Talk
Chat with your Enterprise Data
Dr. Simon Harrer, Co-Founder & CEO @ Entropy Data · January 22, 2026
In this guest talk at Purdue University, I show how AI can answer any business question while enforcing data governance policies. Starting with a live demo of Claude discovering data products, requesting access with a clear purpose, and querying Databricks through an MCP server, I unpack why it works: good metadata in the form of data products, data contracts, semantics, and access agreements — and how AI finally gives us a reason to invest in that metadata.
Recorded as a guest lecture for Purdue University. The transcript below is an edited version of the talk.
Thanks to the Purdue University team for the invitation, and to our co-authors at King’s College London and the Jheronimus Academy of Data Science (JADS) for the research this talk builds on.

Hello, My Name Is Simon
Happy to speak today — I’m calling from Germany, so for me it’s almost late afternoon. By training I’m a software engineer. I worked a lot with Java, co-authored “Java by Comparison” on writing maintainable code, and spent three years in a remote mob-programming team — four or five people on a Zoom call all day, one screen shared, driver swapping every ten minutes, always working on one thing together. I also did a lot of infrastructure work with Kubernetes and the GitOps approach.
Then something I never expected happened: I switched sides. I switched to the dark side — the world of data. About five years ago. Honestly, by then there wasn’t a lot of innovation left in the software engineering world for me; the data world, by contrast, was exploding with innovation, driven by the rise of data mesh, the concept Zhamak Dehghani coined. With my co-author we built datamesh-architecture.com as a reference, and together we translated the O’Reilly Data Mesh book into German — the nice thing is that the German version is printed in color. We fought for that. You Americans are a little more stingy on printing in color, to be honest.
Because of my PhD in distributed systems I never fully left academia, and I still publish research together with people from King’s College London and HTW Berlin. I’m on the Technical Steering Committee of the Linux Foundation’s BITOL project driving open standards around data contracts and data products — you had a talk from Sean Perin, the TSC president, here at Purdue a while back. I co-maintain open-source tooling around those standards. And last but not least I’m the co-founder of Entropy Data, a SaaS data product marketplace. We’re a small startup — already profitable, VC-free, bootstrapped, and growing quickly. That’s my persona.

The White Paper
Today I want to talk about chatting with your enterprise data. We’ve written a white paper on arXiv — arxiv.org/pdf/2601.08687 — together with people from King’s College London and the Jheronimus Academy of Data Science (JADS) in the Netherlands. Go there for a lot more detail; everything I show here is also linked from entropy-data.com/research.

The Goal, in One Sentence
The key idea is simple: we want to enable AI to answer any business question while enforcing data governance policies.
Think about what that means. You give AI a question — or an AI agent autonomously comes up with one — and after a short while you just have the answer. While governance is enforced, because data can be very sensitive: you’re not allowed to do everything with every dataset. That’s what I want to share today.
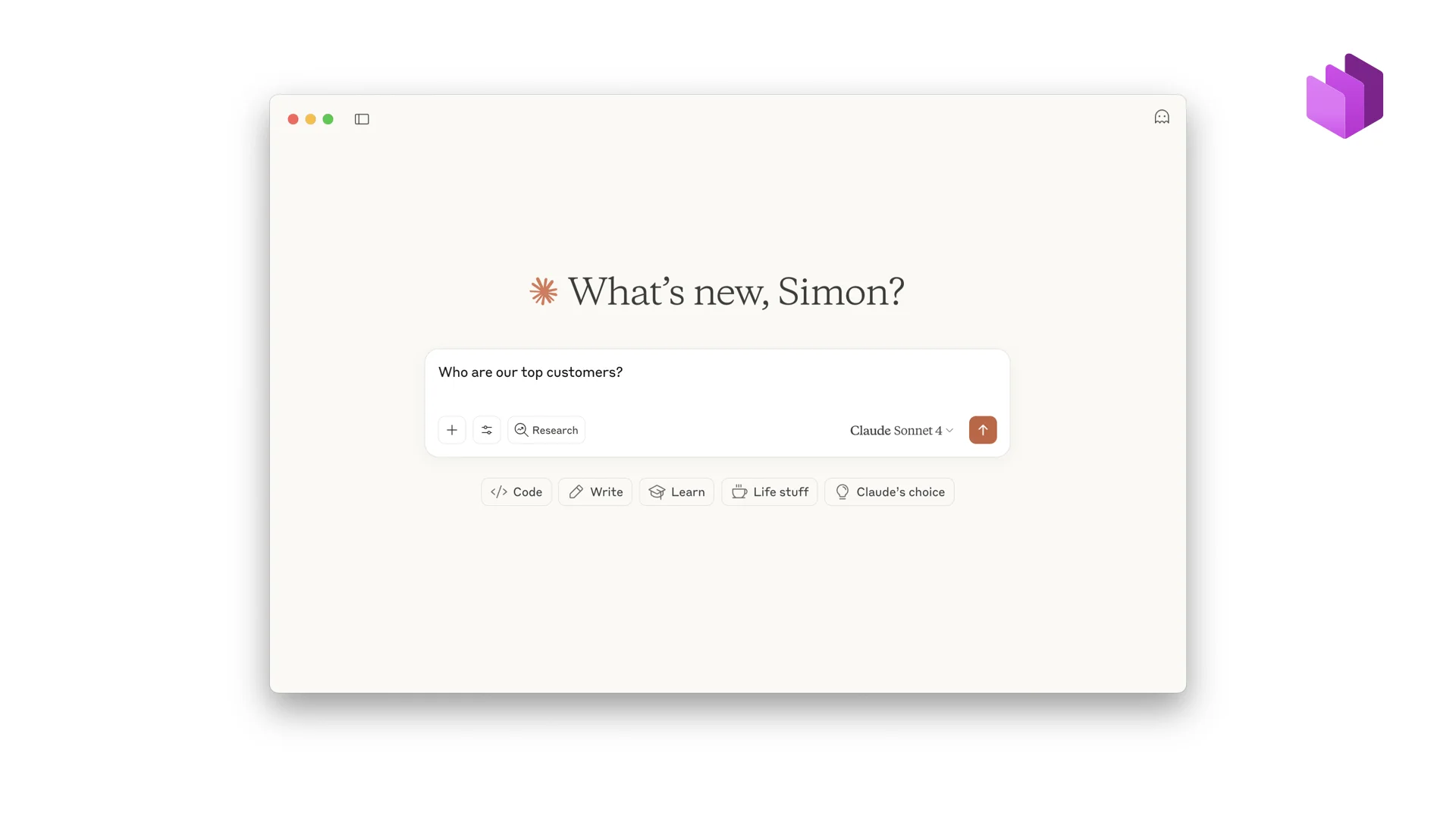
Live Demo: From Question to Answer
Let me get you a little excited with a demo. In the background we have a system that manages everything — a data product marketplace. I’m using Claude, connected to the system via an MCP connector. If everything is set up I can just ask a business question. Let me try: “What are our top customers?”
Claude picks that up as a trigger and automatically looks for relevant data. It runs a search for “customers” and finds a data product. That’s very high-level metadata. So next it does a fetch to get the full details — structure, semantics, quality, and whether we have access. It reads all of that, decides the data product is a good fit, but notices we don’t have access. So it automatically requests access, extracting a specific purpose from my question.
It gets back “submitted for approval, not yet approved.” The AI is a little cheeky: it still tries to execute a SQL query — with a purpose attached, so we know why every query is run — but the request is pending, so the query fails. In a second screen I approve the access request as the owner. Claude tries again, waits a few seconds for the Databricks serverless cluster to warm up, and then the results come back.
From “What are our top customers?” to a governed answer. Every step tracked. Every query carries a “why.” That is chatting with your enterprise data.
“This workflow is triggered by me as a human today, but it could just as well be an autonomous agent. There is no difference. And a lot of these agents are coming.”
A second example: “What are the top reasons for support tickets?” Same flow — but support tickets are less sensitive, so access is auto-approved. Search, fetch, request, query, answer — zero human interaction in the loop.
And one last one: “Export a CSV with customer email addresses for a luxury email campaign, only high-loyalty customers.” This time governance kicks in. The data product’s terms of use forbid marketing use. The AI refuses. In an older model I could sometimes talk it into ignoring that — so we added a second gatekeeper in the MCP server itself. Even if you convince the AI, the server stops the query in flight. Governance boundaries extend to the agents, and that matters, because agents can request access for one purpose and then try to use the data for another. That’s not allowed.

Revisiting the Use Cases
Back to the slides. What did we see? Governed, audited access to data through AI.
- We find the right data product for a given business question.
- We request access with a specific purpose.
- We query the data in the right way.
- We audit the why for every SQL query.
- We block SQL queries if the purpose is not covered by governance.
And all of it automatically. That last word is the one that matters: when the agents arrive, if you don’t have this automated you will not be able to keep up.
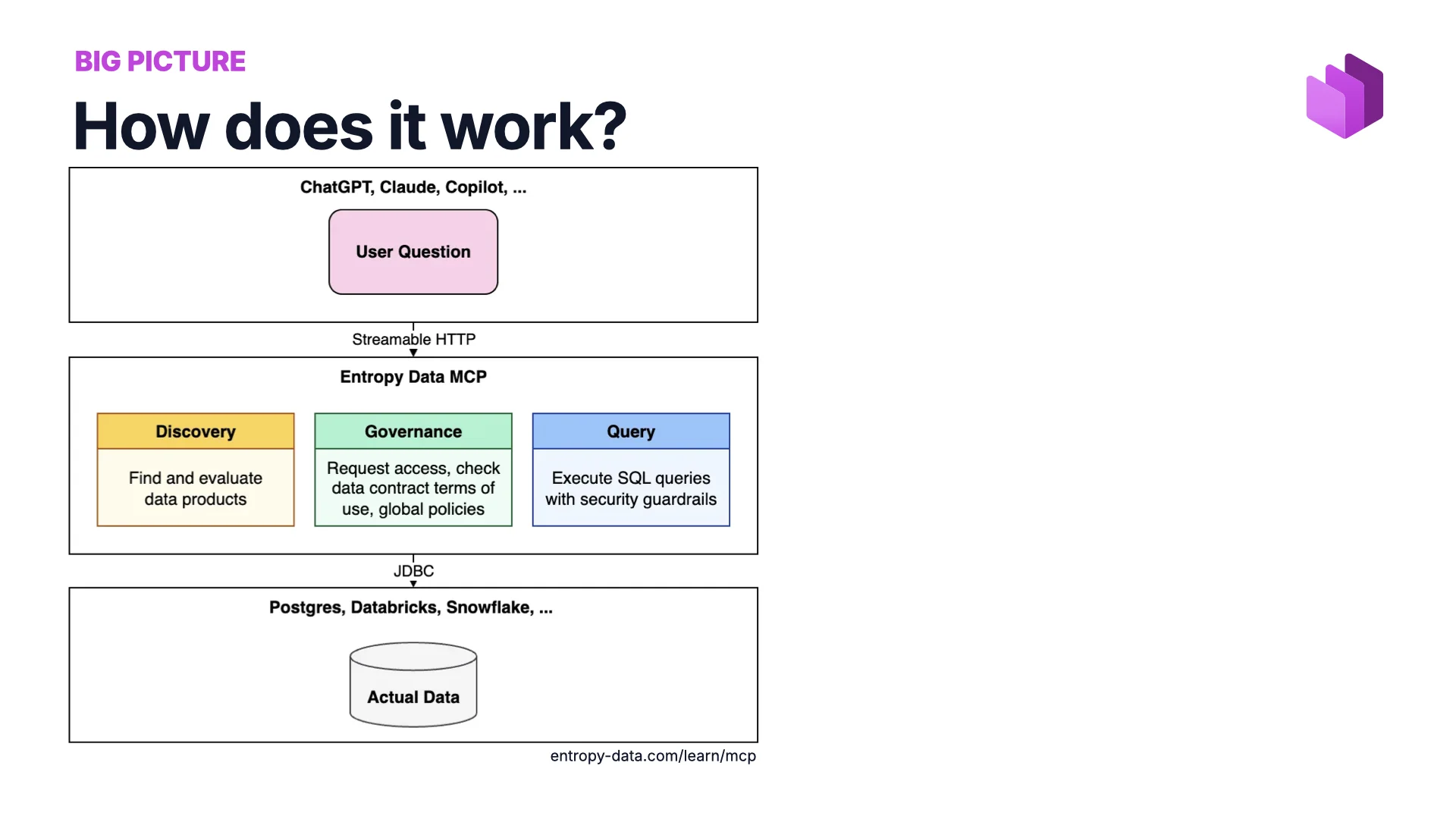
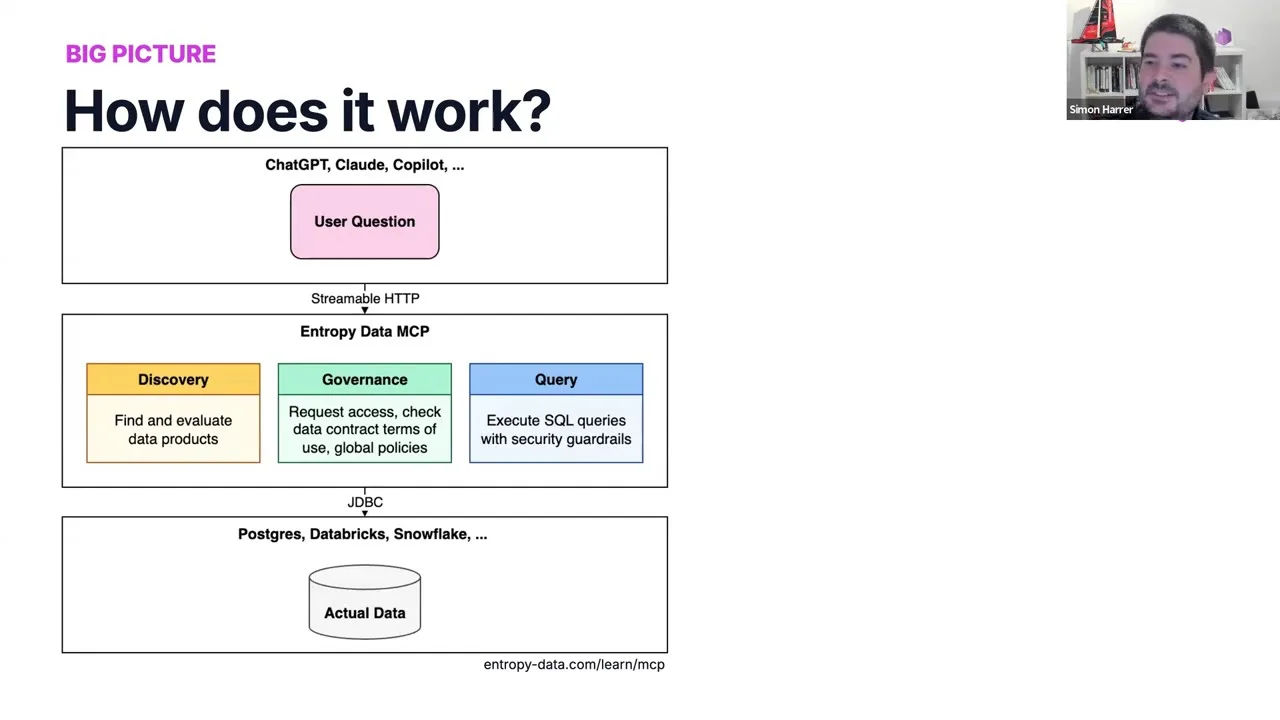
The Big Picture
The architecture is simple. The agentic world at the top (ChatGPT, Claude, Copilot). The actual data at the bottom (Postgres, Databricks, Snowflake). And in the middle an MCP server that acts as a thin governance layer with three responsibilities:
- Discovery — find and evaluate data products.
- Governance — request access, check data contract terms of use, enforce global policies.
- Query — execute SQL with security guardrails in front of it.
Technically, building this today is not hard — Claude Code writes most of it for you. The interesting question is why it works so well.


Two Reasons It Works
The first reason is the obvious one: AI agents keep getting better. You saw the magic — Claude planned its steps in the background, executed them in sequence, recovered from errors, and I didn’t have to tell it to do any of that.
But the real answer is good metadata. Without it, my demo would have been very bad. Let me walk through the success factors — the kinds of metadata that make this actually work.
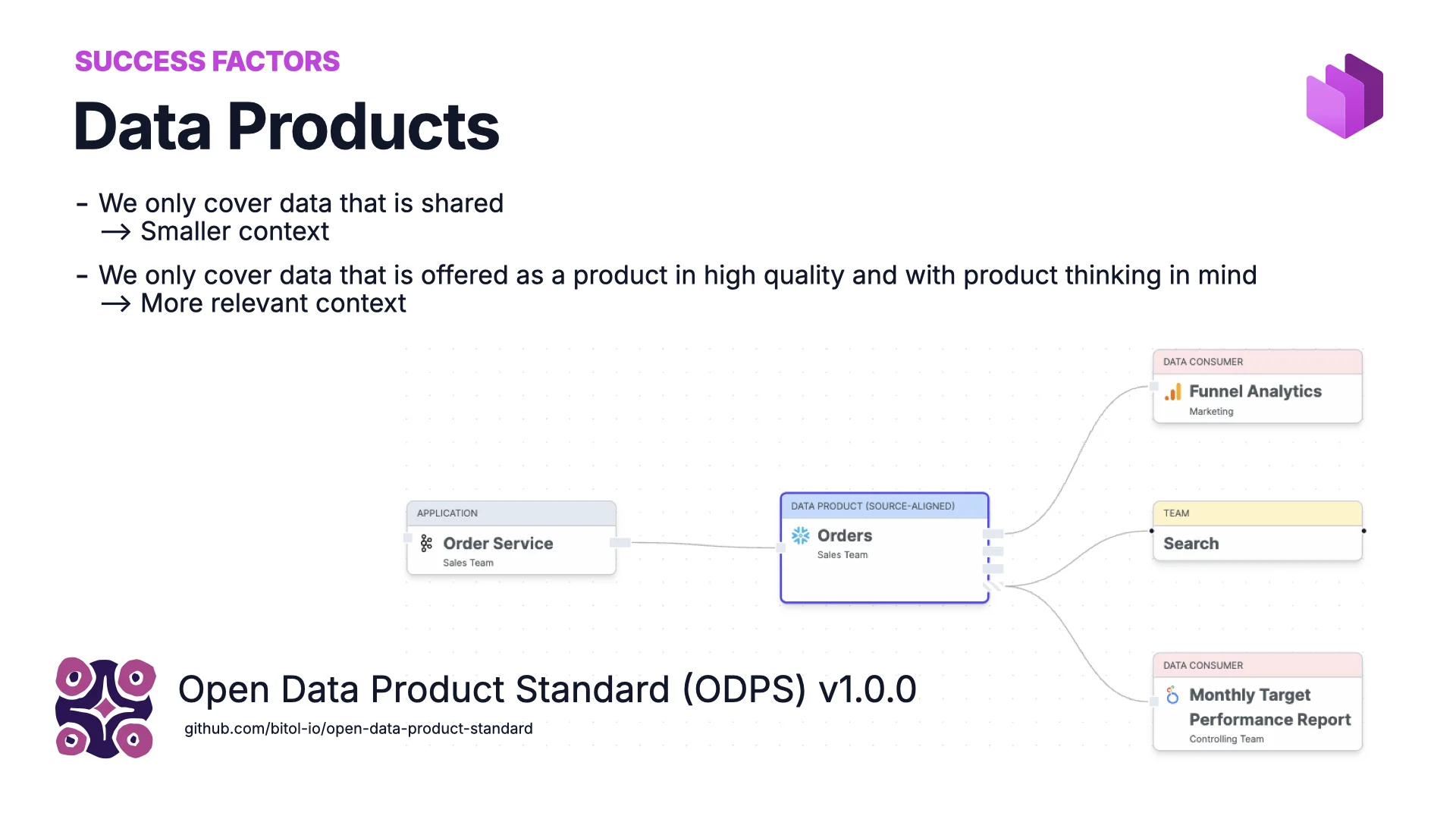
Success Factor #1: Data Products
The marketplace in the background offered data in the form of data products. The idea: you don’t dump every table in your company into the marketplace — only the data someone owns and wants to share as a product.
That does two things. It shrinks the context — and the smaller the context, the better for AI. And it raises quality and ownership: with product thinking you build for a consumer, whether that consumer is a human or an agent. For the format we use the open Open Data Product Standard (ODPS) v1.0.0, which gives the metadata a predictable structure.
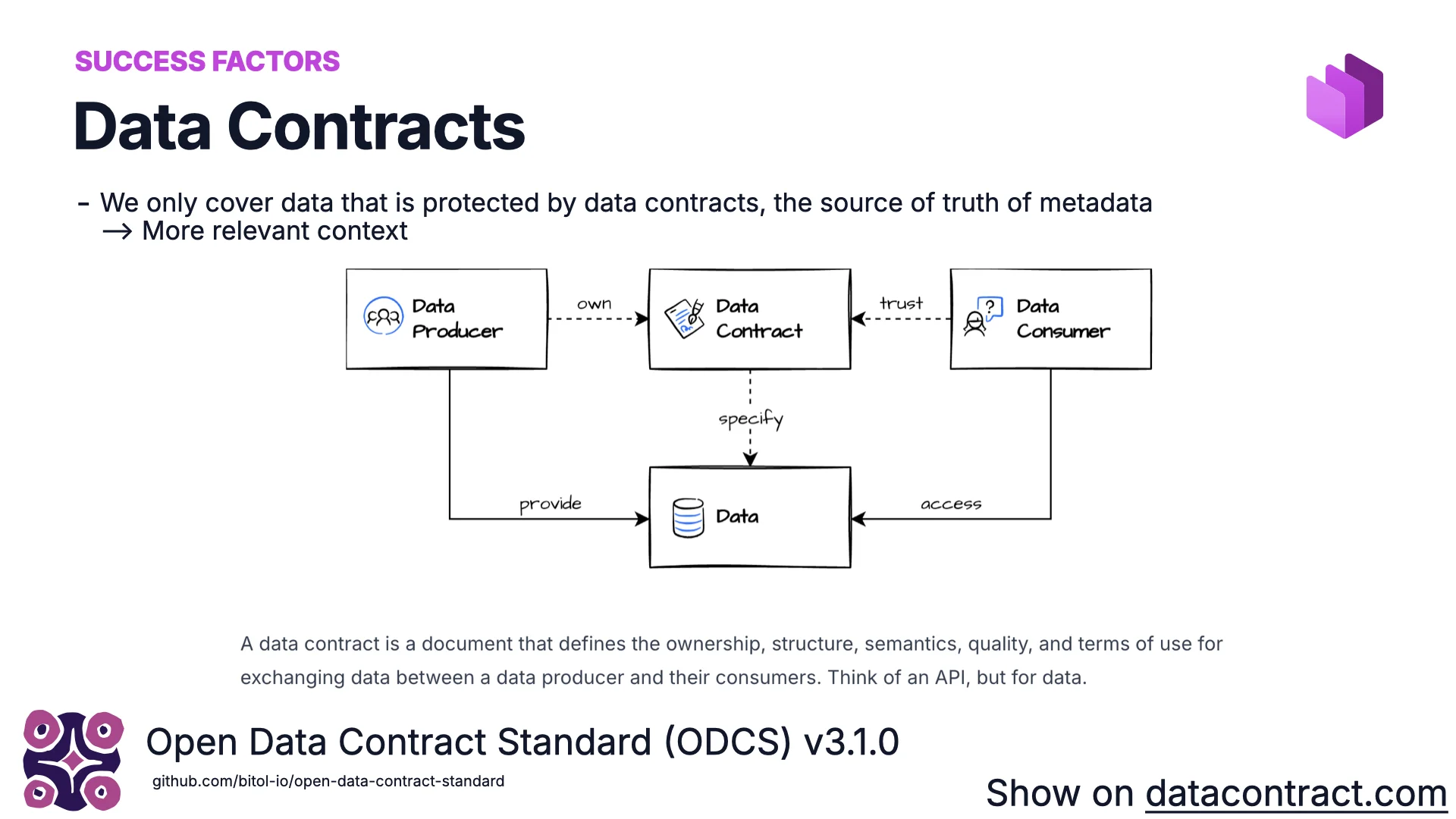
Success Factor #2: Data Contracts
A data contract defines ownership, structure, semantics, quality, and terms of use for data flowing between a producer and its consumers. Think of an OpenAPI spec — but for data. It’s readable by humans, perfect for tooling, and ideal for AI: it is the best metadata you can attach to a dataset, because it can be trusted as the source of truth.
On datacontract.com you can see what this looks like in practice. A contract is typically a YAML file with fundamentals (id, name, version, status), a schema (tables, columns, logical and physical types, classifications like PII), data quality (e.g. order_status ∈ {pending, shipped, cancelled}, or arbitrary SQL — sometimes absolute, sometimes percentage-based, because the data world is messy), ownership and Slack channels, terms of use (what you can and cannot do — e.g. not for marketing), SLAs (retention, freshness — never older than 24 hours), and finally the server (Postgres, Databricks, Snowflake, S3, Iceberg… wherever the data actually lives).
The standard here is ODCS v3.1.0. The open-source editor lets you author contracts through a form, diagram, or raw YAML. The Data Contract CLI — ~800 GitHub stars — reads a contract, connects to the real data source, and verifies every guarantee holds. That automatic verification is what makes the contract trustworthy enough to feed into the AI’s discovery step.
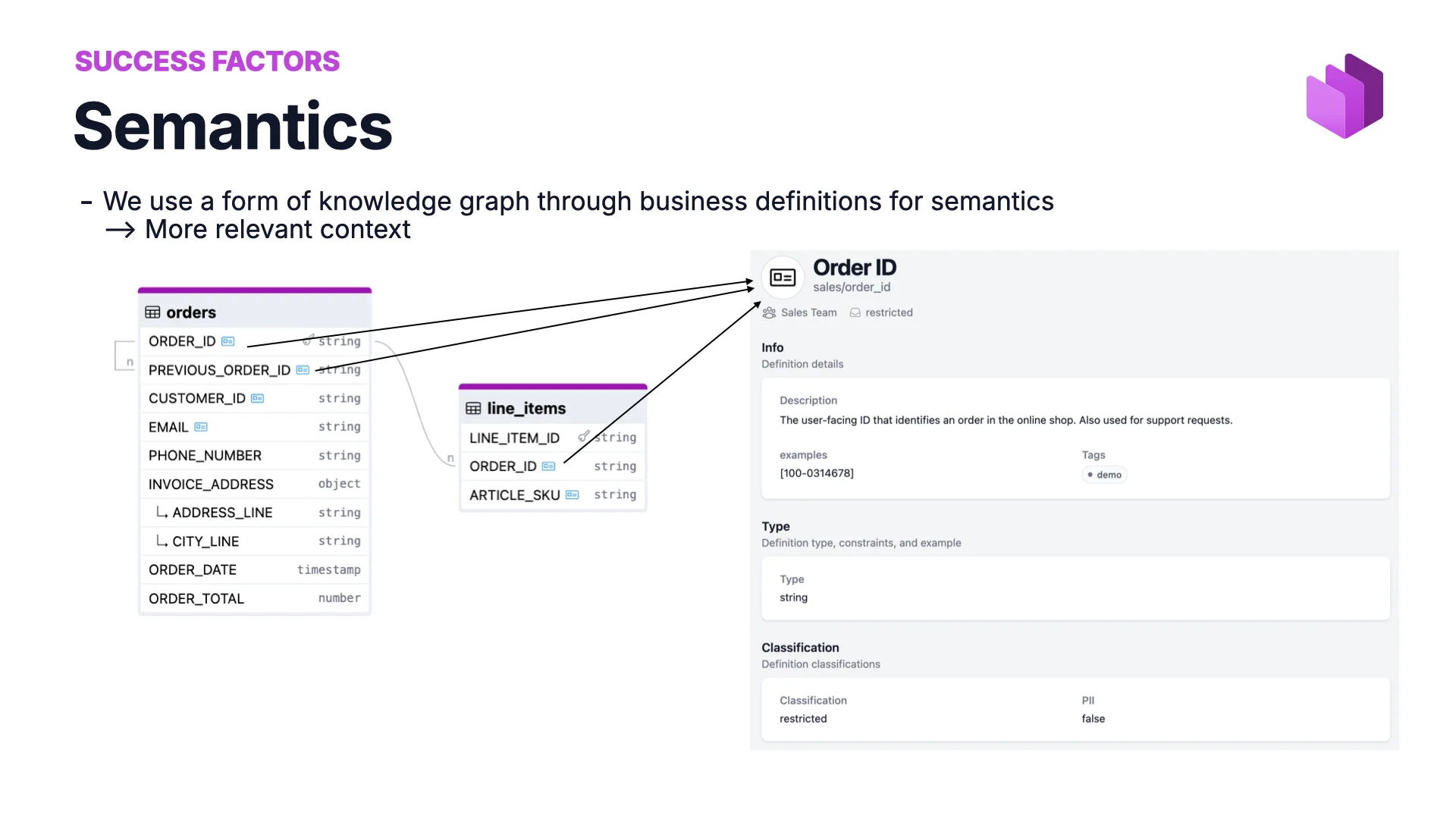
Success Factor #3: Semantics
To do joins across tables, the AI has to know whether two columns can be joined — whether order_id in one table really means the same thing as order_id in another. Especially when joins chain across several data products.
For that we define semantics — a business glossary or knowledge graph. Order ID is defined once in the sales domain, and data contracts point to that shared definition. The same concept, same pointer, same truth everywhere. With semantics in place, AI writes the right SQL joins without having to guess.

Success Factor #4: Access Agreements
In the demo, the AI requested access for me. Under the hood it filled out a form, but the essence is that on the backend we always know:
- Who has access to what data, and why.
- What the terms and conditions of that access are — what is allowed, what is not.
That is what makes governance checks real — and what lets us build a system like this at all.
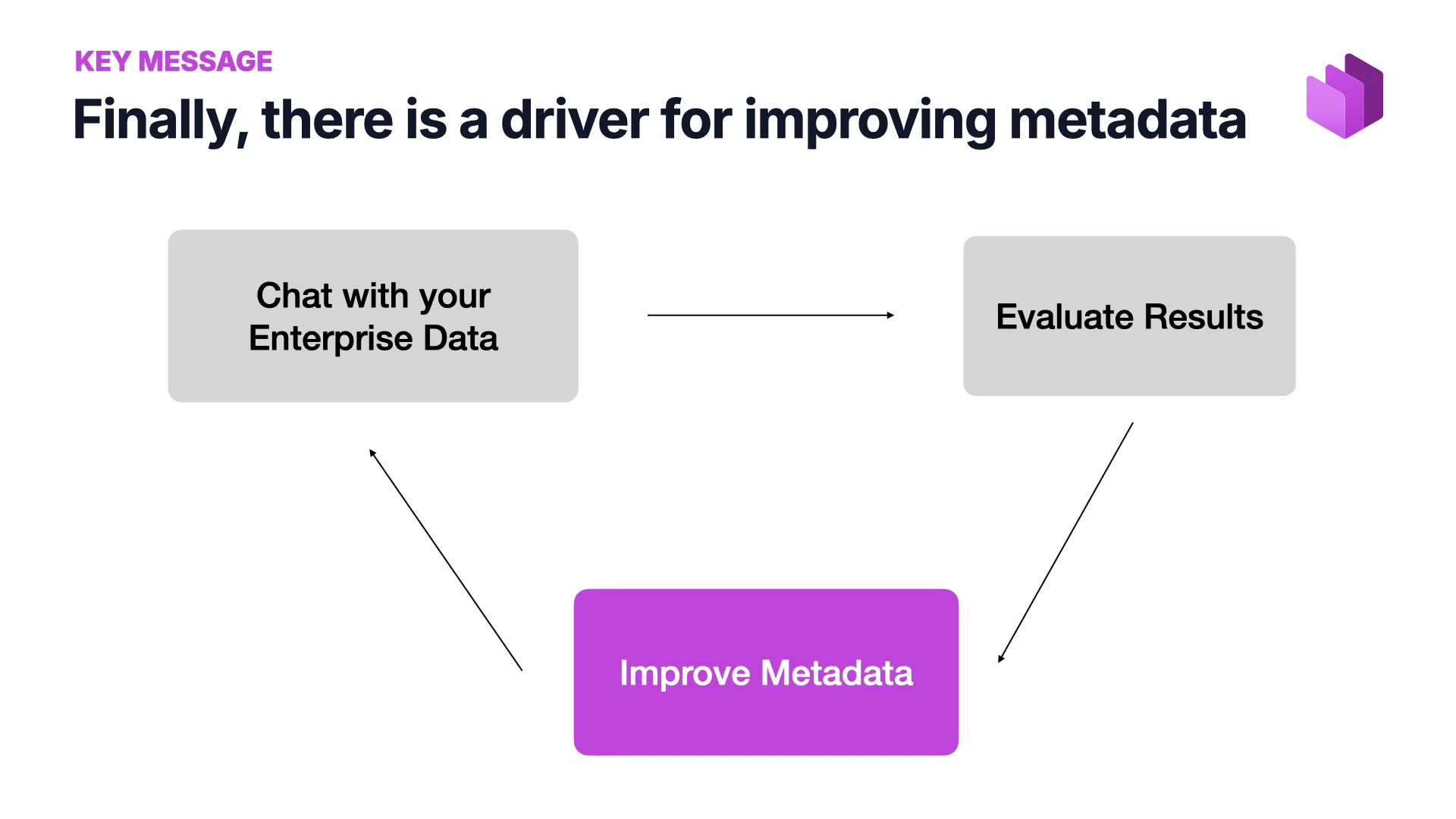
Finally, a Driver for Better Metadata
Before AI, I would have agreed with the devil’s advocate. Getting anyone to invest time in metadata was hard — governance people would show up asking for it and the request would sit at the bottom of the backlog forever. Now there is a feedback loop that didn’t exist before:
Chat with your enterprise data → evaluate the results → if they’re not what you wanted, improve the metadata → chat again → better results.
“People are selfish — they won’t invest time to help others, or to fulfil a policy for the sake of a policy. But when they get the benefit themselves, they will improve the metadata.”
That is the difference. Everybody who sees this demo says: “This is what I want.” And the only way to get it is better metadata. So they’ll invest.

Yes, AI Is Here for Us
Three places AI already helps with metadata today:
- Metadata creation — authoring and updating contracts and product definitions.
- Metadata monitoring — checking whether metadata matches your policies.
- Access approval — the one step that was still manual in the demo.
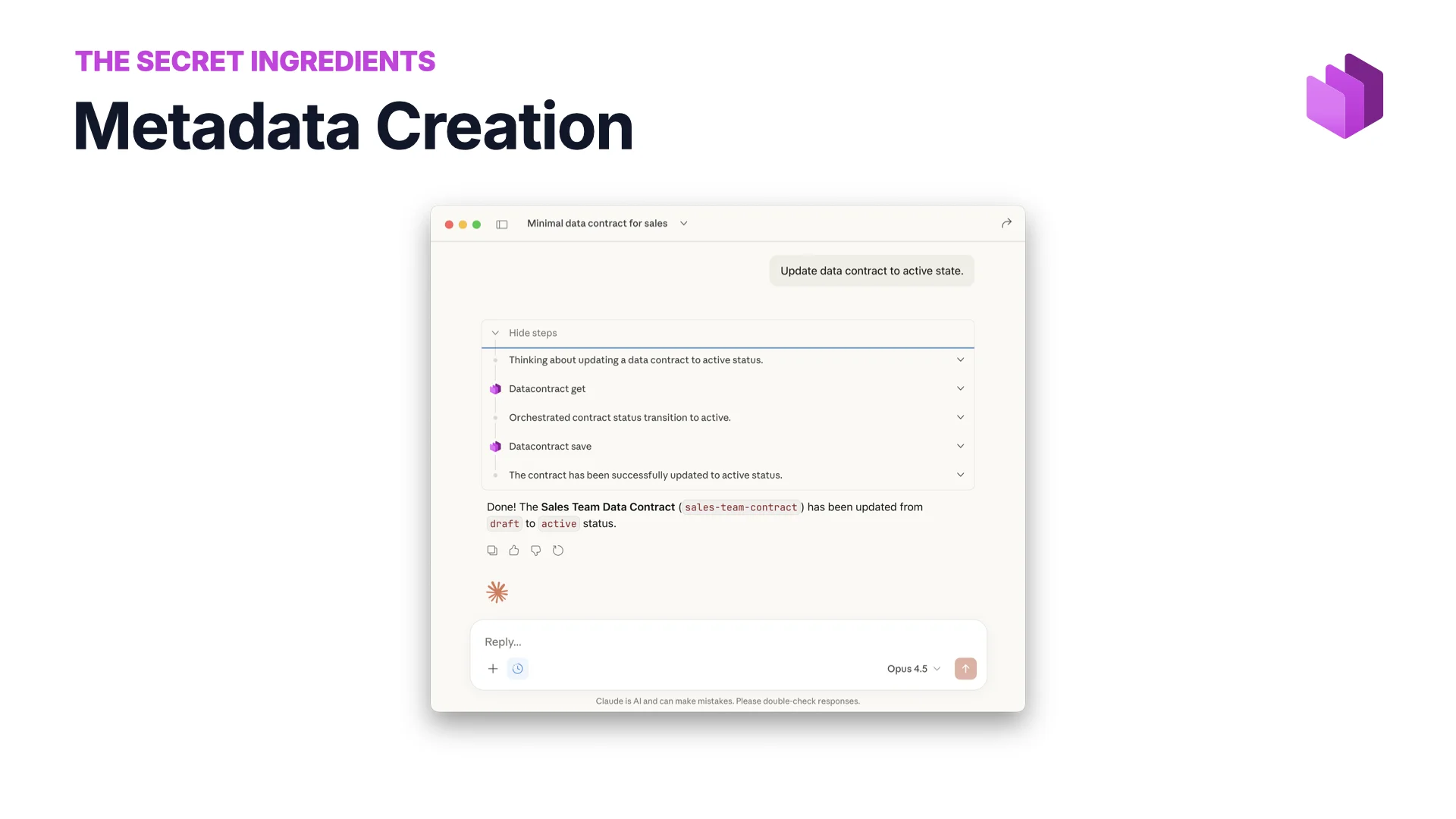
Metadata Creation
You don’t have to type metadata in manually any more. Ask AI to update a data contract, promote it from draft to active, fill in the missing classifications. Give it extra context — your Confluence, the actual data, another system of record — and it will produce much better metadata than it would from the YAML alone.

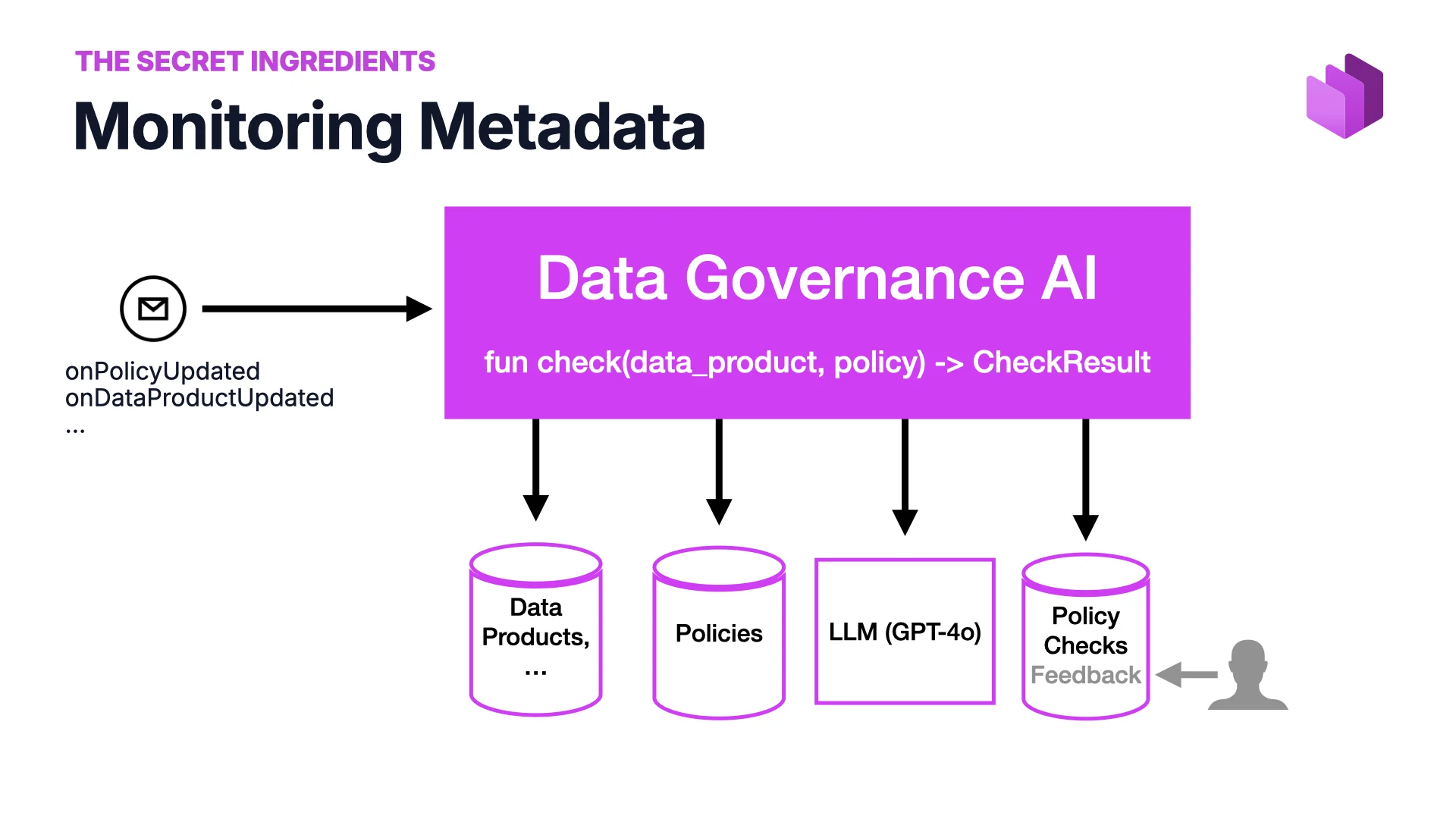

Metadata Monitoring
You don’t want your metadata to deteriorate, because the moment it does, your AI results deteriorate too. So you monitor it against rules: what is a good data product? what is a good data contract? what are we allowing?
The insight is that you can now express those rules in natural language. Governance AI takes a data product plus a policy and returns a check result. The input is policies and data products, the model is an LLM, the output is a set of policy checks with feedback users can flag. We’ve built a prototype and it works well.
The real win: non-experts can now define what “good” looks like. Governance people without programming backgrounds can write rules, monitor the system, and iterate. Yes, hallucinations are still a problem — users can flag false positives, but there is no great answer for false negatives yet. Honest trade-off, powerful pattern.
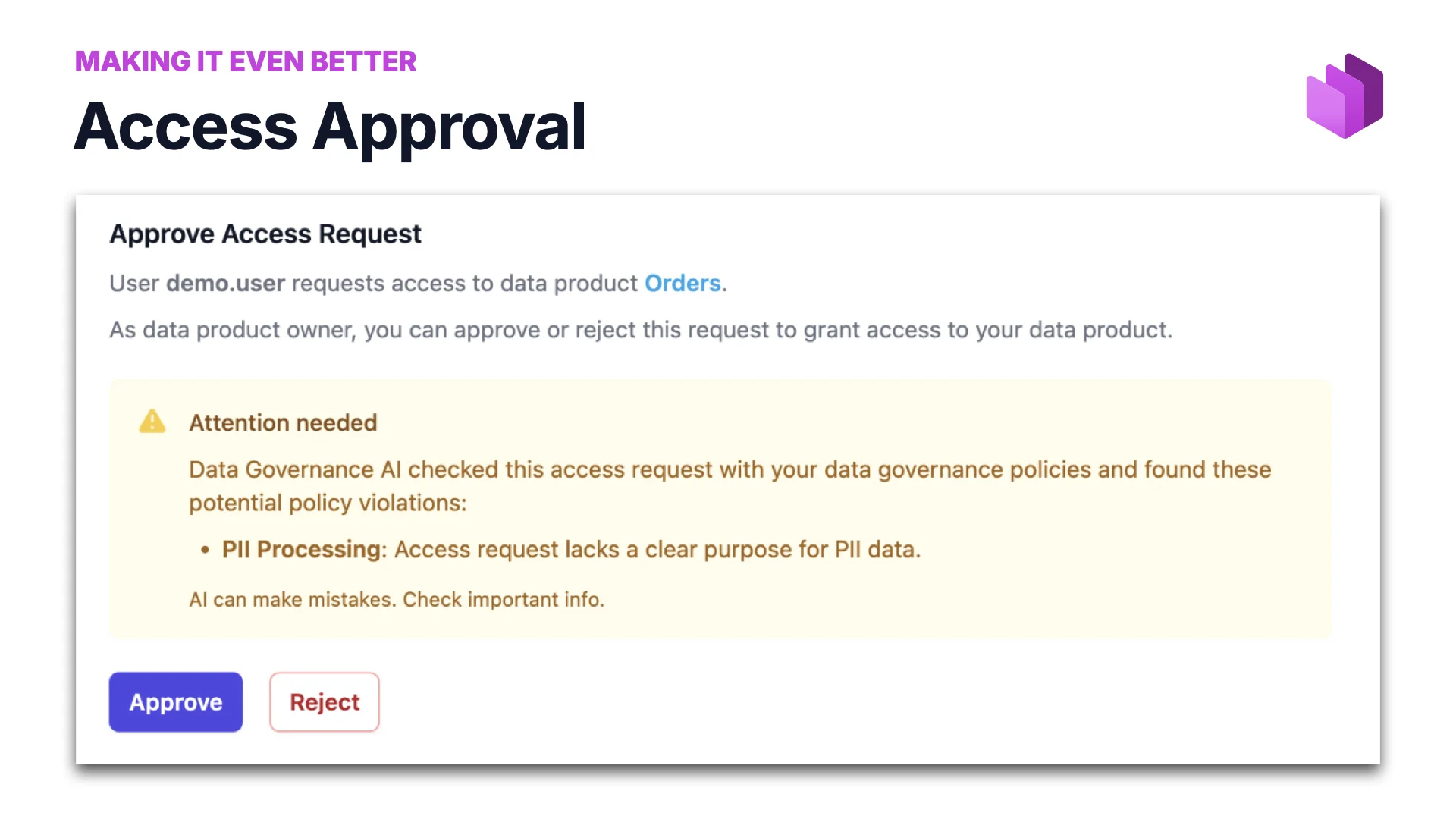
Access Approval
Remember the one manual step in the demo — I had to go into the system and click approve? Why can’t AI at least help with that? So we built that too: Data Governance AI checks the access request against policies and either waves it through or flags specific violations (“PII Processing: access request lacks a clear purpose for PII data”), leaving the owner to approve or reject with context.


Peer-Reviewed: AI Beats Humans at Access Approval
We didn’t just build it — we evaluated it. Together with HTW Berlin and King’s College London, and with two governance experts (Head of Data Governance in e-commerce and in insurance), we ran a study that was accepted at AIES 2025.
The headline numbers:
- Governance AI issued 3.6× more warnings than the human experts — and caught all the same compliance concerns.
- 80% of AI-generated warnings were judged correct after secondary review.
- LLM-generated synthetic test cases effectively simulated real-world governance scenarios.
- Human oversight still matters for contextual and legal accuracy.
In practice: AI was more correct than the humans, because humans can’t hold all the rules in their heads — and AI can. Full paper at entropy-data.com/research.

To Sum Up
We’ve seen governed, audited access to data through AI: find the right data for a question, request access with a purpose, query, audit the why, block queries that don’t match the terms — all automatic. This is the capability everyone needs to move toward. MCP is the right protocol for the governance layer.

Be Prepared
Forget everything else if you want — just remember this: the agents are coming, and you can only be ready with good metadata and automated governance.
Get ready.
Thank You — Questions?
Thanks for having me at Purdue. If you want to continue the conversation:
- Find me on LinkedIn or email simon.harrer@entropy-data.com.
- Read the paper: arxiv.org/pdf/2601.08687.
- Get started with data contracts at datacontract.com — open-source tools included.
- Get started with a data marketplace at entropy-data.com — Docker image available.