Talk · JAX 2026
Data Architecture: The New Backbone of Modern Software
Dr. Gernot Starke (INNOQ Fellow) & Dr. Simon Harrer (CEO, Entropy Data) · May 7, 2026
A joint talk at JAX 2026 in Mainz. Gernot opens with the long view -- the history of data storage and a thesis that software engineering largely forgot about data between 1995 and 2020. Simon follows with the fix: data contracts as the API specification layer for data, the Open Data Contract Standard (ODCS), and a live demo of an AI agent answering business questions on top of contract-backed data products.

Recorded live at JAX 2026 in Mainz. The annotation below is an edited English summary of the talk.


Two Speakers
Gernot Starke is an INNOQ Fellow, co-founder and maintainer of arc42, co-founder of aim42 and the iSAQB, and has been doing software architecture for a very long time. Data has always been part of that, even when the rest of the industry stopped talking about it.
Simon Harrer is a product engineer at heart, co-author of "Java by Comparison" and "Remote Mob Programming", and co-translator of Zhamak Dehghani's "Data Mesh" into German. He spent years at INNOQ before co-founding Entropy Data as a spin-off in 2025. He co-maintains the Data Contract CLI and Data Contract Editor, and serves on the TSC of the Linux Foundation's BITOL project for open data contract and data product standards.


Data vs. Information
Everyone in IT knows the difference, but it is worth saying again. Data is the unordered pile of Lego bricks in the drawer -- isolated symbols with no meaning on their own. 42 or 07.05.2026 is just a value.
Information is data in context, with semantics. "Temperature is 42 °C" or "Talk on 2026-05-07" is something you can act on. The whole story of data architecture is about turning the first thing into the second.




From Core Memory to Floppies
The IT side starts in the 1950s with core memory: tiny iron rings threaded onto wires that you magnetised one way or the other to store a bit. Nothing to do with nuclear energy -- "Kern" just means core -- and almost nobody in the room had ever touched one.
In 1956, IBM shipped the first hard disk: a stack of magnetic platters that held 5 megabytes and weighed about one ton. By the 1970s the compact cassette had been pressed into service as a data medium -- 300-400 kilobytes per side, which today buys you roughly half an app icon.
Then came 8-inch, 5.25-inch and 3.5-inch floppies -- bendy, dust-sensitive, and with almost nothing on them. 80 kB on the early ones, up to 2880 kB on the very last. Datenträger ("data carriers"), in the most literal sense.



From Gigabytes to Ångström
By the 2000s consumer drives were measured in tens of gigabytes, then SSDs in 2010+ pushed the same form factors into the terabyte range. Today's data-centre drives are 24 TB and counting -- and ironically also hard to buy, because every one of them disappears into a hyperscaler.
The fascinating part is what the storage industry quietly became: a Seagate explainer Gernot showed talks about read-write heads flying over the platter at Ångström-scale tolerances -- molecular sizes. Hard-drive vendors are operating in the same precision regime as ASML's chip-fab machines. Worth a four-minute watch.


Trade as a Data Use Case
Recording things has been a basic need of civilisations forever. Trade is a clean example. Egyptian pyramid builders already kept transaction lists. Medieval merchants tracked what they bought and sold with gilded quills.
Then someone invented double-entry bookkeeping -- doubling the amount of data a merchant had to keep, on purpose, in order to reduce errors. It is essentially a system for data quality. (Spoiler: that idea will come back.)
Today, in a modern retail group, data is the gold. It is what lets you negotiate better purchasing terms, allocate stock across stores, and personalise offers. You can have brilliant algorithms, polished dashboards and the world's best ML models -- if the data feeding them is mediocre, what the manager pulls out the other end is mediocre too.


Challenge #1: Software Engineering Forgot Data
The thesis is provocative on purpose: between 1995 and 2020, software engineering largely forgot about data. We were busy with other things.
1995-ish, C++ went mainstream, Java arrived, and everyone learned object orientation -- inheritance, methods, coupling and cohesion. The functional side of software. In the 1980s the term "data model" was still common; by the late 1990s it was almost dirty. Then SOA. Then agile and Scrum (data is not a word that appears anywhere in the Scrum Guide). Then microservices. All of it focused on behaviour, none of it on the shape of the data that was flowing around.
Gernot is happy to admit he was right in the middle of it. "Mit schuld" -- complicit. The point is not to apologise; the point is to notice what we are now climbing back out of.

Challenge #2: Data, the Only Asset Without an Owner
Every other asset in an enterprise has an owner. Data, traditionally, does not. Or rather, everyone thinks they own it, which is the same problem in a different shape.
Gernot's favourite example is from an insurer he worked at during the GDPR rollout. They had a cheerful "address-to-all" convention: whenever someone showed interest in a product, the address was forwarded to every internal recipient who might possibly want it. Then GDPR arrived, "Sylvia" asked to be deleted, and nobody could honestly say where her data had ended up. Nobody owned the address records.
He calls the resulting state, with permission, "Wildwuchs" -- wild growth. There is plenty of data, but no one knows which copy is authoritative, whether it is still valid, or whether it has the right number of decimal places.


Challenge #3: Pretty Pictures on a Swamp
Classical data warehouses produce beautiful reports. The trouble is they are often too late and built on bad data. Gernot has sat in plenty of meetings where someone pulled a tower-case-era Excel sheet out and said: "well, my numbers are different".
That is shadow IT, and it appears precisely where the central data plumbing has failed people. Data lakes inherited the same problem at greater scale -- shovel everything in, hope something good comes out. Hope is a wonderful thing, but a poor data strategy.
The AI wave made this impossible to ignore. The moment a company decided to fine-tune its own model and went looking for training data, the answer was usually: we have a lot of data, but we have no idea which of it is correct. A model trained on a swamp is not intelligent. It is a swamp.

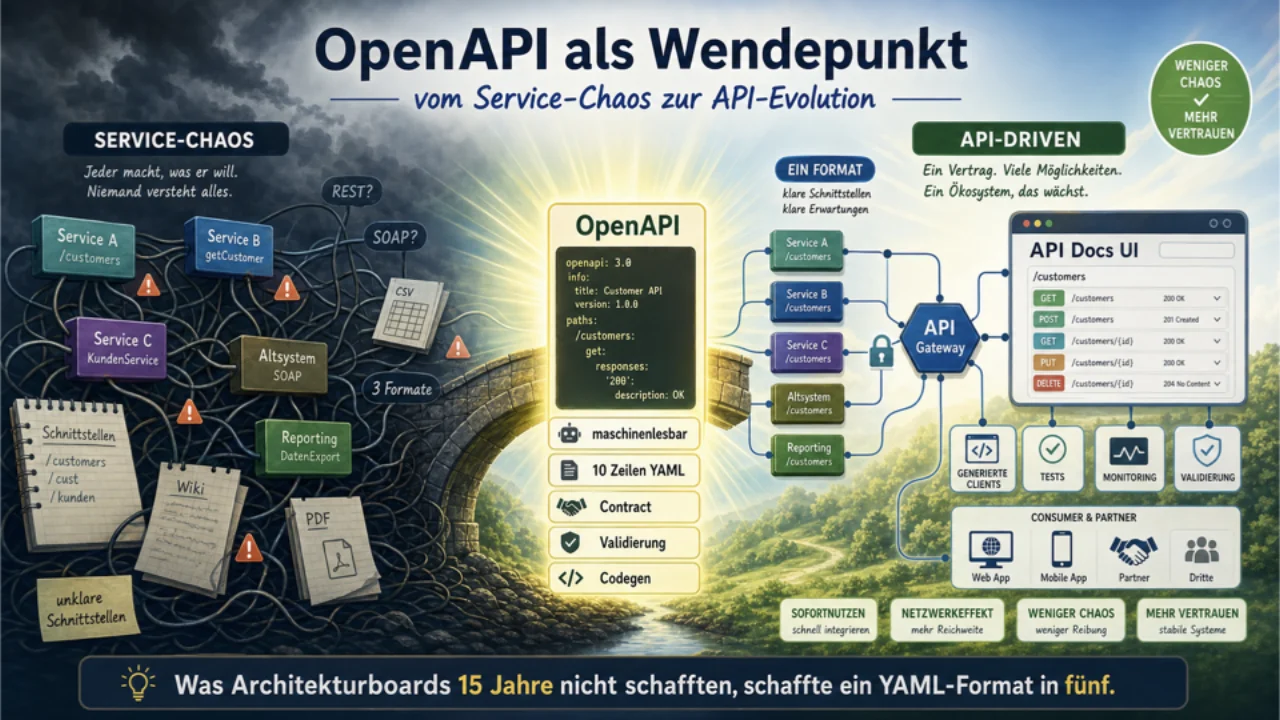

We Have Solved This Before
We have actually been in this kind of mess before. The 2000s "service chaos" looked very similar: SOAP/WSDL was heavy, REST was lightweight but had no contract, documentation lived in Confluence if at all, the ESB was the bottleneck. Nobody really knew what services they had.
What got us out was Swagger and then OpenAPI. One machine-readable, vendor-neutral, plain-text format. Ten lines of YAML are enough to start. Swagger UI gives you instant payoff. As Gernot puts it -- and he is careful with the word -- this was a genuine game-changer for how teams produce and consume services.
Now the same idea has to move into the data world.


Every Company Already Has Data APIs
REST has OpenAPI. Messages and events have AsyncAPI. What about shared datasets?
Because the truth is, every company already has dozens of "data APIs". They just don't look like APIs. They look like:
- CSVs on an SFTP
- JSON files on S3
- SQL tables on BigQuery / Snowflake
- Iceberg files on Azure One Lake
- Delta Live Tables on Databricks
- Excel files on SharePoint
One team produces, others consume. Dashboards, board reports, ML training, downstream pipelines all depend on these interfaces being stable and high quality. And when the producing pipeline silently changes a CSV header or empties a column, the dashboard just shows a different number. No error, no alert -- the worst possible failure mode.
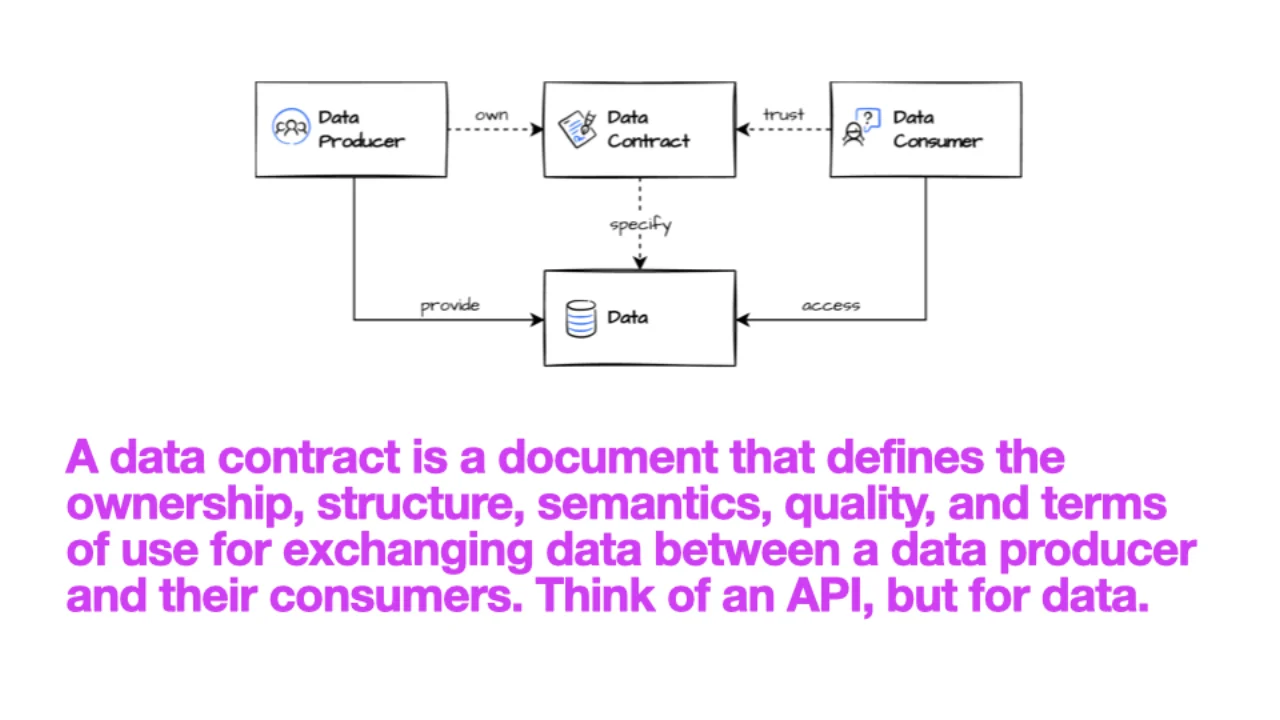
What Is a Data Contract?
A data contract is a document that defines the ownership, structure, semantics, quality, and terms of use for exchanging data between a producer and its consumers. Think of an API specification, but for data.
The producer owns the contract and declares the guarantees. The consumer reads it and trusts it. Without one, consumers fall back to reverse-engineering the schema by staring at sample rows -- guessing that OID2 is the order number when it might be something else entirely. Those silent misreadings are very hard to catch.
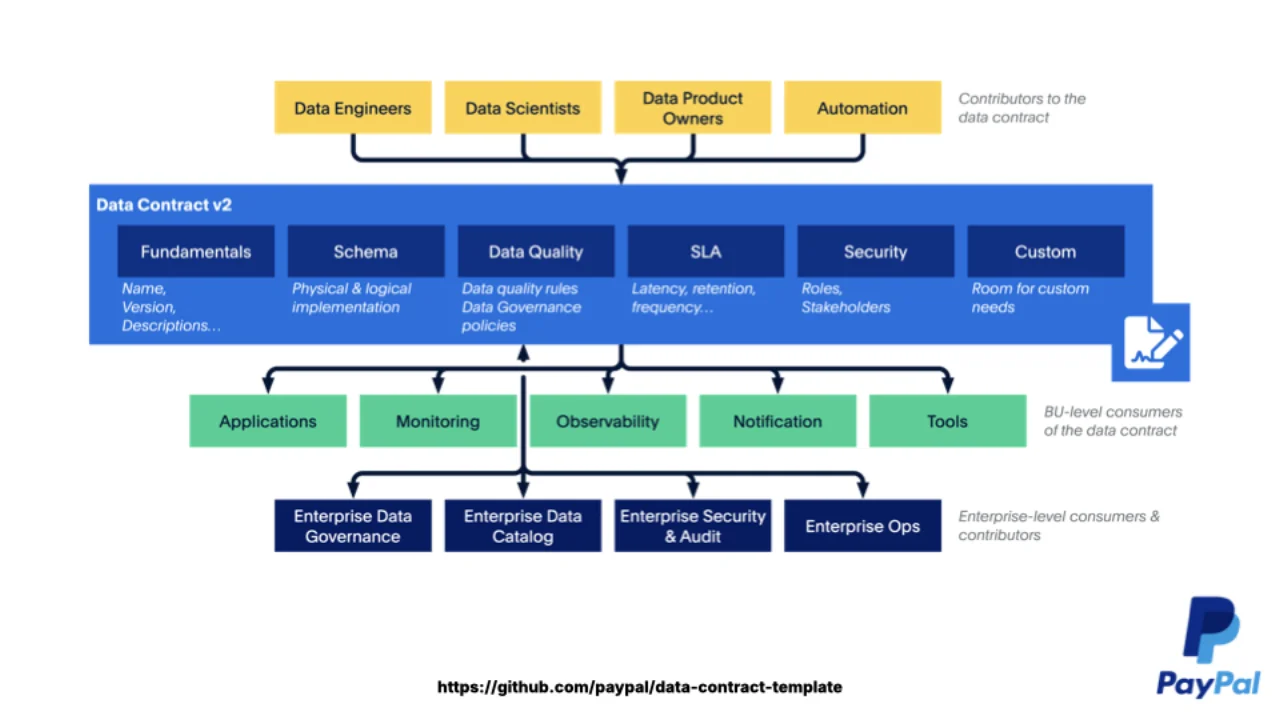
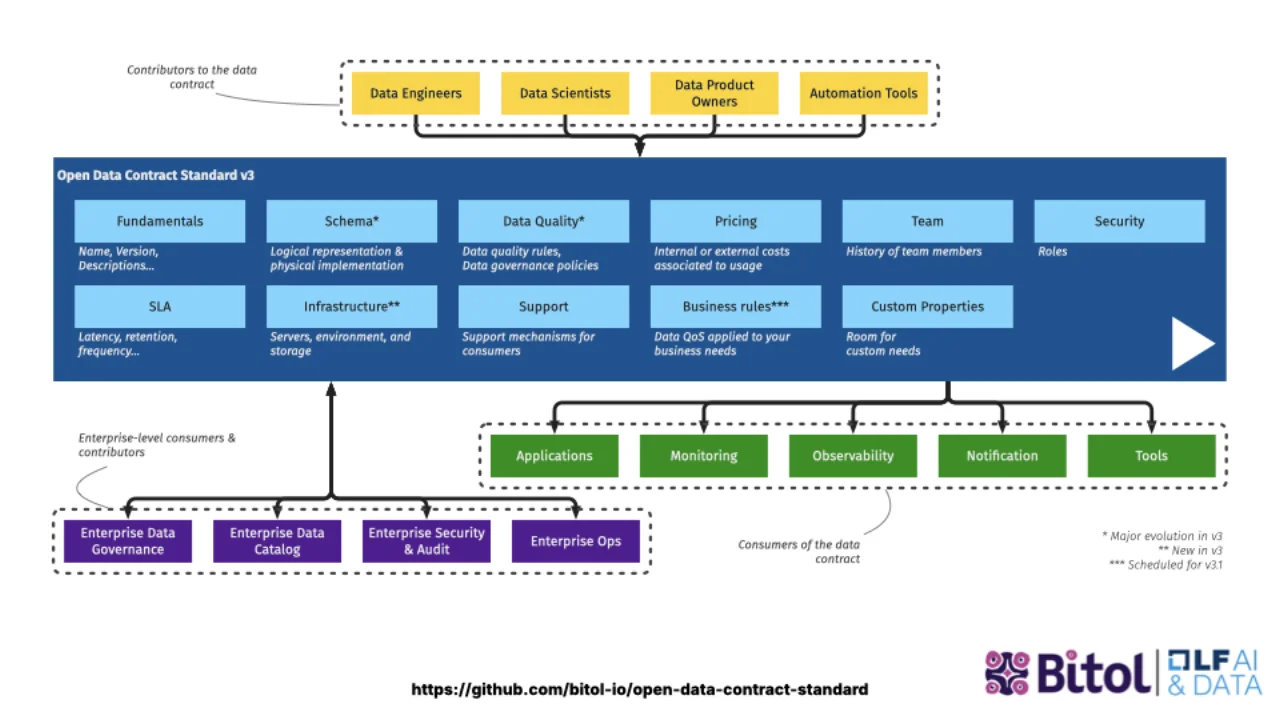
From Snowflakes to a Standard
When the need first showed up, every company invented their own format. Some YAML, some JSON, some Excel, even Word documents. All trying to encode the same thing: what does each field mean, what is its quality, what is the SLA, what are the terms of use.
PayPal open-sourced their internal template and donated it to the Linux Foundation as ODCS 2.2. Simon joined the TSC and helped strip out the PayPal-specifics so that any enterprise could use it. ODCS 3.0, released in 2025, was the first version that was genuinely enterprise-neutral.
It now lives at BITOL, the Linux Foundation project for open data contract and data product standards, with healthy parity between end users, consultants and vendors on the committee -- the kind of governance that makes "standard" a real word and not a marketing one.
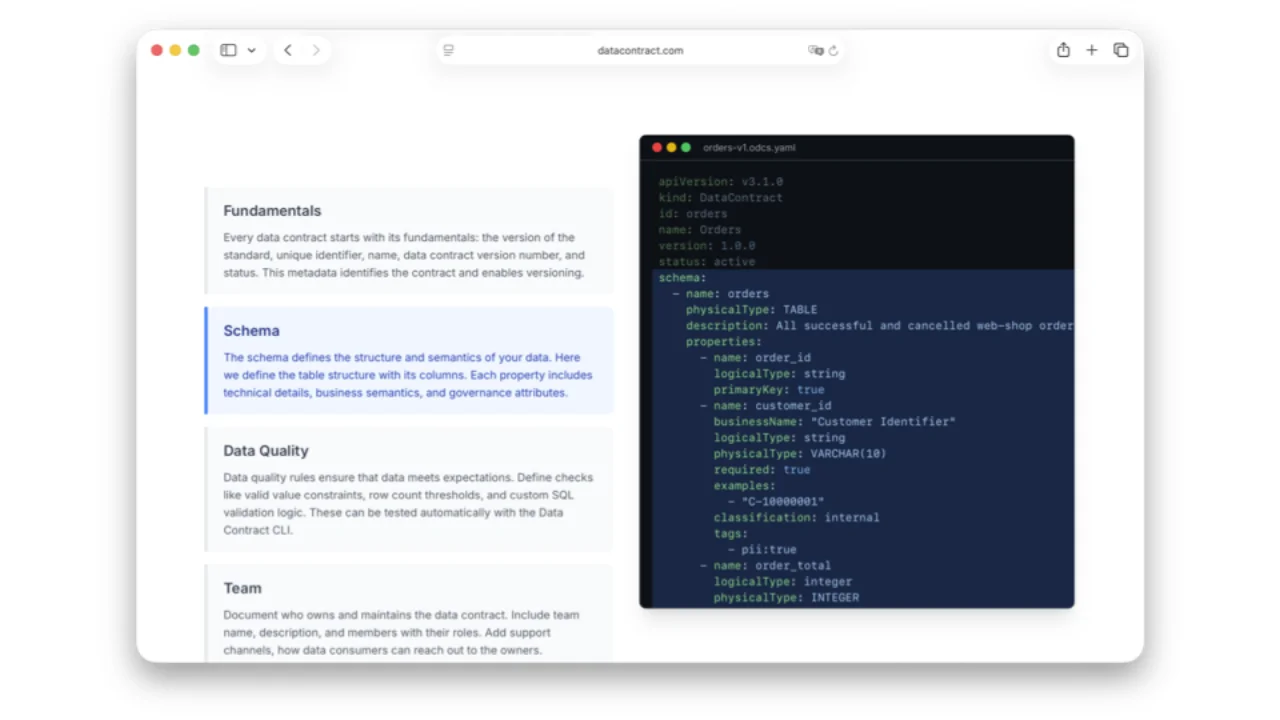
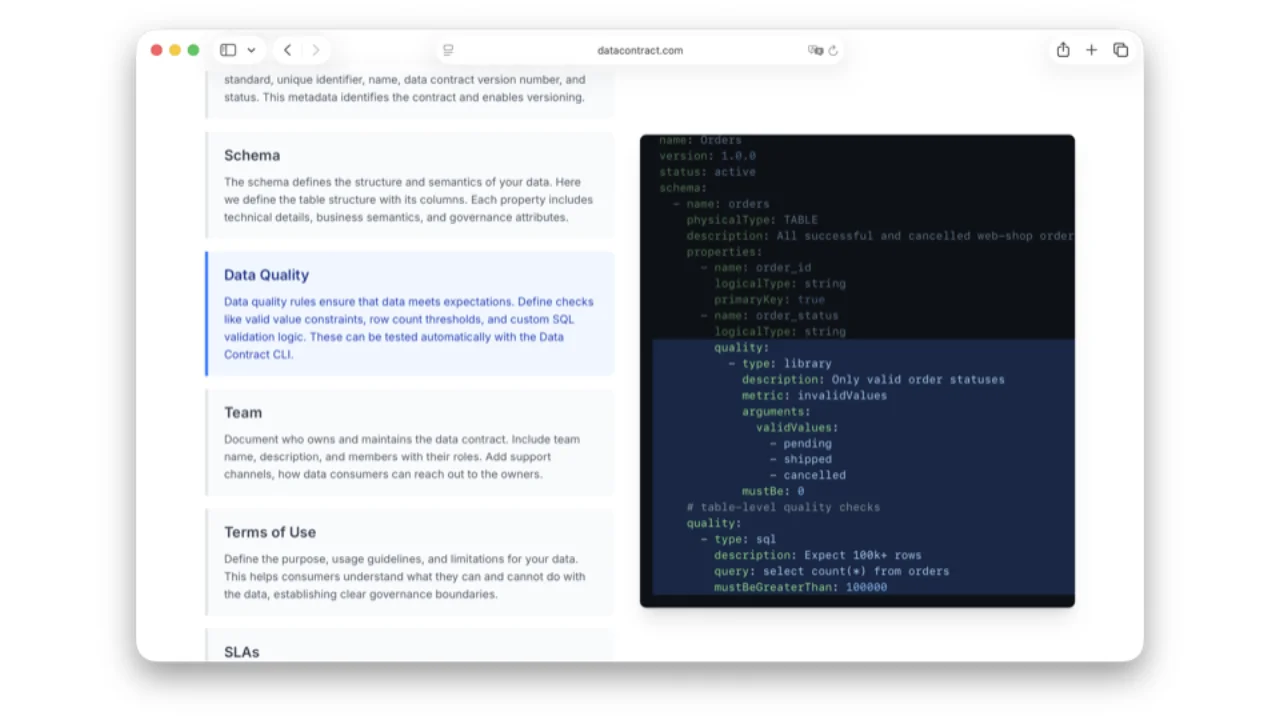
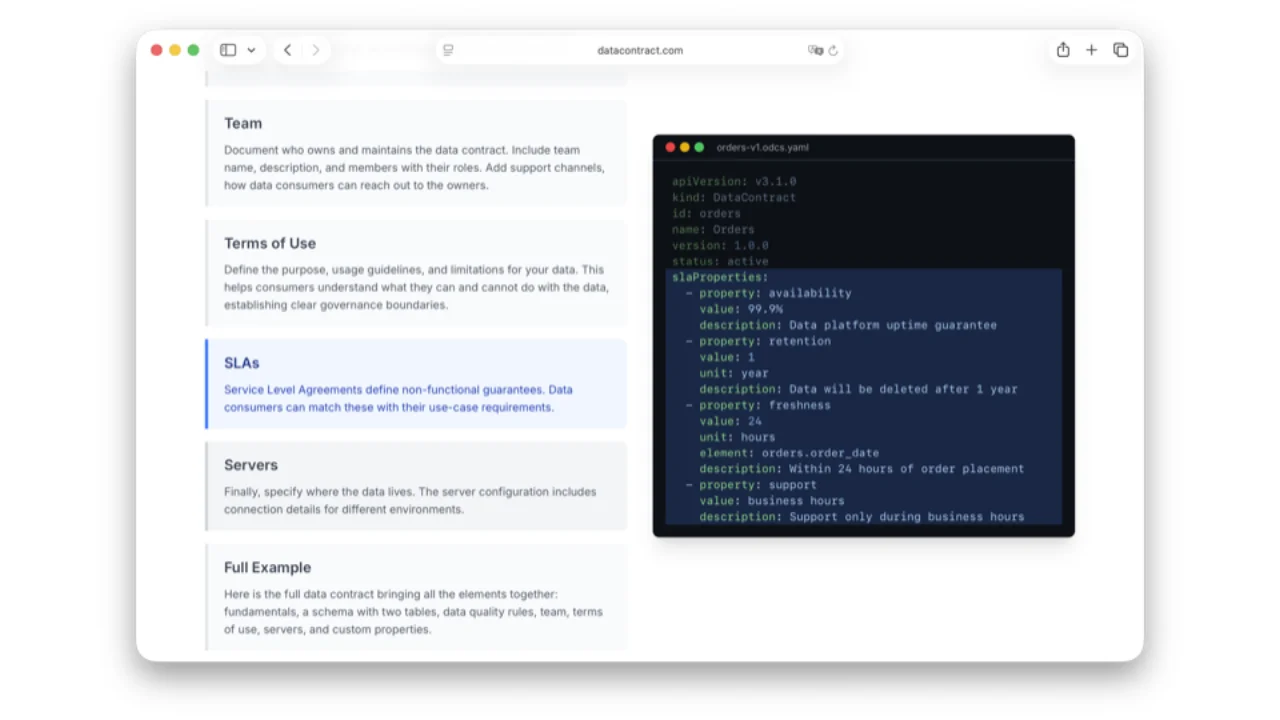
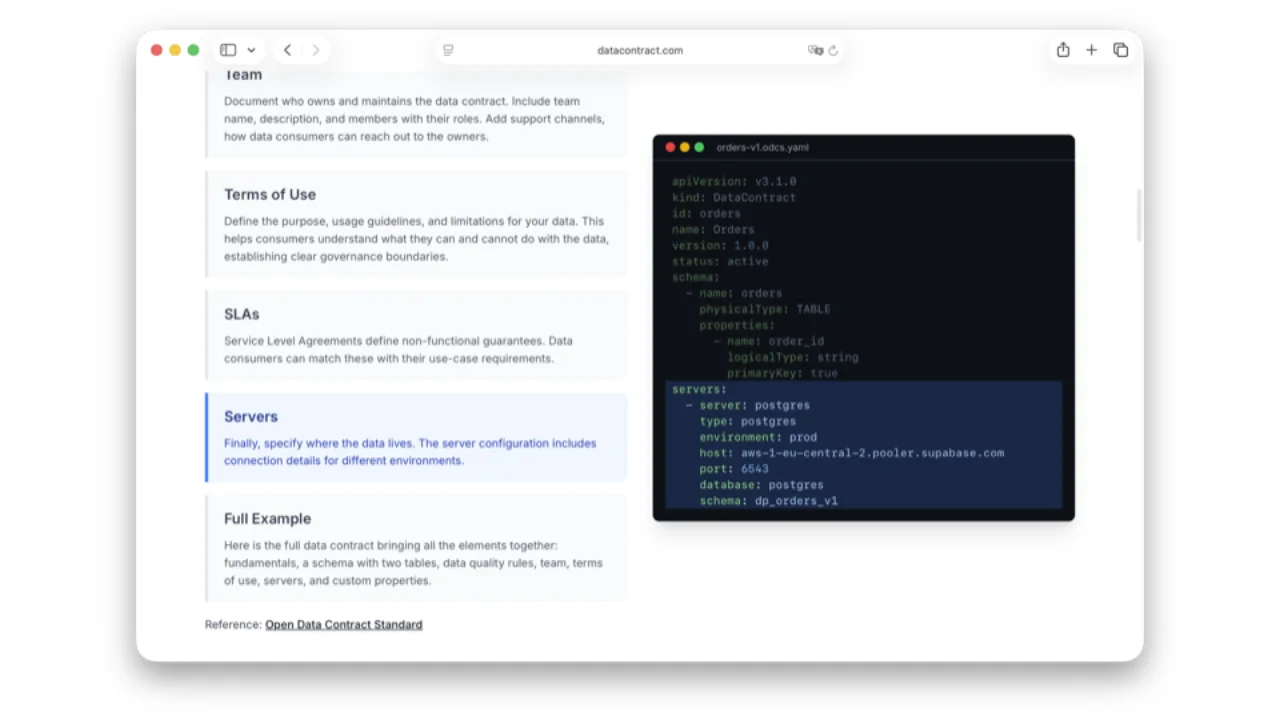
What's Inside an ODCS Contract
A single YAML file captures everything a consumer needs:
- Fundamentals -- id, name, version, status (for lifecycle).
- Schema -- tables and columns with logical & physical types, primary & foreign keys, business names ("Customer Identifier"), classifications, PII tags.
- Data Quality -- enums (
order_status ∈ {pending, shipped, cancelled}) or arbitrary SQL ("row count must be greater than 100,000"). Crucially, expressed as percentages, not strict required/optional -- real data is messy and ML models work fine with 99% completeness. - Team & Support -- owners, Slack channels, ticket systems.
- Terms of Use -- what consumers may and may not do with the data (geographic scope, PII-free guarantees, purpose limitation).
- SLAs -- availability, retention, freshness, latency. In the data world latency and freshness matter much more than platform uptime (Databricks / Snowflake / BigQuery are just up).
- Servers -- where the data actually lives, so an authorised consumer can connect straight to it.
"Making ownership explicit is the big step. Implicit was: producers thought structure and semantics had to evolve, consumers assumed they would stay frozen forever. That mismatch is why pipelines break."
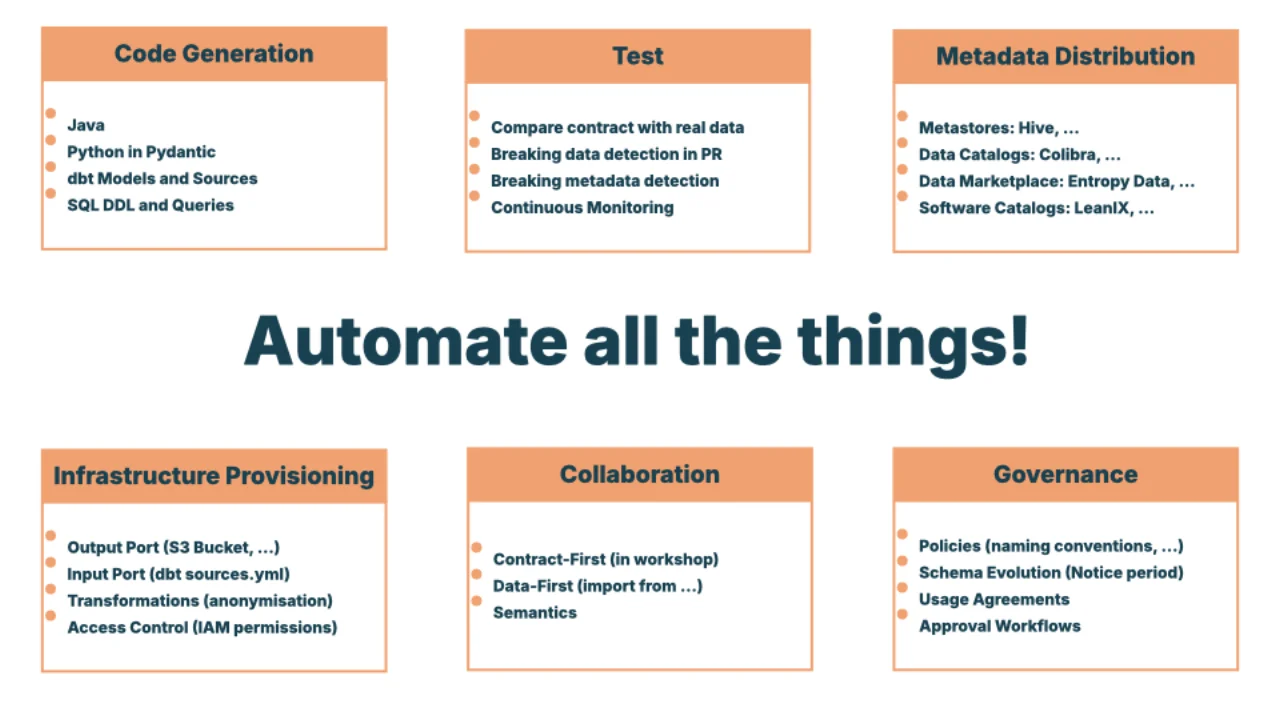
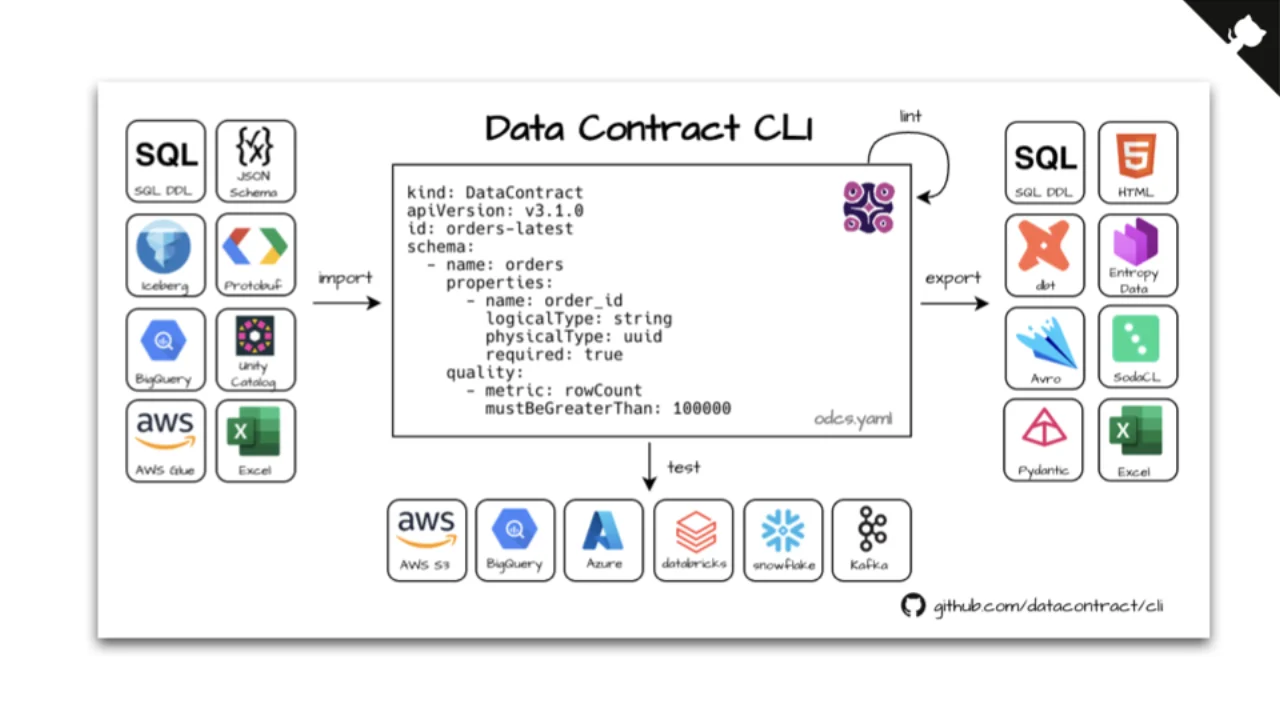
Automate All the Things
Once a contract is YAML, you can do a lot with it: generate Java / Pydantic / dbt models / SQL DDL, compare it against real data, fail PRs on breaking changes, continuously monitor in production, push metadata into catalogs (Colibra), marketplaces (Entropy Data), and software catalogs (LeanIX).
The open-source Data Contract CLI does the heavy lifting -- imports from SQL DDL, JSON Schema, Iceberg, Protobuf, BigQuery, Unity Catalog, AWS Glue, Excel; exports to SQL DDL, HTML, dbt, Entropy Data, Avro, SodaCL, Pydantic, Excel; tests against AWS S3, BigQuery, Azure, Databricks, Snowflake, Kafka.
"Quality checks used to be inherent invariants in our code. Now they live next to the data, in the contract -- and they run continuously."
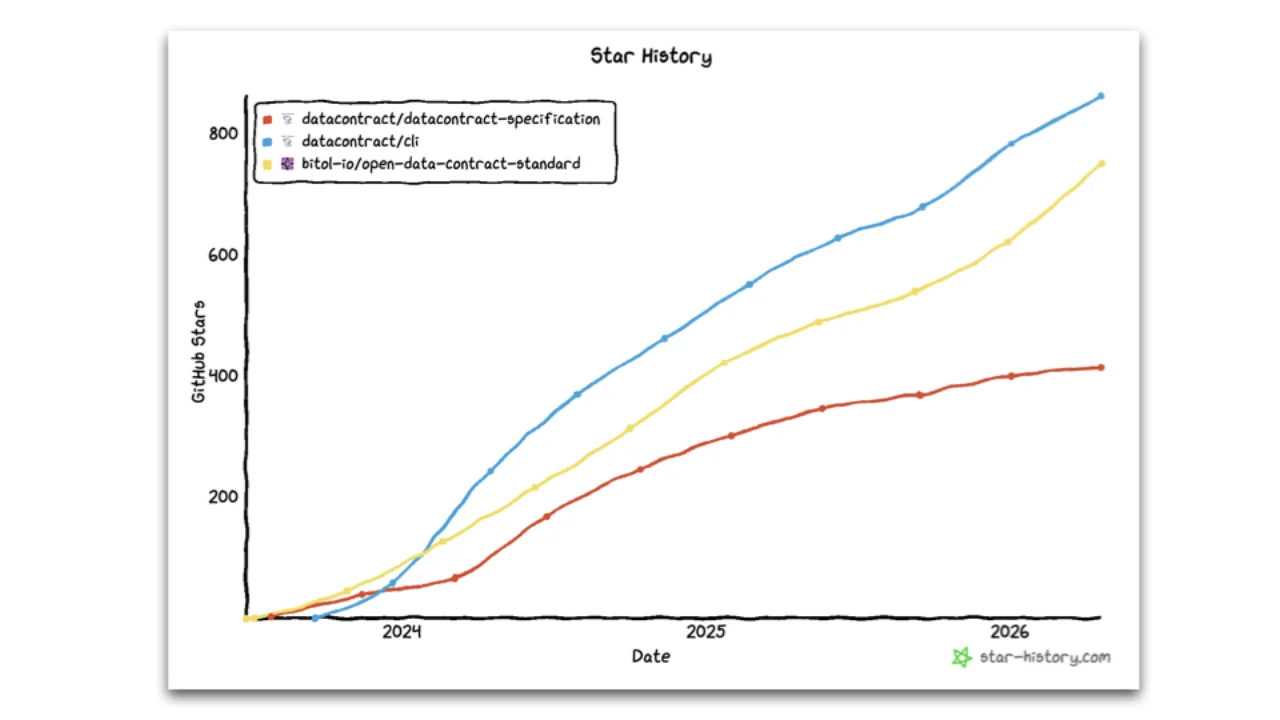
Tooling Matters More Than the Standard
If you look at GitHub stars, the Data Contract CLI is more popular than the ODCS spec itself. That is the OpenAPI lesson again: open standards need good open-source tooling to get adoption.
The standard is what gives you that tooling for free, lets you avoid vendor lock-in when multiple tools support the same format, and means teams help each other instead of reinventing the same YAML ten times in slightly different ways.
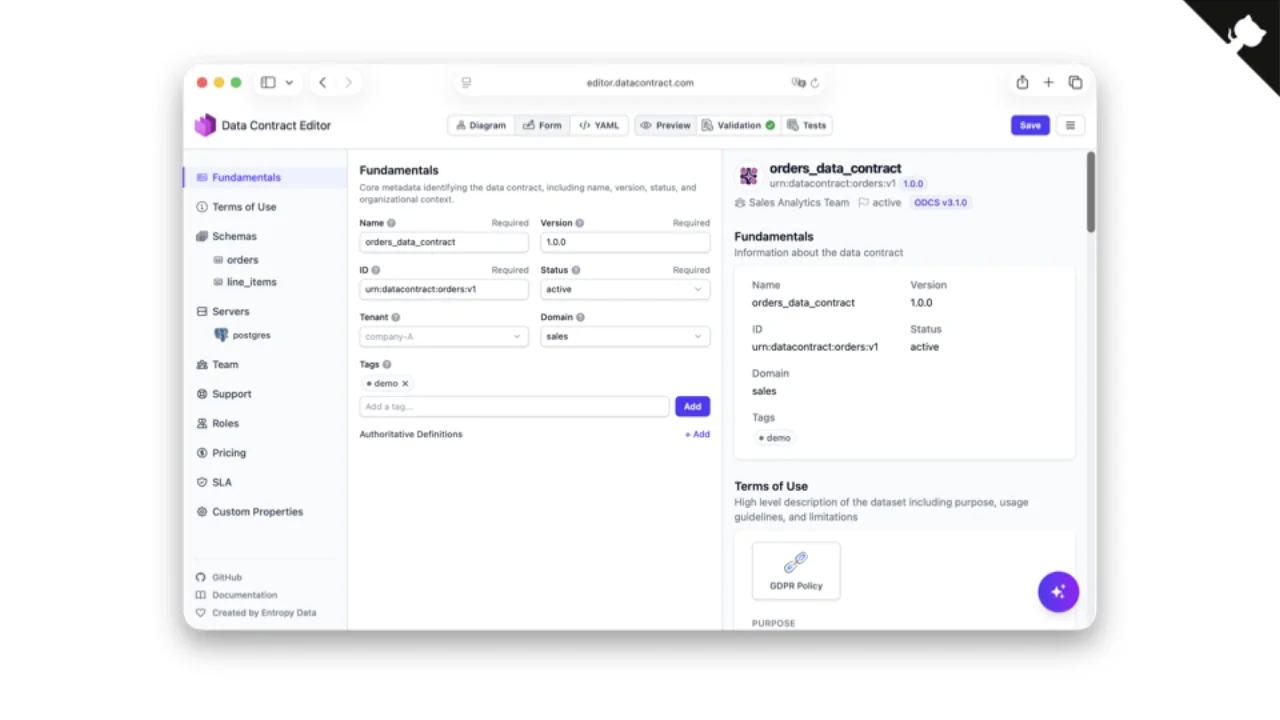
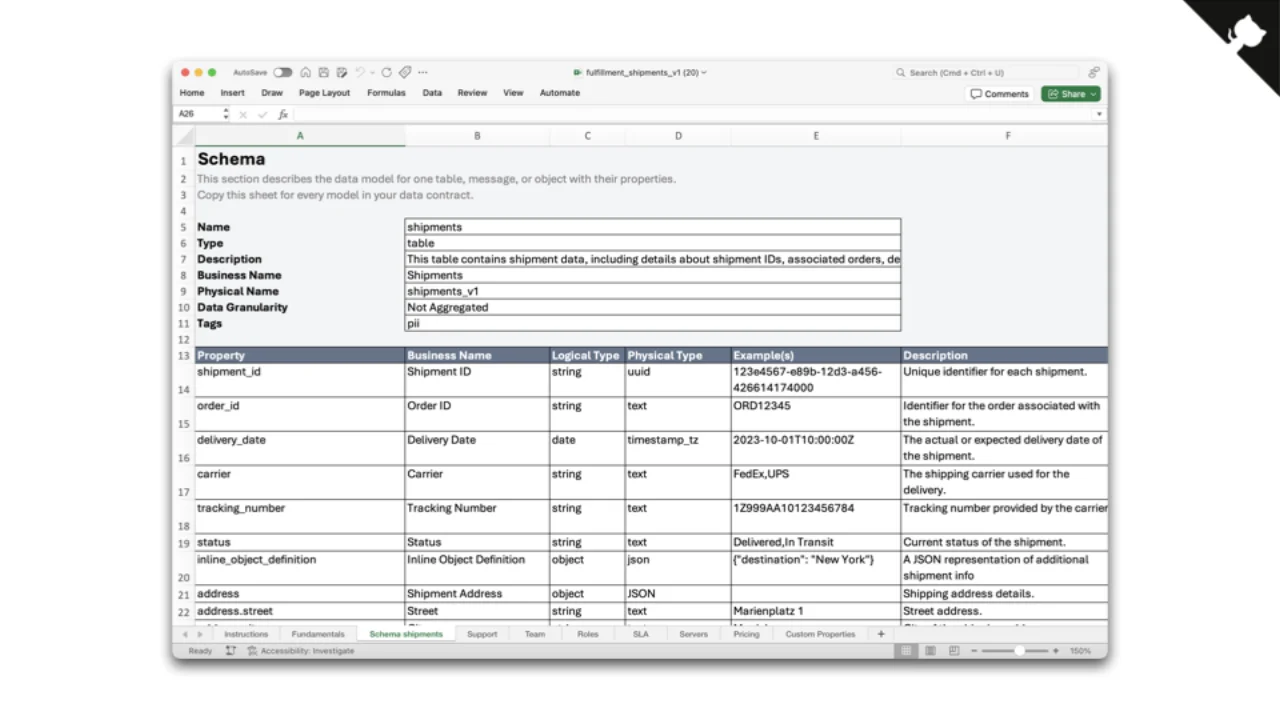
Editors for Humans (and Business People)
YAML by hand is tedious, so we built an open-source Data Contract Editor. Diagram view, form view, raw YAML view -- with preview and validation. It is integrated with the CLI, so while you edit you can re-run tests against the data and see whether the contract still holds.
For colleagues who never want to learn a new tool, there is also an ODCS Excel template. The CLI converts it to YAML. It is not beautiful, but it is practical -- and Excel is not going anywhere.
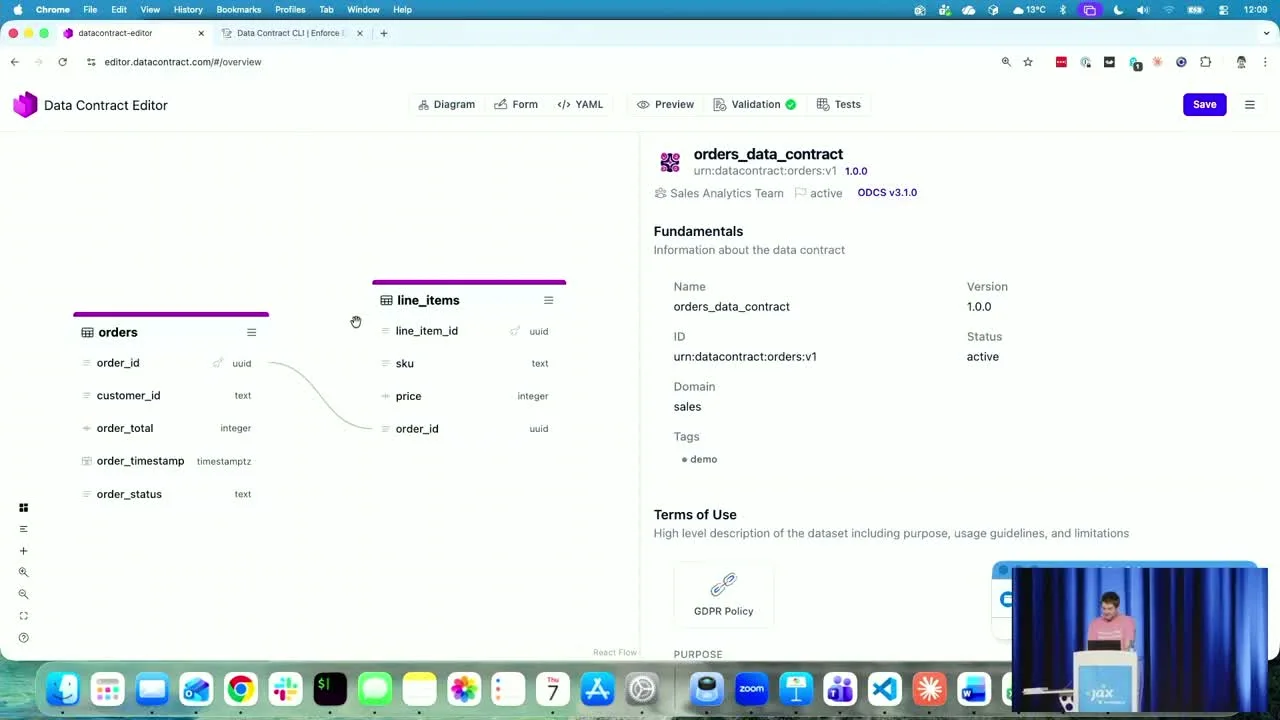
Live Demo: Editor + CLI on a Real Database
The editor at editor.datacontract.com renders an orders and line_items contract as a diagram, with a foreign key linking them. Each field has logical and physical types, examples ("C-10000001"), classifications (internal, PII), and a business-friendly description (SKU → Stockkeeping Unit).
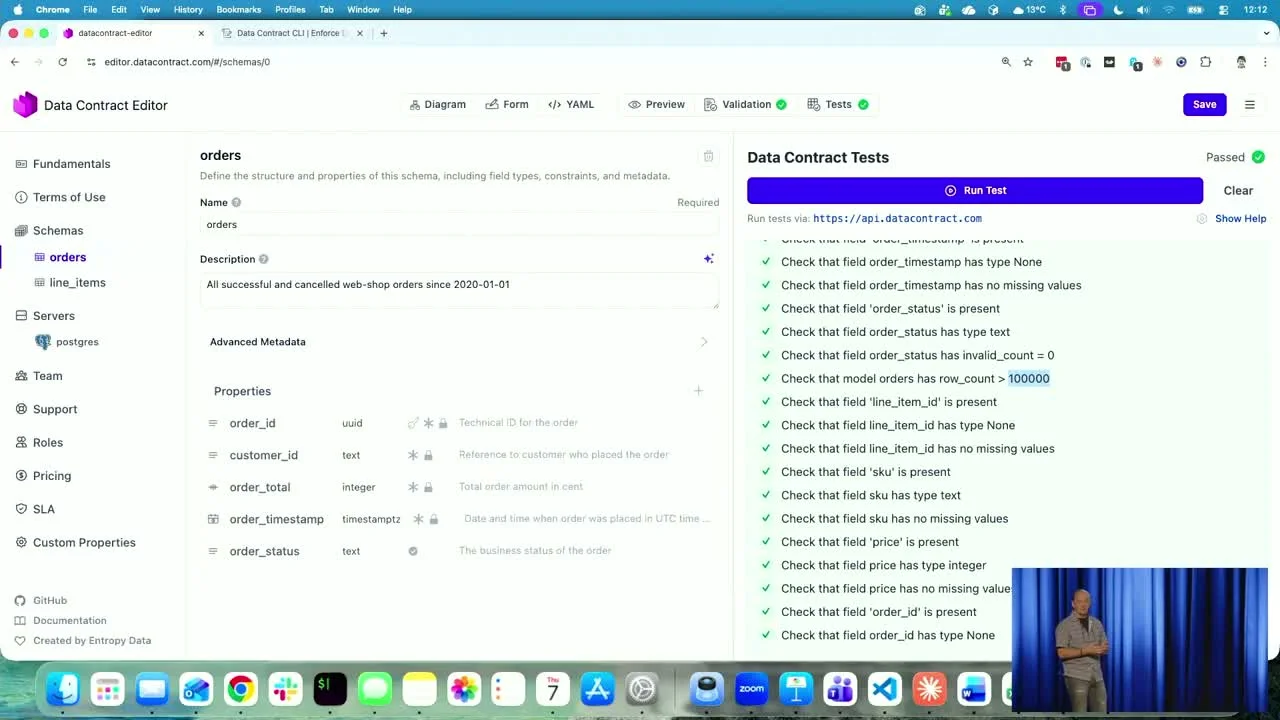
The editor is wired up to a Postgres database hosted on Supabase. Hitting Run Test fires SQL probes via the CLI and brings back a green report: every field of the expected schema is present and well-typed, order_status has no invalid values, and the row count is well above the 100,000 minimum the contract demanded.
Anything you can express in SQL becomes a quality check. Anything you can express becomes a continuous test.
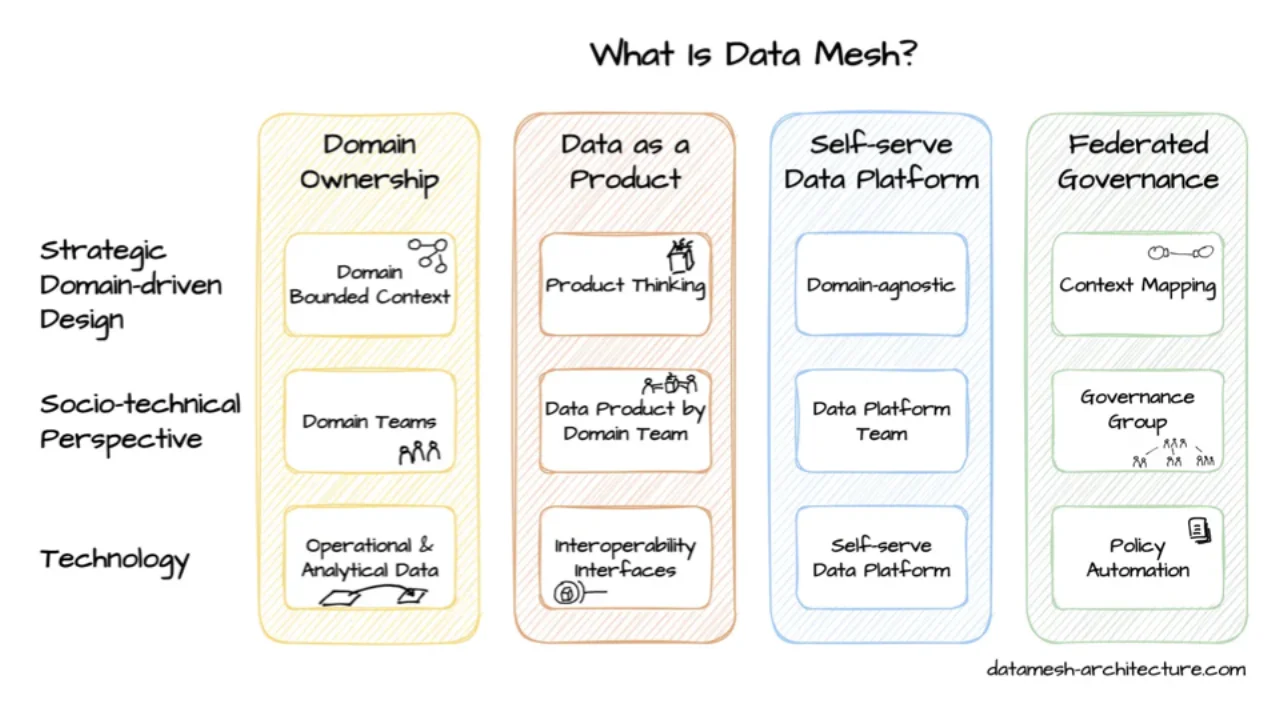
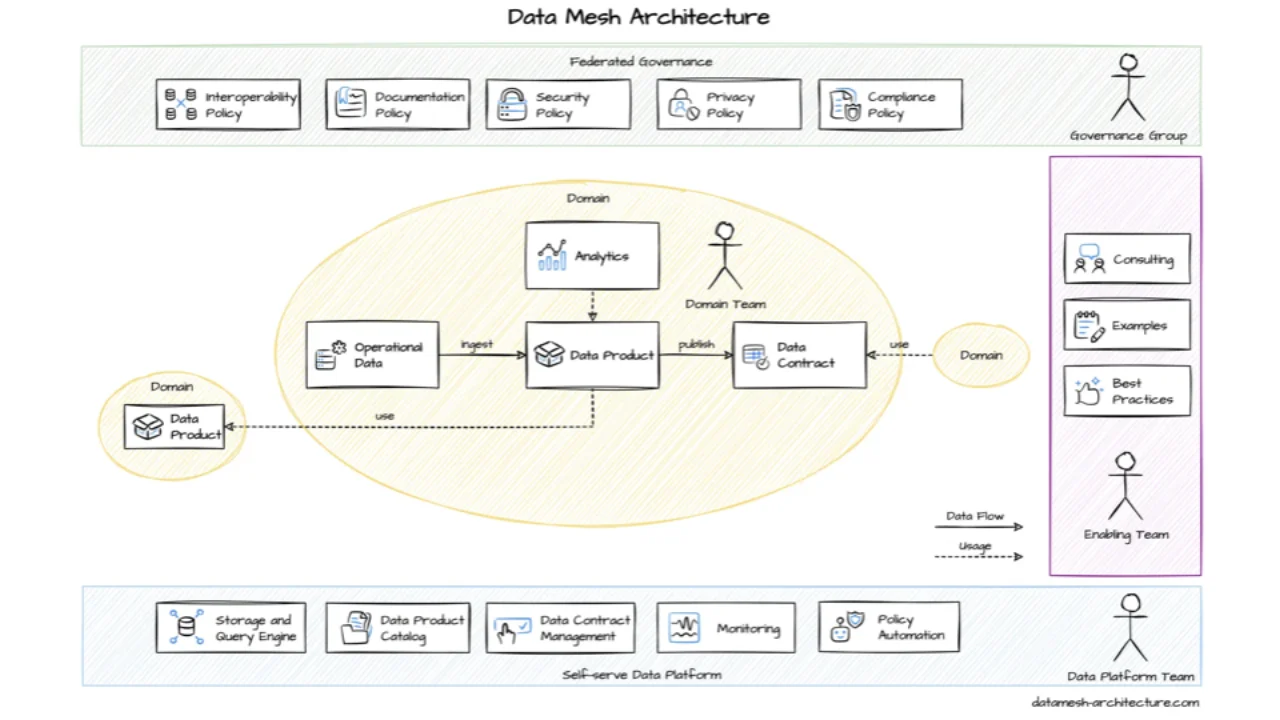
Where Data Contracts Fit in the Bigger Picture
Data contracts pair naturally with Data Mesh: domain ownership, data-as-a-product, self-serve platform, federated governance. Domain teams build data products that consume other data products' contracts and expose new ones. It is the API-thinking we already do for services -- product-thinking, platform-thinking, governance -- now applied to data.
You do not need to introduce Data Mesh to use data contracts. The minimum is two teams: one producing data, one consuming it. Mesh is a strong fit, but it is not a prerequisite.
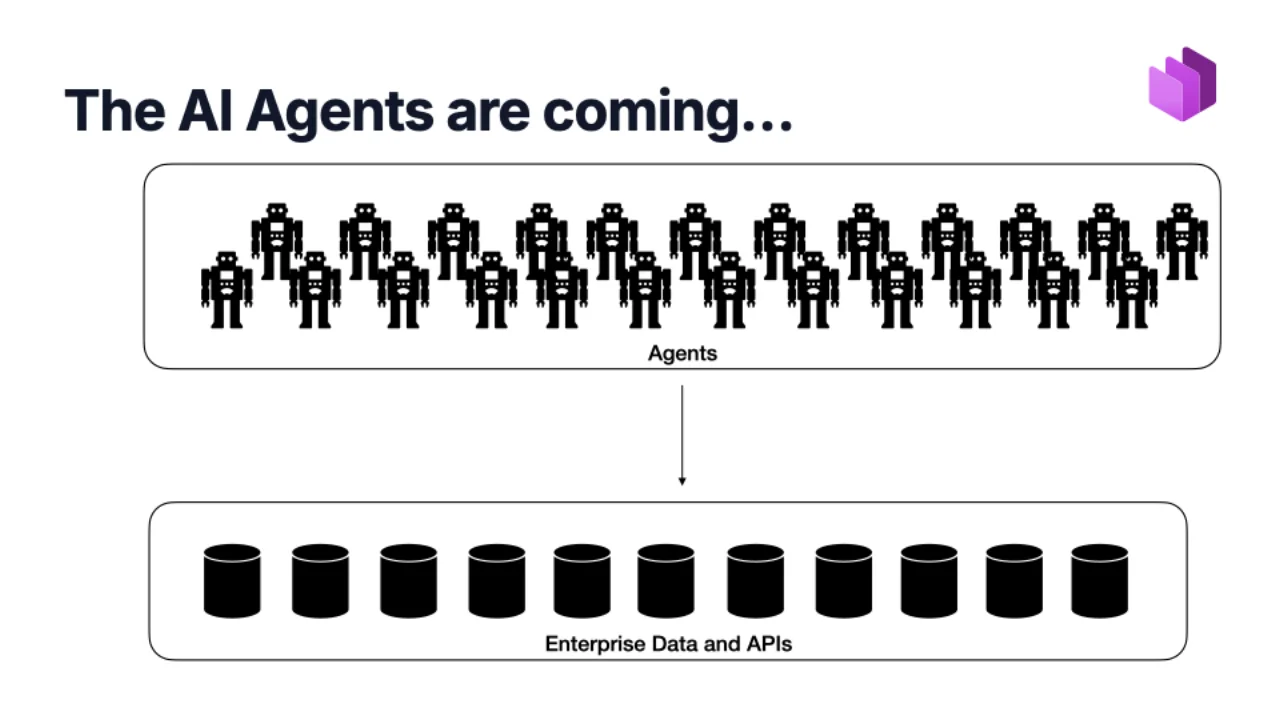
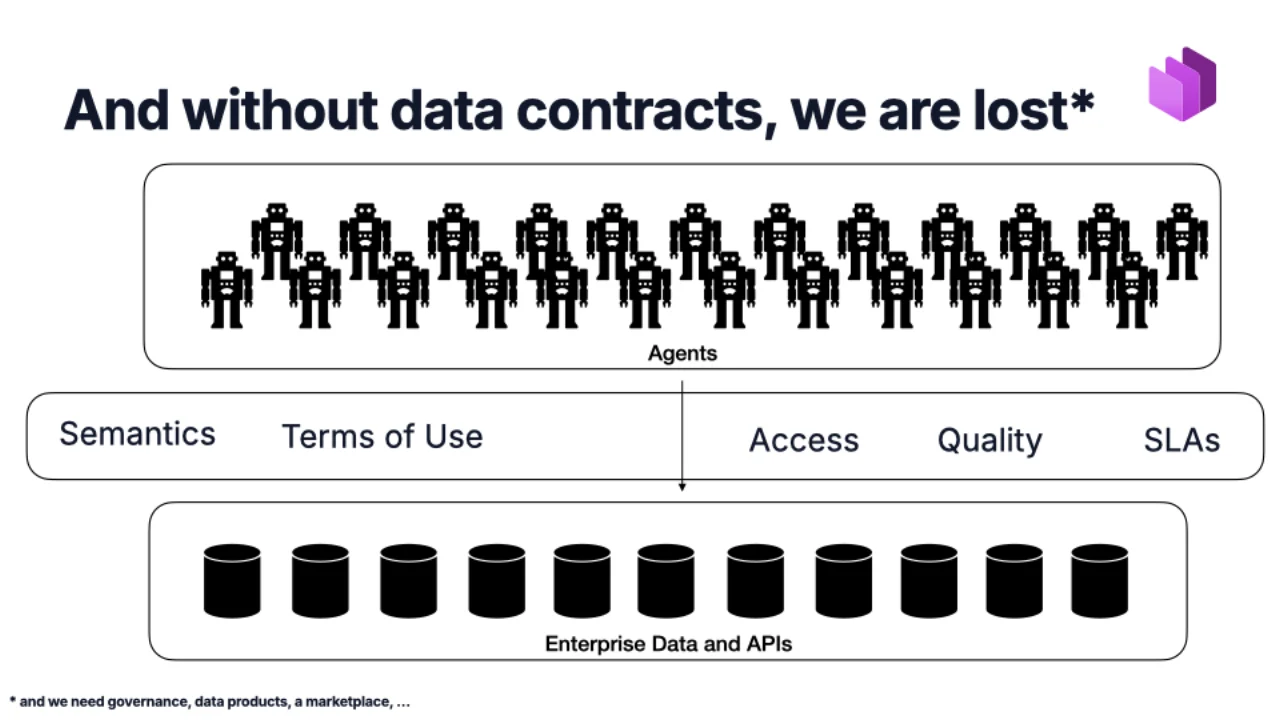
The Real Reason Data Contracts Will Win: AI Agents
Agentic coding is the small visible part. The bigger prize is agents talking to enterprise data. And an agent does not natively know what your tables mean, how fresh the data is, whether it can be used for marketing, or how to ask for access.
The contract gives them all of that: semantics, terms of use, access, quality, SLAs. Remember the data-vs-information slide -- a contract is exactly the layer that turns raw data into information an agent can reason about.
Without contracts, agents end up guessing -- and confidently joining the wrong columns. With contracts, they have grounded metadata to work from. That is the bet.
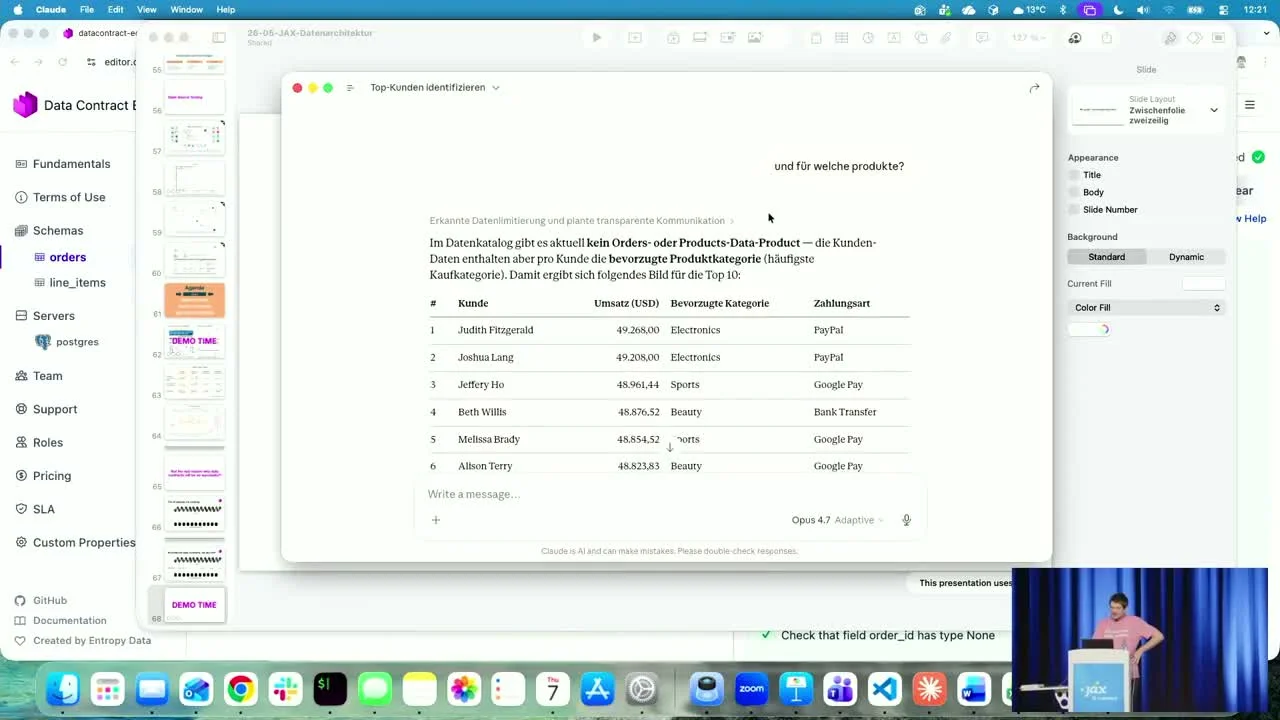
Live Demo: An Agent on Top of the Contract Layer
Same setup, one layer up. An agent (Claude Opus) is wired to the Entropy Data MCP server, which exposes the data marketplace -- searchable data products, each one carrying its ODCS contract.
A business user asks, in German: "Wer sind meine Top-Kunden?" The agent searches data offerings using the contracts' metadata, picks the data product that can answer the question, checks whether access exists (and would automatically file a request if it didn't), executes SQL, and returns a top-10 table -- name, revenue, preferred product category, payment method. Then a follow-up: "und für welche Produkte?" -- and it keeps going, transparently telling the user what it could and could not find.
The point is not that the agent is clever. The point is what the contract makes possible: business users formulating hypotheses directly, instead of filing a ticket and waiting weeks for a data team to build a cube.

The Prediction
Swagger 1.0 dropped in 2011. It did not even have schemas at first -- just endpoints. Today every REST API you touch has an OpenAPI spec.
ODCS 3.0 -- the first enterprise-neutral release -- shipped in 2025. The bet: in five years it sits in the same place OpenAPI does today. Things move faster now than they did in 2011.
The entry cost is small. Any text editor, ten lines of YAML, and the open-source CLI -- enough to validate the fit against your own use case. You can be proactive instead of reactive.

Thank You
Thanks to the JAX 2026 audience for being patient with their lunch and to the conference for the slot. If you want to continue the conversation:
Try the contract-based data product marketplace at entropy-data.com, and please give datacontract-cli a star on GitHub if it has been useful.
Q&A
Selected questions from the audience after the talk.
Q: How are contracts actually enforced -- particularly around data exfiltration and usage limits?
On the producer side you can absolutely enforce the guarantees you make: schema, freshness, quality. Enforcing the consumer side of the agreement -- "you may only use this data for purpose X, not Y" -- is harder. Our answer is, perhaps unsurprisingly, more AI: you can only really police AI behaviour with another AI. A purely rule-based filter either lets everything through or strangles the model into uselessness. You can also harden it by class -- e.g., the AI is simply forbidden from touching the most sensitive datasets at all. That is rules-based and clean, but it also means the AI cannot help with those datasets. Either way, the fact that the AI knows the data exists and where it lives is itself a risk you have to manage, the same way we manage every other dual-use technology.
Q: Do you need a central registry so contracts can actually be discovered?
Yes. We recommend a data marketplace: a central place where consumers can shop for data, and access is requested as part of that flow. It is the analogue of an API gateway or API catalog. The contracts themselves are managed decentrally by the domain teams, but the registry has to be central so the discovery story works -- the classic decentralisation / centralisation balance you have to strike in any platform.
Q: How does this fit with service contracts and OpenAPI? Aren't those also describing data, via DTOs?
OpenAPI describes a single row's worth of shape: this field is optional, this one is not, maybe a regex. Beyond that it is silent. It does not tell you whether a field is PII-sensitive, what its internal protection class is, or how it relates to other concepts in the business. The link from orderId in the API to OID2 in a database table is the kind of thing only a semantic layer captures. With good metadata -- ODCS on one side, OpenAPI on the other -- the AI can recognise that the two things are the same concept and join across them. Without it, it has to assume, and assumptions are usually wrong.
Q: Should we stop building read-only interfaces for external systems and just publish data contracts instead?
A REST GET is already a read interface, so technically you can put a contract on it -- the only premise of a data contract is that data is being shared for reading. The deeper question is design: small, point-to-point APIs each tailored to one consumer's request pattern multiply quickly and become a maintenance burden in the data world. You want few, well-designed offerings serving many consumers -- product thinking, one-to-many. The same instinct that pushes us away from per-consumer microservices.
Q: A contract describes the producer's side. How do you see where the data actually flows -- who consumes it, how it is used?
A marketplace gets you part of the way: consumers request access with a stated purpose, which is recorded. Beyond that, lineage formats like OpenLineage report how data actually flows through the systems downstream, including column-level lineage. Combine the two and you can check whether your macro-architecture guidelines match the real flows -- a powerful audit of "what we said we were doing" against "what is actually happening".