in anderer Form ist.
Gernots Lieblingsbeispiel stammt von einem Versicherer, bei dem er während der DSGVO-Einführung arbeitete. Dort galt eine fröhliche "Adresse-an-alle"-Konvention: Sobald jemand Interesse an einem Produkt zeigte, wurde die Adresse an jeden internen Empfänger weitergeleitet, der sie vielleicht haben wollte. Dann kam die DSGVO, "Sylvia" bat um Löschung, und niemand konnte ehrlich sagen, wo ihre Daten gelandet waren. Niemand besaß die Adressdatensätze.
Den daraus entstandenen Zustand nennt er, mit Erlaubnis, "Wildwuchs". Es gibt jede Menge Daten, aber niemand weiß, welche Kopie maßgeblich ist, ob sie noch gültig ist oder ob sie die richtige Anzahl Nachkommastellen hat.

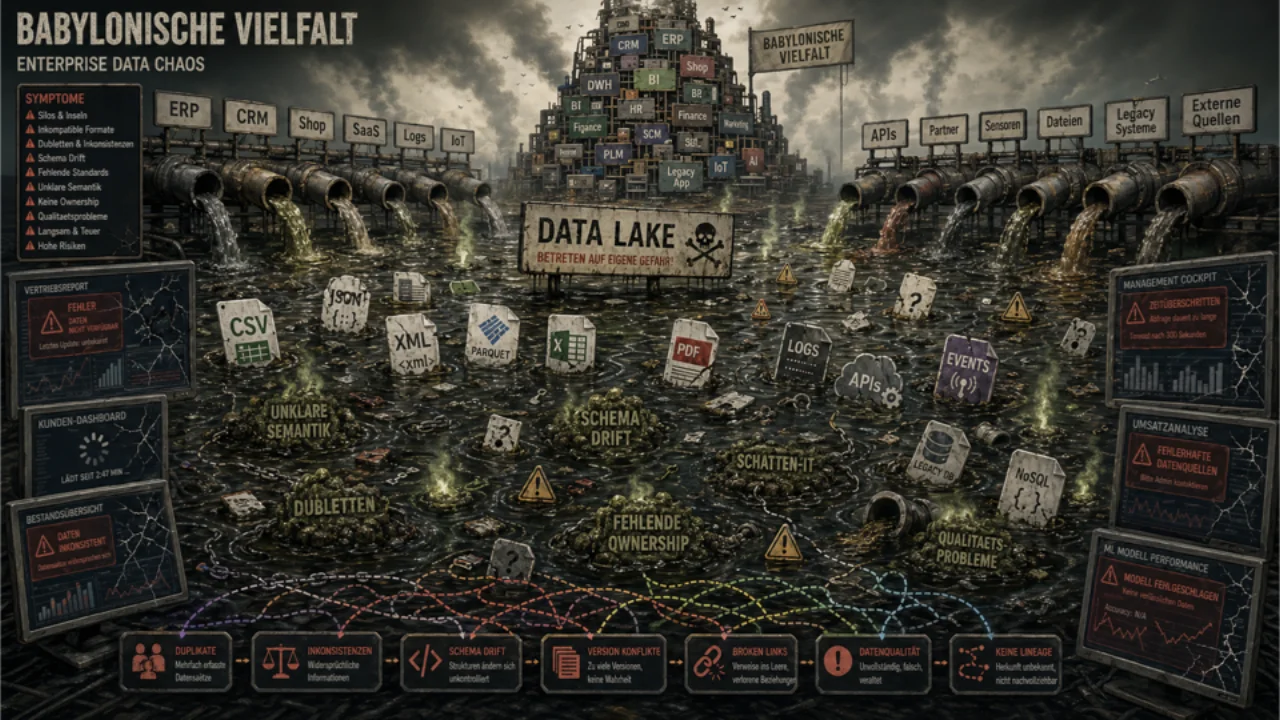

Herausforderung #3: Hübsche Bilder auf einem Sumpf
Klassische Data Warehouses produzieren wunderschöne Reports. Das Problem ist, dass sie oft zu spät kommen und auf schlechten Daten beruhen. Gernot saß in vielen Meetings, in denen jemand ein Excel-Sheet aus der Tower-Case-Ära hervorzog und sagte: "Also, meine Zahlen sind anders."
Das ist Schatten-IT, und sie taucht genau dort auf, wo die zentrale Datenklempnerei die Leute im Stich gelassen hat. Data Lakes erbten dasselbe Problem in größerem Maßstab -- alles hineinschaufeln und hoffen, dass etwas Gutes herauskommt. Hoffnung ist eine wunderbare Sache, aber eine schlechte Datenstrategie.
Die KI-Welle machte das unmöglich zu ignorieren. In dem Moment, in dem ein Unternehmen beschloss, ein eigenes Modell zu fine-tunen, und nach Trainingsdaten suchte, lautete die Antwort meist: Wir haben viele Daten, aber wir haben keine Ahnung, welche davon korrekt sind. Ein auf einem Sumpf trainiertes Modell ist nicht intelligent. Es ist ein Sumpf.

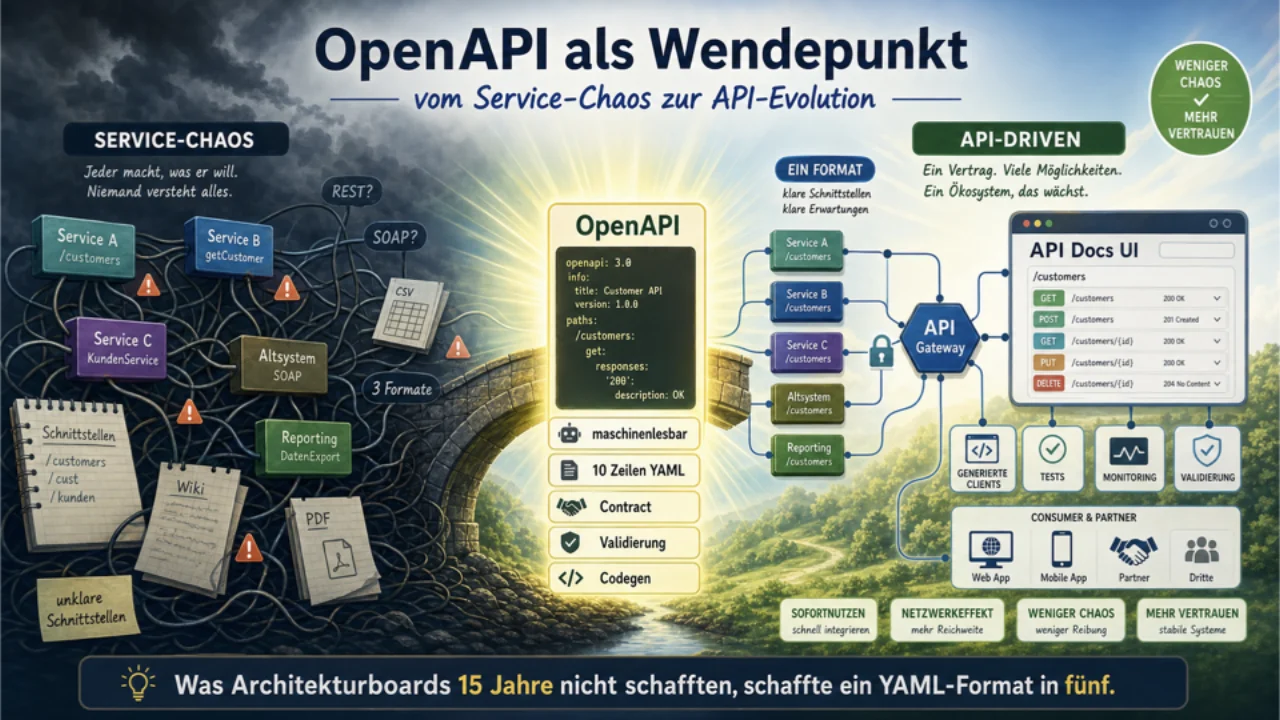

Das haben wir schon einmal gelöst
Wir waren tatsächlich schon einmal in genau so einem Schlamassel. Das "Service-Chaos" der 2000er sah sehr ähnlich aus: SOAP/WSDL war schwergewichtig, REST war leichtgewichtig, hatte aber keinen Contract, Dokumentation lebte -- wenn überhaupt -- in Confluence, der ESB war der Flaschenhals. Niemand wusste wirklich, welche Services er hatte.
Was uns herausholte, waren Swagger und dann OpenAPI. Ein maschinenlesbares, herstellerneutrales Klartextformat. Zehn Zeilen YAML reichen für den Anfang. Swagger UI liefert sofortigen Mehrwert. Wie Gernot es formuliert -- und er ist mit dem Wort vorsichtig -- war das ein echter Game-Changer dafür, wie Teams Services produzieren und konsumieren.
Jetzt muss dieselbe Idee in die Datenwelt wandern.


Jedes Unternehmen hat bereits Daten-APIs
REST hat OpenAPI. Messages und Events haben AsyncAPI. Und geteilte Datasets?
Denn die Wahrheit ist: Jedes Unternehmen hat bereits Dutzende "Daten-APIs". Sie sehen nur nicht aus wie APIs. Sie sehen so aus:
- CSVs auf einem SFTP
- JSON-Dateien auf S3
- SQL-Tabellen auf BigQuery / Snowflake
- Iceberg-Dateien auf Azure One Lake
- Delta Live Tables auf Databricks
- Excel-Dateien auf SharePoint
Ein Team produziert, andere konsumieren. Dashboards, Vorstands-Reports, ML-Training, nachgelagerte Pipelines hängen alle davon ab, dass diese Schnittstellen stabil und qualitativ hochwertig sind. Und wenn die produzierende Pipeline stillschweigend einen CSV-Header ändert oder eine Spalte leert, zeigt das Dashboard einfach eine andere Zahl. Kein Fehler, kein Alert -- der schlimmste denkbare Fehlerfall.
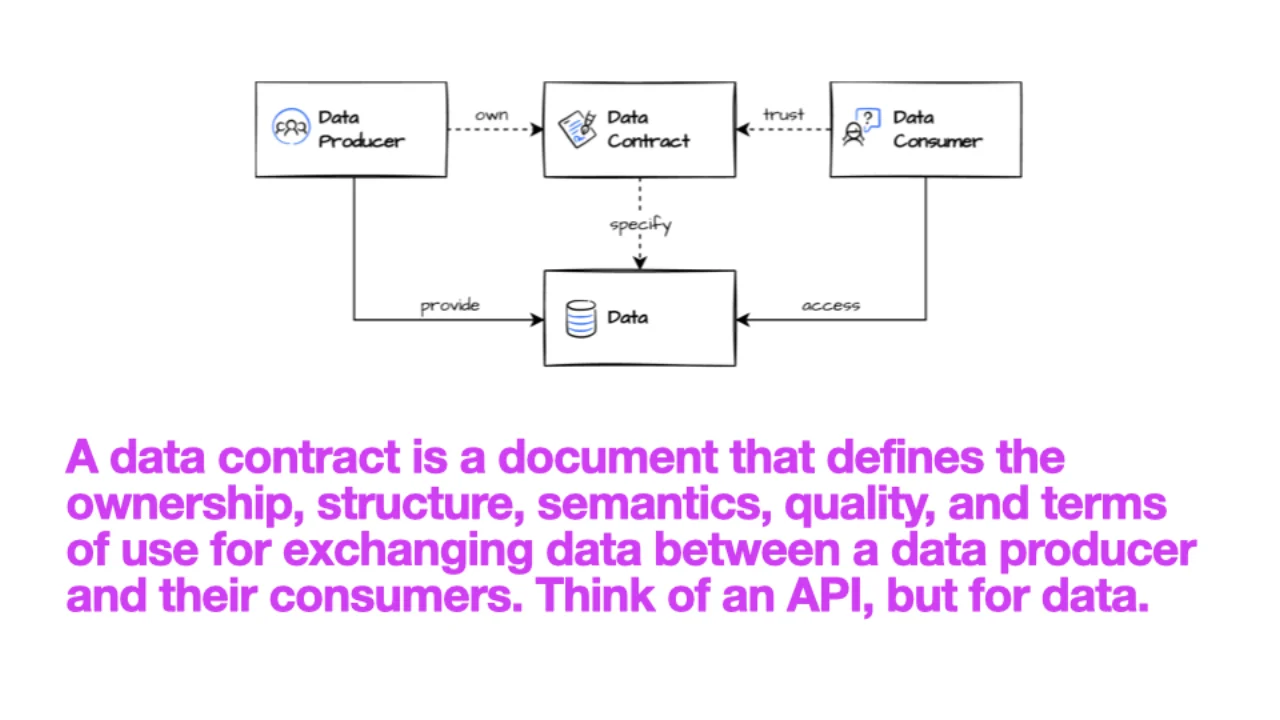
Was ist ein Data Contract?
Ein Data Contract ist ein Dokument, das Ownership, Struktur, Semantik, Qualität und Nutzungsbedingungen für den Datenaustausch zwischen einem Producer und seinen Consumers definiert. Stell dir eine API-Spezifikation vor, aber für Daten.
Der Producer besitzt den Contract und erklärt die Garantien. Der Consumer liest ihn und vertraut ihm. Ohne einen solchen fallen Consumers darauf zurück, das Schema durch Anstarren von Beispielzeilen zu reverse-engineeren -- und raten, dass OID2 die Bestellnummer ist, obwohl es etwas ganz anderes sein könnte. Solche stillen Fehlinterpretationen sind sehr schwer zu erkennen.
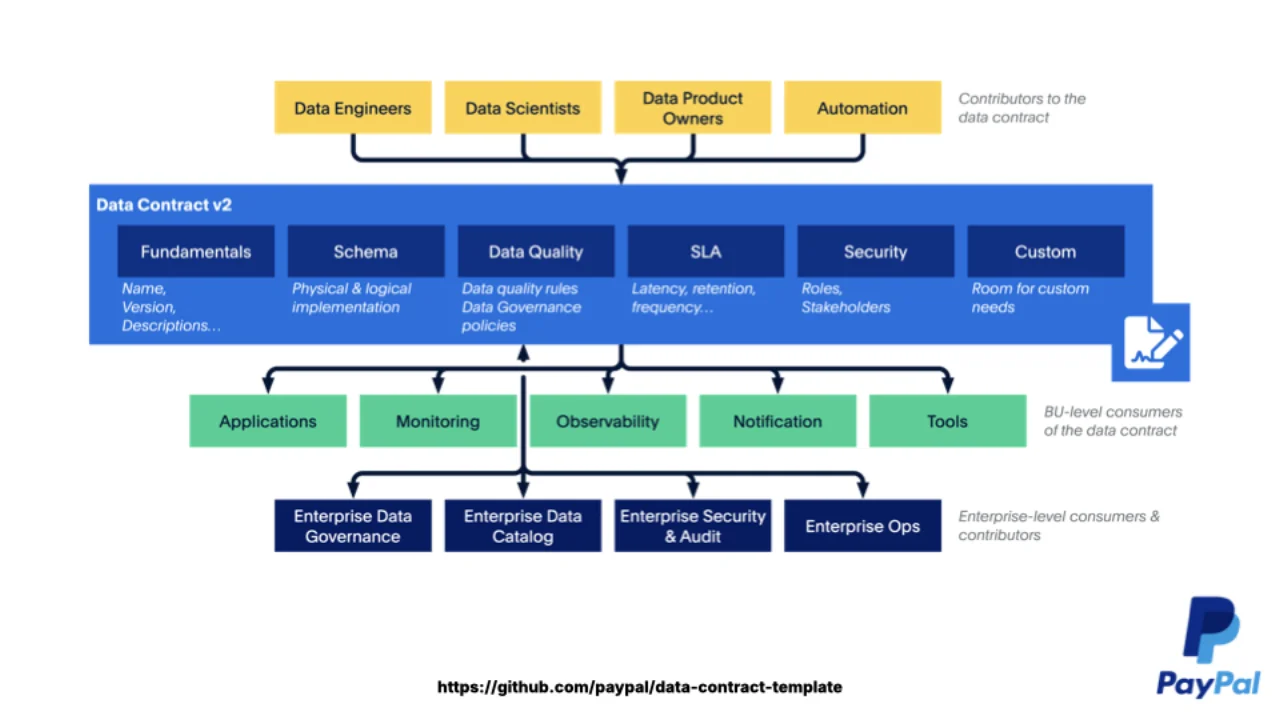
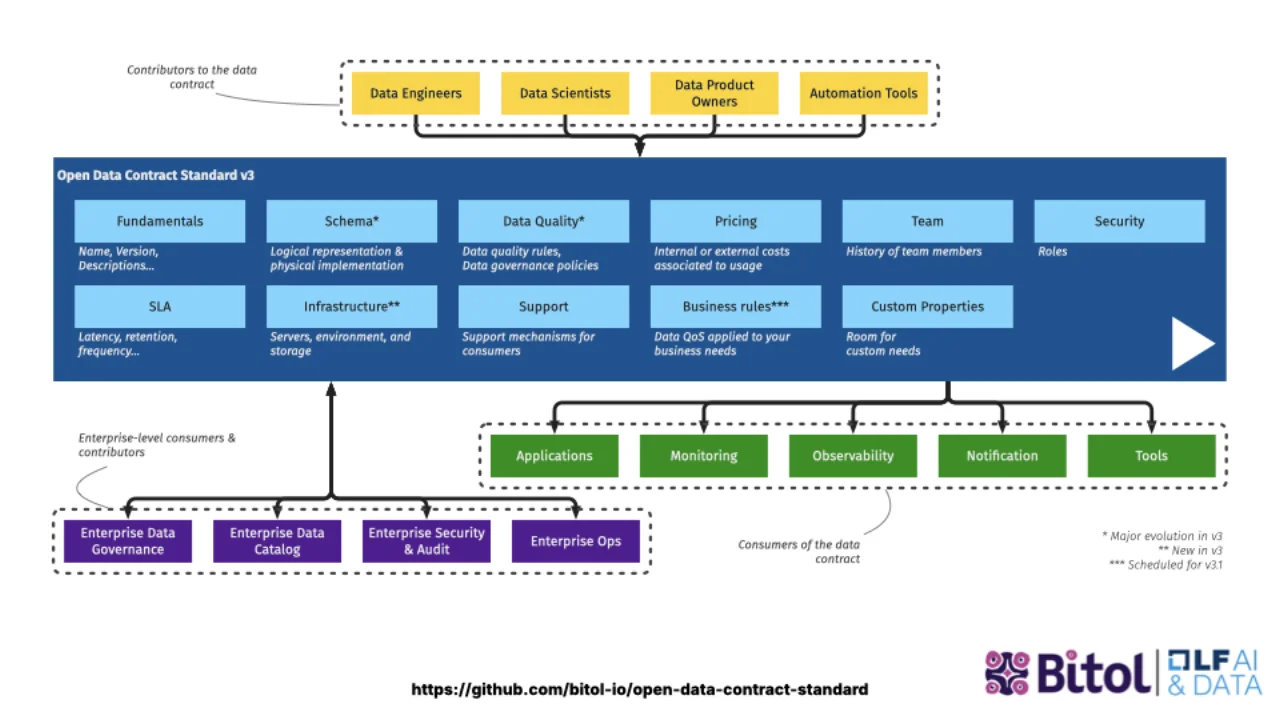
Von Schneeflocken zu einem Standard
Als der Bedarf zum ersten Mal auftauchte, erfand jedes Unternehmen sein eigenes Format. Mal YAML, mal JSON, mal Excel, sogar Word-Dokumente. Alle versuchten dasselbe zu kodieren: Was bedeutet jedes Feld, wie ist seine Qualität, was ist das SLA, was sind die Nutzungsbedingungen.
PayPal stellte sein internes Template als Open Source bereit und spendete es als ODCS 2.2 an die Linux Foundation. Simon stieß zum TSC und half, die PayPal-Spezifika herauszuziehen, damit jedes Unternehmen es nutzen kann. ODCS 3.0, 2025 veröffentlicht, war die erste Version, die wirklich unternehmensneutral war.
Heute lebt es bei BITOL, dem Linux-Foundation-Projekt für offene Data-Contract- und Data-Product-Standards, mit gesunder Parität zwischen Endanwendern, Beratern und Anbietern im Komitee -- die Art von Governance, die "Standard" zu einem echten Wort macht und nicht zu einem Marketingwort.
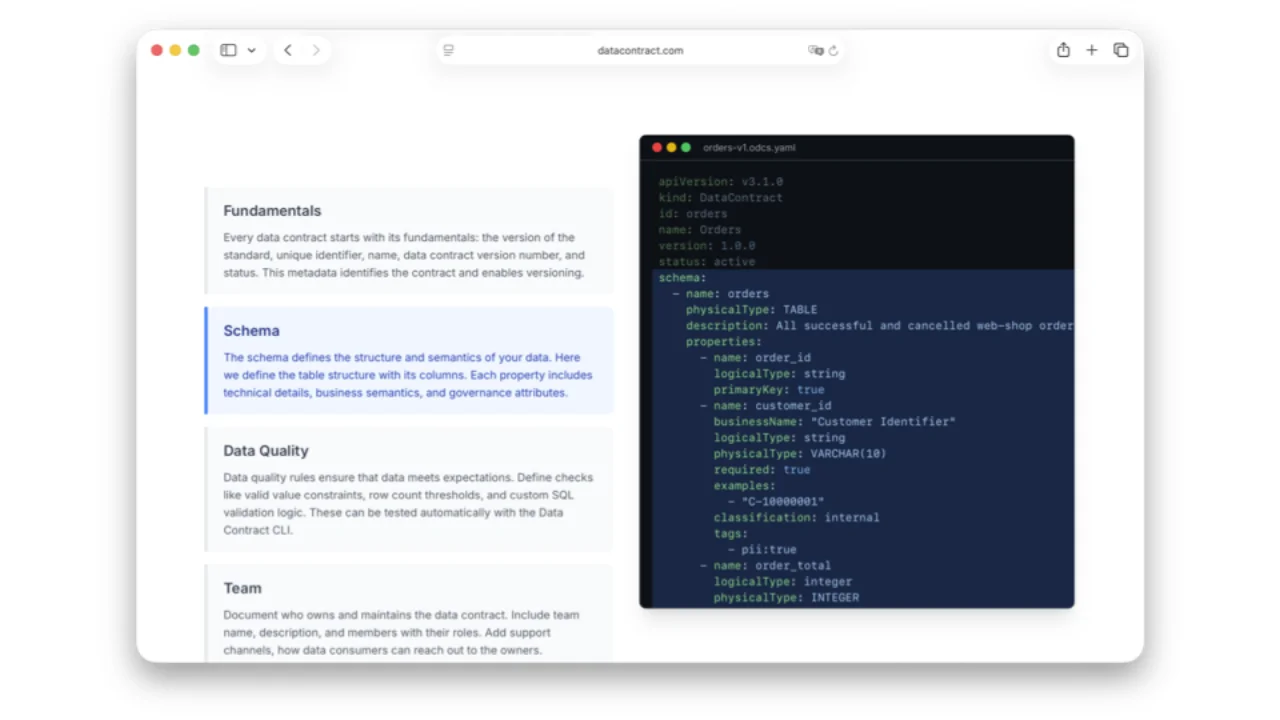
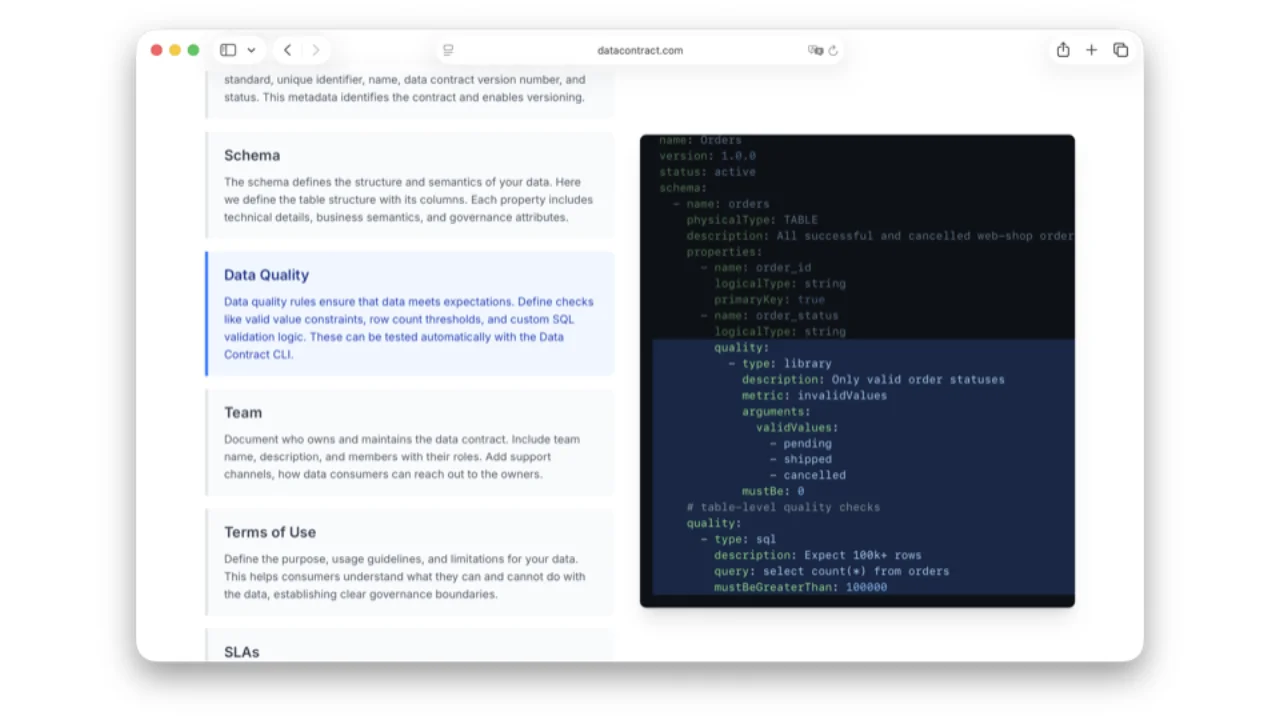
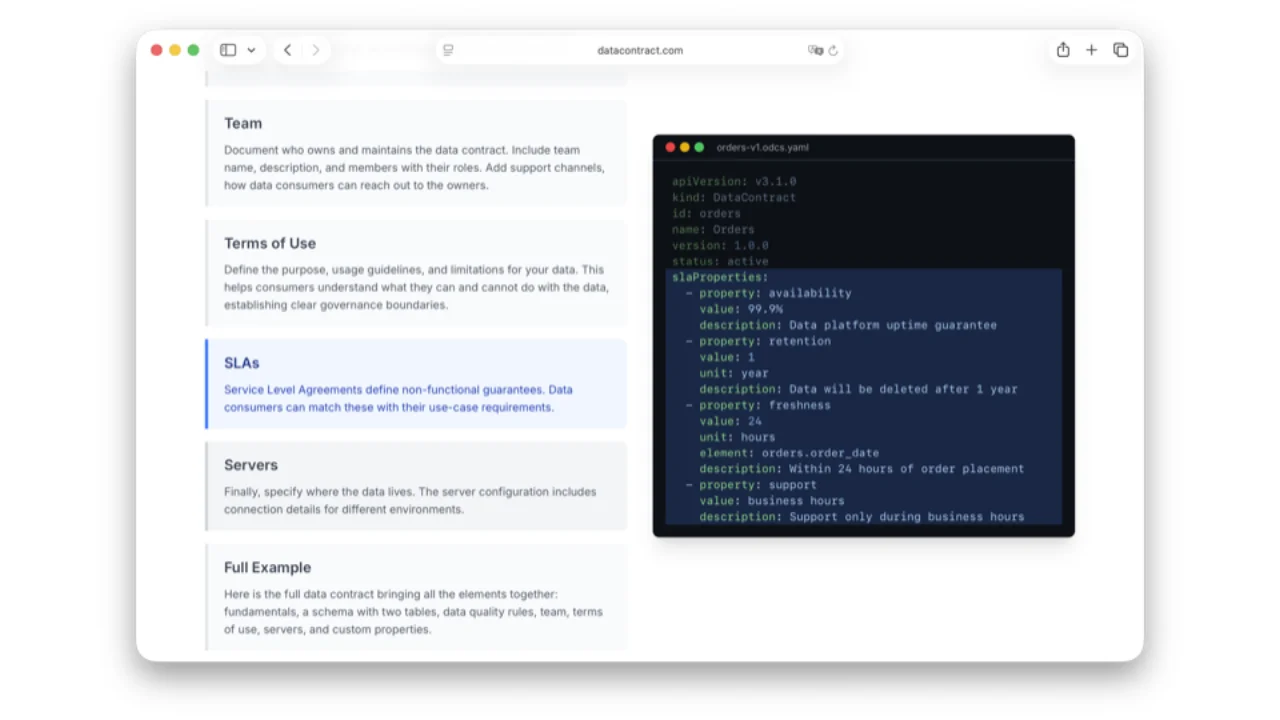
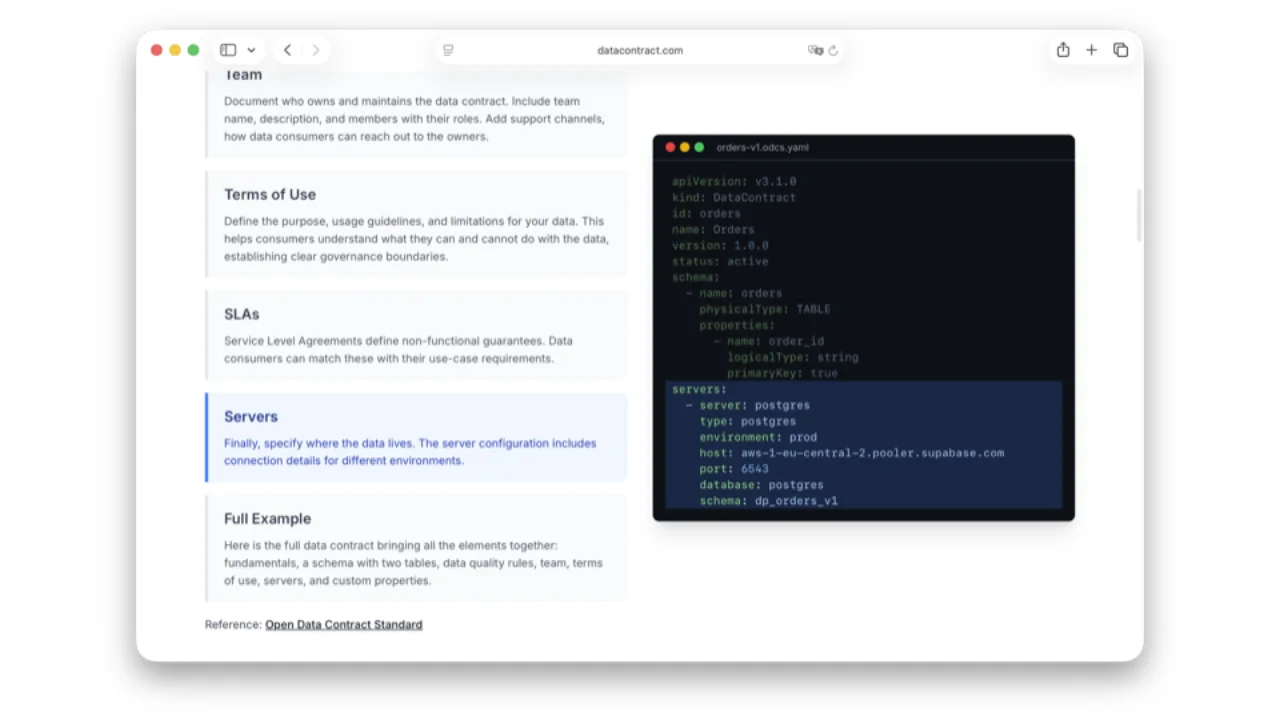
Was in einem ODCS-Contract steckt
Eine einzige YAML-Datei erfasst alles, was ein Consumer braucht:
- Fundamentals -- id, name, version, status (für den Lifecycle).
- Schema -- Tabellen und Spalten mit logischen & physischen Typen, Primär- & Fremdschlüsseln, Business-Namen ("Customer Identifier"), Klassifizierungen, PII-Tags.
- Datenqualität -- Enums (
order_status ∈ {pending, shipped, cancelled}) oder beliebiges SQL ("Zeilenanzahl muss größer als 100.000 sein"). Entscheidend: ausgedrückt als Prozentwerte, nicht als striktes required/optional -- echte Daten sind unsauber, und ML-Modelle funktionieren mit 99 % Vollständigkeit problemlos. - Team & Support -- Owners, Slack-Kanäle, Ticket-Systeme.
- Nutzungsbedingungen -- was Consumers mit den Daten dürfen und nicht dürfen (geografischer Geltungsbereich, PII-freie Garantien, Zweckbindung).
- SLAs -- Availability, Retention, Freshness, Latency. In der Datenwelt zählen Latency und Freshness viel mehr als Plattform-Uptime (Databricks / Snowflake / BigQuery laufen einfach).
- Servers -- wo die Daten tatsächlich liegen, damit ein autorisierter Consumer sich direkt damit verbinden kann.
"Ownership explizit zu machen ist der große Schritt. Implizit war: Producers dachten, Struktur und Semantik müssten sich weiterentwickeln, Consumers nahmen an, sie blieben für immer eingefroren. Dieser Widerspruch ist der Grund, warum Pipelines brechen."
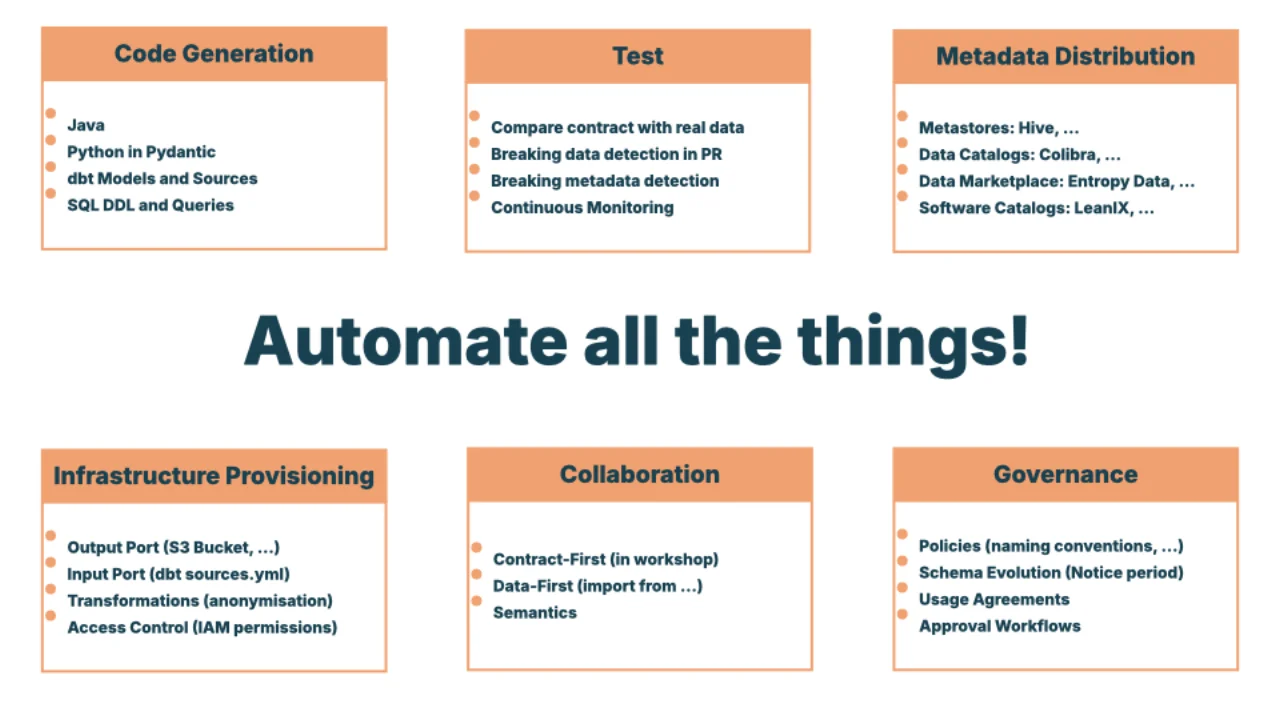
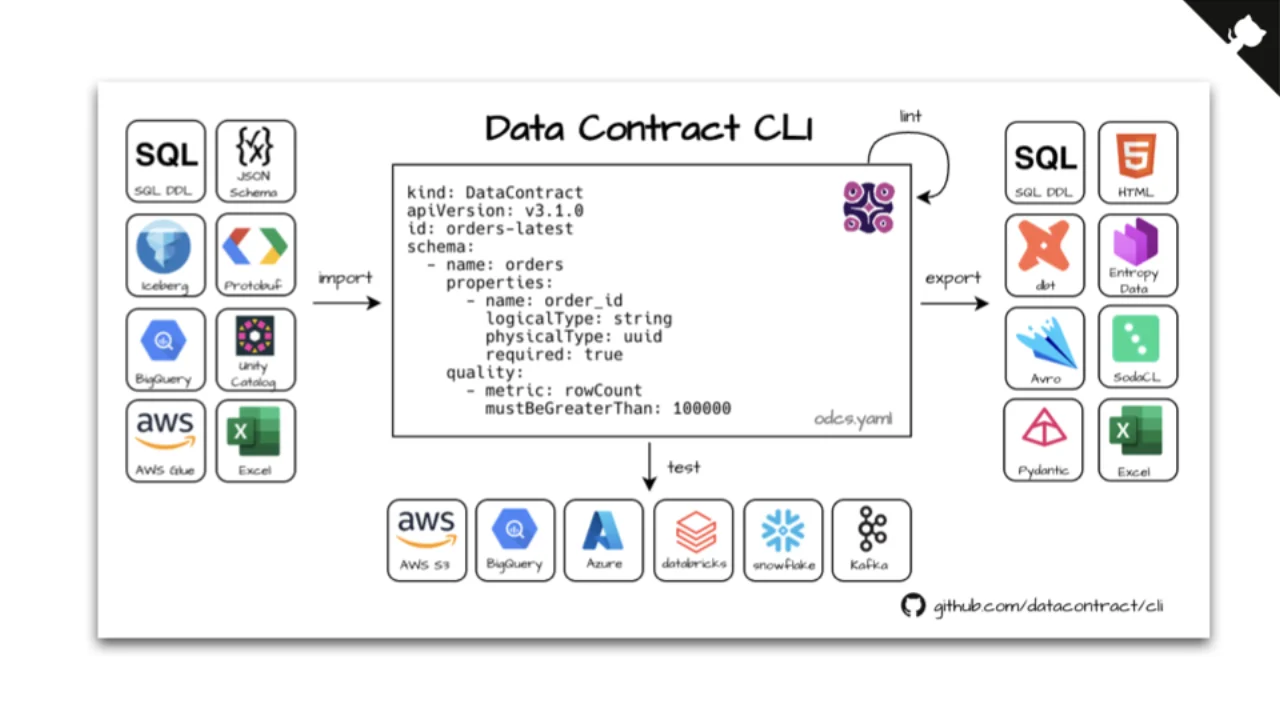
Automate All the Things
Sobald ein Contract als YAML vorliegt, kannst du viel damit machen: Java / Pydantic / dbt-Modelle / SQL-DDL generieren, ihn gegen echte Daten vergleichen, PRs bei Breaking Changes scheitern lassen, in Produktion kontinuierlich überwachen, Metadaten in Kataloge (Colibra), Marktplätze (Entropy Data) und Software-Kataloge (LeanIX) pushen.
Die Open-Source-Data Contract CLI erledigt die Schwerstarbeit -- Imports aus SQL-DDL, JSON Schema, Iceberg, Protobuf, BigQuery, Unity Catalog, AWS Glue, Excel; Exports nach SQL-DDL, HTML, dbt, Entropy Data, Avro, SodaCL, Pydantic, Excel; Tests gegen AWS S3, BigQuery, Azure, Databricks, Snowflake, Kafka.
"Qualitätschecks waren früher inhärente Invarianten in unserem Code. Jetzt leben sie neben den Daten, im Contract -- und laufen kontinuierlich."
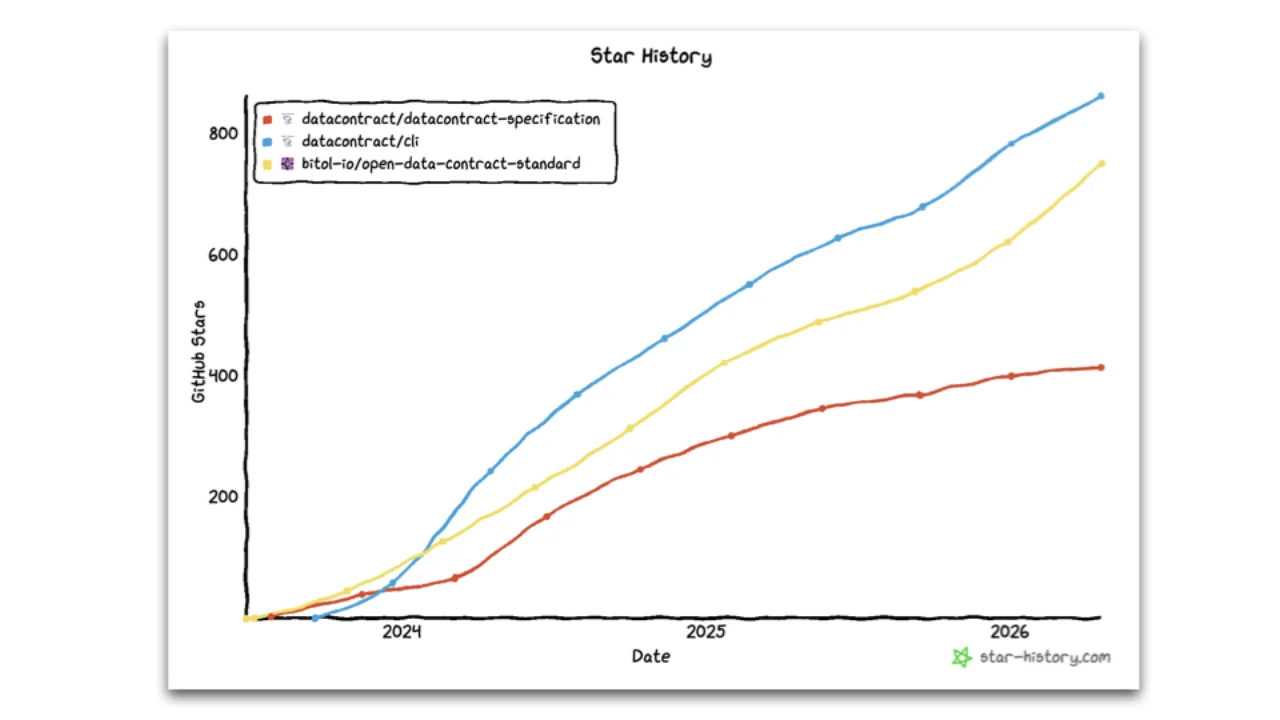
Tooling zählt mehr als der Standard
Wenn du dir die GitHub-Stars anschaust, ist die Data Contract CLI populärer als die ODCS-Spec selbst. Das ist wieder die OpenAPI-Lektion: offene Standards brauchen gutes Open-Source-Tooling, um Adoption zu erreichen.
Der Standard ist das, was dir dieses Tooling kostenlos liefert, was dir Vendor-Lock-in erspart, wenn mehrere Tools dasselbe Format unterstützen, und was bedeutet, dass Teams sich gegenseitig helfen, statt dasselbe YAML zehnmal in leicht unterschiedlichen Varianten neu zu erfinden.
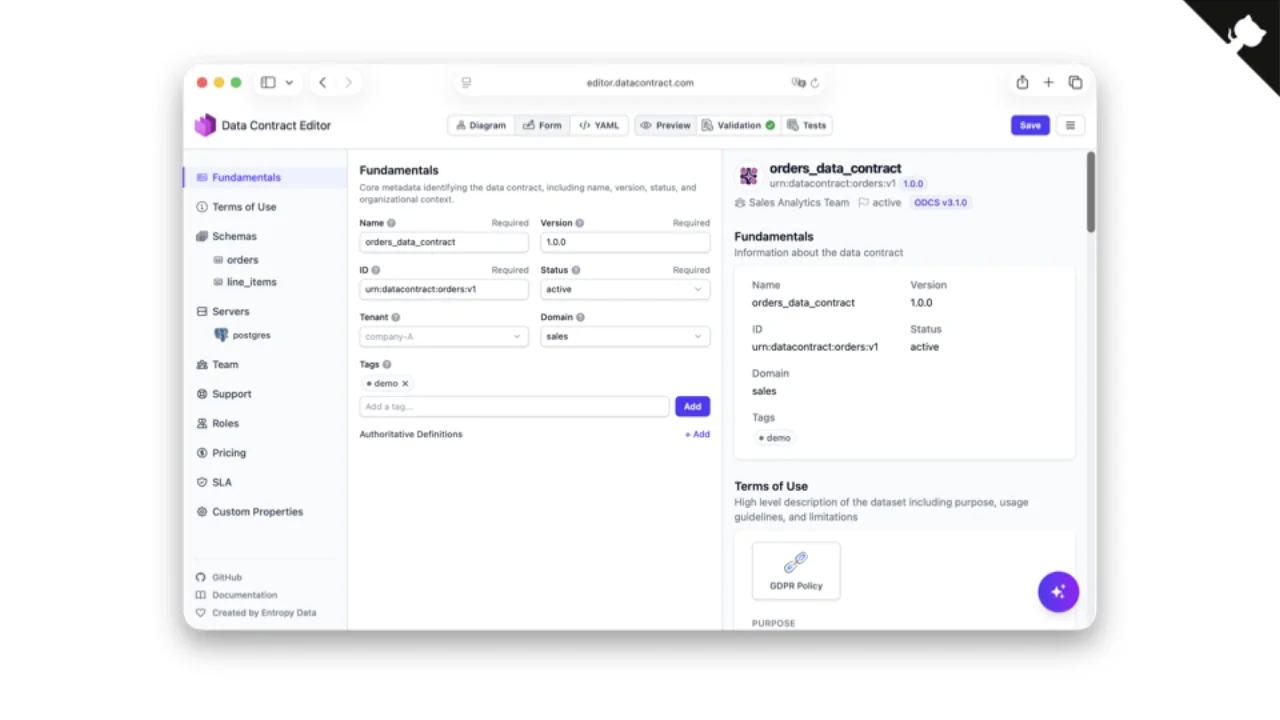
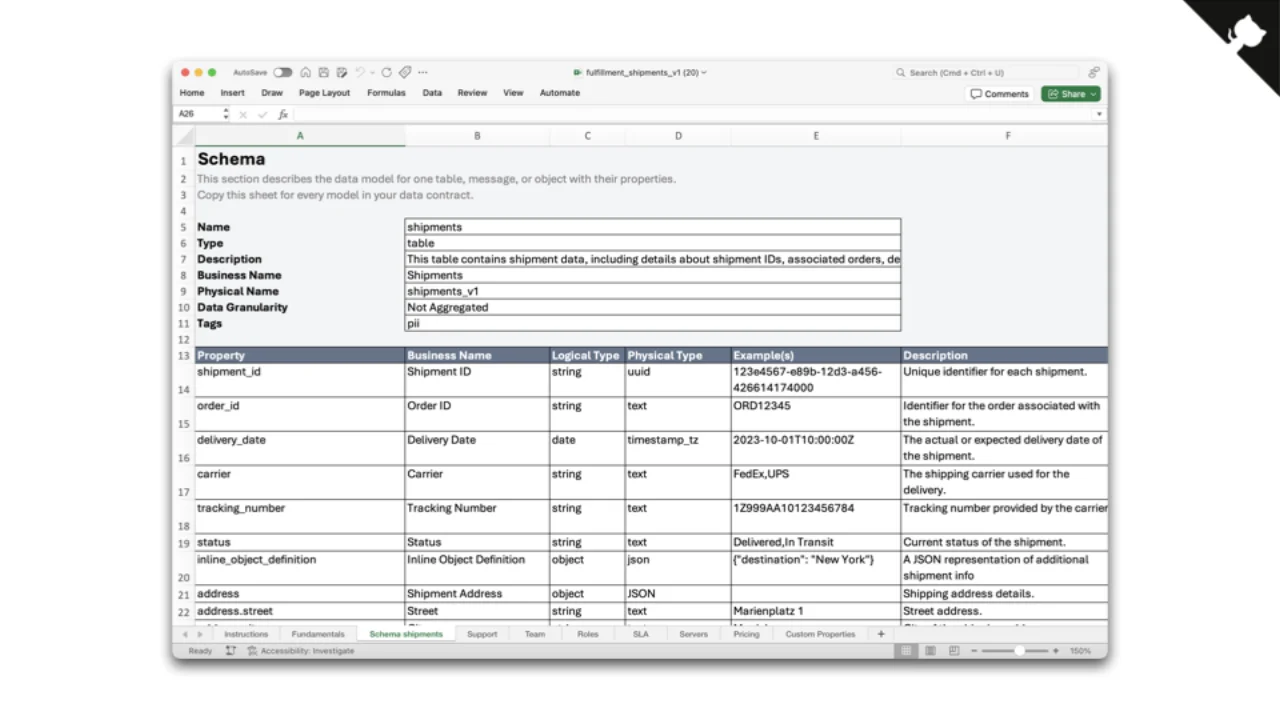
Editoren für Menschen (und Business-Leute)
YAML von Hand ist mühsam, also haben wir einen Open-Source-Data Contract Editor gebaut. Diagrammansicht, Formularansicht, rohe YAML-Ansicht -- mit Vorschau und Validierung. Er ist mit der CLI integriert, sodass du während des Editierens Tests gegen die Daten neu laufen lassen und sehen kannst, ob der Contract noch hält.
Für Kollegen, die nie ein neues Tool lernen wollen, gibt es außerdem ein ODCS-Excel-Template. Die CLI wandelt es in YAML um. Es ist nicht schön, aber praktisch -- und Excel verschwindet nicht so schnell.
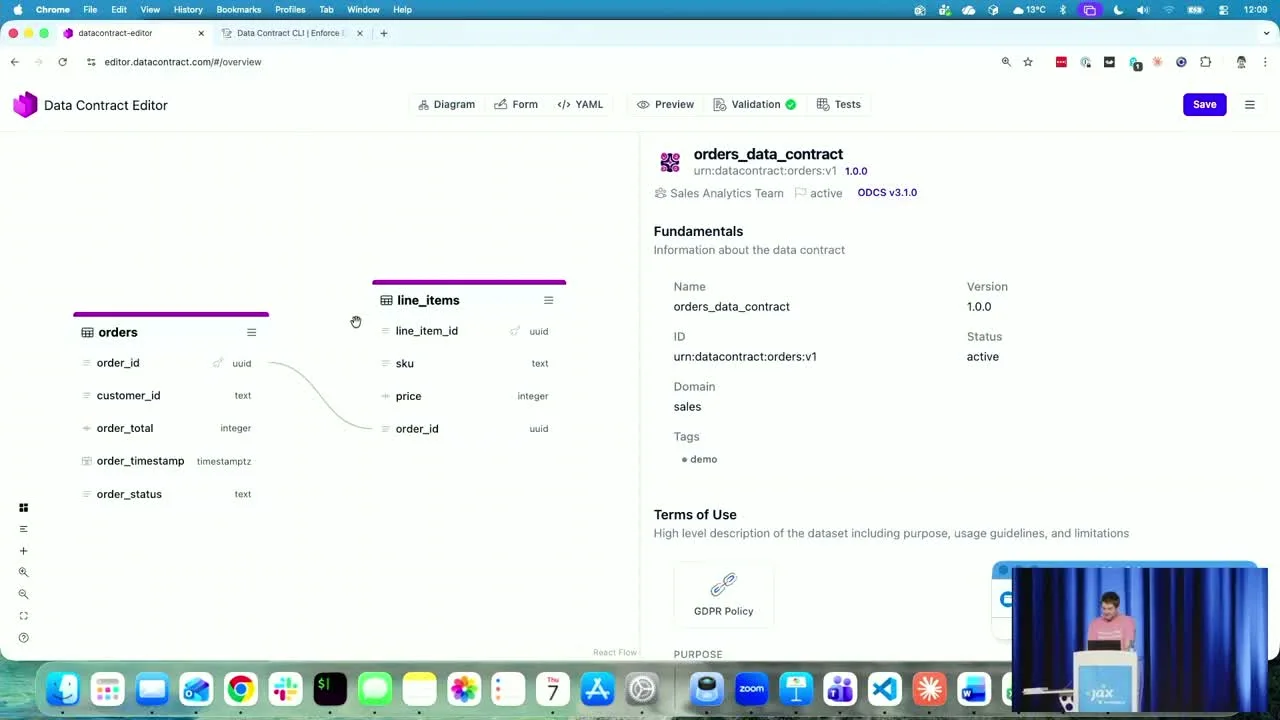
Live-Demo: Editor + CLI auf einer echten Datenbank
Der Editor unter editor.datacontract.com rendert einen orders- und line_items-Contract als Diagramm, mit einem Fremdschlüssel, der beide verbindet. Jedes Feld hat logische und physische Typen, Beispiele ("C-10000001"), Klassifizierungen (internal, PII) und eine businessfreundliche Beschreibung (SKU → Stockkeeping Unit).
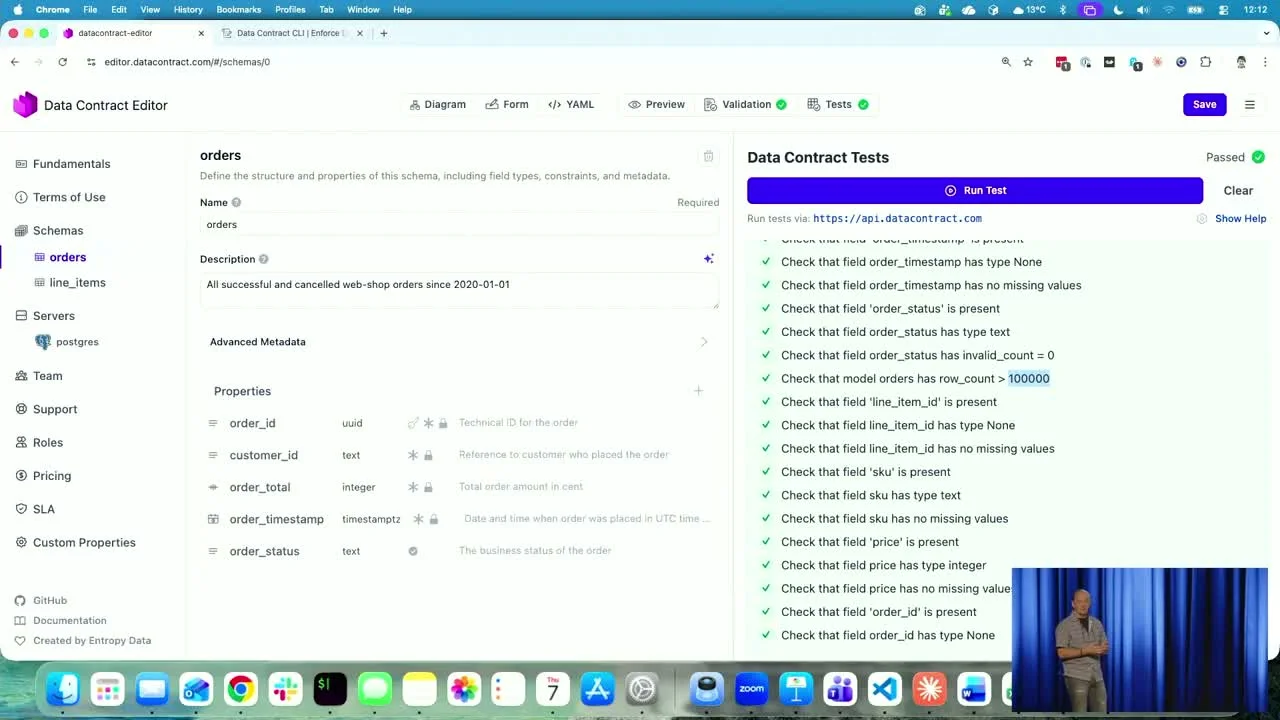
Der Editor ist mit einer auf Supabase gehosteten Postgres-Datenbank verdrahtet. Ein Klick auf Run Test feuert SQL-Proben über die CLI ab und bringt einen grünen Report zurück: Jedes Feld des erwarteten Schemas ist vorhanden und korrekt typisiert, order_status hat keine ungültigen Werte, und die Zeilenanzahl liegt deutlich über dem vom Contract geforderten Minimum von 100.000.
Alles, was du in SQL ausdrücken kannst, wird zu einem Qualitätscheck. Alles, was du ausdrücken kannst, wird zu einem kontinuierlichen Test.
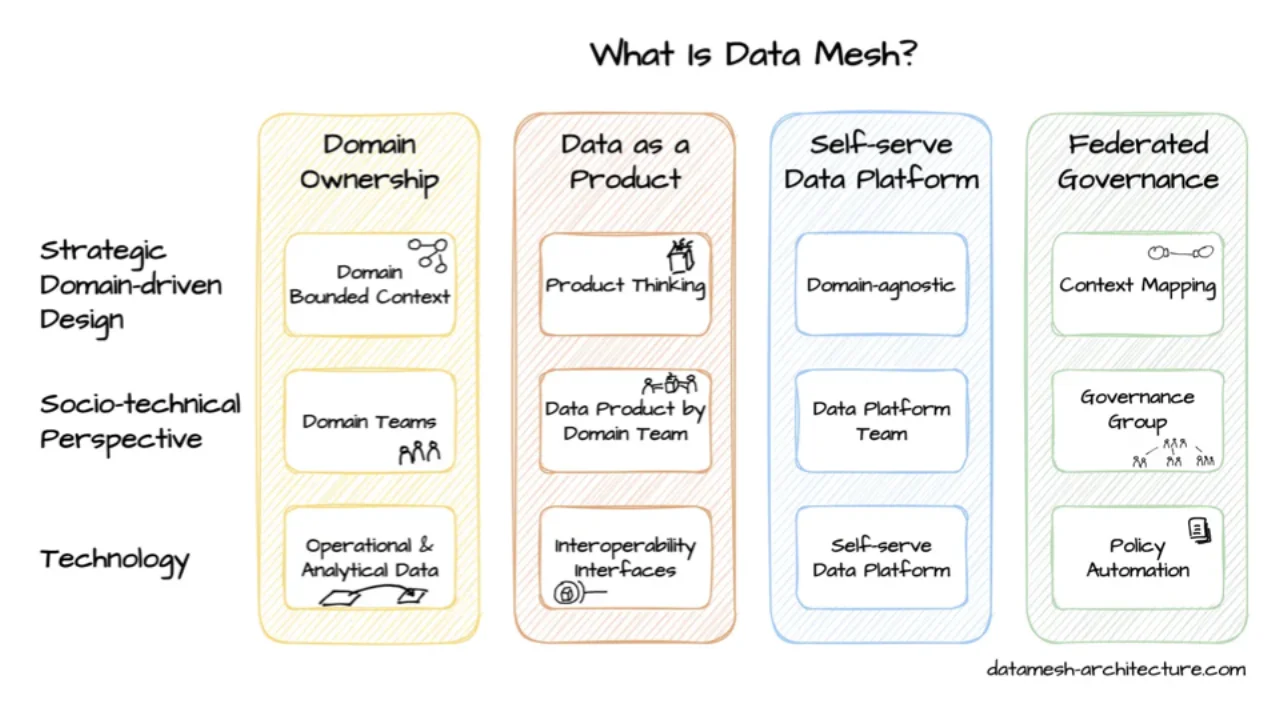
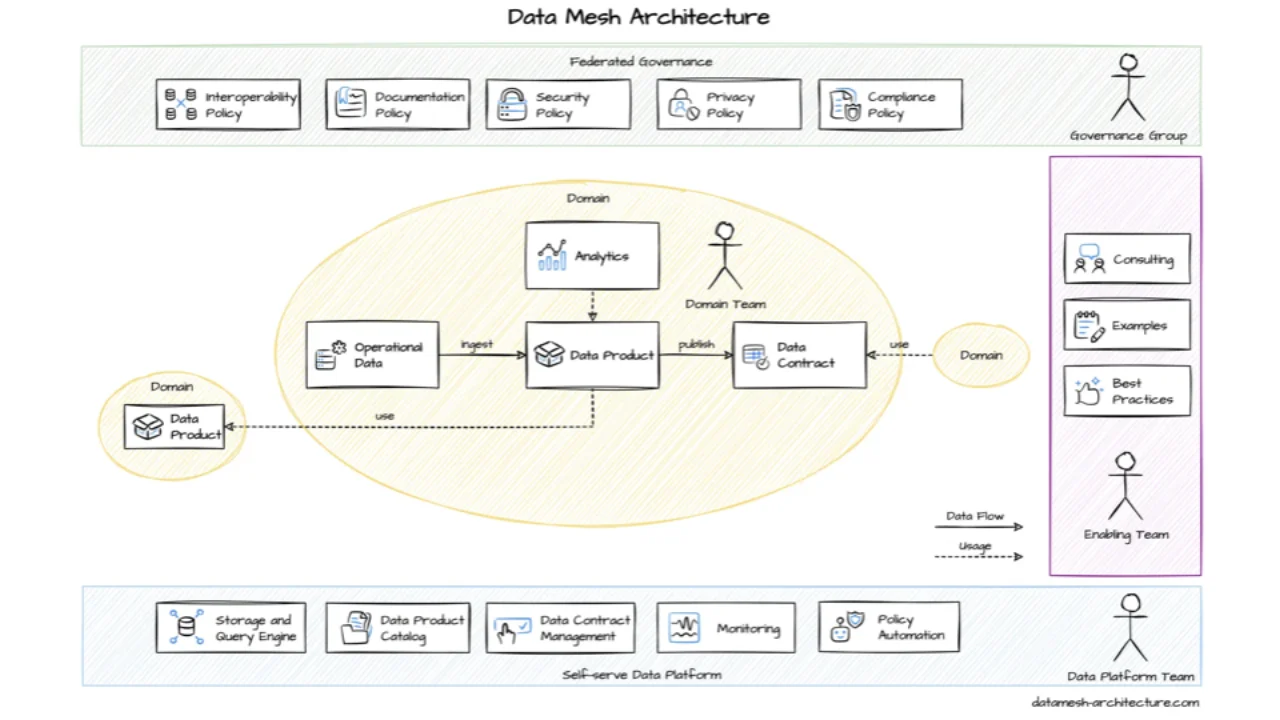
Wo Data Contracts ins große Ganze passen
Data Contracts passen natürlich zu Data Mesh: Domain Ownership, Data-as-a-Product, Self-Serve-Plattform, föderierte Governance. Domain-Teams bauen Datenprodukte, die Contracts anderer Datenprodukte konsumieren und neue bereitstellen. Es ist das API-Denken, das wir bei Services schon tun -- Produkt-Denken, Plattform-Denken, Governance -- jetzt auf Daten angewandt.
Du musst kein Data Mesh einführen, um Data Contracts zu nutzen. Das Minimum sind zwei Teams: eines, das Daten produziert, eines, das sie konsumiert. Mesh passt sehr gut, ist aber keine Voraussetzung.
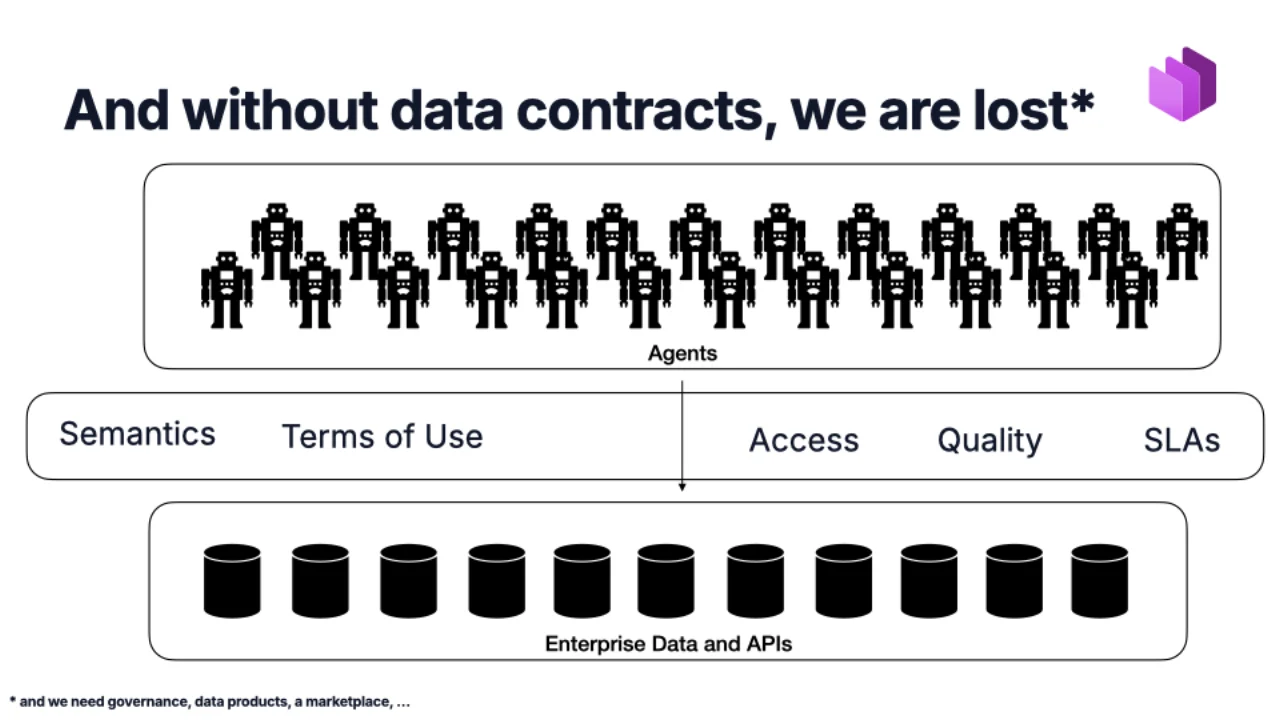
Der wahre Grund, warum Data Contracts gewinnen: KI-Agenten
Agentic Coding ist der kleine sichtbare Teil. Der größere Gewinn sind Agenten, die mit Unternehmensdaten sprechen. Und ein Agent weiß von sich aus nicht, was deine Tabellen bedeuten, wie frisch die Daten sind, ob sie für Marketing genutzt werden dürfen oder wie man Zugriff anfragt.
Der Contract gibt ihnen all das: Semantik, Nutzungsbedingungen, Zugriff, Qualität, SLAs. Erinnerst du dich an die Daten-vs-Information-Folie -- ein Contract ist genau die Schicht, die rohe Daten in Information verwandelt, über die ein Agent nachdenken kann.
Ohne Contracts raten Agenten am Ende -- und joinen selbstbewusst die falschen Spalten. Mit Contracts haben sie geerdete Metadaten als Grundlage. Das ist die Wette.
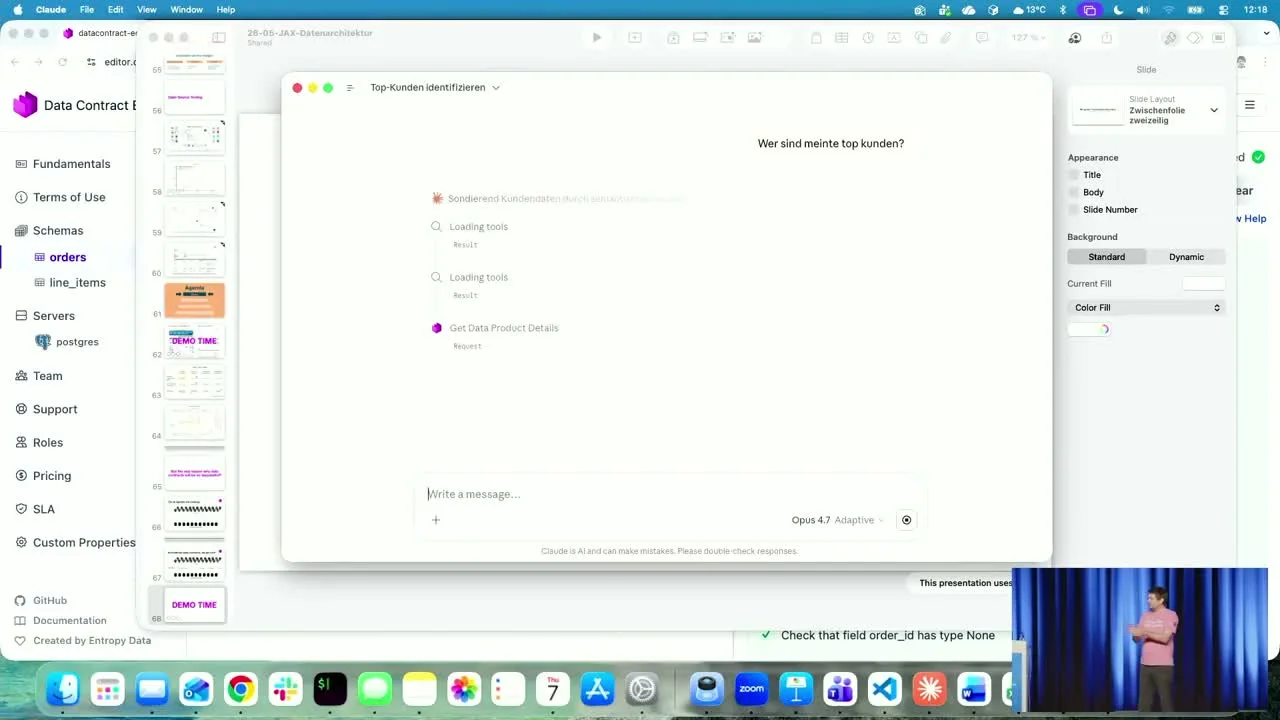
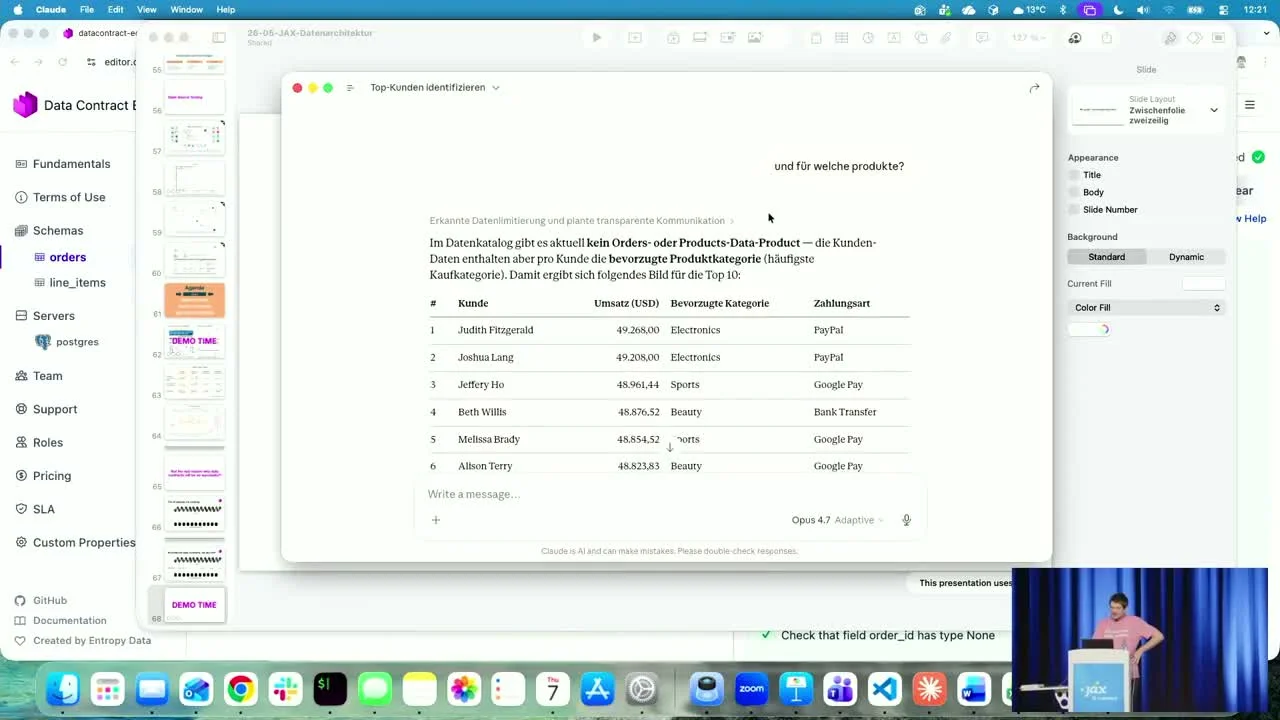
Live-Demo: Ein Agent auf der Contract-Schicht
Gleiches Setup, eine Schicht höher. Ein Agent (Claude Opus) ist mit dem Entropy Data MCP-Server verdrahtet, der den Datenmarktplatz bereitstellt -- durchsuchbare Datenprodukte, jedes mit seinem ODCS-Contract.
Ein Business-User fragt, auf Deutsch: "Wer sind meine Top-Kunden?" Der Agent durchsucht die Datenangebote anhand der Metadaten der Contracts, wählt das Datenprodukt, das die Frage beantworten kann, prüft, ob Zugriff besteht (und würde automatisch eine Anfrage stellen, falls nicht), führt SQL aus und liefert eine Top-10-Tabelle -- Name, Umsatz, bevorzugte Produktkategorie, Zahlungsmethode. Dann eine Folgefrage: "und für welche Produkte?" -- und es geht transparent weiter, indem es dem User mitteilt, was es finden konnte und was nicht.
Der Punkt ist nicht, dass der Agent clever ist. Der Punkt ist, was der Contract möglich macht: Business-User, die direkt Hypothesen formulieren, statt ein Ticket einzureichen und wochenlang darauf zu warten, dass ein Data Team einen Cube baut.

Die Vorhersage
Swagger 1.0 kam 2011 heraus. Es hatte anfangs nicht einmal Schemas -- nur Endpoints. Heute hat jede REST-API, die du anfasst, eine OpenAPI-Spec.
ODCS 3.0 -- die erste unternehmensneutrale Version -- erschien 2025. Die Wette: In fünf Jahren steht es da, wo OpenAPI heute steht. Die Dinge bewegen sich heute schneller als 2011.
Die Einstiegskosten sind gering. Ein beliebiger Texteditor, zehn Zeilen YAML und die Open-Source-CLI -- genug, um den Fit gegen deinen eigenen Use-Case zu validieren. Du kannst proaktiv statt reaktiv sein.

Danke
Danke an das JAX-2026-Publikum für die Geduld mit seiner Mittagspause und an die Konferenz für den Slot. Wenn du das Gespräch fortsetzen willst:
Probier den Contract-basierten Datenprodukt-Marktplatz auf entropy-data.com aus, und gib bitte datacontract-cli einen Stern auf GitHub, wenn es nützlich war.
Q&A
Ausgewählte Fragen aus dem Publikum nach dem Talk.
F: Wie werden Contracts eigentlich durchgesetzt -- insbesondere bei Datenexfiltration und Nutzungslimits?
Auf der Producer-Seite kannst du die Garantien, die du gibst, absolut durchsetzen: Schema, Freshness, Qualität. Die Consumer-Seite der Vereinbarung durchzusetzen -- "du darfst diese Daten nur für Zweck X nutzen, nicht für Y" -- ist schwieriger. Unsere Antwort ist, vielleicht wenig überraschend, mehr KI: KI-Verhalten kannst du nur wirklich mit einer weiteren KI kontrollieren. Ein rein regelbasierter Filter lässt entweder alles durch oder würgt das Modell zur Nutzlosigkeit ab. Du kannst es auch nach Klasse härten -- z. B. ist es der KI schlicht verboten, die sensibelsten Datasets überhaupt anzufassen. Das ist regelbasiert und sauber, bedeutet aber auch, dass die KI bei diesen Datasets nicht helfen kann. So oder so ist die Tatsache, dass die KI weiß, dass die Daten existieren und wo sie liegen, selbst ein Risiko, das du managen musst -- genauso, wie wir jede andere Dual-Use-Technologie managen.
F: Braucht man eine zentrale Registry, damit Contracts überhaupt auffindbar sind?
Ja. Wir empfehlen einen Datenmarktplatz: einen zentralen Ort, an dem Consumers nach Daten shoppen können und Zugriff als Teil dieses Flows angefragt wird. Es ist das Analogon zu einem API-Gateway oder API-Katalog. Die Contracts selbst werden dezentral von den Domain-Teams verwaltet, aber die Registry muss zentral sein, damit die Discovery-Story funktioniert -- die klassische Balance aus Dezentralisierung und Zentralisierung, die du in jeder Plattform finden musst.
F: Wie passt das zu Service-Contracts und OpenAPI? Beschreiben die nicht auch Daten, über DTOs?
OpenAPI beschreibt die Form einer einzelnen Zeile: dieses Feld ist optional, jenes nicht, vielleicht ein Regex. Darüber hinaus schweigt es. Es sagt dir nicht, ob ein Feld PII-sensibel ist, welche interne Schutzklasse es hat oder wie es mit anderen Konzepten im Business zusammenhängt. Die Verbindung von orderId in der API zu OID2 in einer Datenbanktabelle ist genau das, was nur ein Semantic Layer erfasst. Mit guten Metadaten -- ODCS auf der einen, OpenAPI auf der anderen Seite -- kann die KI erkennen, dass beides dasselbe Konzept ist, und darüber joinen. Ohne das muss sie annehmen, und Annahmen sind meistens falsch.
F: Sollten wir aufhören, lesende Schnittstellen für externe Systeme zu bauen, und stattdessen einfach Data Contracts veröffentlichen?
Ein REST-GET ist bereits eine lesende Schnittstelle, also kannst du technisch einen Contract darauf legen -- die einzige Prämisse eines Data Contracts ist, dass Daten zum Lesen geteilt werden. Die tiefere Frage ist Design: kleine, Punkt-zu-Punkt-APIs, jede auf das Anfragemuster eines einzelnen Consumers zugeschnitten, vermehren sich schnell und werden in der Datenwelt zur Wartungslast. Du willst wenige, gut designte Angebote, die viele Consumers bedienen -- Produkt-Denken, one-to-many. Derselbe Instinkt, der uns von Microservices pro Consumer wegführt.
F: Ein Contract beschreibt die Producer-Seite. Wie siehst du, wohin die Daten tatsächlich fließen -- wer sie konsumiert, wie sie genutzt werden?
Ein Marktplatz bringt dich ein Stück weit: Consumers fragen Zugriff mit einem angegebenen Zweck an, der festgehalten wird. Darüber hinaus berichten Lineage-Formate wie OpenLineage, wie Daten tatsächlich durch die nachgelagerten Systeme fließen, inklusive Column-Level-Lineage. Kombiniere beides, und du kannst prüfen, ob deine Makroarchitektur-Richtlinien zu den realen Flüssen passen -- ein mächtiges Audit von "was wir sagten zu tun" gegen "was tatsächlich passiert".