Talk
Chat with your Enterprise Data
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · 22. Januar 2026
In diesem Gastvortrag an der Purdue University zeige ich, wie KI jede Business-Frage beantworten und dabei Data-Governance-Policies durchsetzen kann. Beginnend mit einer Live-Demo, in der Claude Datenprodukte entdeckt, mit einem klaren Zweck Zugriff anfragt und Databricks über einen MCP-Server abfragt, erkläre ich, warum es funktioniert: gute Metadaten in Form von Datenprodukten, Data Contracts, Semantik und Access Agreements — und wie uns KI endlich einen Grund gibt, in diese Metadaten zu investieren.
Aufgezeichnet als Gastvorlesung für die Purdue University. Das Transkript unten ist eine redigierte Fassung des Talks.
Danke an das Team der Purdue University für die Einladung und an unsere Co-Autoren am King’s College London und der Jheronimus Academy of Data Science (JADS) für die Forschung, auf der dieser Talk aufbaut.

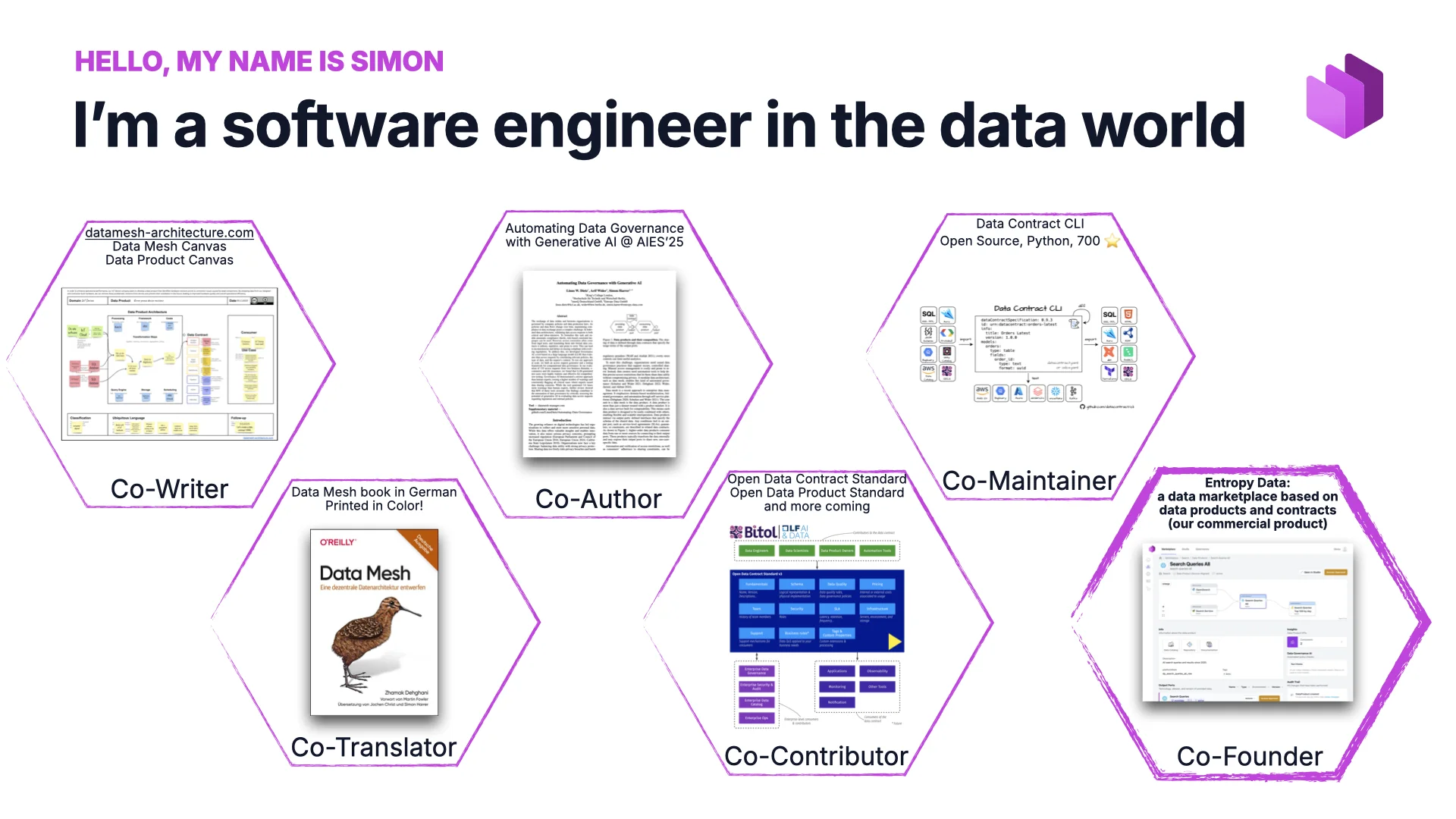
Hallo, mein Name ist Simon
Ich freue mich, heute zu sprechen — ich melde mich aus Deutschland, für mich ist es also fast schon später Nachmittag. Von der Ausbildung her bin ich Software Engineer. Ich habe viel mit Java gearbeitet, habe „Java by Comparison“ über das Schreiben wartbaren Codes mitverfasst und drei Jahre in einem Remote-Mob-Programming-Team verbracht — vier oder fünf Leute den ganzen Tag in einem Zoom-Call, ein Screen geteilt, alle zehn Minuten wechselt der Driver, immer gemeinsam an einer Sache. Außerdem habe ich viel Infrastrukturarbeit mit Kubernetes und dem GitOps-Ansatz gemacht.
Dann passierte etwas, das ich nie erwartet hätte: Ich wechselte die Seiten. Ich wechselte auf die dunkle Seite — die Welt der Daten. Vor ungefähr fünf Jahren. Ehrlich gesagt gab es zu dem Zeitpunkt für mich in der Software-Engineering-Welt nicht mehr viel Innovation; die Datenwelt dagegen platzte vor Innovation, getrieben vom Aufstieg von Data Mesh, dem von Zhamak Dehghani geprägten Konzept. Mit meinem Co-Autor bauten wir datamesh-architecture.com als Referenz, und gemeinsam übersetzten wir das O’Reilly-Data-Mesh-Buch ins Deutsche — das Schöne ist, dass die deutsche Version in Farbe gedruckt ist. Dafür haben wir gekämpft. Ihr Amerikaner seid beim Farbdruck ehrlich gesagt etwas knausriger.
Wegen meiner Promotion in verteilten Systemen habe ich die Wissenschaft nie ganz verlassen und publiziere bis heute Forschung gemeinsam mit Leuten vom King’s College London und der HTW Berlin. Ich bin im Technical Steering Committee des BITOL-Projekts der Linux Foundation, das offene Standards rund um Data Contracts und Datenprodukte vorantreibt — ihr hattet vor einer Weile hier an der Purdue einen Talk von Sean Perin, dem TSC-Präsidenten. Ich pflege mit an Open-Source-Tooling rund um diese Standards. Und last but not least bin ich Co-Founder von Entropy Data, einem SaaS-Datenmarktplatz für Datenprodukte. Wir sind ein kleines Startup — bereits profitabel, ohne VC, bootstrapped und schnell wachsend. Das ist meine Persona.

Das White Paper
Heute möchte ich darüber sprechen, mit deinen Unternehmensdaten zu chatten. Wir haben ein White Paper auf arXiv geschrieben — arxiv.org/pdf/2601.08687 — gemeinsam mit Leuten vom King’s College London und der Jheronimus Academy of Data Science (JADS) in den Niederlanden. Dort findest du viel mehr Details; alles, was ich hier zeige, ist auch von entropy-data.com/de/forschung aus verlinkt.

Das Ziel, in einem Satz
Die Kernidee ist einfach: Wir wollen KI in die Lage versetzen, jede Business-Frage zu beantworten und dabei Data-Governance-Policies durchzusetzen.
Überleg mal, was das bedeutet. Du gibst der KI eine Frage — oder ein KI-Agent kommt autonom selbst auf eine — und nach kurzer Zeit hast du einfach die Antwort. Während Governance durchgesetzt wird, denn Daten können sehr sensibel sein: Du darfst nicht alles mit jedem Datensatz tun. Das ist es, was ich heute teilen möchte.
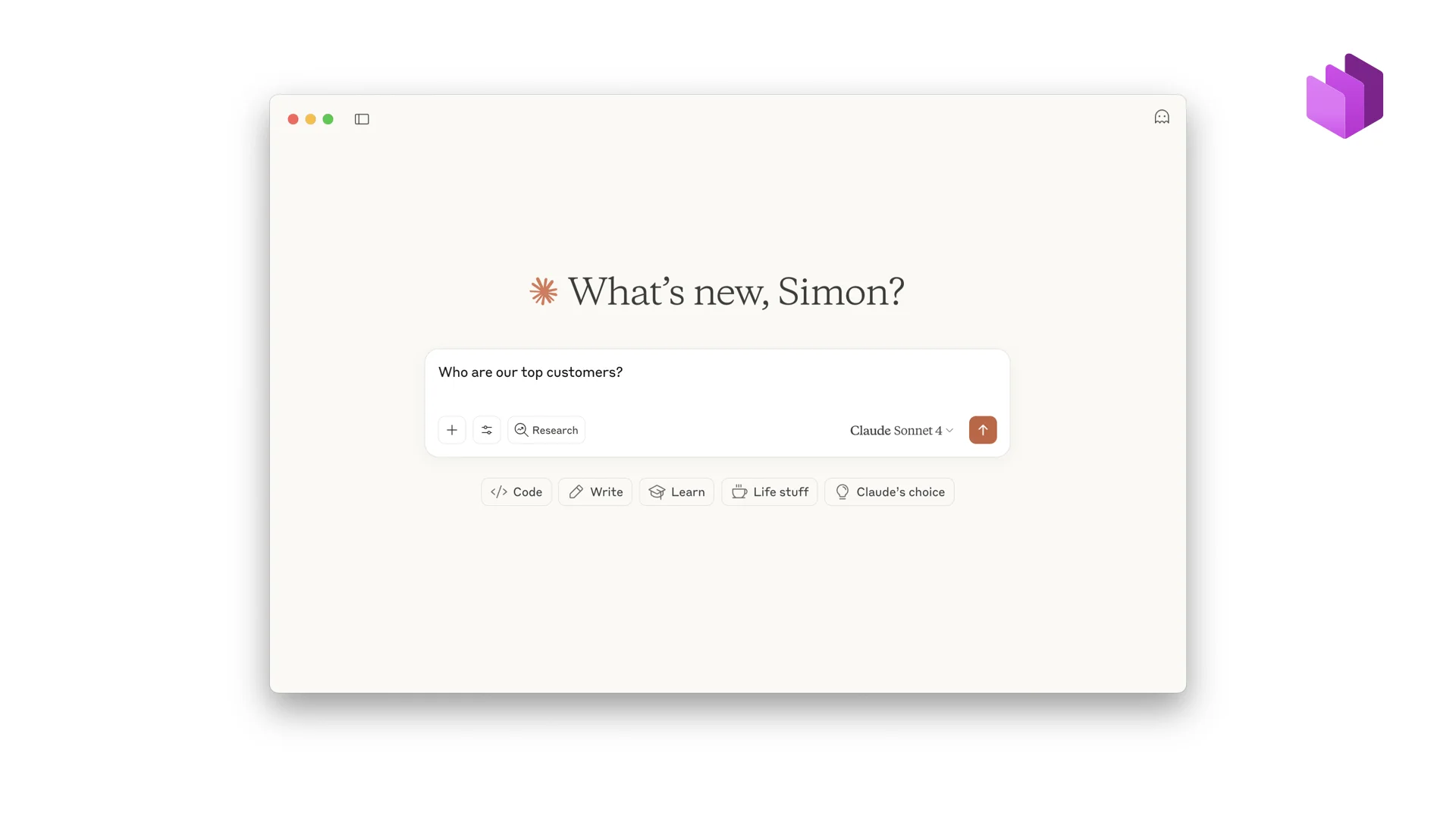
Live-Demo: Von der Frage zur Antwort
Lass mich dich mit einer Demo ein bisschen begeistern. Im Hintergrund haben wir ein System, das alles verwaltet — einen Datenmarktplatz für Datenprodukte. Ich nutze Claude, das über einen MCP-Connector mit dem System verbunden ist. Wenn alles eingerichtet ist, kann ich einfach eine Business-Frage stellen. Versuchen wir: „What are our top customers?“
Claude greift das als Trigger auf und sucht automatisch nach relevanten Daten. Es führt eine Suche nach „customers“ aus und findet ein Datenprodukt. Das sind sehr grobe Metadaten. Als Nächstes macht es also einen Fetch, um die vollständigen Details zu bekommen — Struktur, Semantik, Qualität und ob wir Zugriff haben. Es liest all das, entscheidet, dass das Datenprodukt gut passt, bemerkt aber, dass wir keinen Zugriff haben. Also fragt es automatisch Zugriff an und leitet aus meiner Frage einen konkreten Zweck ab.
Es bekommt zurück „zur Freigabe eingereicht, noch nicht freigegeben“. Die KI ist ein bisschen frech: Sie versucht trotzdem, eine SQL-Query auszuführen — mit einem angehängten Zweck, sodass wir wissen, warum jede Query läuft — aber die Anfrage steht noch aus, also schlägt die Query fehl. In einem zweiten Fenster gebe ich als Owner die Zugriffsanfrage frei. Claude versucht es erneut, wartet ein paar Sekunden, bis der serverlose Databricks-Cluster hochgefahren ist, und dann kommen die Ergebnisse zurück.
Von „What are our top customers?“ zu einer governeden Antwort. Jeder Schritt nachverfolgt. Jede Query trägt ein „Warum“. Das ist Chatten mit deinen Unternehmensdaten.
„Dieser Workflow wird heute von mir als Mensch ausgelöst, aber es könnte genauso gut ein autonomer Agent sein. Es gibt keinen Unterschied. Und viele dieser Agenten kommen.“
Ein zweites Beispiel: „What are the top reasons for support tickets?“ Gleicher Ablauf — aber Support-Tickets sind weniger sensibel, also wird der Zugriff automatisch freigegeben. Suchen, Fetch, anfragen, abfragen, antworten — null menschliche Interaktion in der Schleife.
Und ein letztes: „Export a CSV with customer email addresses for a luxury email campaign, only high-loyalty customers.“ Diesmal greift Governance. Die Nutzungsbedingungen des Datenprodukts verbieten den Einsatz für Marketing. Die KI verweigert. Bei einem älteren Modell konnte ich es manchmal überreden, das zu ignorieren — also haben wir einen zweiten Türsteher im MCP-Server selbst eingebaut. Selbst wenn du die KI überzeugst, stoppt der Server die Query im Flug. Governance-Grenzen erstrecken sich auf die Agenten, und das ist wichtig, denn Agenten können für einen Zweck Zugriff anfragen und dann versuchen, die Daten für einen anderen zu nutzen. Das ist nicht erlaubt.

Die Use Cases im Rückblick
Zurück zu den Slides. Was haben wir gesehen? Governeden, auditierten Zugriff auf Daten durch KI.
- Wir finden das richtige Datenprodukt für eine gegebene Business-Frage.
- Wir fragen Zugriff mit einem konkreten Zweck an.
- Wir fragen die Daten auf die richtige Weise ab.
- Wir auditieren das Warum jeder SQL-Query.
- Wir blockieren SQL-Queries, wenn der Zweck nicht von Governance abgedeckt ist.
Und das alles automatisch. Dieses letzte Wort ist das entscheidende: Wenn die Agenten kommen und du das nicht automatisiert hast, wirst du nicht mithalten können.
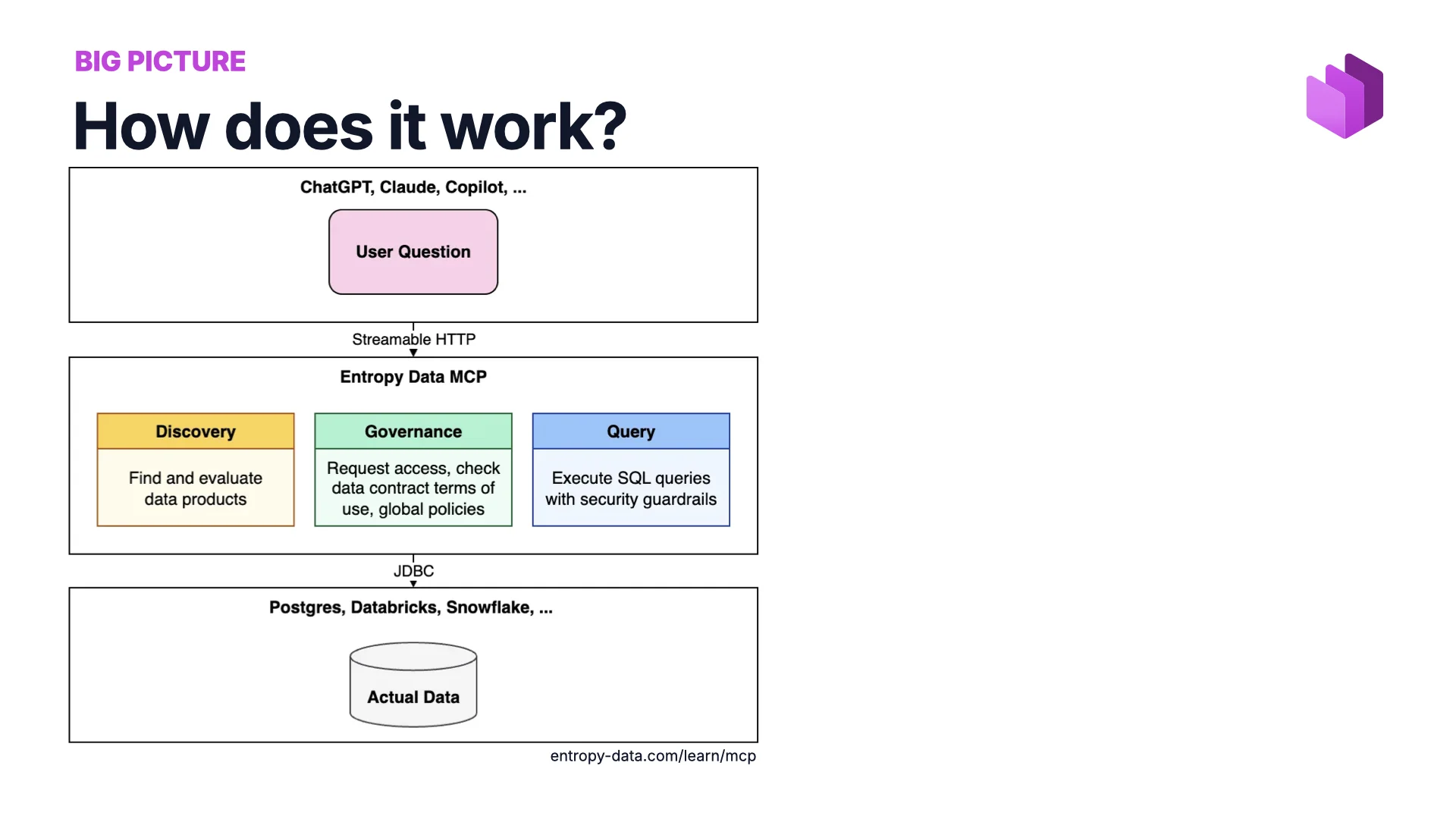
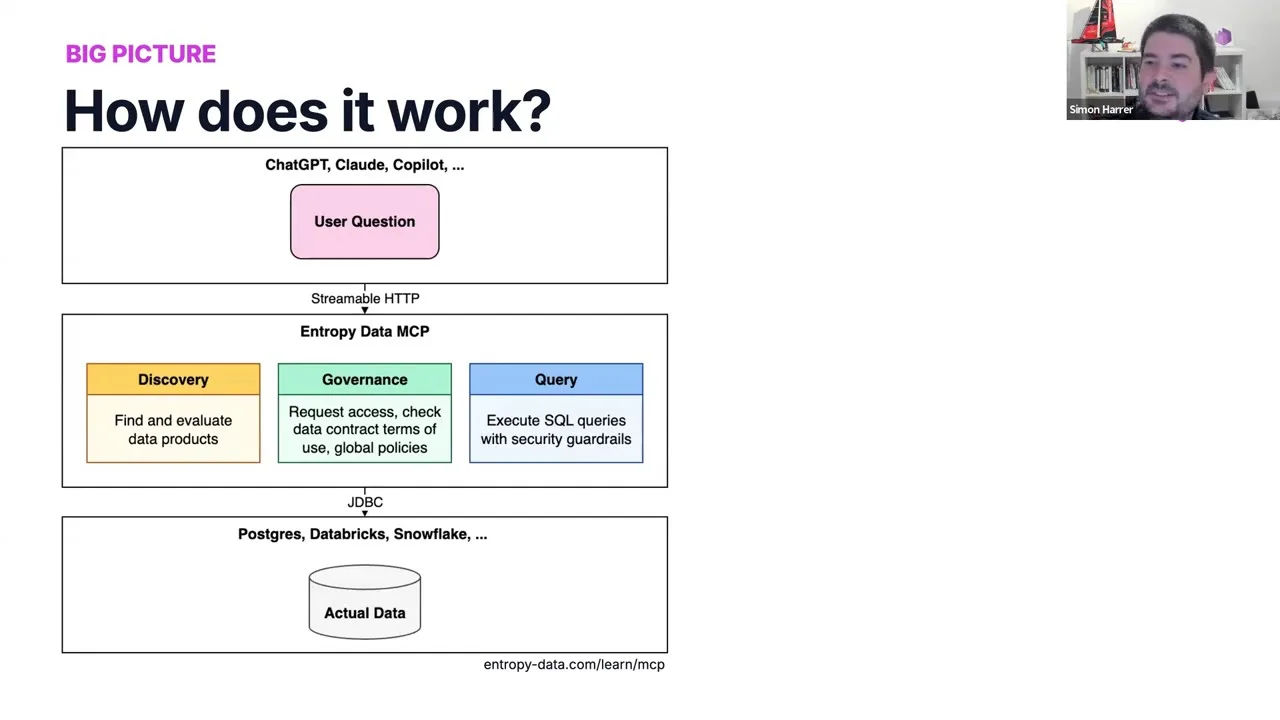
Das große Ganze
Die Architektur ist einfach. Die agentische Welt oben (ChatGPT, Claude, Copilot). Die eigentlichen Daten unten (Postgres, Databricks, Snowflake). Und in der Mitte ein MCP-Server, der als dünne Governance-Schicht mit drei Aufgaben agiert:
- Discovery — Datenprodukte finden und bewerten.
- Governance — Zugriff anfragen, Nutzungsbedingungen des Data Contracts prüfen, globale Policies durchsetzen.
- Query — SQL mit vorgelagerten Security-Guardrails ausführen.
Technisch ist es heute nicht schwer, das zu bauen — Claude Code schreibt das meiste davon für dich. Die spannende Frage ist, warum es so gut funktioniert.


Zwei Gründe, warum es funktioniert
Der erste Grund ist der naheliegende: KI-Agenten werden immer besser. Du hast die Magie gesehen — Claude hat im Hintergrund seine Schritte geplant, sie der Reihe nach ausgeführt, sich von Fehlern erholt, und ich musste ihm nichts davon sagen.
Aber die eigentliche Antwort sind gute Metadaten. Ohne sie wäre meine Demo sehr schlecht gewesen. Lass mich die Erfolgsfaktoren durchgehen — die Arten von Metadaten, die das tatsächlich zum Funktionieren bringen.
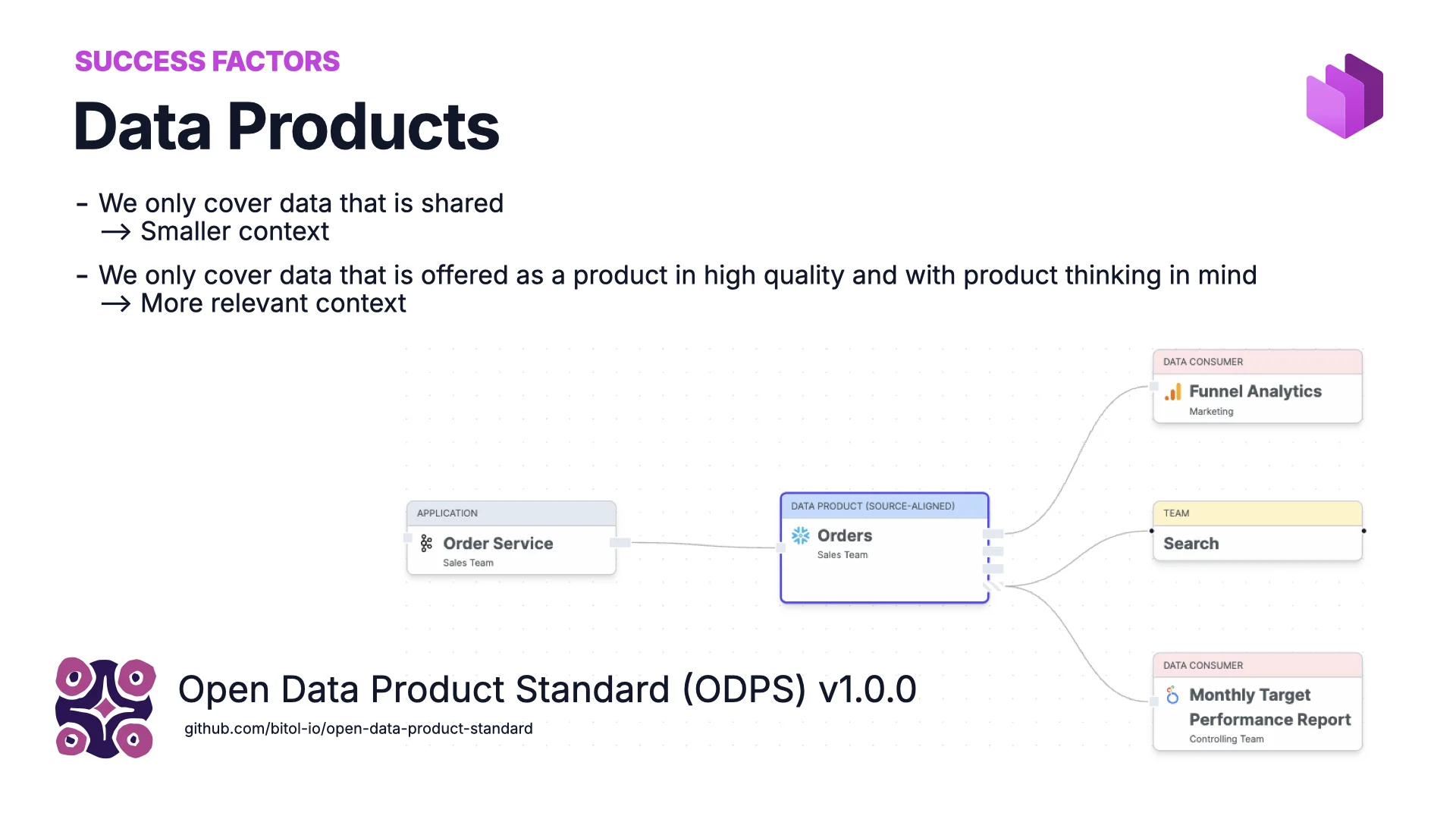
Erfolgsfaktor #1: Datenprodukte
Der Marktplatz im Hintergrund hat Daten in Form von Datenprodukten angeboten. Die Idee: Du kippst nicht jede Tabelle deines Unternehmens in den Marktplatz — nur die Daten, die jemand besitzt und als Produkt teilen möchte.
Das bewirkt zwei Dinge. Es verkleinert den Kontext — und je kleiner der Kontext, desto besser für KI. Und es hebt Qualität und Ownership: Mit Produktdenken baust du für einen Consumer, egal ob dieser Consumer ein Mensch oder ein Agent ist. Als Format nutzen wir den offenen Open Data Product Standard (ODPS) v1.0.0, der den Metadaten eine vorhersehbare Struktur gibt.
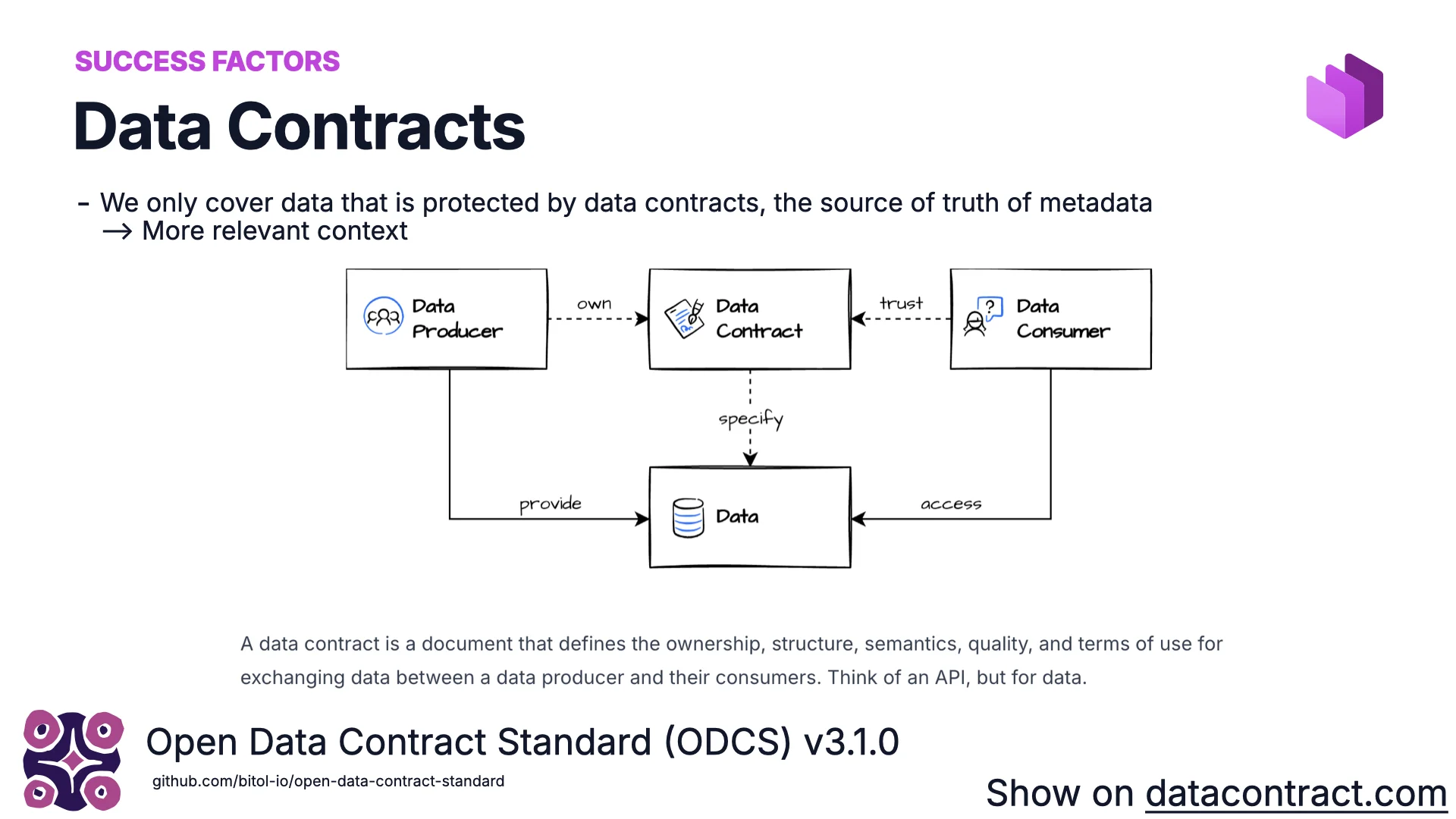
Erfolgsfaktor #2: Data Contracts
Ein Data Contract definiert Ownership, Struktur, Semantik, Qualität und Nutzungsbedingungen für Daten, die zwischen einem Producer und seinen Consumers fließen. Stell dir eine OpenAPI-Spezifikation vor — aber für Daten. Er ist für Menschen lesbar, perfekt für Tooling und ideal für KI: Es sind die besten Metadaten, die du an einen Datensatz hängen kannst, weil man ihnen als Source of Truth vertrauen kann.
Auf datacontract.com siehst du, wie das in der Praxis aussieht. Ein Contract ist typischerweise eine YAML-Datei mit Grundlagen (id, name, version, status), einem Schema (Tabellen, Spalten, logische und physische Typen, Klassifikationen wie PII), Datenqualität (z. B. order_status ∈ {pending, shipped, cancelled}, oder beliebiges SQL — mal absolut, mal prozentual, weil die Datenwelt chaotisch ist), Ownership und Slack-Channels, Nutzungsbedingungen (was du darfst und was nicht — z. B. nicht für Marketing), SLAs (Retention, Aktualität — nie älter als 24 Stunden) und schließlich dem Server (Postgres, Databricks, Snowflake, S3, Iceberg… wo auch immer die Daten tatsächlich liegen).
Der Standard hier ist ODCS v3.1.0. Der Open-Source-Editor lässt dich Contracts über ein Formular, ein Diagramm oder rohes YAML verfassen. Die Data Contract CLI — ~800 GitHub-Stars — liest einen Contract, verbindet sich mit der echten Datenquelle und verifiziert, dass jede Garantie hält. Diese automatische Verifizierung macht den Contract vertrauenswürdig genug, um ihn in den Discovery-Schritt der KI einzuspeisen.
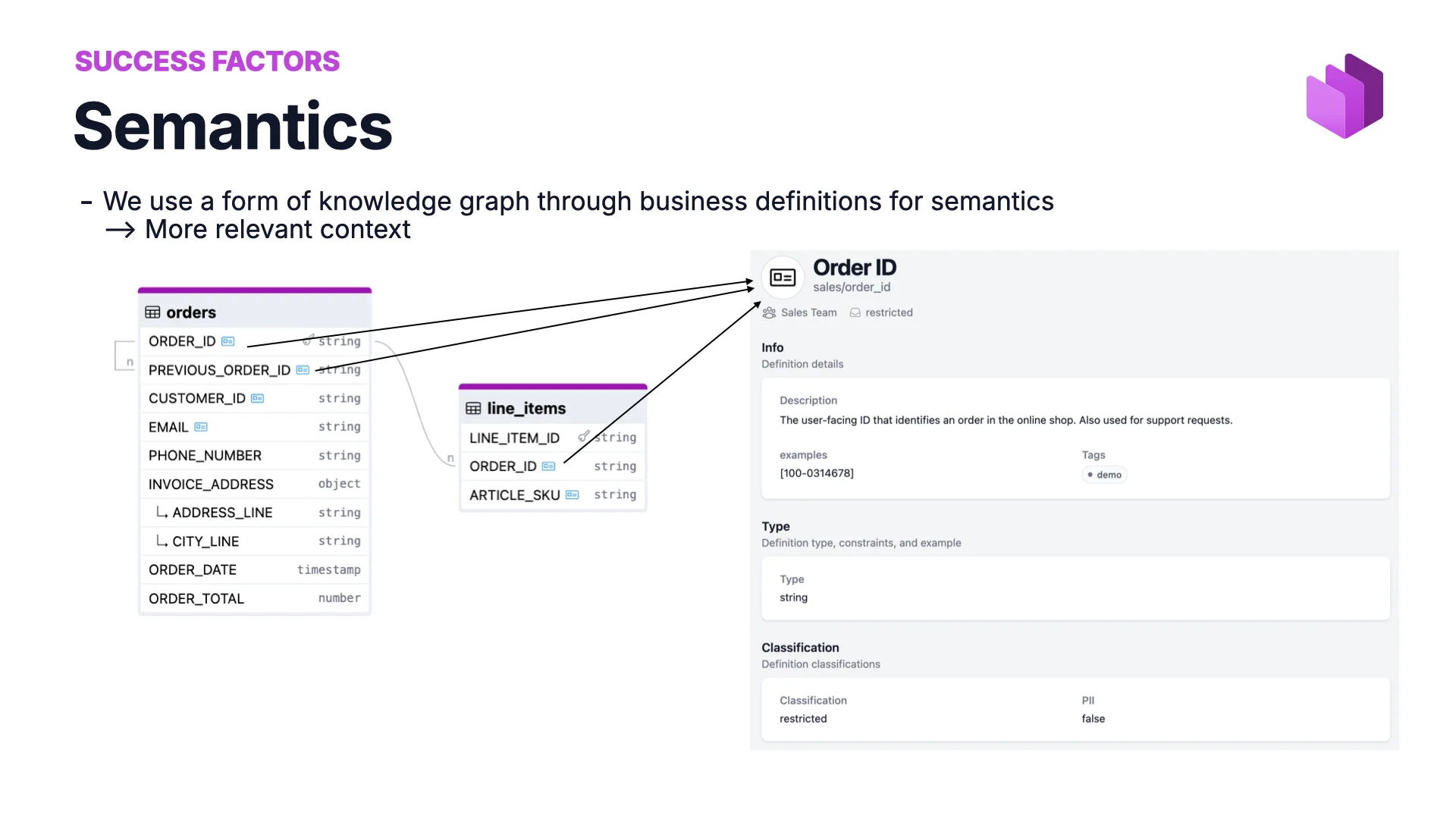
Erfolgsfaktor #3: Semantik
Um Joins über Tabellen hinweg zu machen, muss die KI wissen, ob zwei Spalten gejoint werden können — ob order_id in einer Tabelle wirklich dasselbe bedeutet wie order_id in einer anderen. Besonders, wenn sich Joins über mehrere Datenprodukte ketten.
Dafür definieren wir Semantik — ein Business-Glossar oder einen Knowledge Graph. Order ID wird einmal in der Sales-Fachlichkeit definiert, und Data Contracts verweisen auf diese gemeinsame Definition. Dasselbe Konzept, derselbe Verweis, dieselbe Wahrheit überall. Mit vorhandener Semantik schreibt KI die richtigen SQL-Joins, ohne raten zu müssen.

Erfolgsfaktor #4: Access Agreements
In der Demo hat die KI für mich Zugriff angefragt. Unter der Haube hat sie ein Formular ausgefüllt, aber der Kern ist, dass wir im Backend immer wissen:
- Wer Zugriff auf welche Daten hat und warum.
- Was die Terms and Conditions dieses Zugriffs sind — was erlaubt ist und was nicht.
Das ist es, was Governance-Checks real macht — und was uns überhaupt erlaubt, ein solches System zu bauen.
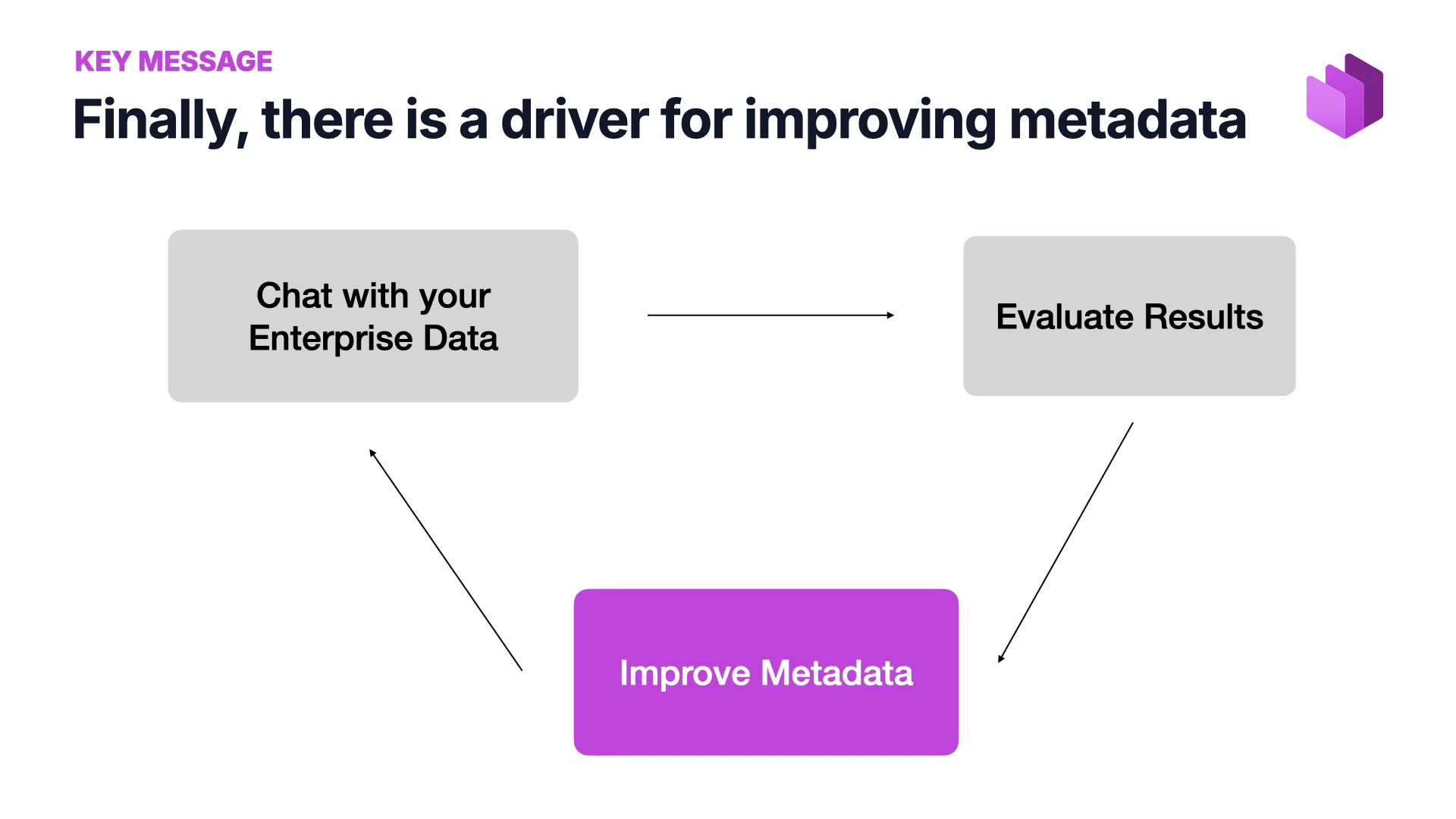
Endlich ein Treiber für bessere Metadaten
Vor KI hätte ich dem Advocatus Diaboli zugestimmt. Irgendjemanden dazu zu bringen, Zeit in Metadaten zu investieren, war schwer — die Governance-Leute tauchten auf und baten darum, und die Anfrage blieb für immer ganz unten im Backlog liegen. Jetzt gibt es einen Feedback-Loop, den es vorher nicht gab:
Mit deinen Unternehmensdaten chatten → die Ergebnisse bewerten → wenn sie nicht das sind, was du wolltest, die Metadaten verbessern → erneut chatten → bessere Ergebnisse.
„Menschen sind egoistisch — sie investieren keine Zeit, um anderen zu helfen oder eine Policy um der Policy willen zu erfüllen. Aber wenn sie den Nutzen selbst haben, verbessern sie die Metadaten.“
Das ist der Unterschied. Jeder, der diese Demo sieht, sagt: „Genau das will ich.“ Und der einzige Weg dahin sind bessere Metadaten. Also investieren sie.

Ja, KI ist für uns da
Drei Stellen, an denen KI heute schon bei Metadaten hilft:
- Metadaten-Erstellung — Contracts und Produktdefinitionen verfassen und aktualisieren.
- Metadaten-Monitoring — prüfen, ob die Metadaten zu deinen Policies passen.
- Zugriffsfreigabe — der eine Schritt, der in der Demo noch manuell war.
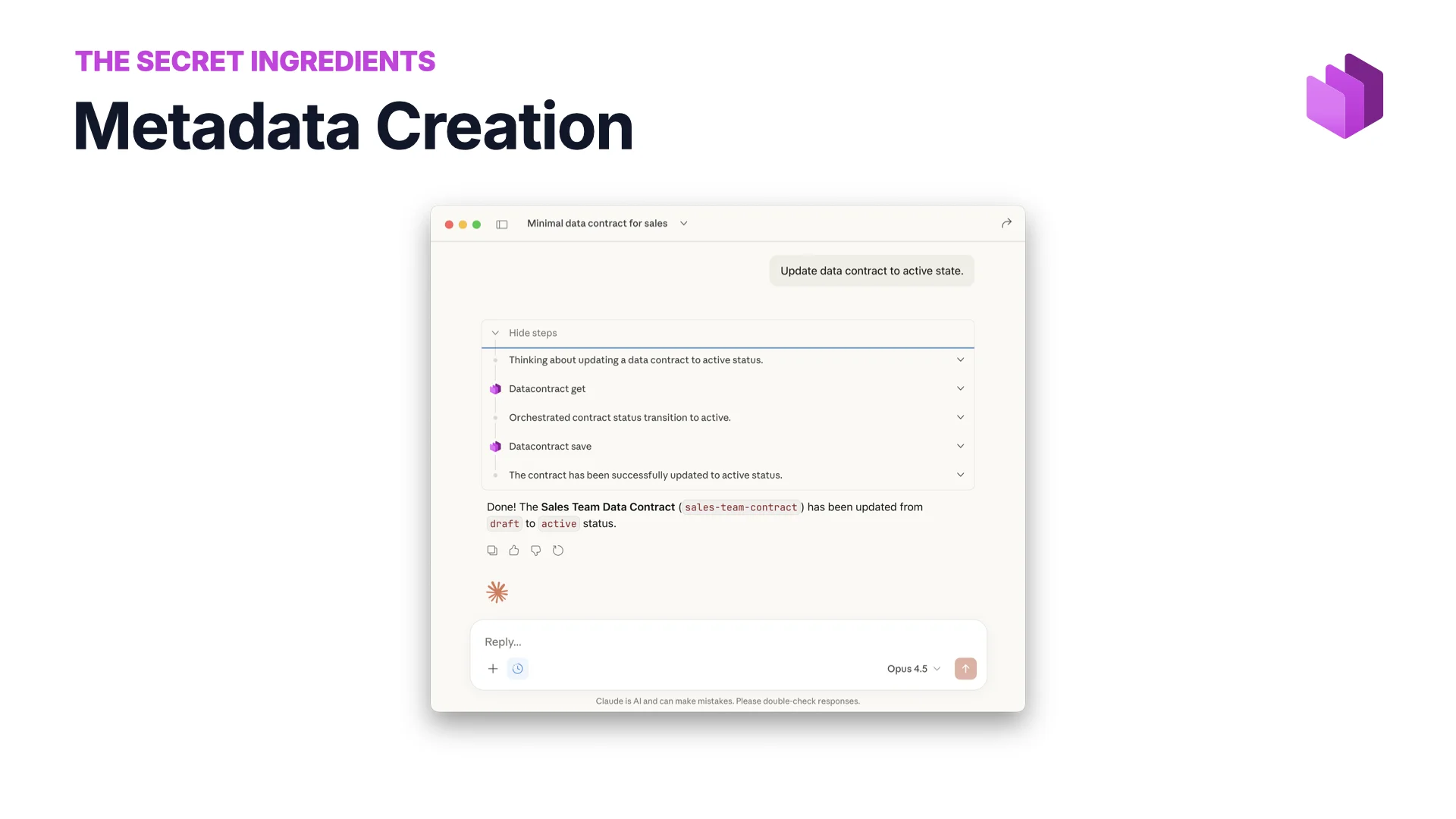
Metadaten-Erstellung
Du musst Metadaten nicht mehr von Hand eintippen. Bitte KI, einen Data Contract zu aktualisieren, ihn von Draft auf Active zu heben, die fehlenden Klassifikationen auszufüllen. Gib ihr zusätzlichen Kontext — dein Confluence, die echten Daten, ein anderes System of Record — und sie produziert viel bessere Metadaten, als sie es aus dem YAML allein könnte.

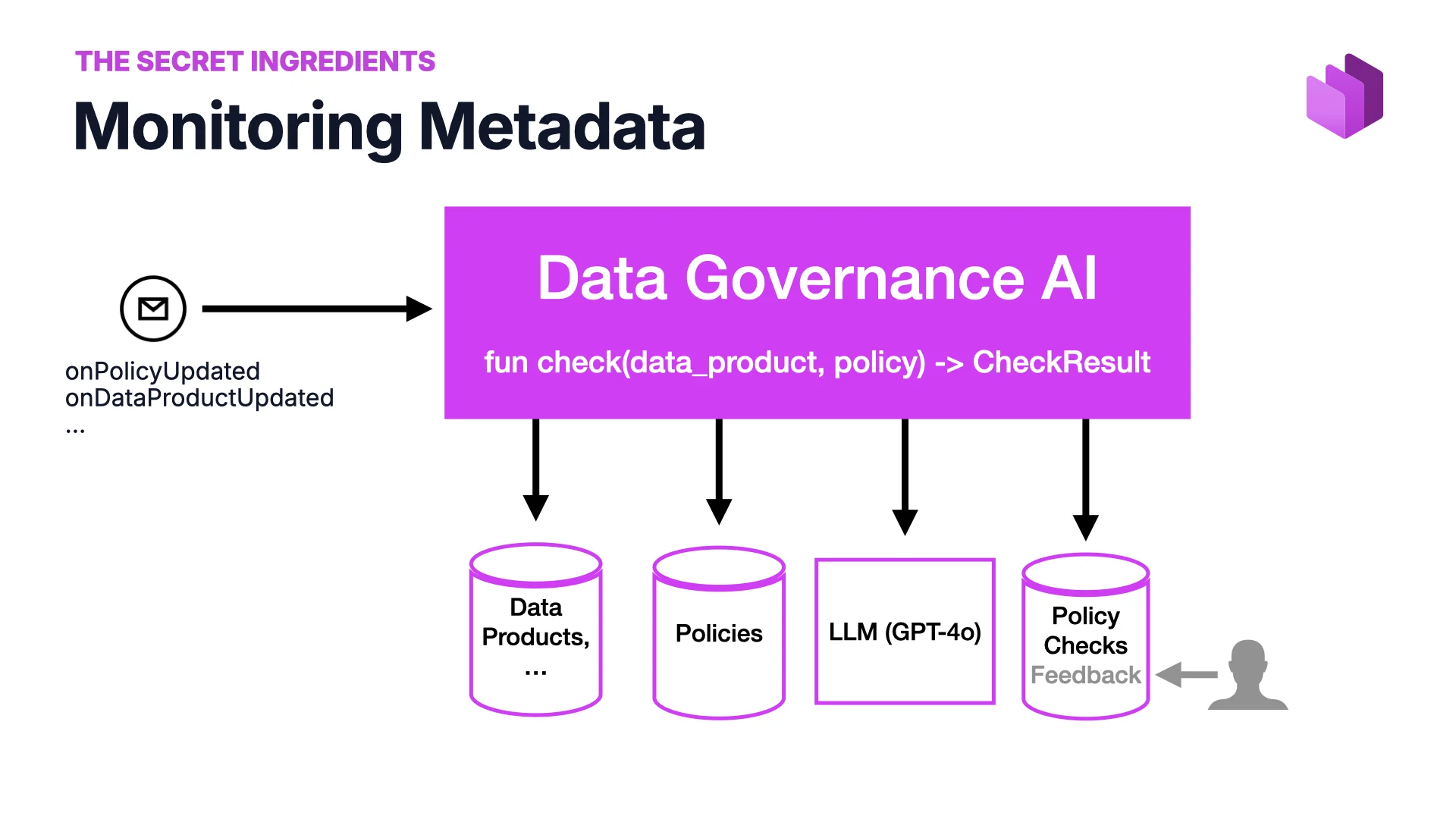

Metadaten-Monitoring
Du willst nicht, dass deine Metadaten verfallen, denn in dem Moment, in dem sie das tun, verfallen auch deine KI-Ergebnisse. Also überwachst du sie gegen Regeln: Was ist ein gutes Datenprodukt? Was ist ein guter Data Contract? Was erlauben wir?
Die Erkenntnis ist, dass du diese Regeln jetzt in natürlicher Sprache ausdrücken kannst. Governance-KI nimmt ein Datenprodukt plus eine Policy und liefert ein Check-Ergebnis. Der Input sind Policies und Datenprodukte, das Modell ist ein LLM, der Output ist eine Reihe von Policy-Checks mit Feedback, das User markieren können. Wir haben einen Prototyp gebaut, und er funktioniert gut.
Der eigentliche Gewinn: Nicht-Experten können jetzt definieren, wie „gut“ aussieht. Governance-Leute ohne Programmierhintergrund können Regeln schreiben, das System überwachen und iterieren. Ja, Halluzinationen sind nach wie vor ein Problem — User können False Positives markieren, aber für False Negatives gibt es noch keine gute Antwort. Ehrlicher Trade-off, mächtiges Muster.
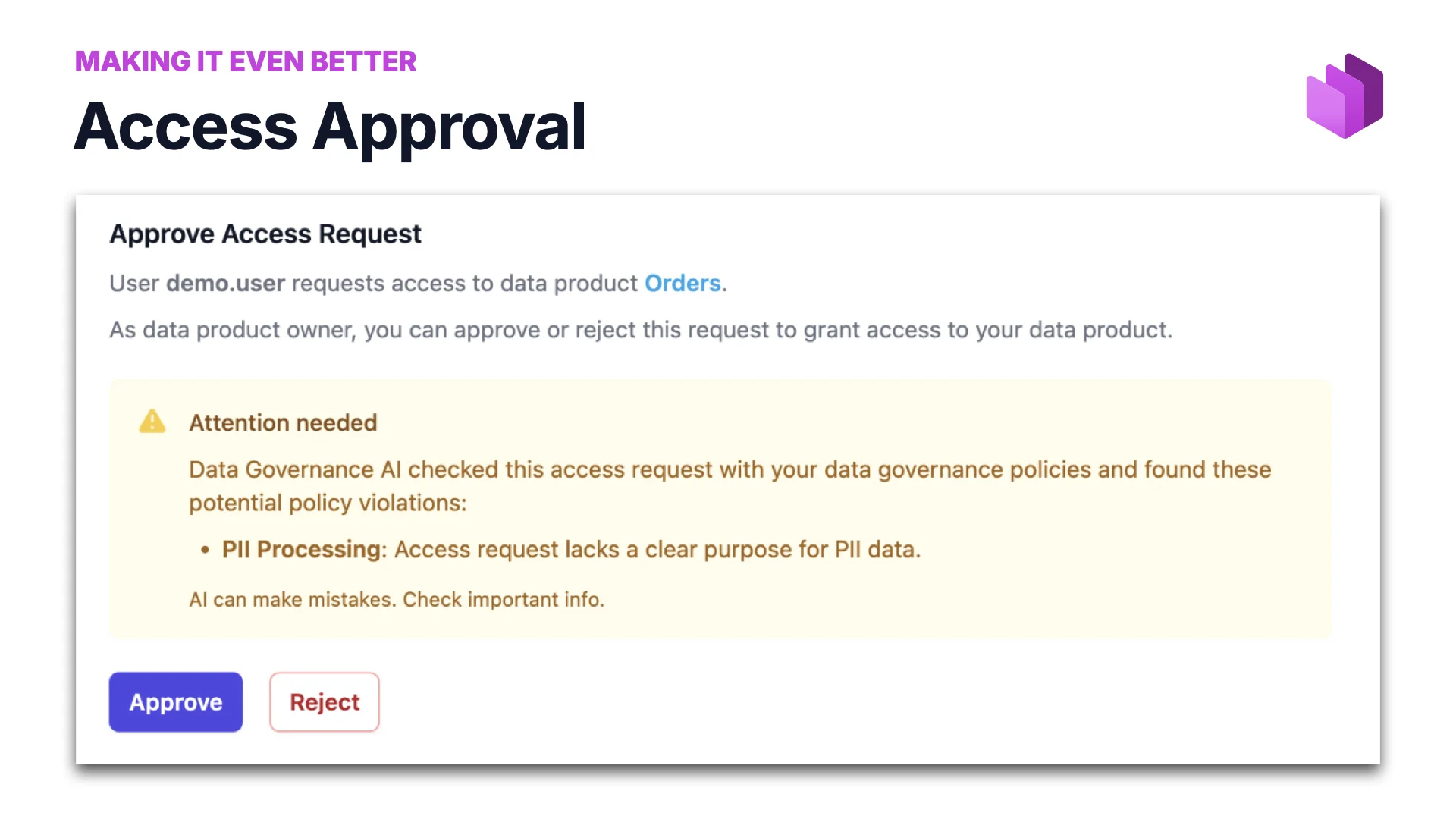
Zugriffsfreigabe
Erinnerst du dich an den einen manuellen Schritt in der Demo — ich musste ins System gehen und auf Freigeben klicken? Warum kann KI dabei nicht zumindest helfen? Also haben wir auch das gebaut: Data Governance AI prüft die Zugriffsanfrage gegen Policies und winkt sie entweder durch oder markiert konkrete Verstöße („PII Processing: der Zugriffsanfrage fehlt ein klarer Zweck für PII-Daten“) und überlässt es dem Owner, mit Kontext freizugeben oder abzulehnen.


Peer-Reviewed: KI schlägt Menschen bei der Zugriffsfreigabe
Wir haben es nicht nur gebaut — wir haben es evaluiert. Gemeinsam mit der HTW Berlin und dem King’s College London und mit zwei Governance-Experten (Head of Data Governance im E-Commerce und in der Versicherung) haben wir eine Studie durchgeführt, die bei der AIES 2025 angenommen wurde.
Die wichtigsten Zahlen:
- Governance-KI gab 3,6× mehr Warnungen aus als die menschlichen Experten — und erfasste alle dieselben Compliance-Bedenken.
- 80 % der KI-generierten Warnungen wurden nach einer zweiten Prüfung als korrekt bewertet.
- LLM-generierte synthetische Testfälle simulierten reale Governance-Szenarien effektiv.
- Menschliche Aufsicht bleibt für kontextuelle und rechtliche Korrektheit wichtig.
In der Praxis: KI war korrekter als die Menschen, weil Menschen nicht alle Regeln im Kopf behalten können — und KI schon. Das vollständige Paper findest du auf entropy-data.com/de/forschung.

Zusammenfassung
Wir haben governeden, auditierten Zugriff auf Daten durch KI gesehen: die richtigen Daten für eine Frage finden, Zugriff mit einem Zweck anfragen, abfragen, das Warum auditieren, Queries blockieren, die nicht zu den Nutzungsbedingungen passen — alles automatisch. Das ist die Fähigkeit, auf die sich jeder zubewegen muss. MCP ist das richtige Protokoll für die Governance-Schicht.

Sei vorbereitet
Vergiss meinetwegen alles andere — merk dir nur das: Die Agenten kommen, und du kannst nur mit guten Metadaten und automatisierter Governance bereit sein.
Mach dich bereit.
Danke — Fragen?
Danke, dass ich an der Purdue sein durfte. Wenn du das Gespräch fortsetzen möchtest:
- Finde mich auf LinkedIn oder schreib eine E-Mail an simon.harrer@entropy-data.com.
- Lies das Paper: arxiv.org/pdf/2601.08687.
- Leg mit Data Contracts los auf datacontract.com — Open-Source-Tools inklusive.
- Leg mit einem Datenmarktplatz los auf entropy-data.com — Docker-Image verfügbar.